







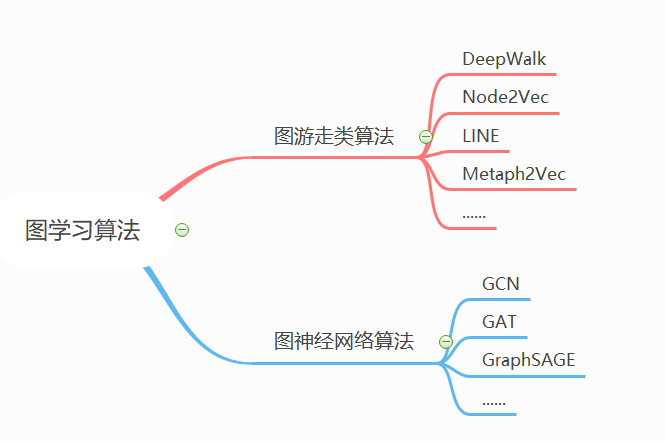
图模型总体上可以分为两大类:一是random-walk游走类模型,另一类就是GCN、GAT等卷积模型了。
1. 为什么出现GCN来处理图结构
在图像领域,CNN被拿来自动提取图像特征的结构,但是CNN处理的图像或者视频数据中像素点(pixel)是排列成成很整齐的矩阵,虽然图结构不整齐(不同点具有不同数目neighbors),但是不是可以用同样的方法去抽取图的的特征呢?
于是就出现了两种方式来提取图的特征。一是空间域卷积(spatial domain),二是频域卷积(spectral domain)。第一种方式由于每个顶点提取出来的neighbors不同,处理上比较麻烦,同时它的效果没有频域卷积效果好,没有做深究。因此,现在比较流行、工程上应用较多的为频域卷积。
2.GCN
GCN的卷积核心公式: Hl+1=σ(D−1/2AD−1/2HlWl)
GCN计算方式上很好理解,本质上跟CNN卷积过程一样,是一个加权求和的过程,就是将邻居点通过度矩阵及其邻接矩阵,计算出各边的权重,然后加权求和。
D负责提供权值的矩阵,邻接A矩阵控制应该融合哪些点, H表示上一层的embedding参数
GCN首次提出了卷积的方式融合图结构特征,提供一个全新的视角。
主要缺点:1.融合时边权值是固定的&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









