







1. 背景介绍
目前存在大量的图像降噪方法,它们的设计通常根据图像的具体噪声类型、噪声水平以及对图像细节保持的要求。
空间域、频域去噪作为最基本也最传统的降噪手段,加上各种先验假设和统计信息衍生出了相当多的变种。
影像画质中的图像噪声:建模与去噪算法盘点 - 知乎 (zhihu.com)
空间域方法在图像原始像素坐标系中直接操作每一个像素点或者其邻域的灰度值,以达到去除噪声的同时尽可能保留图像细节的目的。这些算法通过分析图像中像素与周围像素的关系,根据一定的准则或者假设进行滤波操作,如自相似性、长程相关性。
频域方法将图像从空间域转换到频域,在变换域中对频谱进行处理后再转换回空间域,从而实现噪声的去除。这种方法的优点是可以有针对性地处理图像中不同频率成分的噪声,同时保留图像的结构信息。离散傅里叶和一些小波变换这样的方法获得的是一系列正交基,对于方差较小的噪声,因为无噪声图像本身的变换系数主要集中在低频区域,并且具有较大的幅度,而噪声在变换域中由于方差较小的缘故,通常只有较小的值(例如 95.4% 的值都在两个标准差的范围内),我们可以通过设定阈值的方法(一般为 2~3 个噪声标准差),只保留有噪声图像的变换系数中那些具有较大幅度的值,其他的则置零,绝大部分的噪声的变换系数就得以消除。
混合域去噪算法结合图像在不同域的特点,设计出的综合型图像降噪方法。这类算法的优势在于它可以充分利用不同域内图像信息的不同表示形式,以更全面和灵活的方式来识别和去除噪声,同时保留图像的细节和结构信息。
本篇首先简单会介绍常见的频域去噪方法,但具体的原理细节与公式推导不做深入讨论。然后会基于这些必备基础深入介绍BM3D的细节。
2. 频域降噪
2.1 离散傅里叶变换(DFT)
以微观的角度去描述一张图像:区域A是毫无波澜的平面,区域B是方向45°梯度较大的斜边,区域C是方向60°稍有变化的弱边和方向120°起伏很大的强边的组合...那么图像可以看成由一些不同方向、不同梯度大小的成分的组合。

把这些不同方向、不同梯度大小的成分看成不同频率、不同相位的正弦或余弦函数,高频代表信号快速变化或突变的成分被看作图像梯度较大的区域,相位信息看成图像中像素值变化的方向。因此当对一张图像做傅里叶变换分解时,我们可以根据频率、幅值、相位从另一个空间域看待图像。
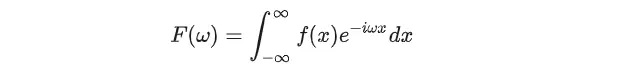
傅里叶变换
根据傅里叶正变换公式,可以理解成在计算信号和三角函数的一个相关性。越相关则系数越大,代表信号中该频率成分越多。

空间域与频域的转换
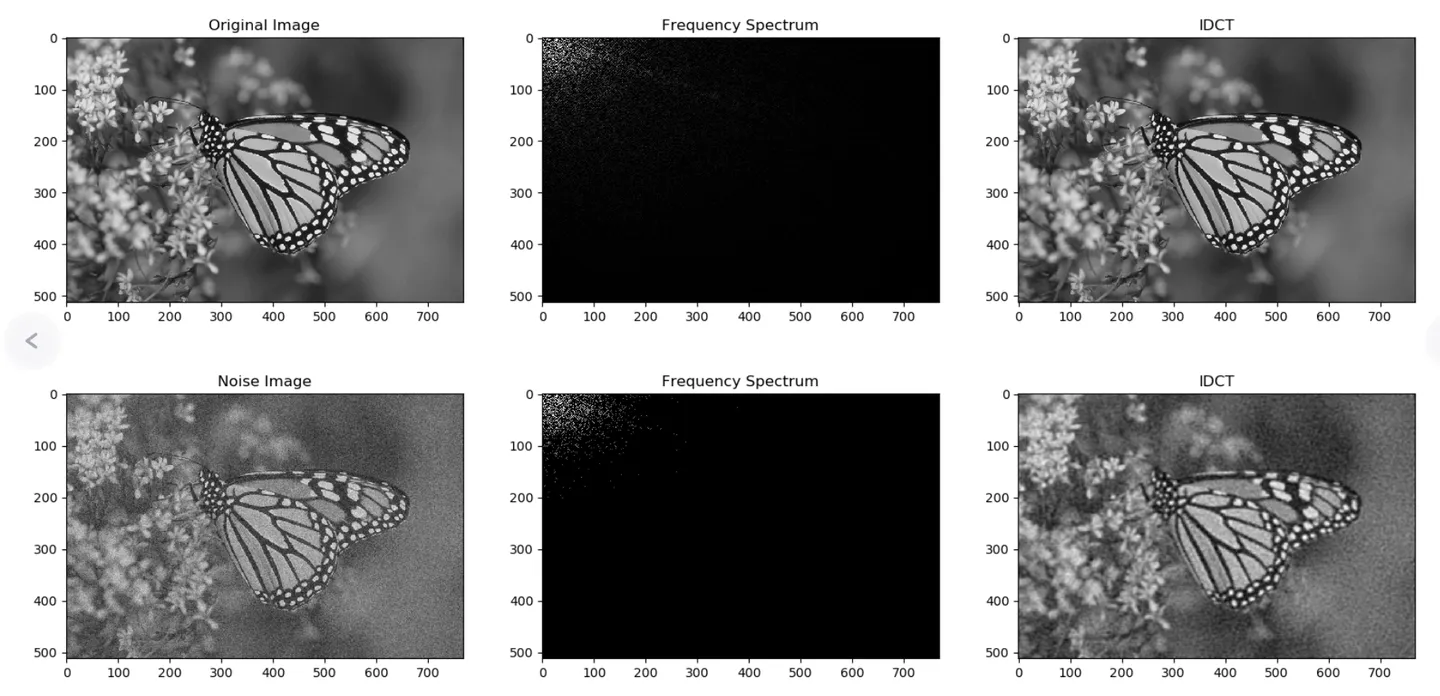
直接对图像进行二维傅里叶变换得到的频谱高频在中间、低频在四角,为了方便观察和处理这里对频谱进行中心化,可以看到图像大部分成分都是低频信号组成。
在频域中,我们可以通过高通或低通滤波器对不想要的频率成分过滤处理不同的图像任务,然后反变换回空间域。其中降噪任务可以通过设置合适的阈值或滤波窗口,去除那些被认为是噪声的分量,同时尽量保留图像的低频和部分中频成分以保持图像的主体结构和细节。

需要注意的是实际单纯从频谱上难以区分噪声和有效信号,直接在频率域中进行滤波有可能会丢失部分有用的高频信息,如图像的边缘和细节。因此在实际应用中,通常会选择保留部分高频信息,或者结合空间域和频率域的方法,如小波变换或多尺度分析等手段进行更细致的噪声去除。
# 读入图像加噪声
image = plt.imread('clean.jpg').mean(axis=-1)
image = image + 20*np.random.normal(size=image.shape)
# 傅里叶变换
fourier = fftpack.fft2(image/255)
threshold = 100
fourier = np.where(np.abs(fourier) < threshold, 0, fourier)
# 计算频谱图
fourier_shifted = fftpack.fftshift(fourier)
# 进行傅里叶反变换
ifft_result = fftpack.ifft2(fourier_shifted)
# 转换为uint8类型以显示图像
ifft_result_abs = np.abs(ifft_result*255).astype(np.uint8)2.2 离散余弦变换(DCT)
DCT变换较DFT变换具有更好的频域能量集中度,所以被广泛应用于图像压缩、图像降噪。图像信号的能量在DCT变换后主要集中在低频系数上,而高频系数通常对应于图像中的噪声。这种特性使得在去噪过程中,只需对高频部分施加一定的阈值处理,就能有效地抑制噪声,同时对图像细节的丢失也不会太大。
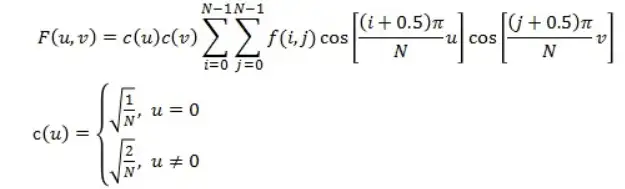
另外相较于傅里叶变换,DCT实数运算在计算效率和实现复杂度上通常优于复数运算。
2.3 小波变换(DWT)
傅里叶变换适合于分析全局频率特性与处理平稳信号,对于非平稳信号有相当大的局限性。首先它虽然知道频率成分,但有关时间节点的局部信息基本丢失。其次对于短暂或瞬态的信号特征(如突变、尖峰),其时域定位能力较弱。为了加强非平稳信号的处理能力,后续也演进出了如加窗短时傅里叶变换等方法,但窗函数、窗口大小、时间分辨率与频率分辨率的取舍都存在局限性。
小波变换的思路有些类似可以变化窗口的短时傅里叶变换,但是基函数变成了具有变化的频率和有限长幅值会衰减的小波。通过对小波基函数伸缩和平移,可以感知信号的不同频率和时域信息,最终聚焦信号的任意尺度细节。
小波变换的基函数都是由母小波和父小波(缩放函数) 缩放和平移后的集合组成,分别用于捕捉信号或图像的高频细节和低频结构,它们通过尺度和位移的调整,共同提供了对信号或图像进行多尺度、多分辨率分析的强大工具。在实际应用中,选择特定的小波基时,会同时指定其母小波和相应的缩放函数。
morlet小波波形
常见的小波基函数有Haar、Symlet 、Coiflet等,不同小波在紧凑性和平滑性有不同设计。实际使用中可能需要通过实验比较不同小波基的效果,以确定最适合的基函数。以haar小波为例,它由简单的矩形波形构成,缩放函数是[1 1],小波函数是[1 -1]。它计算简单且易于理解,适用于快速处理和硬件实现:
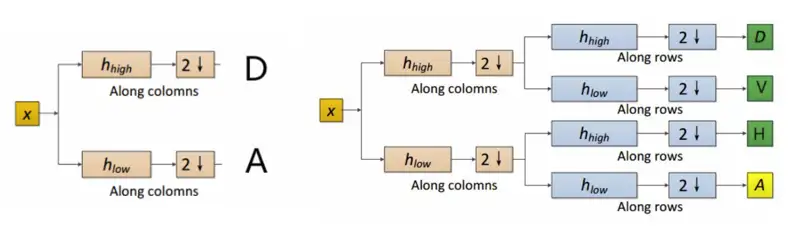
相较于一维DWT,二维DWT从水平和竖直两个方向进行低通和高通滤波
在python中可以利用PyWavelets进行小波变换的分解:
img = cv2.imread("clean.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY).astype(np.float32)
coeffs = pywt.dwt2(img, 'haar')
A, (H, V, D) = coeffs
二维DWT(左上:低频, 右上:水平高频, 左下:垂直高频, 右下:对角高频)
随着分解的级数越来越高,多尺度分解将信号分解为一系列不同尺度的小波系数,这些系数分别对应信号的不同细节层次。粗尺度系数反映信号的低频、整体或平滑特征,细尺度系数则捕捉高频、局部或瞬态细节。

分解后的信号形成一个类似于图像金字塔的层次结构,每一层代表一个特定的分辨率水平。这种结构便于进行信号的分级处理、压缩编码、去噪和特征提取。在去噪任务中,由于信号的噪声往往集中在较高尺度的小波系数中,通过阈值去噪等方法可以针对性地去除这些噪声成分,同时保留信号的主要结构和细节。
3. 维纳滤波(Wiener Filter)
维纳滤波是一种基于统计学原理的图像去噪方法,适用于处理受加性高斯白噪声污染的图像。它以最小均方误差为优化目标,旨在恢复原始无噪声图像。
首先建立噪声图像与原始图像的关系:  ,假设存在一个线性滤波器h,h对
,假设存在一个线性滤波器h,h对 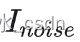 进行滤波后得到估计原始图像
进行滤波后得到估计原始图像  ,也就是说估计图像可以通过观测噪声信号线性加权得到。
,也就是说估计图像可以通过观测噪声信号线性加权得到。
我们最终希望的是原始图像与估计的原始图像的差  要有最小的方差:
要有最小的方差:  。
。
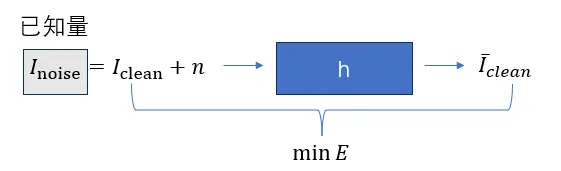
实际我们发现上面这么多变量中只有 是已知量,要反解出这样一个滤波器h是不太可能的,因此不可避免的还需要引入其他假设或近似。由于要寻找一个滤波器h使得方差最小,首先尝试计算期望E对h的导数:
是已知量,要反解出这样一个滤波器h是不太可能的,因此不可避免的还需要引入其他假设或近似。由于要寻找一个滤波器h使得方差最小,首先尝试计算期望E对h的导数:
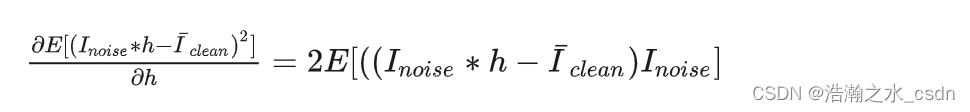
用矩阵的形式描述上述表达式:

令导数等于0,那么其实线性滤波器h的矩阵表达形式就为:

当信号与噪声是独立关系时:
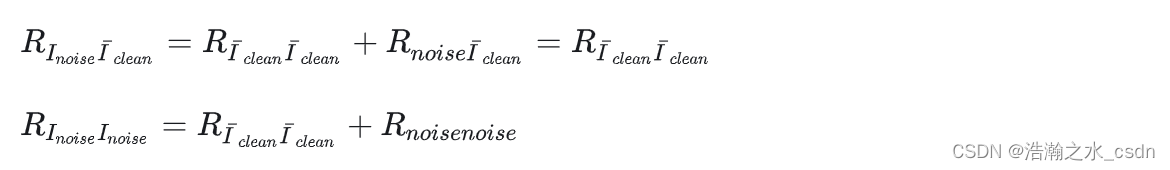
因此当得到噪声的自相关函数与观测噪声图像的自相关函数即可确定线性滤波器的形式,我们称之为维纳滤波器。可以看到之前所说的引入其他假设或近似,在这里就是指提前设置好噪声的自相关函数,针对不同的噪声水平反解出不同强度的维纳滤波器。
from scipy.signal import wiener
image_denoise = wiener(image_noise, [5, 5])
4.BM3D
BM3D是一种混合域的去噪方法,首先在空间域中将图像相似度高的2D patch组合成3D group,这一步与Non-local mean的思想是一样的。然后会在变换域中对3D group进行协同变换和滤波,从而增强稀疏表示,其中变换域主要包括三个连续的步骤:各个group的3D变换,变换谱的收缩和逆3D变换。
由于每个3D group中patch间的相似性,变换域中可以实现真实信号的高度稀疏表示(即成分集中于低频)。高斯白噪声的正交变换仍是与原始信号同分布的高斯白噪声并且强度不会改变,而无噪声部分正交变换能量可以更加集中,从而相较2D变换,3D变换可以很好地区分并衰减噪声。
论文链接:Image denoising by sparse 3D transform-domain collaborative filtering
参考代码:GitHub - Ryanshuai/BM3D_py: pure Python implementation of BM3D
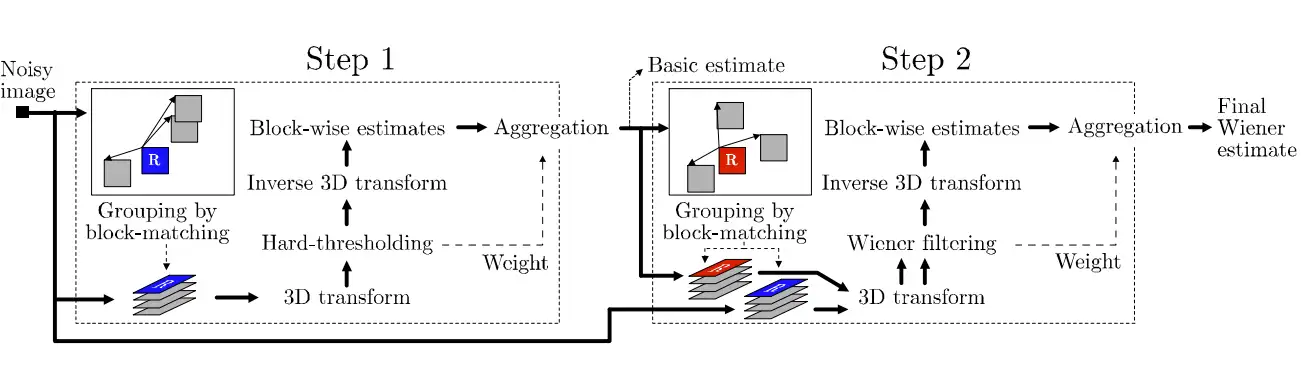
BM3D总流程
BM3D主要可以分为两步:step1主要进行硬阈值滤波,step2主要进行维纳滤波。
step1:基础估计
(1) 相似块匹配
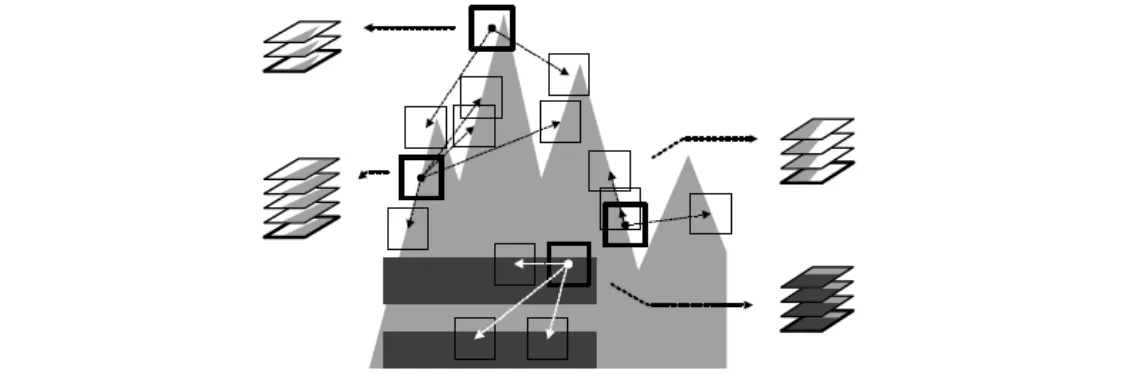
具有相似图像结构的patch被组合到了一起
类似于NLM算法,BM3D算法首先需要在噪声图像中寻找相似图像块。在遍历图像像素的过程中,当前遍历到的像素坐标 �� 对应的像素块被选择作为参考块 ��� 。然后会在周围寻找一系列的相似块 �� ,相似块与参考块的匹配误差或者距离可以表示为:
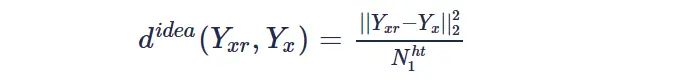
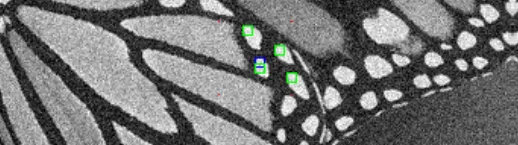
通常由于性能和内存的限制,搜索窗和patch size不会太大
将与参考块匹配误差小于一定阈值的2D patch组合在一起,形成3D group。实际上我们发现group中两个重叠块匹配误差的数学期望和方差为:
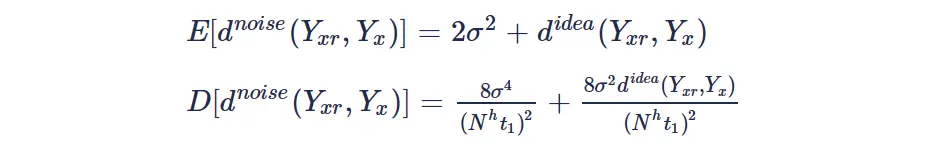
可以发现噪声方差很大或者块很小的时候块的相似性判断准确率会下降,为了提高块匹配的准确率论文提出当噪声方差>40时,先对有噪声图像的匹配块进行二维正交变换,然后将幅度小于阈值的系数置零后,计算系数的均方误差:
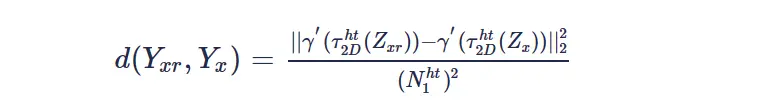
(2) 协同硬阈值滤波
如果每个group中的patch对应的无噪信号是完全相同的,那类似NLM加权平均的思想可以很好衰减噪声。但实际自然图像很难找到那么多完美相似的块,因此BM3D采用了在变换域进行协同滤波的方案。
3D协同变换将由相似图像块组成的3D Group进行某种正交变换(如第二节说到的离散余弦变换或小波变换),由于3D线性变换较为复杂,一般会通过2D变换和1D变换组合代替。以DCT+Haar为例,首先将3D group中每个patch进行2D DCT变换到频域,然后在第三维进行1D Haar或者Hadarmard变换。由于噪声正交变换后能量不变,而真实信号的能量变换后会更加集中,相较单纯的2D DCT等方法,BM3D这里有了大量2D patch统计的额外信息,通过硬阈值就更容易区分和过滤掉噪声成分了。
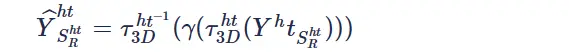
降噪后经过反三维变换变换到空间域,把每个3D group降噪后的patch分别放回图像原来的位置。
这里随便取了一个3D group演示一下整个3D协同滤波的过程:

这里3D group每个patch的尺寸是32X32,在做完二维离散余弦变换(2D DCT)后,频谱(u,v)位置的幅值即包含真实信号的也存在噪声的。随着相似patch的不断增加,对(u,v)位置的多个幅值(这里是7个)再进行1次1D变换,就可以比较准确的把主成分和噪声区别开,并通过硬阈值将噪声丢弃:

这里把patch展成1行(32*32),每列为7个patch相同位置的DCT幅值。对每列1D变换后,可以看到硬阈值前后把幅值比较小的噪声干扰剔除了出去,最后1D反变换与2D反变换就可以复原去噪后的图像。
(3) 聚合
在对参考块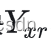 和相似块
和相似块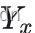 组成的3D group进行了协同滤波后,当前降噪的像素为坐标为
组成的3D group进行了协同滤波后,当前降噪的像素为坐标为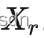 。可以看到图像中一个像素既可以属于不同的参考块,也可以属于一个参考块的不同相似块,即一个像素对应了不同3D group中patch降噪后的结果,那么实际
。可以看到图像中一个像素既可以属于不同的参考块,也可以属于一个参考块的不同相似块,即一个像素对应了不同3D group中patch降噪后的结果,那么实际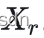 应该取哪个patch的值呢?
应该取哪个patch的值呢?
在假设3D group内所有的像素都是独立的前提下,可以根据协同滤波后剩余的非零系数的个数来进行权值的分配,记硬阈值操作后剩下的系数个数为N则:
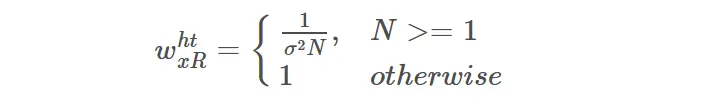
没有被置零的系数越多,代表残留的噪声能量可能就越多
通过对某个像素所属的所有参考块以及对应的相似块的加权叠加,就可以得到其基础估计,这里 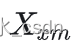 取值为0或1,代表当前像素是否在
取值为0或1,代表当前像素是否在 上:
上:
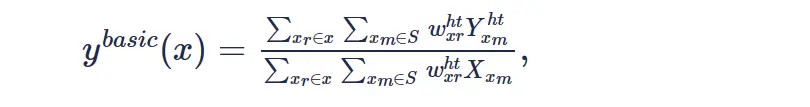
step2:最终估计
当噪声方差较大时,patch的相似度匹配通常并不是很理想。硬阈值操作并不能去除残留在低频系数上噪声,而且很多的细节信息也会被一同滤除,还有一部分原因是 3D 组合内的块不够相似,匹配精度较低。所以Step1 通常只是作为一种基础估计。
Step2 与 Step1 的流程基本一致,首先也是为每一个参考块寻找足够的相似块,但Step2 是直接在基础估计图像上寻找相似块的,因为经过 step1 的基础估计,图像已经能够极大地去除噪声。另外在协同滤波过程中采用了维纳滤波得到更理想的结果,聚合中加权平均的操作与Step1相同,最终得到滤波后的图像。
协同维纳滤波
不同于硬阈值滤波直接将小于阈值的系数置零而完全保留那些较大的系数,BM3D 引入了一种称为经验维纳收缩(Emprical Wiener Shrinkage)的方法。其实际上是根据基础估计图像上的变换系数的功率谱来对原始有噪声图像的变换系数进行收缩,从而能够更好地去除包括低频系数中的噪声能量,同时尽可能地保留原本属于无噪声图像的那部分高频系数。
第三节有提到维纳滤波是依赖于噪声的先验信息的方法,我们可以在Step1基础估计图像中进行相似块匹配,并对应找到原始有噪声图像上同样位置的块组合,这样就得到了有无噪声的两个3D Group,噪声的自相关函数与观测噪声图像的自相关函数先验也就拿到了。
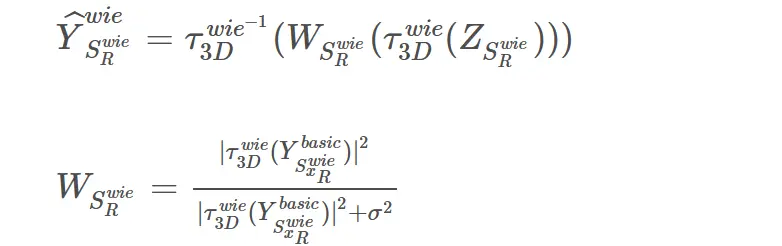
value = np.power(group_3D_est_h, 2) #Step1估计值的功率谱
value /= (value + sigma * sigma)
group_3D_est_h = group_3D_img_h * value #估计信号/噪声信号 = 估计信号的功率谱/实际信号功率谱+噪声功率谱 当基础估计图像频谱作为无噪声图像频谱,即根据基础估计图像变换系数的功率占比来对有噪声图像的变换系数进行调整,这时维纳滤波就称为经验维纳滤波(因为基础估计也不是真实的先验,但经验上来说比较准确)。
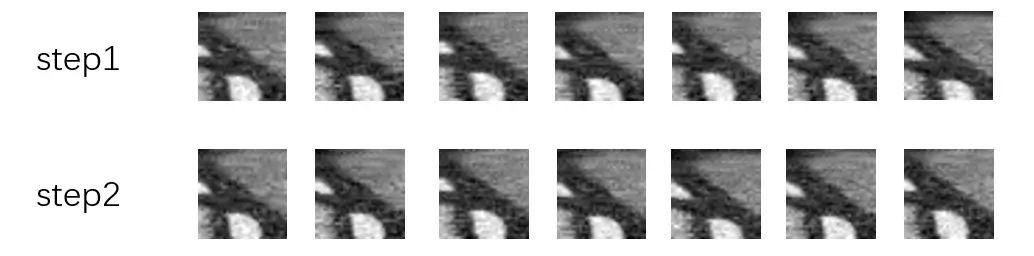
就这个case来看整体step2就step1来说清晰度略高一些,噪声水平差异不大
在输入噪声方差20的时候,step2相较step1清晰度略有提升。而随着输入图像的噪声增加,最终降噪图像的涂抹感加重还是比较严重。

对比NLM,无论细节保留还是噪声的去除,BM3D都优于NLM。

5.Non-Local Bayes
参考论文:Implementation of the Non-Local Bayes Image Denoising Algorithm
参考代码:https://github.com/palanglois/nlBayes
从空域到频域再到混合域,其实发现图像降噪领域还是运用了大量的高等数学、线性代数思想,这里补充介绍一种在BM3D基础上运用到概率论思想的降噪方法,算是把数一三件套凑齐(当然前面一直提到的高斯分布也算是概率模型)。
相较于NL-means算法通过块的相似性赋予权重进行加权平均,以及BM3D通过块的稀疏性进行3D滤波,NL-Bayes对每一组3D group相似的patch进行高斯向量模型的评估。因此每个patch既有NL-means的加权均值又有估计patch可变性的协方差矩阵。利用这两点信息我们可以通过结合贝叶斯理论估计各patchs的噪声。
整个算法跟BM3D非常相似并且也是分为两步,step2主要依赖于step1的去噪估计,然后得到更好的加权权重和patch的高斯模型协方差矩阵进行图像去噪。
首先是原理推导,给定一个无噪声N*N的patch P ,有噪声patch为 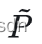 ,那么在已知无噪声像素值的时候猜到该像素点有噪声值是多大的概率是多少呢?由于这里假设噪声是符合高斯分布的,那噪声值的取某个值概率就是符合高斯分布函数了:
,那么在已知无噪声像素值的时候猜到该像素点有噪声值是多大的概率是多少呢?由于这里假设噪声是符合高斯分布的,那噪声值的取某个值概率就是符合高斯分布函数了:
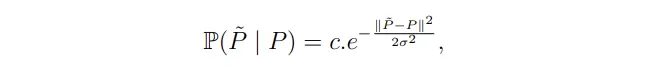
接下来就是经典的bayes问题,我们实际上面临的问题是需要在有噪声的情况下预测对无噪声像素值,根据bayes公式:
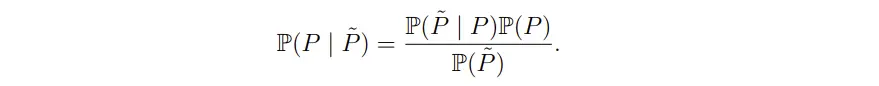
当这个无噪声真实像素值预测正确的概率最大化,才能得到最好的降噪效果。所以问题变成了找到能使  最大的P,这个P就是最优的无噪声patch。目前第一个概率我们是建模为高斯分布,那么第二个概率表达式应该怎么描述呢?目前我们手上只有一堆相似的噪声patch,我们希望利用已有的一些相似的噪声patch
最大的P,这个P就是最优的无噪声patch。目前第一个概率我们是建模为高斯分布,那么第二个概率表达式应该怎么描述呢?目前我们手上只有一堆相似的噪声patch,我们希望利用已有的一些相似的噪声patch 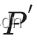 去描述预测无噪图像与实际图像P相似的概率。
去描述预测无噪图像与实际图像P相似的概率。
首先假设存在一个patch Q ,Q与P相似的概率是符合高斯分布的, 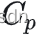 是协方差(可以看成高斯分布的方差,两个patch越不相关方差越小概率越低),如果Q就等于P 的话相似概率就是1,所以第二项可以表示如下:
是协方差(可以看成高斯分布的方差,两个patch越不相关方差越小概率越低),如果Q就等于P 的话相似概率就是1,所以第二项可以表示如下:
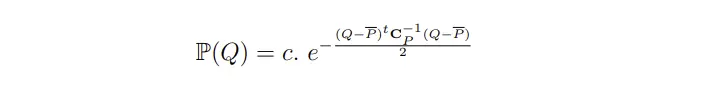
这时最大化概率问题可以转换成如下形式,其中 �¯ 为理想无噪声patch的期望:
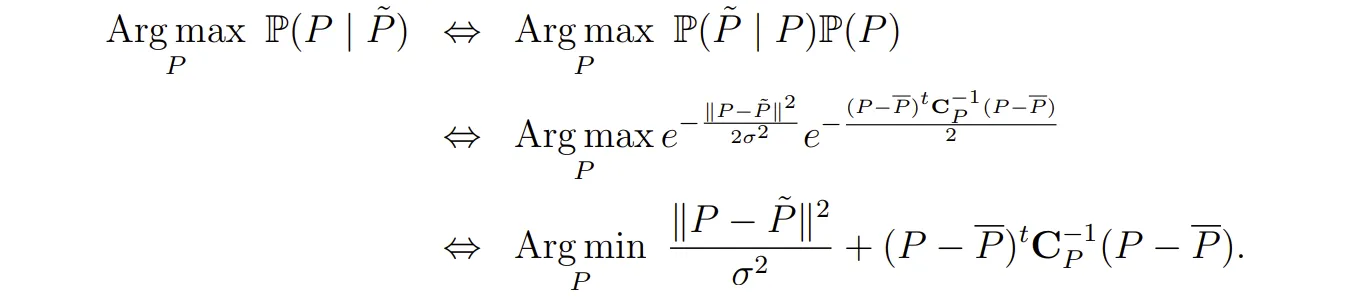
当Q 为噪声块时,协方差矩阵 会多加上高斯噪声的干扰:
![]()
这里假定3D group中与噪声patch 相似的所有patch的均值是和理想无噪声patch的期望基本一致的(step1这个假设肯定是不太准确的,不过还有step2):
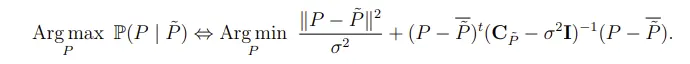
类似全变分降噪的思想,表达式的含义可以理解成无噪声图像P结构上要接近所有噪声图像,σ控制噪声图像与无噪声图像的差异,即控制降噪力度。最小化方程用对P求导计算极值得方式:
![]()
整理下式子,初次估计的降噪patch就变为下式,可以看到最终推导的公式还是比较有可解释性的:
![]()
与BM3D类似,第一步得到了去噪效果比较好的结果后可以以此作为真实去噪图像的估计,重新得到较为准确的协方差矩阵和均值,进行step2的去噪处理:
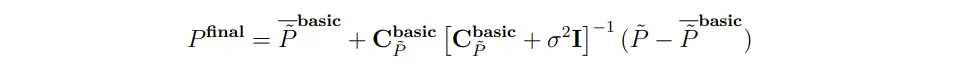
实际上论文中第一步和第二步降噪都是替换掉了BM3D的3D滤波过程,其余流程和BM3D完全一样。

在指标和效果上和BM3D大差不差,利用统计的思想完成的3D group的去噪。这类基于概率论的算法中间很多推导用到太多假设,不过效果不错作者也能自圆其说,可能自己还需要再深入理解一下。



















 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









