






本次分享我们邀请到了香港理工大学AiDLab在读博士彭季华,为大家详细介绍他们的工作:

KTPFormer: Kinematics and Trajectory Prior Knowledge-Enhanced Transformer for 3D Human Pose Estimation
直播信息
时间
2024年5月27日(周一)晚上20:00
主题
CVPR'24 | KTPFormer: 3D人体姿态估计SOTA! 在Transformer下即插即用涨点!
直播平台
3D视觉工坊哔哩哔哩
扫码观看直播,或前往B站搜索3D视觉工坊观看直播
嘉宾介绍

彭季华
香港理工大学AiDLab在读博士。研究方向为3D视觉与人体姿态估计。
直播大纲
3D人体姿态估计现有方法简介
CVPR2024论文KTPFormer详解
参与方式

摘要
我们提出了一种运动学和轨迹先验知识强化后的Transformer (KTPFormer)。它克服了现有基于Transformer的3D人体姿态估计方法的一个弱点,即它们的自注意力机制中的Q、K、V向量都是基于简单的线性映射得到的。我们提出了两个先验注意力机制,即运动学先验注意力(KPA)和轨迹先验注意力(TPA)。KPA和TPA利用了人体解剖结构和运动轨迹信息,来促进多头自注意力机制有效地学习关节之间和帧与帧之间的全局依赖关系和特征。KPA通过构建运动学拓扑来建模人体关节之间的运动学关系,而TPA则构建了轨迹拓扑来学习关节在帧与帧之间的运动轨迹信息。通过生成带有先验知识的Q、K、V向量,这两种先验机制使KTPFormer能够同时建模人体关节在空间和时间上的运动关系。在三个基准数据集(Human3.6M、MPI-INF-3DHP和HumanEva)上的实验表明,KTPFormer达到了目前SOTA的结果。更重要的是,我们的KPA和TPA机制具有轻量级的即插即用设计,可以应用到各种基于Transformer的模型(比如diffusion)中,在有效提高模型性能的同时只需要很小的计算开销(大约0.02M)。
方法
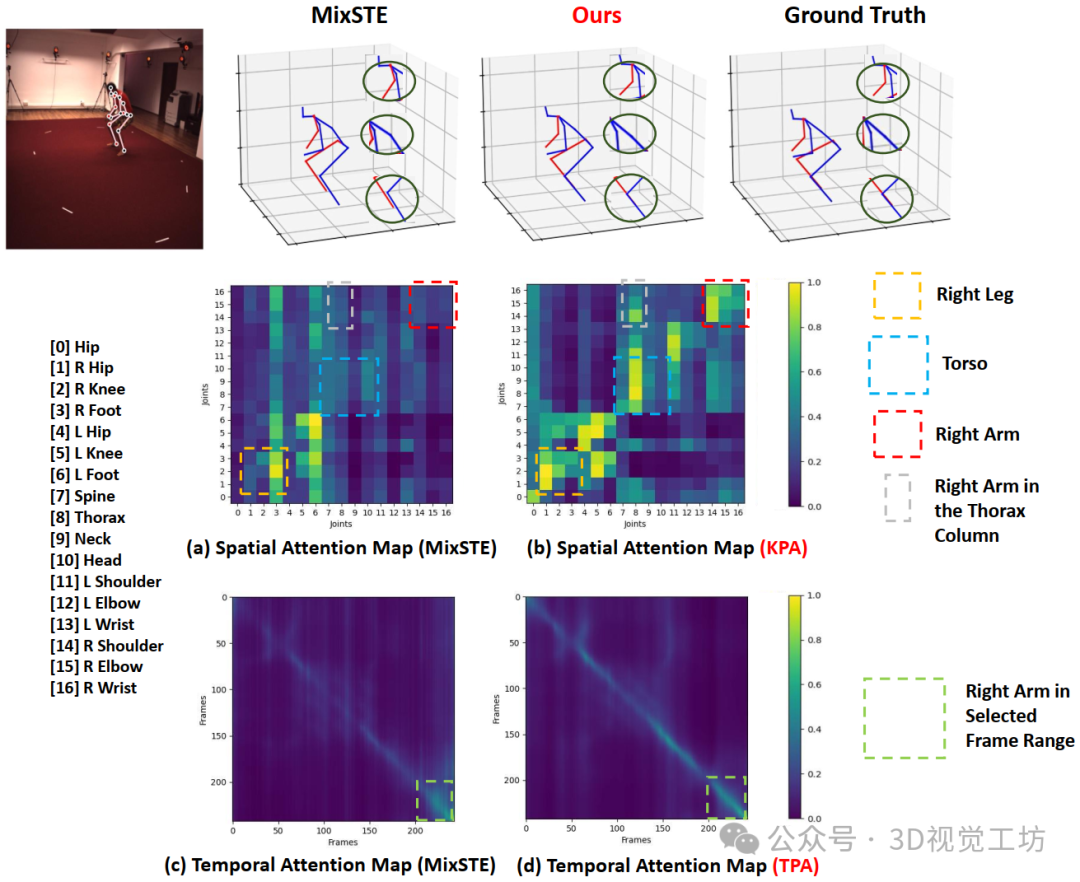
现有基于Transformer的3D人体姿态估计方法主要利用Transformer中的self-attention建模每一帧内关节间的空间相关性以及帧与帧之间的姿态或关节的时间相关性。然而,无论是空间还是时间自注意力的计算,现有的方法都使用线性映射将2D姿态序列转化为高维的tokens,并在空间和时间自注意力机制中统一地处理它们。这会导致在self-attention中出现“attention collapse”的问题,即自注意力过于集中在输入tokens的有限子集上,而忽视了对该token序列其他部分的建模,因为它不知道哪些token之间需要重点关注。
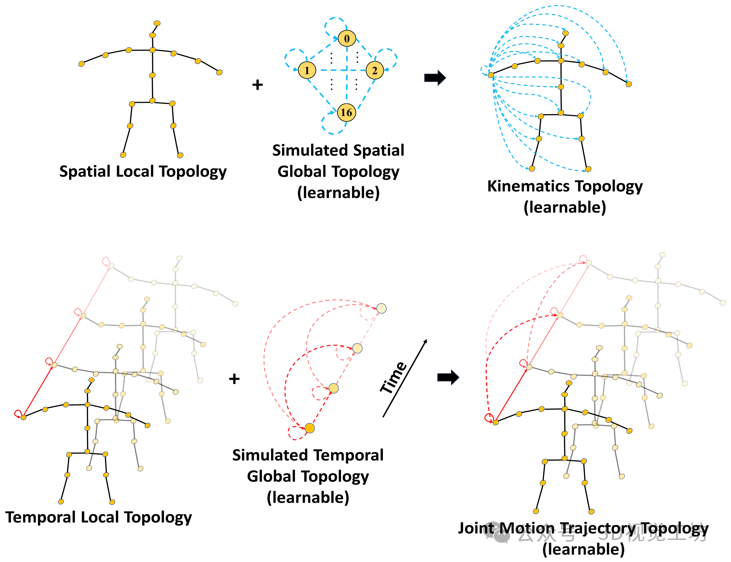
为了解决以上的问题,我们在Transformer中引入了两个先验注意力机制,即运动学先验注意力(KPA)和轨迹先验注意力(TPA),如下图1所示。KPA首先基于人体解剖结构构建了一个空间局部拓扑。这些关节之间的物理连接关系是固定的,用实线表示。为了引入不相邻关节之间的运动学关系,我们使用全连接的空间拓扑来计算每个关节之间的注意力权重,称为模拟的空间全局拓扑。在这个拓扑中,每对关节之间的连接关系是可学习的,因此我们用虚线表示。我们将空间局部拓扑和模拟的空间全局拓扑相结合,就得到了一个运动学拓扑,每个关节都与其他关节有可学习的运动学关系。这个运动学拓扑信息旨在为空间多头自注意力提供先验知识,使其能够根据不同动作中的运动学关系来为空间注意力图分配权重。
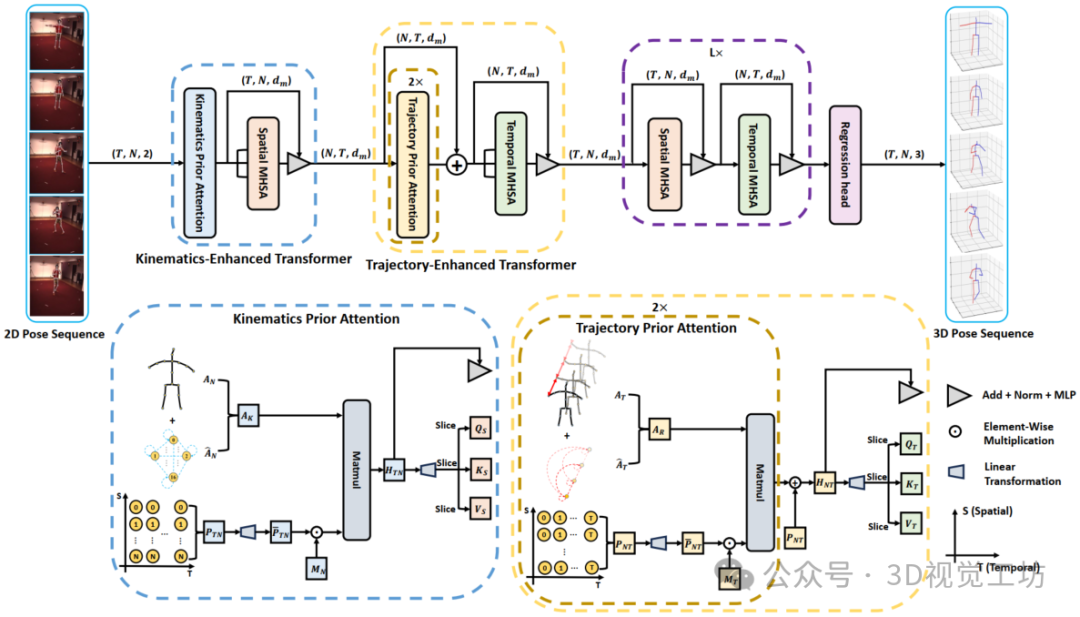
类似地,如图1下方所示,TPA连接了同一个关节在时序上的连续帧,建立时间局部拓扑。接下来,我们利用可学习的向量(虚线)连接所有相邻和非相邻帧中的关节,构建时间全局拓扑,这等同于自注意力机制中所有帧之间注意力权重的计算,我们称为模拟的时间全局拓扑。然后,我们将这两个拓扑结合,得到一个新的关节运动轨迹拓扑。这让网络能同时学习关节运动的时序性和周期性(非相邻帧中的关节在高帧率的视频中具有相似的运动)。嵌入了轨迹信息的时序tokens将在时序自注意力机制中有效地被激活,这增强了自注意力机制的时序建模能力。如图2所示,我们将KPA和TPA这两个先验机制与普通的多头自注意力(MHSA)和MLP相结合,得了一个用运动学和轨迹先验知识增强的Transformer (KTPFormer)。
实验
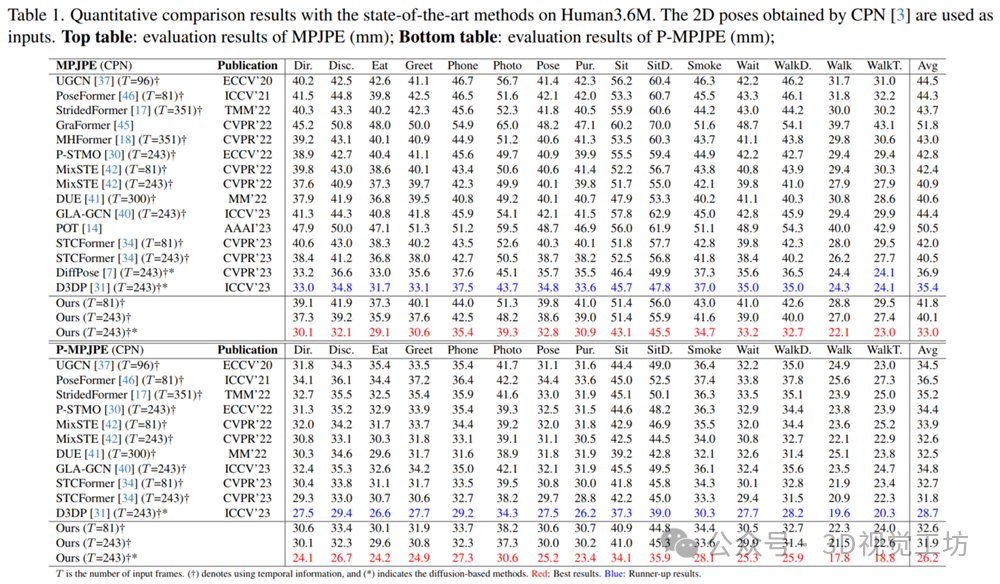
KTPFormer在Human3.6M、MPI-INF-3DHP和HumanEva这三个公开数据集上进行了实验。评估准则主要是计算关节之间的平均预测误差MPJPE,以及预测姿态和ground-truth姿态对齐后的P-MPJPE。如下面表格1和2所示,我们与最近几年的SOTA方法在Human3.6M上进行了比较。我们的KTPFormer以CPN检测的2D poses作为输入,在使用了D3DP[1]提出的diffusion过程后,在MPJPE和P-MPJPE指标上分别达到了33.0mm和26.2mm的SOTA结果。另外,在表格2中,我们以ground-truth 2D poses作为输入,也在MPJPE上达到了SOTA的结果18.1mm。
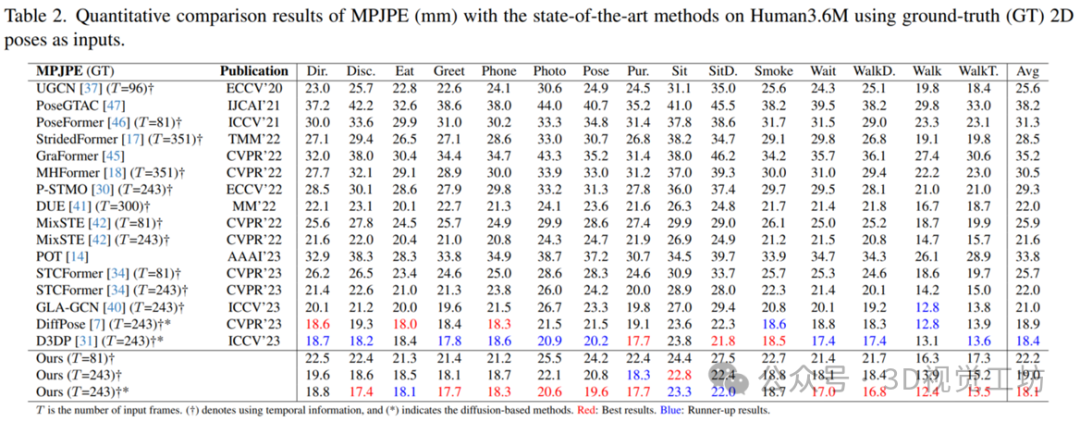
如下面表格3和表格4所示,KTPFormer在MPI-INF-3DHP(带有更复杂的室外场景)和HumanEva(更小的数据集)上也分别取得了目前SOTA的结果。
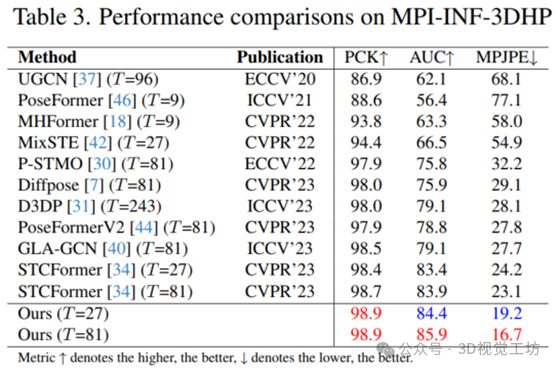
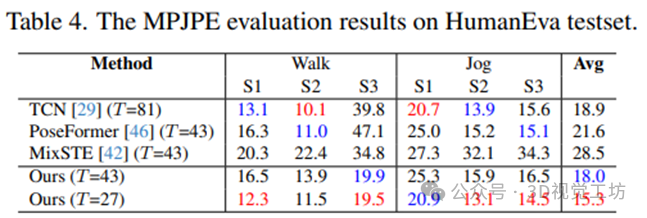
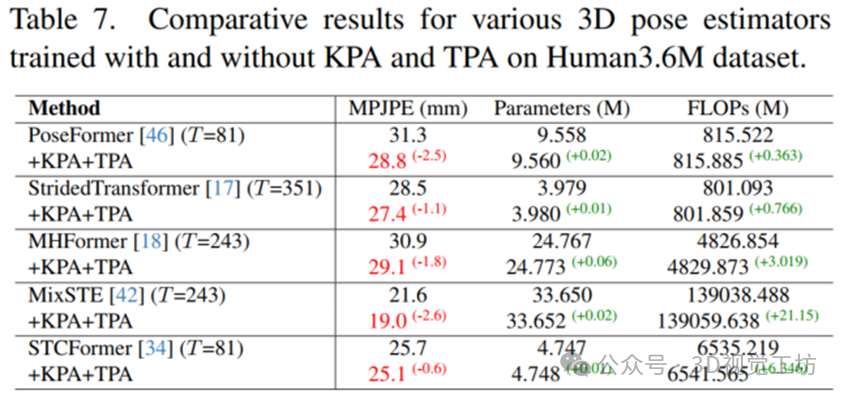
如下表格7所示,我们设计的KPA和TPA先验机制可以以即插即用的方式应用到最近不同的3D姿态预测器中,实现有效地涨点,同时只增加了极少量的参数和FLOPs,体现出了轻量化的设计思想。
如下图所示,KPA可以让空间自注意力机制更合理地在关节之间分配注意力权重;TPA也可以强化时序注意力的时序性和周期性(时序注意力图的对角线变粗表示模型更加关注相邻帧和小范围的不相邻帧之间的运动关系)。
总结
本文提出了一种运动学和轨迹先验知识增强的KTPFormer用于3D人体姿态估计,它包含了两种新颖的先验注意力机制KPA和TPA。它们可以有效增强自注意力机制在建模全局相关性方面的能力。在三个数据集上的实验结果表明,我们的方法能够在计算开销仅略有增加的情况下显著提高性能。此外,我们的KPA和TPA可以作为轻量级的即插即用模块被应用到各种基于Transformer的3D姿态预测模型中,甚至可以被应用到人体动作识别模型中。

[1] Wenkang Shan, Zhenhua Liu, Xinfeng Zhang, Zhao Wang,Kai Han, Shanshe Wang, Siwei Ma, and Wen Gao. Diffusion-based 3d human pose estimation with multihypothesis aggregation. arXiv preprint arXiv:2303.11579, 2023. 2, 5, 6, 7
注:本次分享我们邀请到了香港理工大学AiDLab在读博士彭季华,为大家详细介绍他们的工作:KTPFormer。如果您有相关工作需要分享,欢迎联系:cv3d008

















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









