








YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程
YOLOv11改进汇总贴:YOLOv11及自研模型更新汇总-CSDN博客
《Adapt or Perish: Adaptive Sparse Transformer with Attentive Feature Refinement for Image Restoration》
一、 模块介绍
论文链接:Adapt or Rerish
代码链接:https://github.com/joshyZhou/AST
论文速览:基于 transformer 的方法在图像恢复任务中取得了有希望的性能,因为它们能够对长距离依赖性进行建模,这对于恢复清晰图像至关重要。尽管不同的高效注意力机制设计已经解决了与使用 transformer 相关的密集计算,但它们通常涉及冗余信息和来自不相关区域的嘈杂交互,因为要考虑所有可用的标记。在这项工作中,作者提出了一种自适应稀疏变压器 (AST) 来减轻不相关区域的噪声交互,并消除空间和通道域中的特征冗余。AST 包括两个核心设计,即自适应稀疏自注意力 (ASSA) 模块和特征细化前馈网络 (FRFN)。具体来说,ASSA 是使用双分支范式自适应计算的,其中引入稀疏分支以过滤掉低查询键匹配分数对聚合特征的负面影响,而密集分支则确保通过网络有足够的信息流来学习判别性表示。同时,FRFN 采用增强和简化方案来消除通道中的特征冗余,从而增强清晰潜影的恢复。常用基准的实验结果表明,我们的方法在多项任务中具有多功能性和竞争性能,包括去除雨纹、去除真雾和去除雨滴。
总结:一种高效的特征提取模块,通过稀疏注意力ASSA模块与特征细化前馈模块FRFN组成。
二、 加入到YOLO中
2.1 创建脚本文件
首先在ultralytics->nn路径下创建blocks.py脚本,用于存放模块代码。

2.2 复制代码
复制代码粘到刚刚创建的blocks.py脚本中,如下图所示:
class FRFN(nn.Module):
def __init__(self, dim=32, hidden_dim=128, act_layer=nn.GELU, drop=0., use_eca=False):
super().__init__()
self.linear1 = nn.Sequential(nn.Linear(dim, hidden_dim * 2),
act_layer())
self.dwconv = nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, groups=hidden_dim, kernel_size=3, stride=1, padding=1),
act_layer())
self.linear2 = nn.Sequential(nn.Linear(hidden_dim, dim))
self.dim = dim
self.hidden_dim = hidden_dim
self.dim_conv = self.dim // 4
self.dim_untouched = self.dim - self.dim_conv
self.partial_conv3 = nn.Conv2d(self.dim_conv, self.dim_conv, 3, 1, 1, bias=False)
def forward(self, x):
# bs x hw x c
c, bs, hh, hw = x.size()
# hh = int(math.sqrt(hw))
#
# # spatial restore
# x = rearrange(x, ' b (h w) (c) -> b c h w ', h=hh, w=hh)
x1, x2, = torch.split(x, [self.dim_conv, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
# flaten
x = rearrange(x, ' b c h w -> b (h w) c', h=hh, w=hw)
x = self.linear1(x)
# gate mechanism
x_1, x_2 = x.chunk(2, dim=-1)
x_1 = rearrange(x_1, ' b (h w) (c) -> b c h w ', h=hh, w=hw)
x_1 = self.dwconv(x_1)
x_1 = rearrange(x_1, ' b c h w -> b (h w) c', h=hh, w=hw)
x = x_1 * x_2
x = self.linear2(x)
# x = self.eca(x)
return rearrange(x, ' b (h w) (c) -> b c h w ', h=hh, w=hw)

2.3 更改task.py文件
打开ultralytics->nn->modules->task.py,在脚本空白处导入函数。
from ultralytics.nn.blocks import *

之后找到模型解析函数parse_model(约在tasks.py脚本中940行左右位置,可能因代码版本不同变动),在该函数的最后一个else分支上面增加相关解析代码。
elif m is FRFN:
c2 = ch[f]
args = [ch[f]]
2.4 更改yaml文件
打开更改ultralytics/cfg/models/11路径下的YOLOv11.yaml文件,替换原有模块。

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, FRFN, []]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)

2.5 修改train.py文件
创建Train脚本用于训练。
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = YOLO(model='ultralytics/cfg/models/11/yolo11.yaml')
# model.load('yolov8n.pt')
model.train(data='./data.yaml', epochs=2, batch=1, device='0', imgsz=640, workers=2, cache=False,
amp=True, mosaic=False, project='runs/train', name='exp')

在train.py脚本中填入修改好的yaml路径,运行即可训练,数据集创建教程见下方链接。

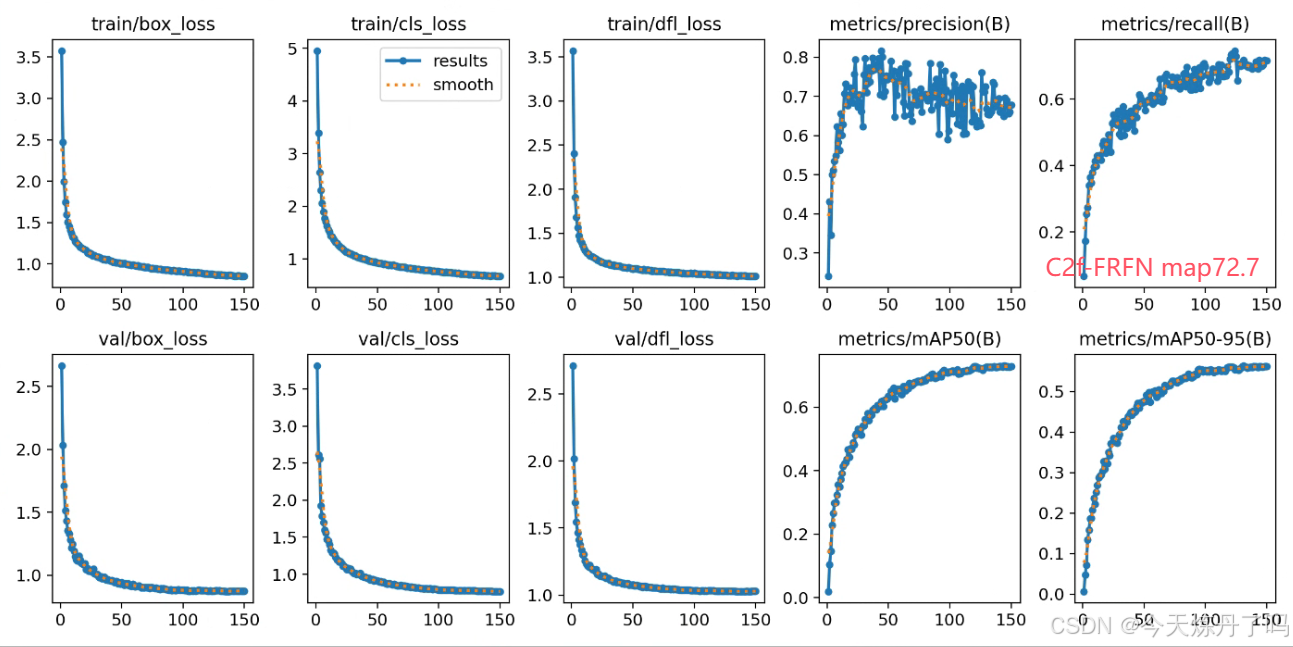
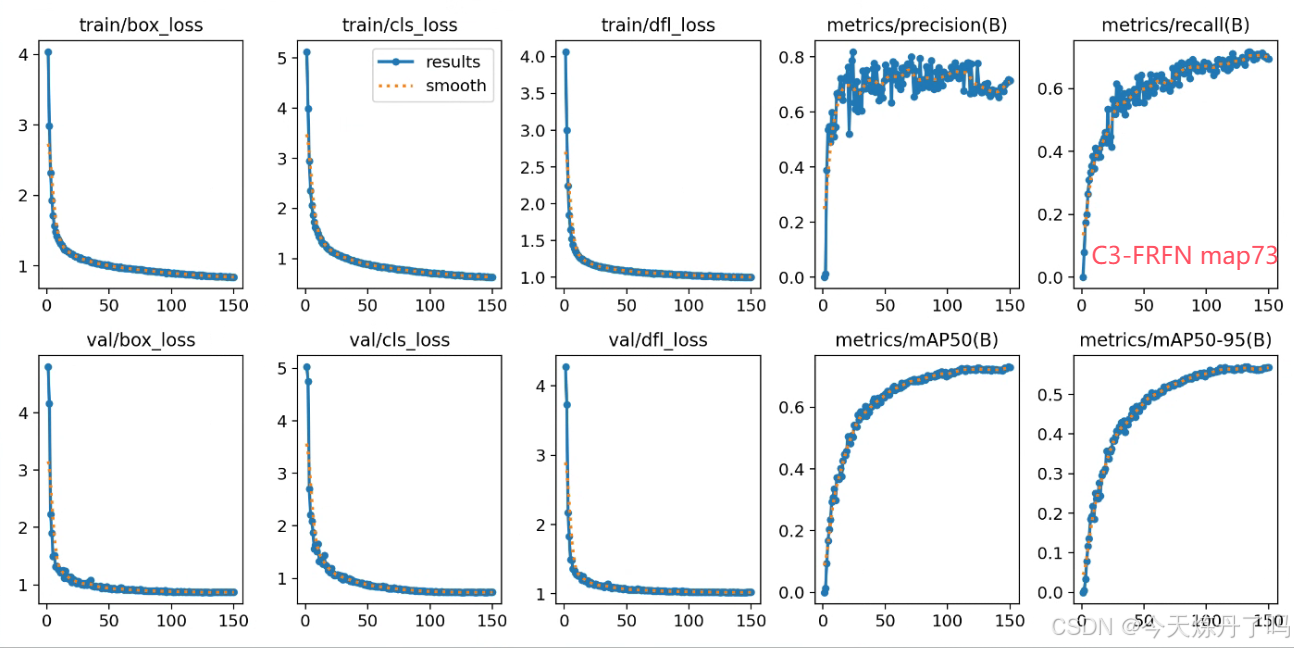
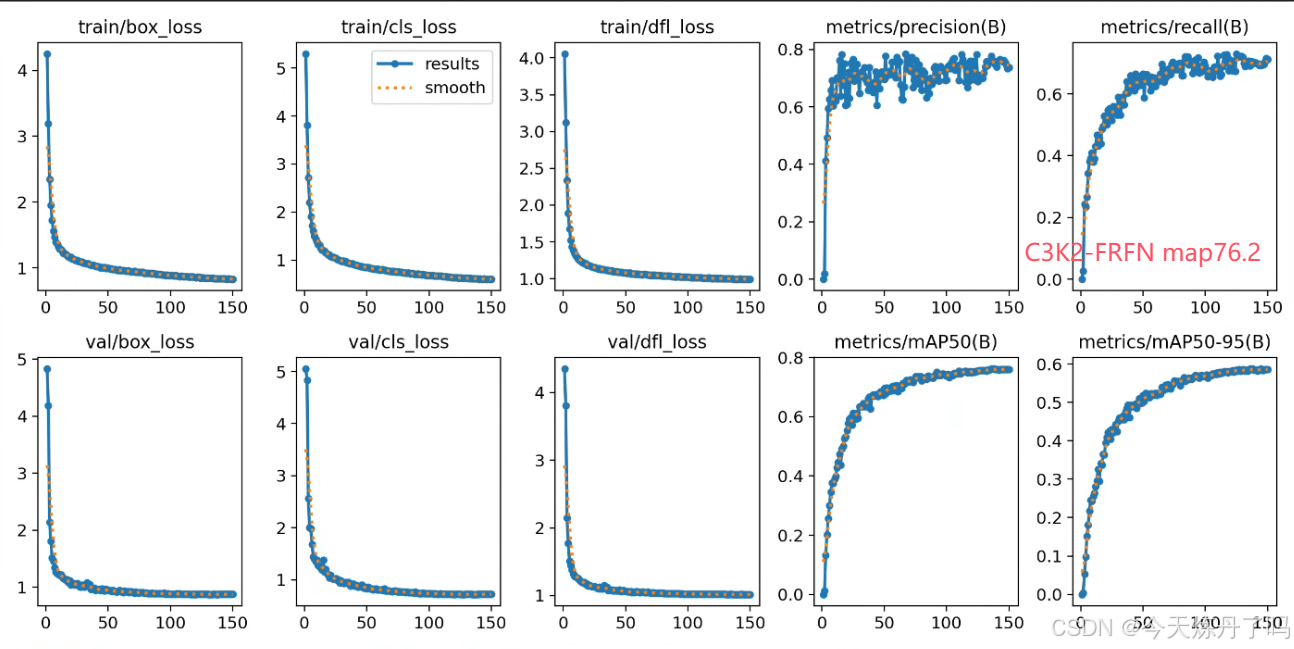
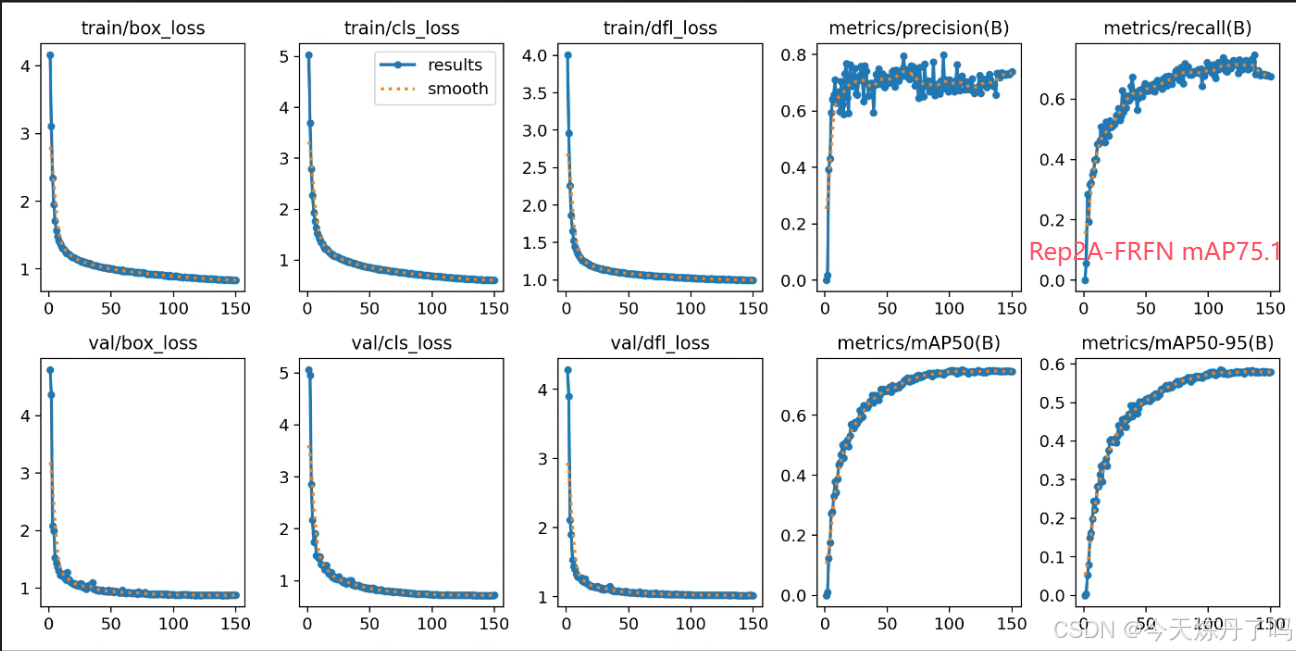
三、相关改进思路(代码见2024/11/8群文件)
根据FRFN的特性,可以使用该模块与C2f、C3、C3K2等模块融合,相关结构图如下。相关自研模块与该模块融合代码见群文件。上百种深度学习改进模块,欢迎点击下方小卡片与我联系。

⭐另外,融合上百种深度学习改进模块的YOLO项目仅119(含百种改进的v9),RTDETR119,含高性能自研模型,更易发论文,代码每周更新,欢迎点击下方小卡片加我了解。⭐



















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









