







1.记录一下nuscenes数据集的格式,参考了nuScenes数据集标注格式以及nuscenes官网教程。
2.v1.0-mini总共有如下几个json文件:
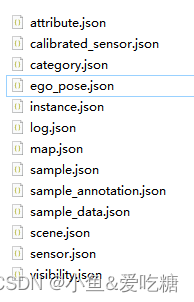
3.总的解释一下:
attribute.json:描述了物体本身的一些状态,比如行驶、停下等等。
calibrated_sensor.json:在特定车辆上校准的特定传感器(激光雷达/雷达/摄像头)的定义。 所有外在参数都相对于自我车身框架给出。 所有相机图像均未失真和校正。
category.json:对象类别的分类(例如车辆、人类)。
ego_pose.json:相机所在车的标注信息。
instance.json:以实例为单位,记录某个实例出现的帧数、初始token、结尾token等。
log.json:一些场景、日期的日志信息。
map.json:地图相关的一些标注信息,数据集的map文件夹里面会包括map的图片。
sample.json:照片的标注,以照片为单位,一张照片对应一个sample。
sample_annotation.json:保存了物体的标注信息。
sample_data.json:sample对应的简单信息,不包括标注,可以索引出同一个物体前后帧的信息。
scene.json:场景数据。场景是从日志中提取的 20 秒长的连续帧序列。
sensor.json:保存所有传感器的数据表,包含一些简单的传感器类型。
visibility.json:描述一个物体可视的程度,即被遮挡、截断的程度。
4.分开解释:
attribute.json:描述了物体本身的一些状态,比如行驶、停下等等。
{
"token": <str> -- 唯一标识.
"name": <str> -- 属性名称
"description": <str> -- 属性详细描述
}
calibrated_sensor.json:在特定车辆上校准的特定传感器(激光雷达/雷达/摄像头)的定义。 所有外在参数都相对于自我车身框架给出。 所有相机图像均未失真和校正。
{
"token": <str> -- 唯一标识
"sensor_token": <str> -- 从sensor.json中对应得到相机类型
"translation": <float> [3] --相机外参,偏移矩阵,单位为米.
"rotation": <float> [4] -- 相机外参,四元数旋转角
"camera_intrinsic": <float> [3, 3] -- 相机内参(似乎只有camera会有)
}
category.json:对象类别的分类(例如车辆、人类)。
{
"token": <str> -- 唯一标识
"name": <str> -- 物体类别名称
"description": <str> -- 类别详细描述
"index": <int> -- The index of the label used for efficiency reasons in the .bin label files of nuScenes-lidarseg. This field did not exist previously.
}
ego_pose.json:相机所在车的标注信息
{
"token": <str> -- 唯一标识
"translation": <float> [3] --Unix时间戳,应该是保存数据表时候的一个时间戳,怀疑与图片名的后缀一一对应,没有详细考证
"rotation": <float> [4] -- 车辆外参,四元数旋转角.
"timestamp": <int> -- 车辆外参,偏移矩阵,单位为米
}
ego车辆,还有照片中其他车辆(sample_annotation.json)的外参,参考坐标系是世界坐标系,世界坐标系的原点是lidar或radar定义的,没有什么规律,所以要求其他车辆的相机坐标系坐标,就需要在这三个外参(ego、camera、sample)换算一下。
instance.json:以实例为单位,记录某个实例出现的帧数、初始token、结尾token等。
instance {
"token": <str> -- 唯一标识
"category_token": <str> -- 类别标识,可以找到category.json里的对应类别
"nbr_annotations": <int> -- 出现的数量,即该实例在此数据集一共出现了多少帧
"first_annotation_token": <str> -- 第一帧的annotation标识,在sample_annonation.json里可以找到对应标注,下同
"last_annotation_token": <str> -- 最后一帧的annotation标识
}
log.json:一些场景、日期的日志信息。
{
"token": <str> -- 唯一标识
"logfile": <str> -- 日志文件
"vehicle": <str> -- 车辆名称
"date_captured": <str> -- 拍摄日期
"location": <str> -- 拍摄地点
}
map.json:地图相关的一些标注信息,数据集的map文件夹里面会包括map的图片。
map {
"token": <str> -- 唯一标识
"log_tokens": <str> [n] -- 地图中的日志文件
"category": <str> -- 地图类别,似乎都是sematic的,因为提供的地图图片都是分割的,Nuscenes本身也包括了道路分割的数据集
"filename": <str> -- 对应的地图文件名
}
sample.json:照片的标注,以照片为单位,一张照片对应一个sample。关键帧
{
"token": <str> -- 唯一标识
"timestamp": <int> -- 时间戳
"scene_token": <str> -- 场景标识,从scene.json中对应唯一场景
"next": <str> -- 下一张照片的token
"prev": <str> -- 上一张照片token
}
sample_annotation.json:保存了物体的标注信息。
{
"token": <str> -- 唯一标识
"sample_token": <str> -- 从sample.json中索引出唯一对应的sample
"instance_token": <str> -- 从instance.json中索引出唯一对应的instance
"attribute_tokens": <str> [n] -- 从attribute.json中索引出唯一对应的attribute
"visibility_token": <str> -- 从visibility.json中索引出唯一对应的visibility
"translation": <float> [3] -- 物体外参,偏移矩阵,单位为米
"size": <float> [3] -- 物体大小,单位为米,顺序为宽、长、高
"rotation": <float> [4] -- 物体外参,四元数旋转矩阵
"num_lidar_pts": <int> -- bbox中出现的lidar点数量,下同
"num_radar_pts": <int> -- bbox中出现的radar点数量
"next": <str> -- 下一帧的标注token
"prev": <str> -- 同一个物体,上一帧标注的token,在本数据表中索引出唯一对应的标注信息,上同
}
sample_data.json:sample对应的简单信息,不包括标注,可以索引出同一个物体前后帧的信息。
{
"token": <str> -- 唯一标识
"sample_token": <str> -- 可以从sample.json中索引出唯一对应的sample
"ego_pose_token": <str> -- 对应的ego车辆的token,可以从ego_pose中索引出来,据我观察,1和3都是相同的
"calibrated_sensor_token": <str> -- 可以从calibrated_sensor.json中索引出对应的相机外参和内参,3和4就对应索引出上文所说的ego和camera的外参,sample的外参并不在这个表里,而是在sample_annotation.json中,见下文
"filename": <str> -- Relative path to data-blob on disk.
"fileformat": <str> -- 文件格式,照片和雷达格式
"width": <int> -- 同下,像素宽度,都是1600;
"height": <int> -- 照片像素高度,似乎只有jpg才会有,都是900
"timestamp": <int> -- 时间戳
"is_key_frame": <bool> -- 是否是关键帧,Nuscenes中,每秒两帧关键帧,提供标注信息
"next": <str> -- 下一个sample_data的token
"prev": <str> -- 上一个sample_data的token,从本数据表中可以索引出对应的数据,是同一个物体的上一个标注,即上一次出现这个物体是在哪里,下同
}
scene.json:场景数据。场景是从日志中提取的 20 秒长的连续帧序列。
scene {
"token": <str> -- 唯一标识
"name": <str> -- 场景名
"description": <str> -- 场景描述
"log_token": <str> -- 日志token,从log.json索引出对应日志
"nbr_samples": <int> -- 场景中出现的sample的数量,就是该场景下一共出现过多少个标注的物体,同一物体就算一次
"first_sample_token": <str> -- 第一个sample的token,从sample.json中可以索引出唯一sample,下同
"last_sample_token": <str> -- 场景下的最后一个sample
}
sensor.json:保存所有传感器的数据表,包含一些简单的传感器类型。
sensor {
"token": <str> -- 唯一标识
"channel": <str> -- 位置
"modality": <str> {camera, lidar, radar} -- 类型
}
visibility.json:描述一个物体可视的程度,即被遮挡、截断的程度。
visibility {
"token": <str> -- 唯一标识
"level": <str> -- 可视化级别,是一个百分数,越高则越清晰,即识别越简单
"description": <str> -- 详细描述。一共有4个等级,分别是0到40%,40到60%,60到80%,80到100%
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









