






-
- 黏菌优化算法-SMA -可用于(数据聚类/特征选择/模型参数优化/桥梁结构优化)
- 概述
- 黏菌优化算法(Slime Mould Algorithm,SMA)是一种新型的启发式优化算法。它是受黏菌的觅食行为启发而提出的。黏菌在寻找食物的过程中,会通过自身的细胞质流动来探索周围环境,这种独特的行为模式为算法的设计提供了思路。
- 黏菌的行为模拟
- 觅食阶段:在自然界中,黏菌会向食物源方向伸展伪足。在算法中,这一行为被模拟为搜索空间中的个体(类似于黏菌个体)朝着可能的最优解方向移动。假设在一个优化问题的解空间中,每个解看作是一个个体的位置,这些个体就像黏菌一样,通过某种机制来判断并朝着更优的位置移动。
- 更新机制:黏菌个体的位置更新是 SMA 的核心操作。它根据当前个体位置、最优个体位置以及其他相关参数来计算新的位置。这个更新过程考虑了个体之间的信息交流和对历史最优位置的记忆,就像黏菌在觅食过程中会利用自身的经验和周围环境的反馈来调整前进方向。
- 数学模型
- 一般地,设种群规模为,搜索空间维度为,第个个体在第维的位置表示为,其位置更新公式如下:
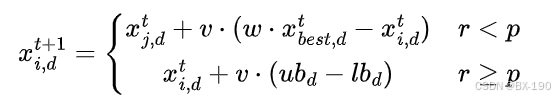
- 应用领域
- 工程优化:例如在机械设计中,可以用于优化机械结构的参数,如零件尺寸、形状等,以达到最小化质量或最大化强度等目标。
- 函数优化:对于复杂的数学函数求最优解,SMA 可以在一定程度上避免陷入局部最优,有效地搜索到全局最优或近似最优解。
- 神经网络参数优化:在训练神经网络时,SMA 可以用来优化神经网络的权重和阈值等参数,提高神经网络的性能。
- 优势与不足
- 优势:
- 具有较强的全局搜索能力,能够在复杂的搜索空间中找到较优的解。
- 相比于一些传统的优化算法,SMA 的参数相对较少,易于理解和实现。
- 不足:
- 对于高维复杂问题,可能会出现收敛速度慢的情况。
- 和其他启发式算法一样,其性能在很大程度上依赖于参数的设置,不合适的参数可能导致算法无法得到理想的结果。
- 优势:
数据聚类
- 原理:SMA 模拟黏菌在觅食过程中通过化学信号进行信息交流和聚集的行为,将数据点看作是黏菌个体,数据点之间的相似性作为黏菌之间的吸引程度。算法通过不断迭代更新黏菌的位置,使相似的数据点聚集在一起,形成不同的簇。
- 优势:相比传统聚类算法,SMA 能更好地处理复杂分布的数据,发现数据中的潜在结构,对存在噪声和离群点的数据也有较好的鲁棒性。
- 应用实例:在市场调研中,对消费者的各种属性数据进行聚类,可依据消费者的年龄、收入、消费习惯等数据,利用 SMA 将消费者分为不同的群体,为企业制定精准营销策略提供依据。
特征选择
- 原理:将特征选择问题转化为一个优化问题,把每个特征子集看作是黏菌的一个可能位置。SMA 通过评估每个特征子集对应的适应度值,即利用该特征子集进行模型训练时的性能指标,如分类准确率、回归误差等,来判断特征子集的优劣。算法不断搜索,以找到能使适应度值最优的特征子集,实现特征选择。
- 优势:SMA 可以在高维数据中快速筛选出对模型性能贡献最大的特征,减少数据维度,提高模型训练效率,降低过拟合风险,增强模型的泛化能力。
- 应用实例:在生物医学数据分析中,对于大量的基因表达数据,使用 SMA 可以挑选出与特定疾病相关的关键基因特征,为疾病诊断和治疗靶点的发现提供重要依据。
模型参数优化
- 原理:将模型的参数空间看作是黏菌的搜索空间,每个黏菌代表一组模型参数。SMA 通过模拟黏菌的觅食和移动行为,在参数空间中进行搜索,根据模型在训练数据上的性能表现,如损失函数值、准确率等,来更新黏菌的位置,即调整模型参数,以找到使模型性能最优的参数组合。
- 优势:SMA 能够在复杂的参数空间中进行全局搜索,避免陷入局部最优解,相比传统的梯度下降等优化方法,能更有效地找到最优参数,提高模型的拟合能力和预测精度。
- 应用实例:在深度学习中,对卷积神经网络(CNN)的超参数,如学习率、层数、卷积核大小等进行优化。利用 SMA 可以找到一组最优的超参数,使 CNN 在图像识别、语音识别等任务中取得更好的效果。
桥梁结构优化
- 原理:把桥梁的结构参数,如梁高、桥墩直径、预应力筋布置等,作为黏菌的位置变量。SMA 以桥梁的安全性、经济性、适用性等为目标函数,通过模拟黏菌的行为来调整这些结构参数,寻找满足设计要求和约束条件下的最优结构方案。
- 优势:SMA 可以同时考虑多个设计目标和约束条件,综合优化桥梁结构,能够在保证桥梁安全性能的前提下,降低建设成本,提高桥梁的使用寿命和性能。
- 应用实例:在大跨度桥梁的设计中,使用 SMA 对斜拉桥的拉索布置、主梁截面形状等参数进行优化,可使斜拉桥在承受较大荷载的同时,具有更好的稳定性和经济性,减少材料用量和施工难度。
具体代码及实验结果
%% 清除工作区变量
clear
%% 清除命令行窗口内容
clc
%% 关闭所有图形窗口
close all
%% 将当前目录及其子目录添加到搜索路径
addpath(genpath(pwd))
%% 选定优化函数,可自行替换为 F1~F23
number='F10';
%% 获取优化函数的下界、上界、维度和目标函数表达式
[lb,ub,dim,y]=CEC2005(number);
%% 最大迭代次数
MaxIteration=1000;
%% 种群规模
Solution_no=50;
%% 调用SMA算法,将返回最优适应度值、最佳粒子位置和收敛曲线
[Destination_fitness,bestPositions,Convergence_curve]=SMA(Solution_no,MaxIteration,lb,ub,dim,y);
%% 显示最佳适应度值
disp(['最佳适应度值',num2str(Destination_fitness)])
%% 显示最佳粒子位置
disp(['最佳粒子位置',num2str(bestPositions)])
%% 绘图部分
subplot(1,2,1)
%% 绘制选定函数的图像
func_plot(number)
title(number)
xlabel('x')
ylabel('y')
zlabel('z')
subplot(1,2,2)
CNT=50;
%% 从 1 到最大迭代次数中随机选取 50 个点
k=round(linspace(1,MaxIteration,CNT));
%% 定义迭代次数向量,从 1 到最大迭代次数
iter=1:1:MaxIteration;
%% 绘制半对数坐标图,横坐标为迭代次数的随机选取点,纵坐标为相应收敛曲线的值
semilogy(iter(k),Convergence_curve(k),'m-x','linewidth',1);
%% 开启网格
grid on;
title(['函数收敛曲线',number])
xlabel('Iterations');
ylabel('Objective function value');
%% 开启图形边框
box on
legend('SMA')
%% 设置图形窗口的位置和大小
set (gcf,'position', [200,300,700,300])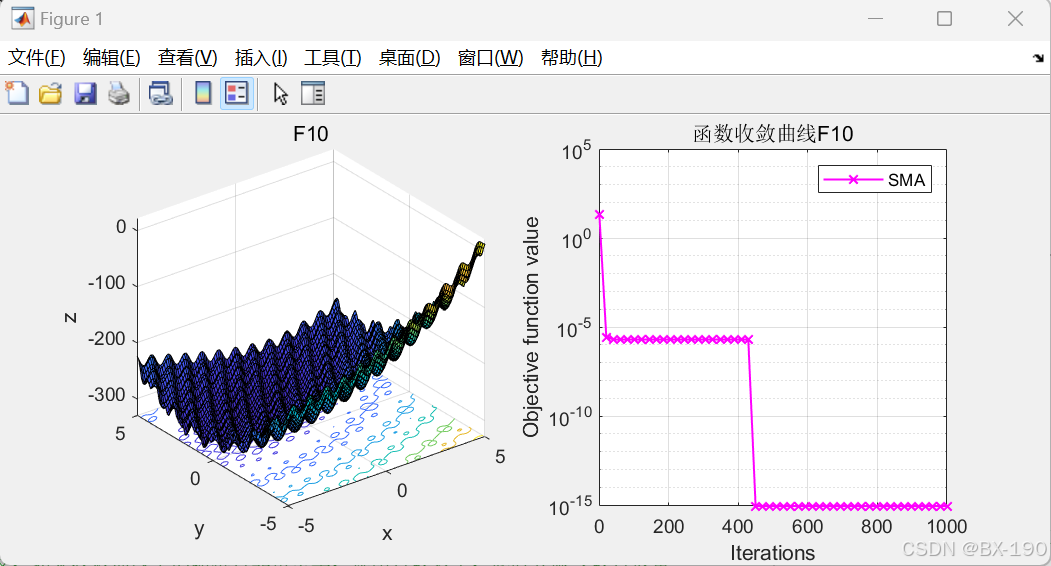
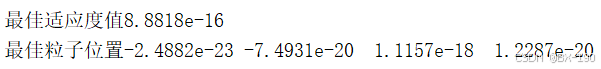

















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









