




在《LLM对齐“3H原则”》这篇文章中,我们介绍了LLM与人类对齐的“3H”原则,但是这些对齐标准主要是基于人类认知进行设计的,具有一定的主观性。因此,直接通过优化目标来建模这些对齐标准较为困难。本文将介绍基于人类反馈的强化学习方法(RLHF),引入人类反馈的指导,以便更好地对齐大语言模型。

1、RLHF介绍
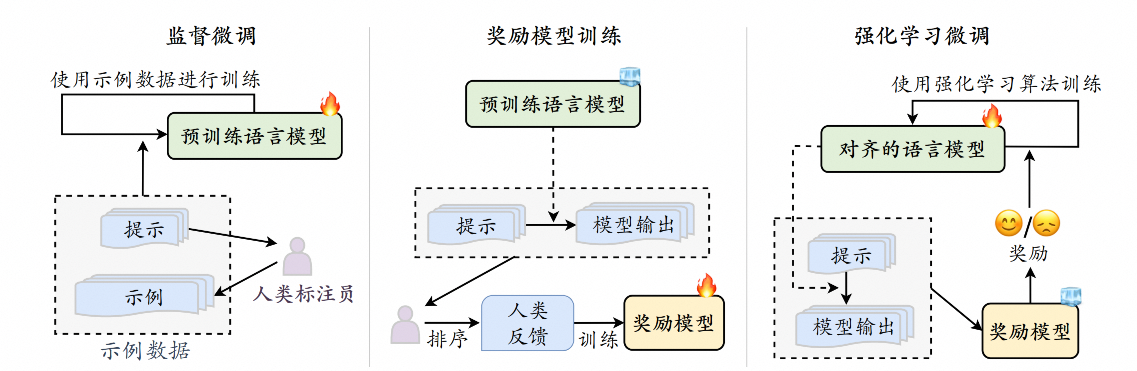
为了加强大语言模型与人类价值观的一致性,基于人类反馈的强化学习旨在利用收集到的人类反馈数据指导大语言模型进行微调,从而使得大语言模型在多个标准(例如有用性、诚实性和无害性)上实现与人类的对齐。
RLHF首先需要收集人类对于不同模型输出的偏好,然后使用收集到的人类反馈数据训练奖励模型,最后基于奖励模型使用强化学习算法(如Proximal Policy Optimization,PPO)微调大语言模型。这种将人类反馈纳入大语言模型训练过程的方法已成为实现人类对齐的主要技术途径之一。
2、RLHF算法系统
RLHF算法系统主要包括三个关键组成部分:需要与人类价值观对齐的模型、基于人类反馈数据学习的奖励模型以及用于训练大语言模型的强化学习算法。
具体来说,待对齐模型一般指的是经过预训练、具备一定通用能力的大语言模型。然而,这些模型并没有与人类价值观对齐,在下游任务中可能表现出不合适甚至有害的行为。例如,InstructGPT针对具有175B参数的GPT-3模型进行对齐。GPT-3在大规模语料上进行了预训练,但是在一些特殊场景下仍然会生成不恰当的输出内容。
奖励模型的作用是为强化学习过程提供指导信号,反映了人类对于语言模型生成文本的偏好,通常以标量值的形式呈现。奖励模型既可以采用人类偏好数据对已有的语言模型继续微调,也可以基于人类偏好数据重新训练一个新的语言模型。
虽然原始的InstructGPT采用了较小的GPT-3(只有6B参数)作为奖励模型,现阶段的研究通常认为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











