






ON THE TRAINING AND GENERALIZATION OF DEEP OPERATOR NETWORKS(关于深度算子网络的训练和泛化)
算子网络DeepONet由两个网络构成,即trunk网络和branch网络,通常是同时训练这两个网络,这相当于是在高维空间中解决复杂的优化问题,同时,非凸和非线性的性质也使得训练非常有挑战性。为了解决这个问题,本文提出了一种新的训练方法,即两步训练方法,先训练trunk网络,再训练branch网络,通过将复杂的训练任务分解为两个子任务,降低了复杂度。
首先trunk网络被认为是表示输出函数的基,而branch网络是对应的系数,第一步的目的是在不引入branch网络的情况下,通过trunk网络和相应的系数一起找到基表示,第一步找到的系数对于branch网络来说,是目标值;因此在第二步中,训练branch网络以学习从第一步中得到的值。
2.准备工作
令 Ω x ⊂ R d x \Omega_x\subset\mathbb{R}^{d_x} Ωx⊂Rdx, Ω y ⊂ R d y \Omega_y\subset\mathbb{R}^{d_y} Ωy⊂Rdy是紧区域(区域的任何开覆盖都有有限子覆盖),令 ( X , d X ) (\mathcal{X},d_\mathcal{X}) (X,dX)是定义在 Ω x \Omega{x} Ωx上的函数的度量空间, ( Y , ∥ ⋅ ∥ Y ) (\mathcal{Y},\Vert\cdot\Vert_\mathcal{Y}) (Y,∥⋅∥Y)是定义在 Ω y \Omega_{y} Ωy上的函数的赋范空间.
令
G
:
X
∋
f
↦
G
[
f
]
∈
Y
\mathcal{G}:\mathcal{X}\ni f\mapsto\mathcal{G}[f]\in\mathcal{Y}
G:X∋f↦G[f]∈Y
是用神经网络逼近的算子
首先把
f
f
f转化为有限维的,有两种方法,第一种是固定一组离散化的点
{
x
i
}
i
=
1
m
x
\{x_i\}_{i=1}^{m_x}
{xi}i=1mx,离散
f
f
f为:
第二种是提取
f
f
f的有限多个Fourier系数,例如假设:
其中
f
^
i
=
<
f
,
ϕ
i
>
\hat{f}_i=<f,\phi_i>
f^i=<f,ϕi>,那么就令:
其中 m x m_x mx表示输入函数传感器的数量.
2.1.DeepONet
对于: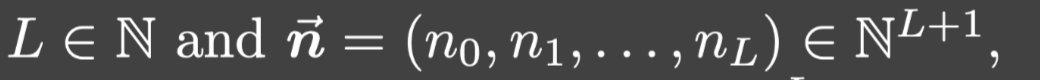
一个L层的神经网络是从:
的映射,其中
z
L
z^L
zL循环定义为:
这里, σ \sigma σ是非线性激活函数, W l ∈ R n l × n l − 1 W^l\in\mathbb{R}^{n_l\times n_{l-1}} Wl∈Rnl×nl−1和 b l ∈ R n l b^l\in\mathbb{R}^{n_l} bl∈Rnl分别是第 l l l层的权重矩阵和偏置向量.向量 n ⃗ \vec{n} n被称为网络结构.
branch网络是一个向量值的
L
b
L_b
Lb层神经网络: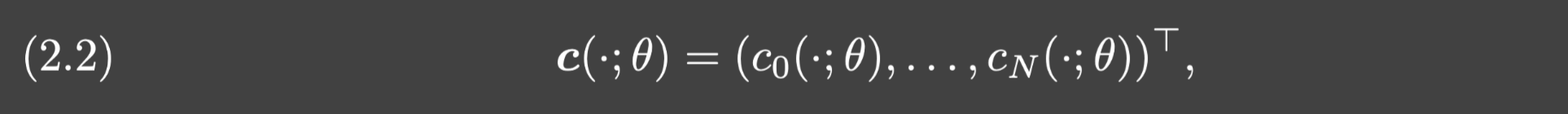
它的结构是:
其中 θ \theta θ表示网络参数,N指的是DeepONet的宽度,即每层神经元的个数.
trunk网络是向量值的
L
t
L_t
Lt层神经网络,它定义在
Ω
y
⊂
R
d
y
\Omega_y\subset\mathbb{R}^{d_y}
Ωy⊂Rdy上: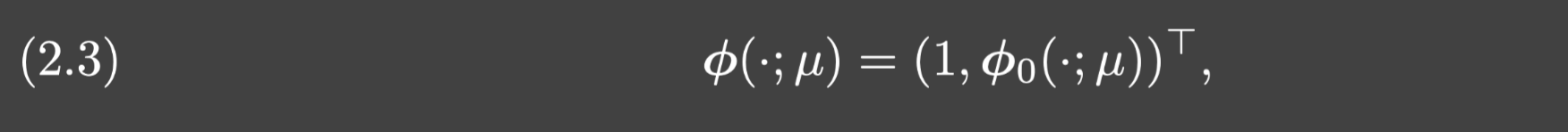
其中 ϕ 0 ( ⋅ ; μ ) = ( ϕ 1 ( ⋅ ; μ ) , ⋯ , ϕ N ( ⋅ ; μ ) ) \phi_0(\cdot;\mu)=(\phi_1(\cdot;\mu),\cdots,\phi_N(\cdot;\mu)) ϕ0(⋅;μ)=(ϕ1(⋅;μ),⋯,ϕN(⋅;μ))是一个 L t L_t Lt层神经网络,它的网络结构是 n ⃗ t = ( d y , n 1 ( t ) , ⋯ , n L t − 1 ( t ) , N ) \vec{n}_t=(d_y,n_1^{(t)},\cdots,n_{L_t-1}^{(t)},N) nt=(dy,n1(t),⋯,nLt−1(t),N),并且 μ \mu μ表示网络参数.
之后,DeepONet被定义为branch网络和trunk网络的内积,即:
其中 Θ = { μ , θ } \Theta=\{\mu,\theta\} Θ={μ,θ}是DeepONet的可训练参数.
2.2. DeepONet的训练
令
{
f
k
}
k
=
1
K
\{f_k\}_{k=1}^K
{fk}k=1K是
X
\mathcal{X}
X中的一组输入函数,
u
k
(
⋅
)
=
G
[
f
k
]
(
⋅
)
u_k(\cdot)=\mathcal{G}[f_k](\cdot)
uk(⋅)=G[fk](⋅)是对应的
Y
\mathcal{Y}
Y中的输出函数.我们希望最小化如下函数: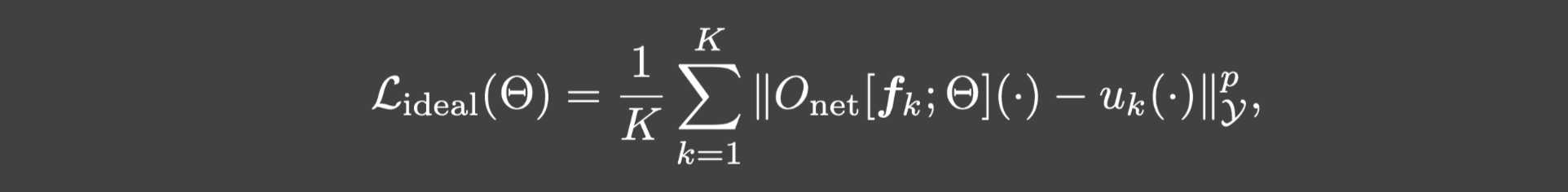
p是一个依赖于 ∥ ⋅ ∥ Y \Vert\cdot\Vert_{\mathcal{Y}} ∥⋅∥Y的正数,例如,如果 ∥ ⋅ ∥ Y \Vert\cdot\Vert_{\mathcal{Y}} ∥⋅∥Y是 L 2 L_2 L2范数,那么p=2.
在实际操作中,我们要将
∥
⋅
∥
Y
\Vert\cdot\Vert_{\mathcal{Y}}
∥⋅∥Y离散化,令
∥
⋅
∥
Y
m
y
\Vert\cdot\Vert_{\mathcal{Y}_{m_y}}
∥⋅∥Ymy是离散范数.所以上述优化问题转换为最小化如下损失函数: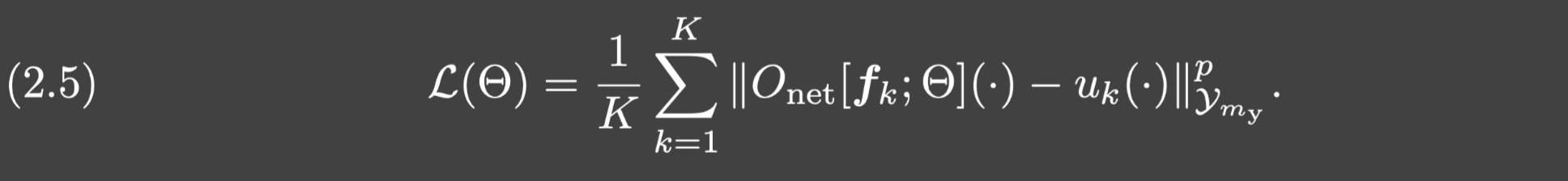
通常优化问题使用一阶优化方法来求解,如随机梯度下降,然而损失函数的非凸性和非线性性经常阻碍这些方法得到令人满意的损失最小化。虽然有很多研究证明了,DeepONet有能力近似许多非线性算子,特别是涉及PDE的算子,但是如果没有有效的训练机制,DeepONet的这种表达能力将失去效果.
3.方法
为了解决上述问题,本文提出了新的训练方法.首先,简单起见,令
Y
=
L
ω
p
(
Ω
y
)
\mathcal{Y}=L_{\omega}^p(\Omega_y)
Y=Lωp(Ωy),相应的范数是: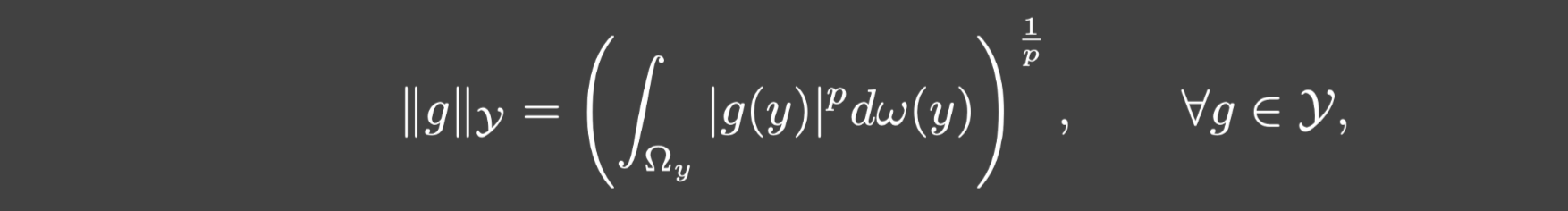
其中
ω
\omega
ω是概率测度,满足:
∫
Ω
y
d
ω
(
y
)
=
1
\int_{\Omega_y}d\omega(y)=1
∫Ωydω(y)=1,并利用蒙特卡洛采样得到它对应的离散范数: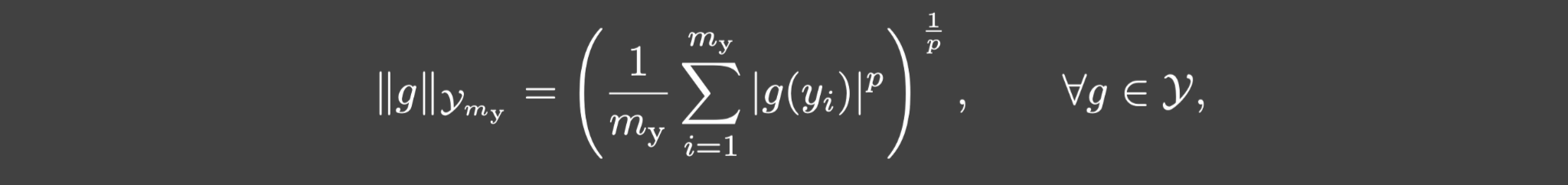
其中 { y i } i = 1 m y \{y_i\}_{i=1}^{m_y} {yi}i=1my是 ω \omega ω的独立同分布的随机样本, m y m_y my是输出函数的传感器个数.
训练数据是: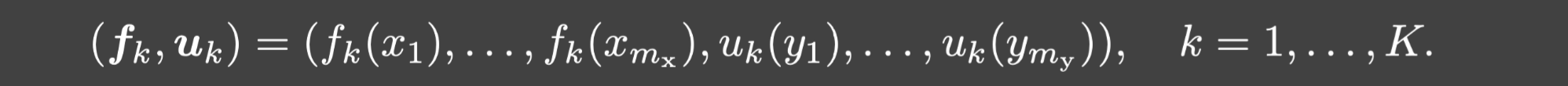
从而由(2.4)可知训练损失函数即为: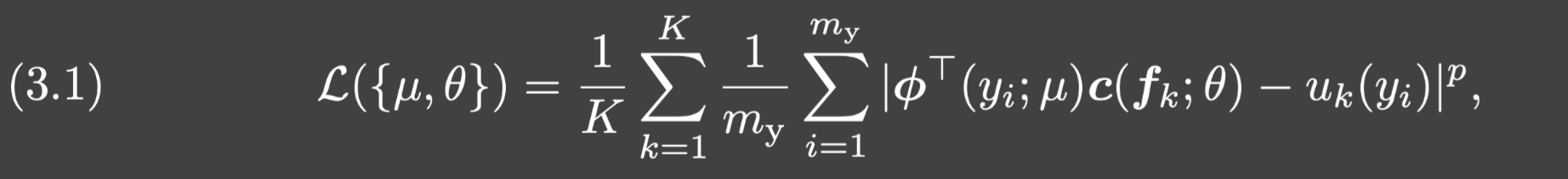
其中 θ \theta θ和 μ \mu μ分别是branch网络和trunk网络的所有网络参数.
3.1. 损失函数的矩阵表示
令: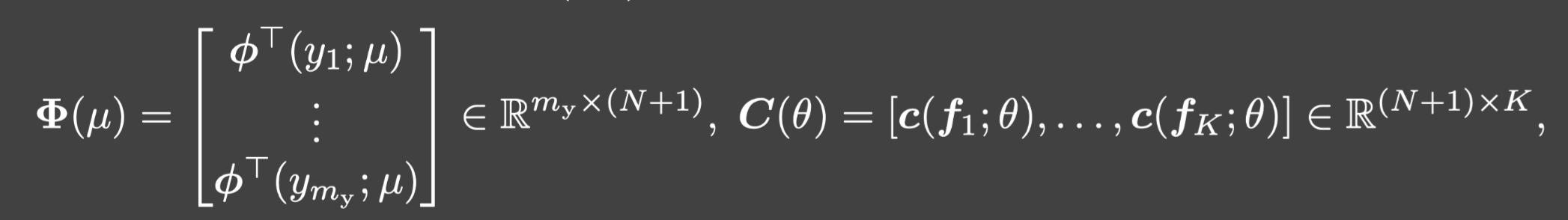
并且 U = [ u 1 , ⋯ , u K ] ∈ R m y × K U=[u_1,\cdots,u_K]\in\mathbb{R}^{m_y\times K} U=[u1,⋯,uK]∈Rmy×K.
从而(3.1)可以表示为: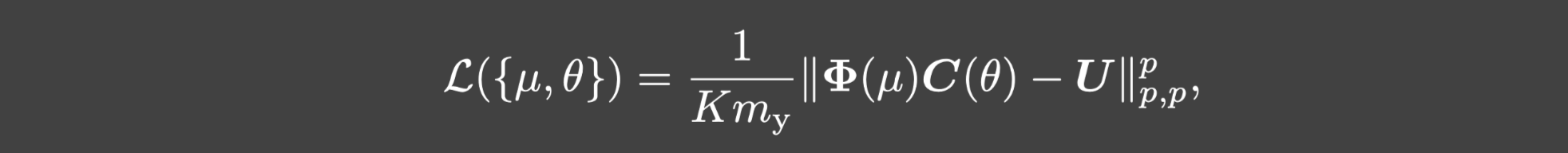
其中
∥
⋅
∥
p
,
p
\Vert\cdot\Vert_{p,p}
∥⋅∥p,p是逐项的矩阵范数(F范数),从而训练DeepONet也就是求解如下优化问题: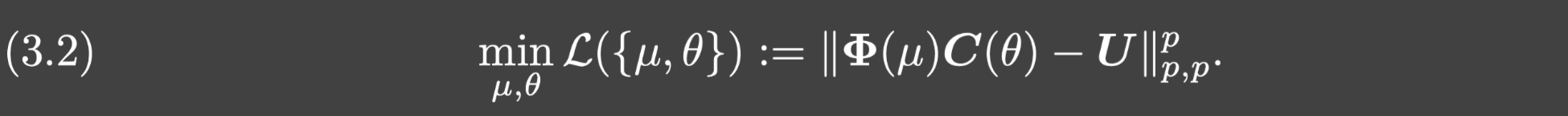
3.2.DeepONet的重新参数化
令T是一个规模是N+1的可训练平方矩阵,并且考虑一个新的trunk网络
ϕ
^
\hat{\phi}
ϕ^,它的形式是: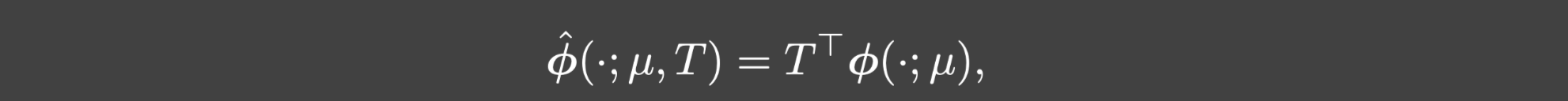
由此产生的DeepONet就是: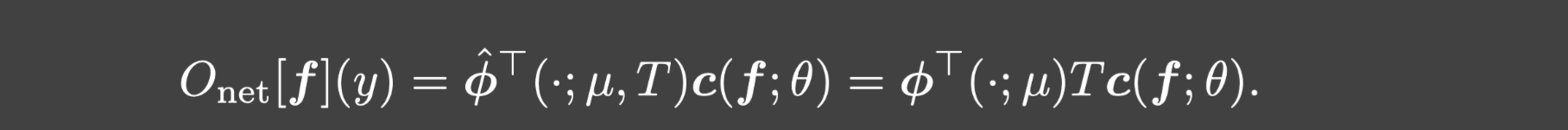
利用这个重参数化,我们考虑如下损失函数: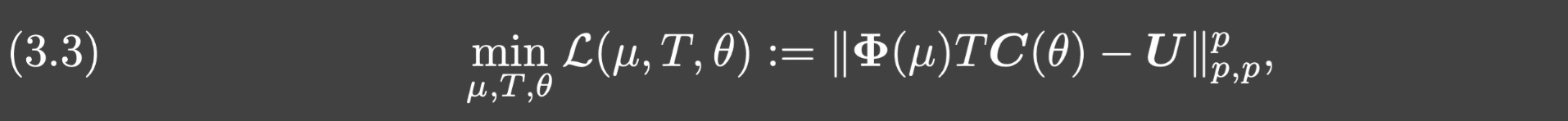
本文所提出的训练方法旨在解决问题(3.3)。注意到 Φ ( μ ) T \Phi(\mu)T Φ(μ)T可以被视为以新的trunk网络 ϕ ^ \hat{\phi} ϕ^为基的类范德蒙矩阵.(?)
3.3 两步训练方法
假设 m y > N m_y>N my>N
Step 1. 第一步通过最小化如下问题来训练新的trunk网络: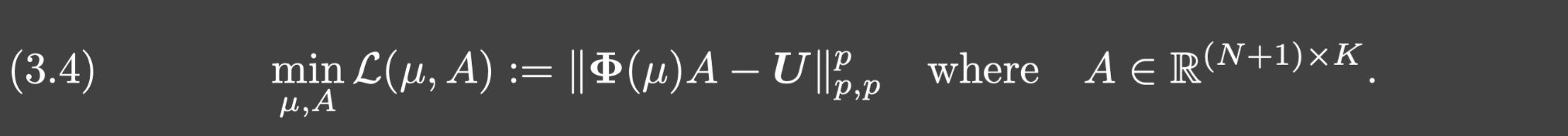
令 ( μ ⋆ , A ⋆ ) (\mu^{\star},A^{\star}) (μ⋆,A⋆)是最优解,假设 Φ ( μ ⋆ ) \Phi(\mu^{\star}) Φ(μ⋆)满秩.令 T ⋆ = ( R ⋆ ) − 1 T^{\star}=(R^{\star})^{-1} T⋆=(R⋆)−1,其中 R ⋆ R^{\star} R⋆是 Φ ( μ ⋆ ) \Phi(\mu^{\star}) Φ(μ⋆)的QR分解,也就是 Φ ( μ ⋆ ) = Q ⋆ R ⋆ \Phi(\mu^{\star})=Q^{\star}R^{\star} Φ(μ⋆)=Q⋆R⋆.从而trunk网络就完全确定为 ϕ ^ ( ⋅ ; μ ⋆ , T ⋆ ) \hat{\phi}(\cdot;\mu^{\star},T^{\star}) ϕ^(⋅;μ⋆,T⋆).
Step 2. 第二步训练branch网络去匹配
R
⋆
A
⋆
R^{\star}A^{\star}
R⋆A⋆,也即考虑如下优化问题: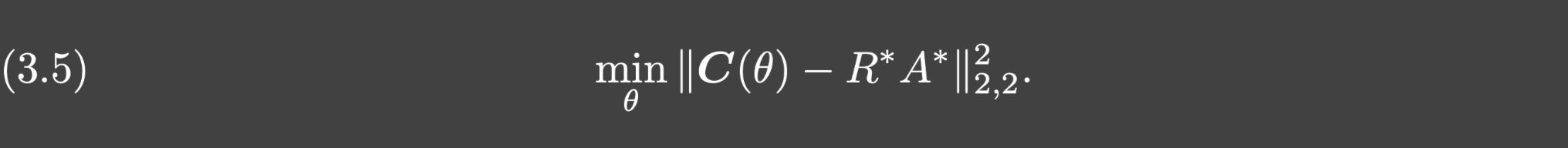
假设 θ ⋆ \theta^{\star} θ⋆是最优解,那么branch网络就是 c ( ⋅ ; θ ⋆ ) c(\cdot;\theta^{\star}) c(⋅;θ⋆).
Remark:由于(3.4)相对于A是凸的(p>1时),所以第一步避免了branch网络的非线性和非凸性带来的困难.
T ⋆ T^{\star} T⋆的作用可以被视为在关于离散点 { y j } \{y_j\} {yj}的标准trunk网络上应用Gram-Schmidt,有没有 T ⋆ T^{\star} T⋆对近似能力没有提升,但是引入 T ⋆ T^{\star} T⋆会显著提高稳定性和泛化能力.
3.4. 误差分析
我们首先证明把(3.4)和(3.5)求解得到的最优解代入(3.3)等于(3.2).
定理3.4. 假设branch网络的结构足够大,使得对于任何
M
∈
R
(
N
+
1
)
×
K
M\in\R^{(N+1)\times K}
M∈R(N+1)×K,都存在
θ
~
\tilde{\theta}
θ~,满足
C
(
θ
~
)
=
M
C(\tilde{\theta})=M
C(θ~)=M.令
(
μ
⋆
,
A
⋆
)
(\mu^{\star},A^{\star})
(μ⋆,A⋆)和
θ
⋆
\theta^{\star}
θ⋆分别是(3.4)和(3.5)的最优解,那么: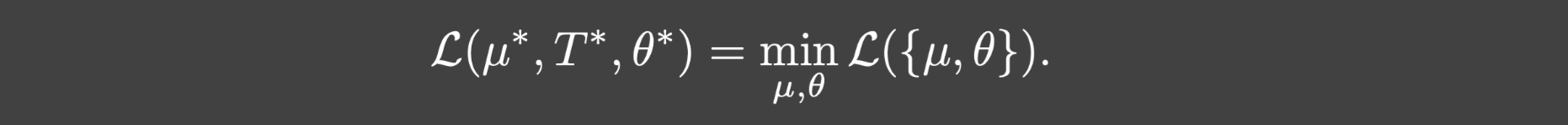
证明: 反正法.若存在
{
μ
^
,
θ
^
}
\{\hat{\mu},\hat{\theta}\}
{μ^,θ^}满足:
令
A
^
:
=
C
(
θ
^
)
\hat{A}:=C(\hat{\theta})
A^:=C(θ^),从而: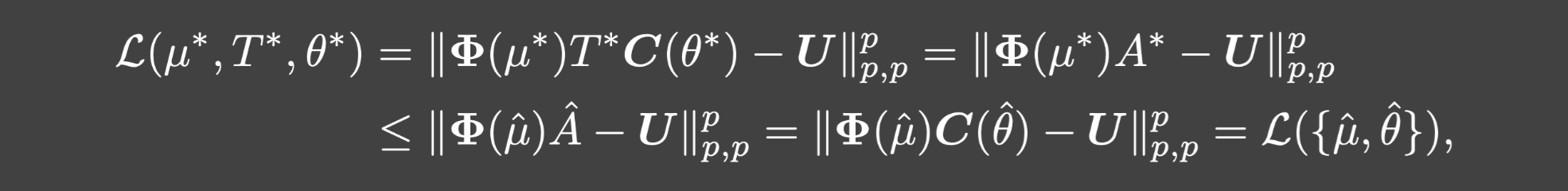
矛盾.
再令
μ
^
=
μ
⋆
\hat{\mu}=\mu^{\star}
μ^=μ⋆和
θ
\theta
θ是branch网络参数满足
C
(
θ
^
)
=
A
⋆
C(\hat{\theta})=A^{\star}
C(θ^)=A⋆.从而: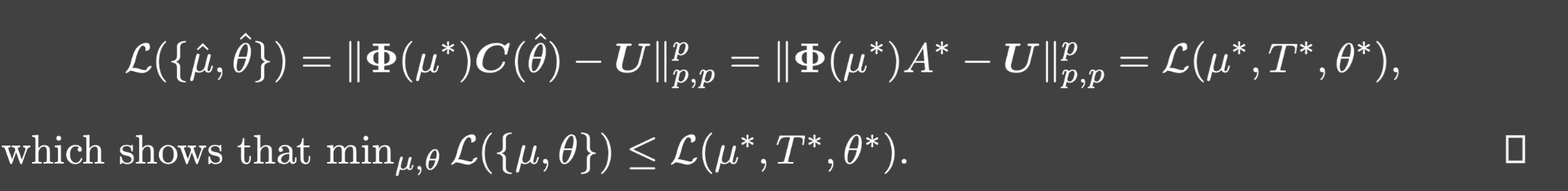
对于trunk网络的训练(3.4),如果恰当选择trunk网络的结构,可以做到Loss为0.
定理3.5. 假设p=2,U的秩为r,并且(2.3)中的trunk网络
ϕ
0
\phi_0
ϕ0是一个
(
2
m
y
+
1
)
(2m_y+1)
(2my+1)层的Relu网络,它的结构如下: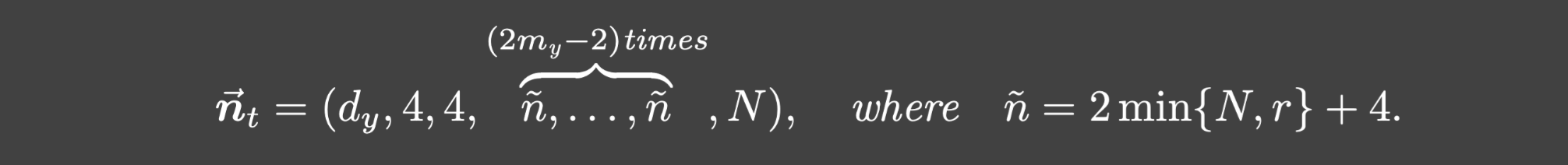
那么就会存在
μ
⋆
\mu^{\star}
μ⋆和
A
⋆
A^{\star}
A⋆满足: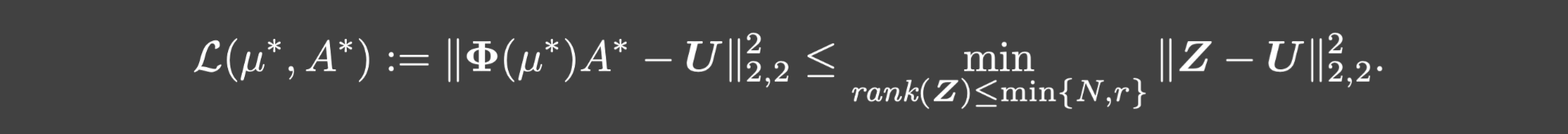
特别的,如果 N ≥ r N\ge r N≥r,那么 L ( μ ⋆ , A ⋆ ) = 0 \mathcal{L(\mu^{\star},A^{\star})=0} L(μ⋆,A⋆)=0.
证明: 令
U
=
Z
Σ
r
V
T
U=Z\Sigma_rV^T
U=ZΣrVT是U的SVD分解.令: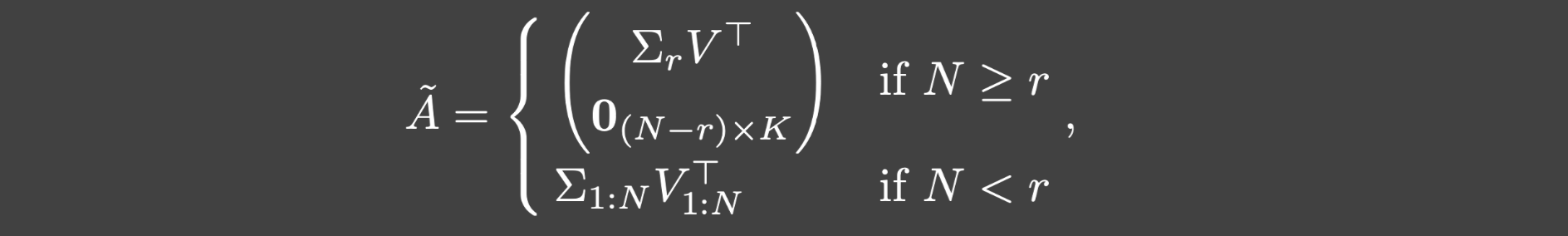
其中
Σ
1
:
s
\Sigma_{1:s}
Σ1:s是
Σ
r
\Sigma_r
Σr的前s阶子矩阵,
V
1
:
s
V_{1:s}
V1:s是V的前s阶子矩阵.可以验证如果trunk网络满足如下条件: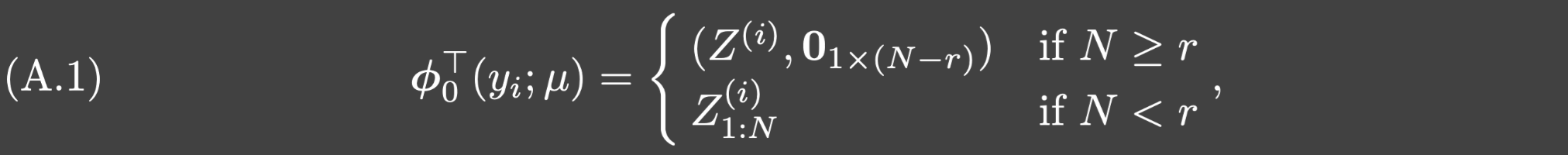
其中 Z ( i ) Z^{(i)} Z(i)是Z的第i行, Z 1 : s ( i ) Z_{1:s}^{(i)} Z1:s(i)是 Z ( i ) Z^{(i)} Z(i)的前s项.那么通过令 A ⋆ = [ 0 ⃗ , A ~ ] A^{\star}=[\vec{0},\tilde{A}] A⋆=[0,A~],则 Φ ( μ ) A ⋆ = Φ 0 ( μ ) A ~ = Z 1 : r ~ Σ 1 : r ~ V 1 : r ~ T \Phi(\mu)A^{\star}=\Phi_0(\mu)\tilde{A}=Z_{1:\tilde{r}}\Sigma_{1:\tilde{r}}V_{1:\tilde{r}}^T Φ(μ)A⋆=Φ0(μ)A~=Z1:r~Σ1:r~V1:r~T,从而可以得证.其中 r ~ = m i n { N , r } \tilde{r}=min\{N,r\} r~=min{N,r}, Φ 0 ( μ ) \Phi_0(\mu) Φ0(μ)的第i行是 ϕ 0 T ( y i ; μ ) \phi_0^T(y_i;\mu) ϕ0T(yi;μ).
接下去我们将显式构造一个深度ReLU网络满足(A.1)
(?????)
定理3.6. 假设trunk网络的结构如定理3.5中所述,且
N
≥
r
N\ge r
N≥r.假设branch网络的结构足够大,以至于对于任何
M
∈
R
(
N
+
1
)
×
K
M\in\R^{(N+1)\times K}
M∈R(N+1)×K,都存在
θ
~
\tilde{\theta}
θ~都满足
C
(
θ
~
)
=
M
C(\tilde{\theta})=M
C(θ~)=M,那么:
**证明:**由定理3.5可知存在
μ
⋆
,
A
⋆
\mu^{\star},A^{\star}
μ⋆,A⋆满足
L
(
μ
⋆
,
A
⋆
)
=
0
\mathcal{L}(\mu^{\star},A^{\star})=0
L(μ⋆,A⋆)=0当
N
≥
r
N\ge r
N≥r时.由于对任何一个矩阵都存在
θ
~
\tilde{\theta}
θ~,使得
C
(
θ
~
)
=
M
C(\tilde{\theta})=M
C(θ~)=M,所以存在
θ
⋆
\theta^{\star}
θ⋆,满足
C
(
θ
⋆
)
=
M
C(\theta^{\star})=M
C(θ⋆)=M.从而: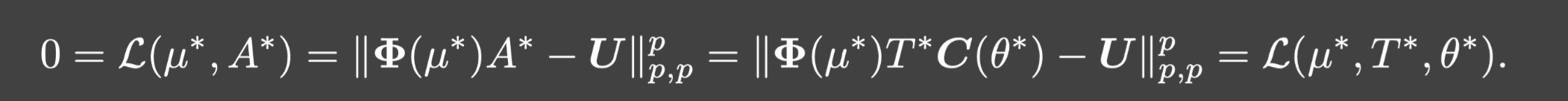
进一步再结合定理3.4可知 0 = L ( μ ⋆ , T ⋆ , θ ⋆ ) = m i n L ( { μ , θ } ) 0=\mathcal{L}(\mu^{\star},T^{\star},\theta^{\star})=min\mathcal{L}(\{\mu,\theta\}) 0=L(μ⋆,T⋆,θ⋆)=minL({μ,θ}).
证毕.
泛化误差分析
泛化误差指的是:令
X
K
=
{
f
1
,
⋯
,
f
K
}
⊂
X
\mathcal{X}_K=\{f_1,\cdots,f_K\}\subset\mathcal{X}
XK={f1,⋯,fK}⊂X是一个函数集,
{
u
j
:
=
G
[
f
j
]
:
j
=
1
,
⋯
,
K
}
\{u_j:=\mathcal{G}[f_j]:j=1,\cdots,K\}
{uj:=G[fj]:j=1,⋯,K}是对应的算子
G
\mathcal{G}
G的输出函数,
O
n
e
t
O_{net}
Onet是完全训练好的DeepONet,对于
f
∈
X
∖
X
K
f\in\mathcal{X}\setminus\mathcal{X}_{K}
f∈X∖XK,那么DeepONet
O
n
e
t
O_{net}
Onet在
f
f
f的泛化误差就是: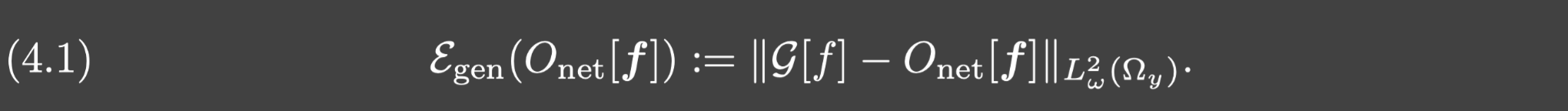
算子学习的最终目标是从有限多个数据中构造一个神经算子 O n e t O_{net} Onet,满足在 X \mathcal{X} X上产生小的泛化误差.
接下去进行泛化误差分析:假设训练数据的数量是 K K K,输入函数传感器的数量 m x m_x mx,输出函数传感器的数量 m y m_y my,DeepONet的宽度 N N N.
让我们考虑一类从
X
\mathcal{X}
X到
Y
=
L
ω
2
(
Ω
y
)
\mathcal{Y}=L_{\omega}^2(\Omega_{y})
Y=Lω2(Ωy)的算子类
C
o
p
\mathcal{C}_{op}
Cop,它有如下谱的形式: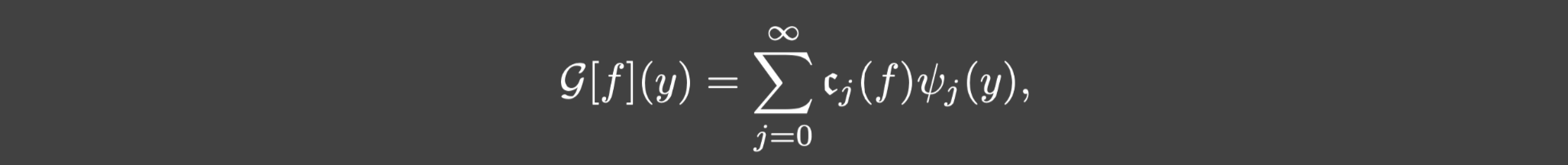
其中
{
c
j
}
\{c_j\}
{cj}是在
X
′
\mathcal{X}'
X′上的
L
j
L_j
Lj-Lipschitz函数,满足: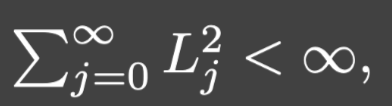
并且
{
ψ
j
(
⋅
)
}
j
\{\psi_j(\cdot)\}_j
{ψj(⋅)}j是
L
ω
2
(
Ω
y
)
L_{\omega}^2(\Omega_{y})
Lω2(Ωy)的正交基,满足: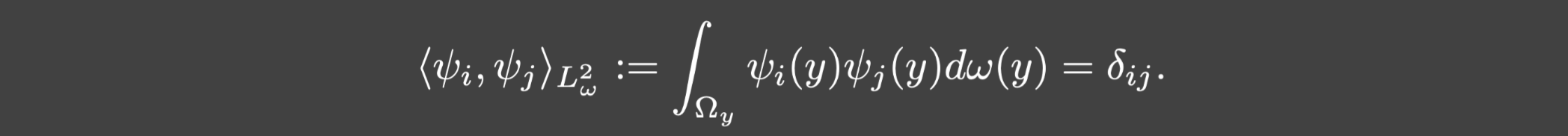
然后可知 C o p \mathcal{C}_{op} Cop中的每个算子都是Lipschitz的.
命题4.1 任何 G ∈ C o p \mathcal{G}\in\mathcal{C}_{op} G∈Cop都是Lipschitz连续的,记 L G L_\mathcal{G} LG是 G \mathcal{G} G的Lipschitz常数.
证明: 对于任何
f
,
f
′
∈
X
f,f'\in\mathcal{X}
f,f′∈X,发现:
证毕.
令: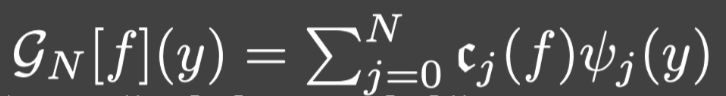
是 G [ f ] \mathcal{G}[f] G[f]的最佳N项逼近.
令:
是对应的最佳N项逼近误差
为了保证最佳N项逼近误差的一致有界性和一致衰减率,下面进行了几个假设.
假设4.2(算子) 对于任何 G ∈ C o p \mathcal{G}\in\mathcal{C}_{op} G∈Cop,假设:
1.存在一个常数M>0,对于任何 f ∈ X f\in\mathcal{X} f∈X,对于几乎每个y,都成立 ∣ G [ f ] ( y ) ∣ ≤ M |\mathcal{G}[f](y)|\le M ∣G[f](y)∣≤M;
2.令: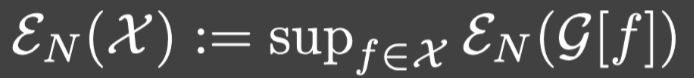
是 X \mathcal{X} X上的最佳N项逼近误差的上确界.
假设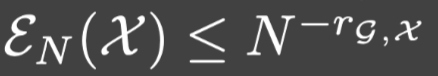 成立,对于某些依赖于
X
,
G
\mathcal{X},\mathcal{G}
X,G和基
{
ϕ
j
}
\{\phi_j\}
{ϕj}的
r
G
,
X
>
0
r_{\mathcal{G},\mathcal{X}}>0
rG,X>0.
成立,对于某些依赖于
X
,
G
\mathcal{X},\mathcal{G}
X,G和基
{
ϕ
j
}
\{\phi_j\}
{ϕj}的
r
G
,
X
>
0
r_{\mathcal{G},\mathcal{X}}>0
rG,X>0.
由于DeepONet需要从无限维空间 X \mathcal{X} X中提取有限维信息作为输入,为了量化需要多少输入函数来填充区域,做出以下假设:
假设4.3(输入函数和传感器) 符号 ≲ \lesssim ≲用于抑制仅依赖于 ( X , d X ) (\mathcal{X},d_\mathcal{X}) (X,dX)的常数.
1.对于除了有限多个
m
x
m_x
mx之外的所有
m
x
∈
N
m_x\in\N
mx∈N,都存在
m
x
m_x
mx个离散化点
{
x
j
}
j
=
1
m
x
∈
Ω
x
\{x_j\}_{j=1}^{m_x}\in\Omega_x
{xj}j=1mx∈Ωx满足: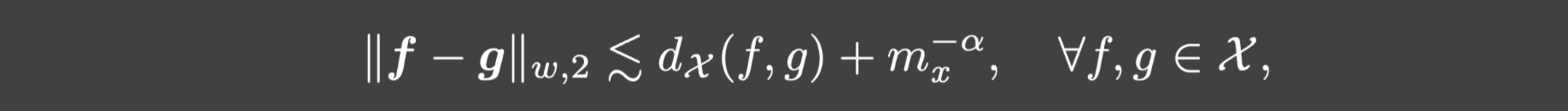
其中 是加权欧几里得范数,
α
>
0
\alpha>0
α>0是一个仅依赖于
X
\mathcal{X}
X的常数.
是加权欧几里得范数,
α
>
0
\alpha>0
α>0是一个仅依赖于
X
\mathcal{X}
X的常数.
2.对于任何
K
∈
N
K\in\N
K∈N,都存在K个输入函数: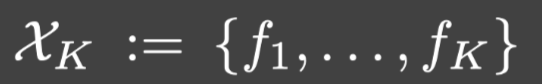
满足对于任何
f
∈
X
f\in\mathcal{X}
f∈X,对于一些仅依赖于
X
\mathcal{X}
X的
s
>
0
s>0
s>0,成立: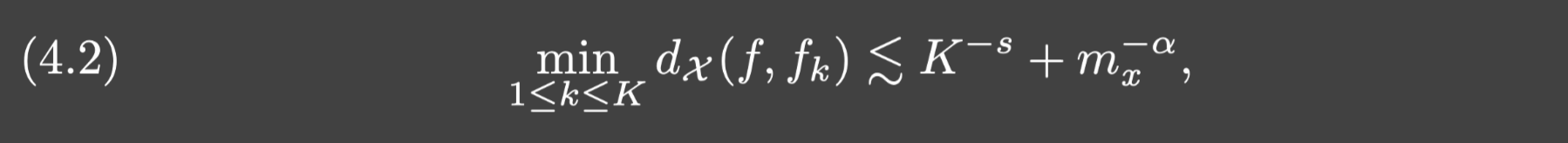
举个例子:令: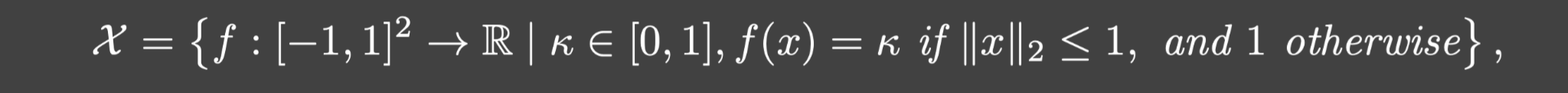
定义一个在
X
×
X
\mathcal{X}\times\mathcal{X}
X×X上的映射
d
X
d_{\mathcal{X}}
dX,满足: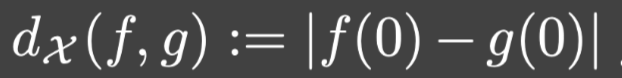
这样定义的映射是一个度量. 对于一个给定的点集
{
x
j
}
j
=
1
m
x
\{x_j\}_{j=1}^{m_x}
{xj}j=1mx,其中存在一个点的2范数小于等于1,并且令
ω
j
=
0
\omega_j=0
ωj=0如果
∥
x
j
∥
>
1
\Vert x_j\Vert>1
∥xj∥>1,
ω
j
=
1
∣
{
x
i
∣
∥
x
i
∥
≤
1
}
∣
\omega_j=\frac{1}{|\{x_i|\Vert x_i\Vert\le 1\}|}
ωj=∣{xi∣∥xi∥≤1}∣1如果
∥
x
j
∥
≤
1
\Vert x_j\Vert\le 1
∥xj∥≤1.对于
f
∈
X
f\in\mathcal{X}
f∈X,令:
和: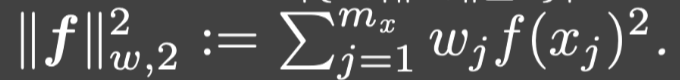
从而: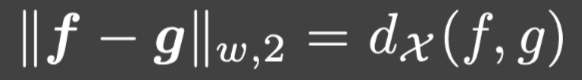
这是假设4.3.1
对于任何
K
∈
N
K\in\N
K∈N,令
X
K
=
{
f
1
,
⋯
,
f
K
}
\mathcal{X}_K=\{f_1,\cdots,f_K\}
XK={f1,⋯,fK},其中
f
i
∈
X
f_i\in\mathcal{X}
fi∈X和
f
i
(
0
)
=
i
K
f_i(0)=\frac{i}{K}
fi(0)=Ki.从而对于任何
f
∈
X
f\in\mathcal{X}
f∈X, 都存在
g
∈
X
K
g\in\mathcal{X}_K
g∈XK使得: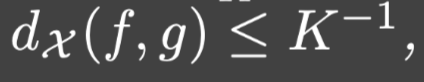
这就是假设4.3.2.
接下去,假设可以形成给定测度的正交基,有了这个假设之后就可以使用最小二乘分析.
假设4.7(trunk网络和传感器) 设F是一组可行的trunk网络参数,定义为: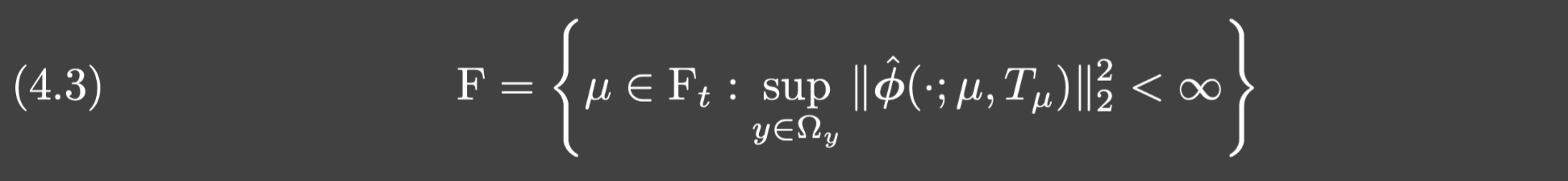
其中
F
t
=
{
μ
:
∃
T
μ
使得
ϕ
^
(
⋅
;
μ
,
T
μ
)
是
L
ω
2
(
Ω
y
)
的正交基
}
F_t=\{\mu:\exist T_\mu使得\hat{\phi}(\cdot;\mu,T_\mu)是L_\omega^2(\Omega_y)的正交基\}
Ft={μ:∃Tμ使得ϕ^(⋅;μ,Tμ)是Lω2(Ωy)的正交基}.假设
{
y
1
,
⋯
,
y
m
y
}
\{y_1,\cdots,y_{m_y}\}
{y1,⋯,ymy}是从概率测度
ω
\omega
ω中随机独立取的一组离散化点.对于
r
t
>
0
r_t>0
rt>0,假设
m
y
m_y
my充分大满足: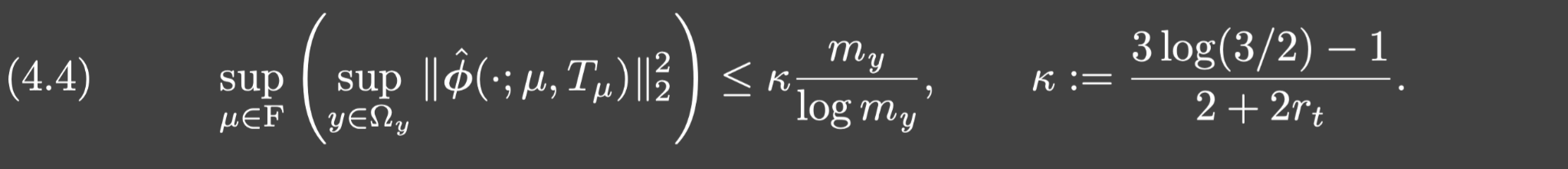
最后介绍branch网络的假设,简单起见,为了让(3.5)的loss为0,假设网络是一个宽度足够大的两层神经网络.
假设4.8(branch网络) 1.branch网络是一个两层神经网络,它的激活函数 σ \sigma σ是Lipschitz连续的.
2.对于每个K,都存在一个宽度是
n
K
n_K
nK的两层branch网络,它能够使得(3.5)的loss为0. 也就是说,存在
θ
⋆
\theta^{\star}
θ⋆满足
C
(
θ
⋆
)
=
R
⋆
A
⋆
C(\theta^\star)=R^\star A^\star
C(θ⋆)=R⋆A⋆. 具体地说,设
θ
⋆
=
{
γ
l
,
β
l
,
w
l
}
l
=
1
n
K
\theta^\star=\{\gamma_l,\beta_l,w_l\}_{l=1}^{n_K}
θ⋆={γl,βl,wl}l=1nK, 其中
那么对于
k
=
1
,
⋯
,
K
k=1,\cdots,K
k=1,⋯,K,成立: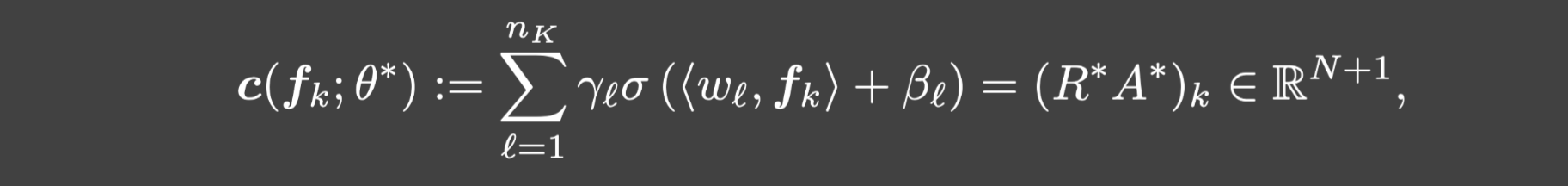
其中 ( R ⋆ A ⋆ ) k (R^\star A^\star)_k (R⋆A⋆)k是 R ⋆ A ⋆ R^\star A^\star R⋆A⋆的第k列.
3.设: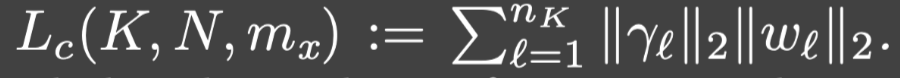
假设 L c ( K , N , m x ) L_c(K,N,m_x) Lc(K,N,mx)是独立于 K , N , m x K,N,m_x K,N,mx一致有界的,记它的上界是 L ˉ c \bar{L}_c Lˉc.
下面利用上面的假设来表征完全训练的DeepONet的泛化误差:
定理4.10 假设4.2,4.3,4.7,4.8都成立. 令
O
n
e
t
O_{net}
Onet是完全训练好的DeepONet,也就是trunk网络是由(3.4)得到的,其中p=2,
μ
⋆
∈
F
\mu^\star\in F
μ⋆∈F如假设4.7定义的那样;branch网络是由(3.5)得到的.给定截断算子
T
M
(
z
)
=
s
i
g
n
(
z
)
m
a
x
{
M
,
∣
z
∣
}
\mathfrak{T}_M(z)=sign(z)max\{M,|z|\}
TM(z)=sign(z)max{M,∣z∣},令
O
~
n
e
t
[
f
]
(
y
)
:
=
T
M
(
O
n
e
t
[
f
]
(
y
)
)
\tilde{O}_{net}[f](y):=\mathfrak{T}_M(O_{net}[f](y))
O~net[f](y):=TM(Onet[f](y)). 那么对于任何
f
∈
X
f\in\mathcal{X}
f∈X, 成立: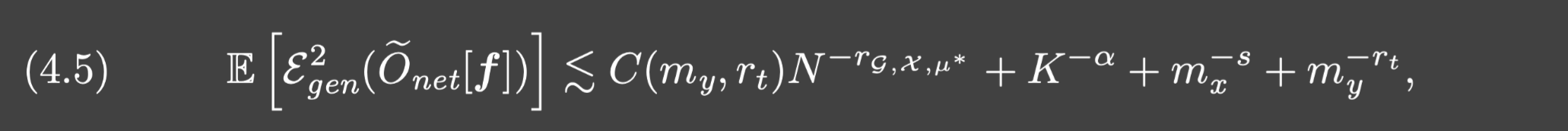
其中: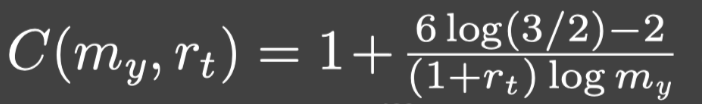
并且对所有随机输出函数的传感器
{
y
i
}
i
=
1
m
y
\{y_i\}_{i=1}^{m_y}
{yi}i=1my求期望. 所有隐藏常数都与
K
,
m
x
,
m
y
,
N
K,m_x,m_y,N
K,mx,my,N无关但可能依赖于: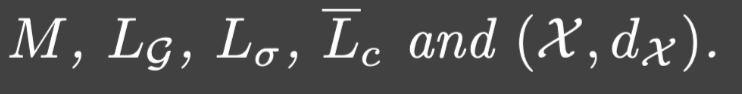


















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









