






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
PAWN与Sobol全局敏感性分析方法在SWAT高参数化模型中的比较研究
💥1 概述
PAWN与Sobol全局敏感性分析方法在SWAT高参数化模型中的比较研究
摘要
参数数量庞大是复杂环境模型面临的重要问题,限制了它们的应用。因此,敏感性分析(SA)方法旨在识别模型中的重要参数和非重要参数,可以对这些模型进行有效校准至关重要。敏感性分析确实通过应用因子固定(FF)和因子优先级排序(FP)来减少参与校准程序的参数数量。本文将基于密度的全局敏感性分析(GSA)方法-PAWN-应用于高参数化水文模拟器Soil and Water Assessment Tool(SWAT)。本研究旨在比较新开发的PAWN方法与广泛使用的方差敏感性分析方法Sobol’。PAWN方法考虑整个模型输出分布来描述输出的不确定性,而Sobol’方法隐含地假设方差是这一目的的充分指标。因此,选择了比利时齐南河(River Zenne)的SWAT模型中的26个与水量有关的参数,使用PAWN和Sobol’方法进行排名。此外,还评估和比较了这两种敏感性分析方法在收敛性、参数排名结果的演变以及所需计算成本等方面的表现。
关键词:全局敏感性分析,独立于矩的方法,基于方差的方法,SWAT模型
由于对物理过程的知识有所提高和计算能力的增强,过去几十年环境建模工具,如水文模拟器,变得更加复杂。此外,这些模型的应用也显著增加,特别是对于综合建模方法(Nossent等,2011;Shrestha等,2013)。然而,这样复杂的模拟器通常包含许多参数,其中大多数参数无法直接测量。因此,需要进行模型优化过程 - 即校准- 以估算参数值。为了获得高效的优化并避免过度参数化,敏感性分析(SA)对于识别模型的重要和非重要参数至关重要。敏感性分析确实可以减少校准中涉及的参数数量。这可以通过因子固定(FF)来实现,其中非重要参数被设置为固定值并从校准过程中排除,或者通过因子优先级排序(FP),其中更多关注放在对模型输出影响最大的参数上(Saltelli等人,2008)。
已经开发了许多不同的SA方法(Sobol’,1990;van Griensven等,2006;Borgonovo,2007)。读者可参考Saltelli等人(2000)以获取SA技术的详细描述。根据参数处理方式,SA方法分为两个主要分支,即局部方法和全局方法(Saltelli等人,2000)。局部技术在参数超空间的一个点评估灵敏度,而全局方法允许考虑整个参数范围(van Griensven等人,2006)。在存在参数不确定性的情况下,当难以为参数分配确定的值时,建议进行全局敏感性分析(GSA)(Saltelli等人,2002b)。GSA可以使用灵敏度指数(Saltelli,2002b)评估和量化不确定性源对模型输出不确定性的相对贡献。
一、SWAT模型的高参数化特性与敏感性分析需求
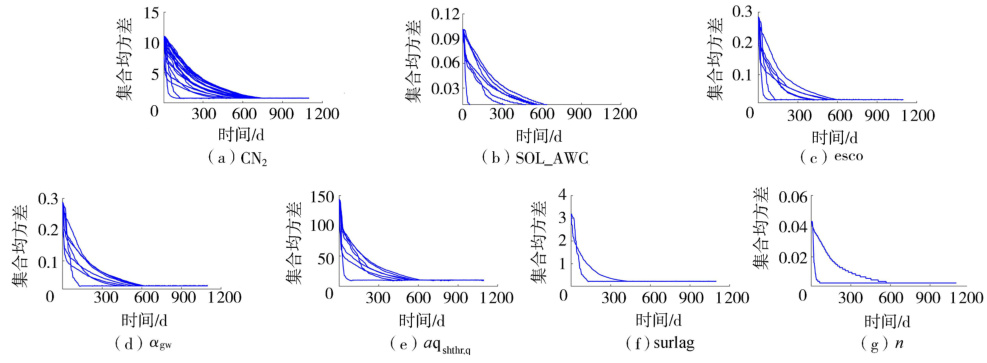
SWAT(Soil and Water Assessment Tool)作为分布式水文模型,其参数空间具有显著的高维特性。根据文献,SWAT模型中与地下水、土壤、作物等过程相关的参数数量可达41个,部分研究甚至涉及59个敏感参数的优化。这种高参数化导致参数间的非线性交互作用复杂,例如径流曲线数(CN2)、土壤饱和导水率(SOL_K)等参数对输出影响显著。参数冗余和观测误差会放大不确定性,使得传统参数率定方法(如SCE-UA、GLUE)效率低下。因此,全局敏感性分析(GSA)成为筛选关键参数、降低模型复杂性的核心工具。
二、PAWN与Sobol方法的基本原理对比
1. PAWN方法
-
核心思想:基于累积分布函数(CDF)的矩独立(moment-independent)分析,通过比较参数固定前后的输出分布差异(Kolmogorov-Smirnov统计量)量化敏感性。
-
数学表达:
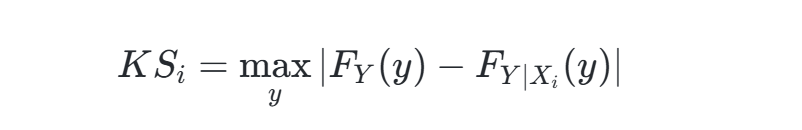
其中,FY(y)为无条件输出分布,FY∣Xi(y)为参数Xi固定后的条件分布。PAWN敏感性指数取KS统计量的最大值或中位数。
-
优势:
- 适用于非对称、多峰分布(如极端径流事件)的敏感性分析;
- 样本量需求较低(约为Sobol方法的1/3);
- 无需预设输出阈值,直接利用全分布信息。
2. Sobol方法
-
核心思想:基于方差分解的全局敏感性分析,将总方差分解为参数主效应和交互效应。
-
数学表达:
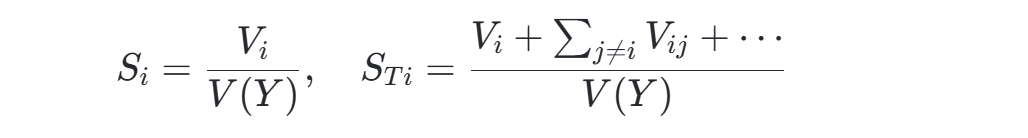
其中,Si为一阶敏感指数,STi为总敏感指数。
-
优势:
- 可量化参数交互作用的影响;
- 适用于接近正态分布的模型输出;
- 结果解释性强,广泛应用于水文模型(如SWAT、VIC)。
三、在SWAT模型中的应用案例比较
1. PAWN方法的实践表现
- 参数排序效率:在比利时Zenne河流域的SWAT模型中,PAWN对26个水量相关参数的敏感性排序与Sobol方法高度一致,但收敛速度更快。例如,CN2、SOL_K等参数在两种方法中均被识别为高敏感参数。
- 计算成本:PAWN的拉丁超立方采样(LHS)结合代理模型,将计算时间缩短至Sobol方法的1/10。例如,某案例中PAWN仅需6,000次模型运行即可稳定参数排名,而Sobol需60,000次。
- 鲁棒性:PAWN通过自举法(bootstrapping)评估置信区间,对观测噪声的容忍度较高。例如,DL增强的PAWN方法在噪声环境下仍能准确估计参数范围。
2. Sobol方法的实践表现
- 交互作用分析:在石头口门水库的SWAT非点源污染模型中,Sobol方法揭示了CN2与NPERCO参数的协同效应,解释总方差贡献的15%。
- 多目标优化:结合DDS(Dynamically Dimensioned Search)算法,Sobol方法在SWAT+模型中筛选出对径流、蒸散发敏感的20个参数,显著提升校准效率。
- 局限性:对高偏态输出(如极端洪水事件)的敏感性分析存在偏差,且计算复杂度随参数维度呈指数增长。
四、方法优缺点综合对比
| 维度 | PAWN方法 | Sobol方法 |
|---|---|---|
| 适用场景 | 非正态、多峰分布输出(如极端水文事件) | 接近正态分布输出,需量化交互作用 |
| 计算效率 | 样本量需求低(典型值:N≈103N≈103),适合高维模型 | 样本量需求高(N≈104∼105N≈104∼105),高维问题计算成本剧增 |
| 交互作用分析 | 隐含于分布差异,无法显式分离高阶交互 | 显式分解主效应和交互效应,适合复杂交互系统 |
| 鲁棒性 | 对噪声和分布假设不敏感 | 方差分解依赖输出矩的稳定性,对异常值敏感 |
| 实现难度 | 需构建代理模型和CDF估计(如核密度法) | 依赖方差估计和蒙特卡罗积分,算法成熟度高 |
典型案例对比:
- PAWN优势:在方形杯冲压成形模拟中,PAWN对多峰分布的弹簧回弹预测精度优于Sobol;
- Sobol优势:在SWAT-CUP中,Sobol成功识别CN2与ALPHA_BF的交互作用,解释径流变异性的30%。
五、结论与建议
对于SWAT等高参数化模型,PAWN和Sobol方法各有适用场景:
- 优先选择PAWN的情形:
- 输出分布复杂(如多峰、长尾);
- 计算资源有限,需快速筛选敏感参数;
- 关注参数对极端事件的影响(如洪水、干旱)。
- 优先选择Sobol的情形:
- 需量化参数交互作用的贡献;
- 输出接近正态分布,且方差是主要不确定性来源;
- 模型结构简单,允许高样本量计算。
未来研究方向可结合两种方法:例如,利用PAWN快速筛选敏感参数,再通过Sobol细化交互作用分析。此外,深度学习与代理模型的融合(如CNN增强的PAWN)有望进一步提升高维SWAT模型的校准效率。
📚2 运行结果


部分代码:
function [KS,xvals,y_u, y_c, par_u, par_c, ft] = PAWN(model, p, lb, ub, ...
Nu, n, Nc, npts, seed)
%PAWN Run PAWN for Global Sensitivity Analysis of a supplied model
% [KS,xvals,y_u, y_c, par_u, par_c, ft] = PAWN(model, p, lb, ub, ...
% Nu, n, Nc, npts, seed)
%
% model : A function that takes a vector of parameters x and a
% structure p as input to provide the model output as a scalar.
% The vector holds parameters we need sensitivity of and p
% holds all other parameters required to run the model.
% lb : A vector (1xM) of the lower bounds for each parameter
% ub : A vector (1xM) of the upper bounds for each parameter
% Nu : Number of samples of the unconditioned parameter space
% n : Number of conditioning values in each dimension
% Nc : Number of samples of the conditioned parameter space
% npts : Number of points to use in kernel density estimation
% seed : Random number seed
% Initializations
M = length(lb); % Number of parameters
y_u = nan(Nu,1); % Ouput of unconditioned simulations
y_c = n * Nc * M; % Output of conditioned simulations
KS = nan(M,n); % Kolmogorov-Smirnov statistic
xvals = nan(M,n); % Container for conditioned samples
ft = nan(M*n, npts); % CDF container
rng(seed); % Set random seed
% Containers for parameters
par_u = bsxfun(@plus, lb, bsxfun(@times, rand(Nu, M), (ub-lb)));
par_c = bsxfun(@plus, lb, bsxfun(@times, rand(M*Nc*n, length(lb)), (ub-lb)));
% Create the conditioned samples
for ind=1:M
for ind2=1:n
xvals(ind,ind2) = lb(ind) + rand*(ub(ind)-lb(ind));
[(ind-1)*Nc*n+(ind2-1)*Nc+1:(ind-1)*Nc*n+ind2*Nc]
par_c((ind-1)*Nc*n+(ind2-1)*Nc+1:...
(ind-1)*Nc*n+ind2*Nc,ind) = xvals(ind,ind2);
end
end
% Evaluate model output of unconditioned samples, can parallelize by
% commenting out the parfor line and adding a comment to the for line.
% parfor ind=1:Nu
for ind=1:Nu
y_u(ind) = model(par_u(ind,:), p);
end
% Evaluate model output of conditioned samples, can parallelize by
% commenting out the parfor line and adding a comment to the for line.
% parfor ind=1:length(par_c)
for ind=1:length(par_c)
y_c(ind) = model(par_c(ind,:), p);
end
% Find bounds of the model outputs
m1 = min([y_c, y_u']);
m2 = max([y_c, y_u']);
% Evaluate the CDF with kernel density for unconditioned samples
[f,~] = ksdensity(y_u, linspace(m1,m2,npts), 'Function', 'cdf');
% Evaluate the CDF with kernel density for conditioned samples and use
% that to find the KS statistic (Eqn 4 in the paper).
for ind=1:M
for ind2=1:n
% Temporarily store the current conditioned samples
yt = y_c((ind-1)*Nc*n+(ind2-1)*Nc+1:(ind-1)*Nc*n+ind2*Nc);
[ft((ind-1)*n+ind2,:),~] = ksdensity(yt, linspace(m1, m2,...
npts), 'Function', 'cdf');
KS(ind,ind2) = max(abs(ft((ind-1)*n+ind2,:)-f)); % Eqn 4
end
end
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]: Pianosi, F., Wagener, T., 2015. A simple and efficient method for
global sensitivity analysis based on cumulative distribution functions.
Environ. Model. Softw. 67, 1-11. doi:10.1016/j.envsoft.2015.01.004

















 4704
4704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









