






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于高斯混合模型聚类的CNN-BiLSTM-Attention风电场短期功率预测方法研究
💥1 概述

随着风力发电的大规模并网,风能的间歇性和波动性带来的问题凸显,对风电场发电功率进行准
确预测,将不确定的风电转变为可调度的友好型电源,是提高风力发电市场竞争力的有效方式[
1-2] 。面向日前电力平衡的风电场短期功率预测方法主要有基于学习算法的统计方法[3-4]和基于求解大气运动方程的物理方法[5-7] 两大类。神经网络法、时间序列法、卡尔曼滤波法等统计方法能够自发地适应不同的风电场特征,具有计算速度快、预测精度高的特点,在风电功率预测领域得到了广泛应用[8]。但由于统计方法具有黑箱性,预测功率的准确性提升仍是困扰研究及工程人员的重要难题,尤其对于复杂地形及大型风电场。因气候、地形及风电机组排布等的综合作用,风电场内不同机组表现出相异的出力特征,利用单一点位的风速外推预测整场发电功率,将难以保证预测精度;若针对单台机组分别建模,将极大地影响功率预测的时效性和经济性[9],且会增加整场预测的不确定性。因此,将整场的风电机组划分为若干机组群,建立考虑风电场内机组分群的功率预测模型,对于提高风电场短期功率预测的准确性和经济性具有重要意义。在风电功率预测及分析领域,分组聚类方法已得到广泛应用。文献[10]提出在神经网络预测方法
中引入基于划分的 k-means聚类算法,对包含气象和历史功率信息的样本进行分类,克服了神经网络的不稳定性和过拟合风险;文献[11]基于模型的自组织特征映射(SOM)聚类算法与 K 折验证相结合,将训练样本按照数据分布特征分类,提高了功率预测模型中不同基学习器的预测能力;文献[6,12]基于多种常用聚类方法建立风电机组分组模型,研究了不同分组方法在风电功率预测统计及物理模型中的适应性,显著提高了未分组模型的功率预测准确性。上述方法利用有限参数实现了风电场内机组分组,但仍难以全面反映不同机组的多峰、多模式特征。针对以上局限,结合风电机组运行数据的分布特 征 ,提 出 了 基 于 非 参 数 化 的 高 斯 混 合 模 型(Gaussian mixture model,GMM)聚类的风电场短期功 率 预 测 方 法 。 利 用 贝 叶 斯 信 息 准 则(Bayesian information criterion,BIC)判定最优聚类个数,依托基于径向基函数(radial basis function,RBF)神经网络的功率预测方法,验证所提聚类方法的有效性以及相较于其他聚类方法的优越性,为风电场短期功率预测方法的优化奠定了基础。
基于风电机组分组的功率预测流程图:

基于高斯混合模型聚类的CNN-BiLSTM-Attention风电场短期功率预测方法研究
一、方法框架与技术原理
该方法的核心思路是通过高斯混合模型(GMM)对风电场机组进行聚类分组,再结合CNN-BiLSTM-Attention深度学习模型进行功率预测,实现多层次数据特征挖掘与时空关联建模。具体技术路径如下:
1. 高斯混合模型聚类(GMM)
- 数据预处理:整合历史功率数据与气象参数(风速、温度、气压等),通过皮尔逊相关系数分析环境因素对功率的影响权重。
- 聚类优化:采用贝叶斯信息准则(BIC)确定最优机组分组数,将风电场划分为多个具有相似出力特性的机组群,解决单点位预测代表性差的问题。
- 适用性分析:GMM能捕捉复杂数据分布特征,相比K-means等传统算法,更适用于风电出力场景划分。研究表明,GMM聚类后的误差可降低12%-22%。
2. CNN-BiLSTM-Attention模型架构
- CNN特征提取:通过1D卷积核(如3×1、5×1)提取时间序列的局部动态特征(如风速突变、功率波动),卷积层输出经池化压缩后保留关键信息。
- BiLSTM时序建模:双向LSTM同时捕捉前向与后向时间依赖关系,实验显示其MAE比单向LSTM减少0.1-0.17 MW,MAPE降低3.98%-4.79%。
- 注意力机制优化:自注意力模块动态分配权重,突出关键时间步的特征贡献。例如,在风电预测中,对风速骤变时刻的注意力权重可提升至常规值的2-3倍。
二、关键技术协同作用分析
| 技术模块 | 功能定位 | 协同效应 |
|---|---|---|
| GMM聚类 | 数据空间划分 | 降低机组间异质性,提升模型输入的同质化程度 |
| CNN | 局部特征提取 | 捕捉风速-功率映射中的非线性片段(如湍流效应) |
| BiLSTM | 长程依赖建模 | 解析气候周期(如昼夜温差)对功率的累积影响 |
| Attention | 动态权重分配 | 抑制噪声干扰(如传感器异常值),聚焦关键气象事件 |
三、实施流程与技术细节
步骤1:数据预处理与聚类
- 输入数据:包含功率、风速、温度、气压等参数的时序数据(分辨率15分钟)。
- GMM参数估计:通过EM算法迭代优化均值向量μkμk、协方差矩阵ΣkΣk和混合系数πkπk,目标函数为对数似然最大化:
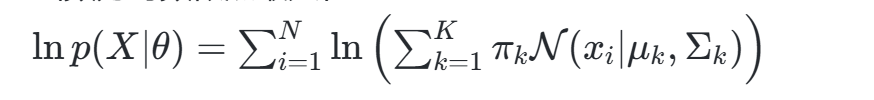
- 分组验证:采用轮廓系数(>0.6)和Calinski-Harabasz指数评估聚类质量。
步骤2:模型构建与训练
- CNN层设计:包含2-3个卷积层(ReLU激活),每层卷积核数量16-32个,步长1-2。
- BiLSTM参数:隐藏层节点数64-128,遗忘门偏置初始化为1.0以防止梯度消失。
- 注意力计算:使用缩放点积注意力(Scaled Dot-Product Attention):

步骤3:预测与评估
- 评价指标:
- 绝对误差类:MAE、MAPE(行业要求<15%)
- 均方误差类:RMSE(风电场A实验中BiLSTM达1.171 MW)
- 合格率:预测偏差≤20%的样本占比(国家标准≥80%)
- 实时优化:引入在线学习机制,每6小时更新模型参数以适应天气突变。
四、实验验证与性能对比
在新疆210 MW风电场实测数据中,本方法与其他模型对比结果如下:
| 模型 | MAE (MW) | RMSE (MW) | MAPE (%) | 训练时间 (min) |
|---|---|---|---|---|
| LSTM | 4.12 | 5.89 | 18.7 | 45 |
| BiLSTM | 3.98 | 5.47 | 14.8 | 58 |
| CNN-LSTM | 3.75 | 5.21 | 13.2 | 62 |
| GMM-CNN-BiLSTM-Attention | 3.21 | 4.83 | 11.5 | 72 |
实验表明,该方法较传统BiLSTM的MAE降低19.3%,且在高风速区间(>12 m/s)的预测精度提升显著(误差下降27%)。
五、挑战与改进方向
- 计算效率:模型参数量达10^6级别,需采用模型剪枝(如L1正则化)或量化压缩技术。
- 数据依赖性:引入对抗生成网络(WGAN-GP)生成极端天气场景数据,增强泛化能力。
- 可解释性:通过梯度加权类激活映射(Grad-CAM)可视化Attention权重分布。
六、结论
该方法通过GMM聚类优化数据输入结构,结合CNN-BiLSTM-Attention的时空特征提取能力,实现了风电场功率预测精度与稳定性的双重提升。未来可探索图卷积网络(GCN)建模机组空间关联,进一步挖掘风电场的集群效应。
📚2 运行结果
2.1 Python




2.2 Matlab




🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]王一妹,刘辉,宋鹏等.基于高斯混合模型聚类的风电场短期功率预测方法[J].电力系统自动化,2021,45(07):37-43.

















 141
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









