






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer2233,助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪必备!

来源:腾讯优图实验室
近日,第39届年度AAAI国际人工智能顶级会议(AAAI Conference on Artificial Intelligence, AAAI 2025)公布了论文录取结果。AAAI 2025共收到来自全球的12957篇有效投稿,最终录用了3,032篇论文,录用率为23.4%。AAAI是中国计算机学会(CCF)推荐的A类国际学术会议,也是人工智能领域历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,该会议旨在促进人工智能领域的研究与科学交流。
今年,腾讯优图实验室共有10篇论文被录用,内容涵盖大型语言模型、深度伪造检测等研究方向,展示了腾讯优图实验室在人工智能领域的技术能力和研究成果。
以下为腾讯优图实验室部分入选论文概览:
用于分层点云学习的高效 RWKV 类模型
PointRWKV: Efficient RWKV-Like Model for Hierarchical Point Cloud Learning
Qingdong He, Jiangning Zhang, Jinlong Peng, Haoyang He(浙江大学), Xiangtai Li(南洋理工大学), Yabiao Wang, Chengjie Wang
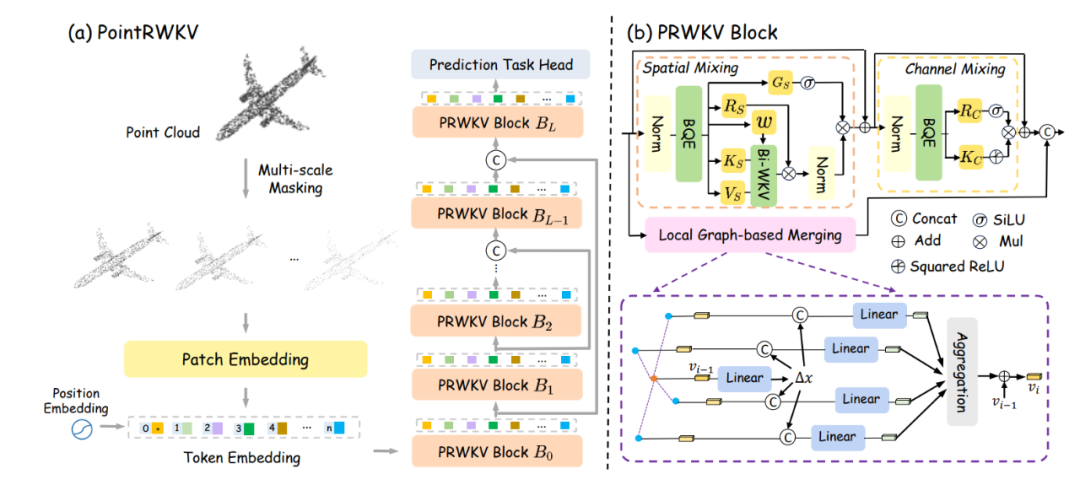
Transformer 彻底改变了点云学习任务,但二次复杂度阻碍了其向长序列的扩展。这给有限的计算资源带来了负担。最近出现的 RWKV 是一种新型的深度序列模型,在 NLP 任务中显示出序列建模的巨大潜力。在这项工作中,我们提出了 PointRWKV,这是一种线性复杂度的新模型,源自 NLP 领域的 RWKV 模型,具有 3D 点云学习任务的必要适应性。具体而言,以嵌入的点块作为输入,我们首先提出使用改进的多头矩阵值状态和动态注意递归机制探索 PointRWKV 块内的全局处理能力。为了同时提取局部几何特征,我们设计了一个并行分支,使用图稳定器在固定半径的近邻图中有效地对点云进行编码。此外,我们将 PointRWKV 设计为 3D 点云分层特征学习的多尺度框架,以促进各种下游任务。对不同点云学习任务进行的大量实验表明,我们提出的 PointRWKV 优于基于 transformer 和 mamba 的同类产品,同时显著节省了约 42% 的 FLOP,展示了构建基础 3D 模型的潜在选择。
论文链接:
https://hithqd.github.io/projects/PointRWKV/
通过令牌级打乱和混合探索无偏见的深度伪造检测
Exploring Unbiased Deepfake Detection via Token-Level Shuffling and Mixing
Xinghe Fu(浙大), Zhiyuan Yan, Taiping Yao, Shen Chen, Xi Li(浙大)
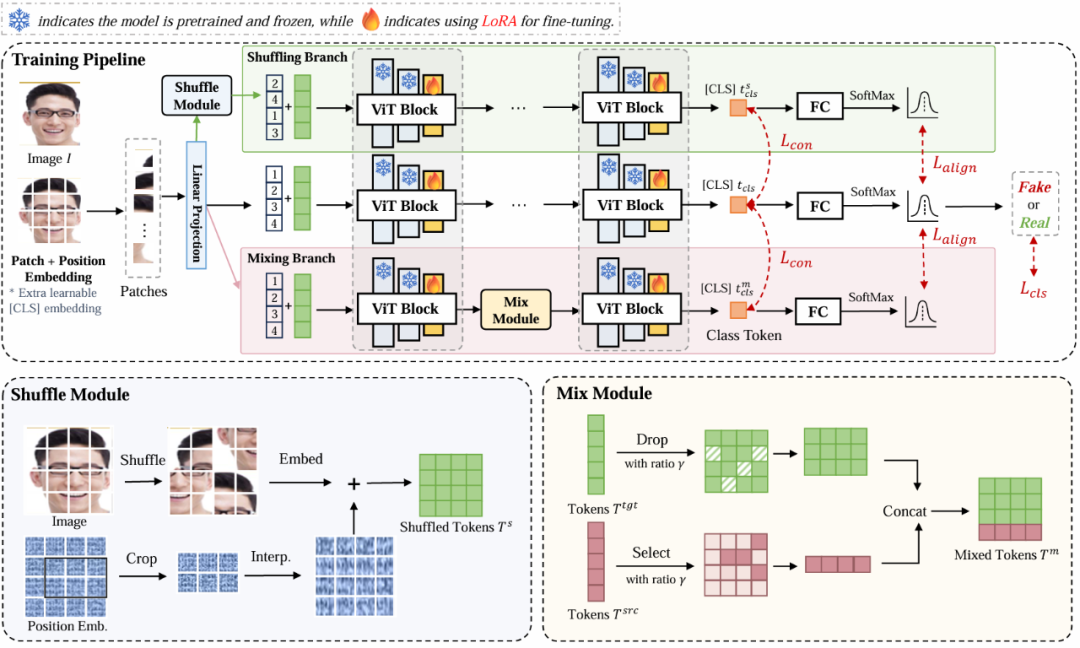
泛化问题被广泛认为是深度伪造检测任务的关键挑战。大多数先前的研究认为,泛化问题是由各种伪造方法之间的差异造成的。然而,我们的研究表明,当与伪造无关的因素发生变化时,泛化问题仍然可能发生。在这项工作中,我们确定了检测器可能过拟合的两个偏差:位置偏差和内容偏差。对于位置偏差,我们观察到检测器倾向于“惰性地”依赖于图像内的特定位置(例如中心区域)。至于内容偏差,我们认为检测器可能会错误地利用与伪造无关的信息进行检测(例如背景和头发)。为了干预这些偏差,我们提出了两个分支,用于在 transformer 的隐空间中对token进行打乱和混合。对于打乱分支,我们重新排列每个图像的标记和相应的位置嵌入,同时保持局部相关性。对于混合分支,我们在小批量内随机选择和混合具有相同标签的两个图像之间的潜在空间中的token,以重新组合内容信息。在学习过程中,我们在特征空间和预测空间中对齐来自不同分支的检测器的输出,应用特征的对比损失和预测的散度损失来获得无偏的特征表示和分类器。我们通过在广泛使用的评估数据集上进行实验验证了我们方法的有效性。
面向识别的拟真可控掌静脉生成
PVTree: Realistic and Controllable Palm Vein Generation for Recognition Tasks
Sheng Shang(合工大), Chenglong Zhao, Ruixin Zhang, Jianlong Jin(合工大), Jingyun Zhang(微信支付33号实验室), Rizen Guo(微信支付33号实验室), Shouhong Ding, Yunsheng Wu, Yang Zhao(合工大), Wei Jia(合工大)
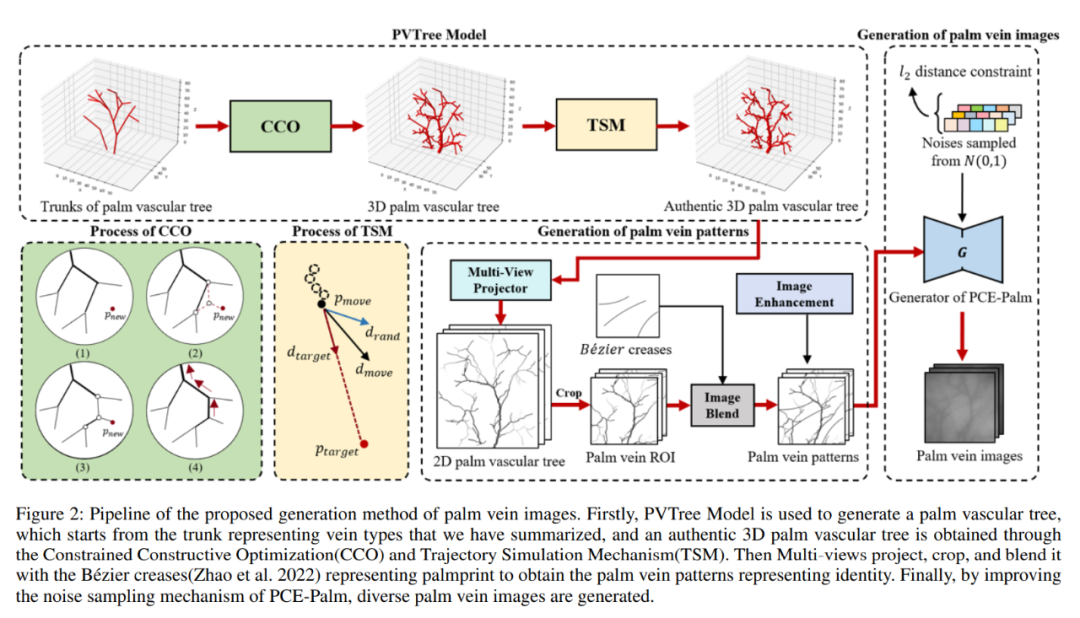
掌静脉识别是一种新兴的生物识别技术,它提供了更高的安全性和隐私保护。然而,由于数据采集的高成本和隐私保护限制,获取足够的掌静脉数据以训练深度学习识别模型是一个挑战。这导致了对使用生成模型生成伪掌静脉数据的兴趣日益增加。然而,现有的方法往往产生不真实的掌静脉图案,或者在控制身份和风格属性方面存在困难。为了解决这些问题,我们提出了一种新的掌静脉生成框架,命名为PVTree。首先,通过使用改进的约束建设优化(CCO)算法创建的复杂且真实的3D掌血管树定义掌静脉身份。其次,通过将相同身份的3D血管树从不同角度投影到2D图像,并使用生成模型将其转换为真实图像,从而生成相同身份的掌静脉图案。因此,PVTree满足了身份一致性和类内多样性的需求。在主流公开数据集上的大量实验表明,我们提出的掌静脉生成方法优于现有方法,并在1:1开放设定下取得了更高的TAR@FAR = 1e-4。据我们所知,这是第一次训练在合成掌静脉数据上的识别模型性能超过了训练在真实数据上的识别模型的性能,这表明掌静脉图像生成研究有着光明的前景。
大模型编码提升序列推荐
LLMEmb: Large Language Model Can Be a Good Embedding Generator for Sequential Recommendation
Qidong Liu(西交), Xian Wu, Wanyu Wang(香港城大), Yejing Wang(香港城大), Yuanshao Zhu(香港城大), Xiangyu Zhao(香港城大), Feng Tian(西交), Yefeng Zheng(西湖大学)
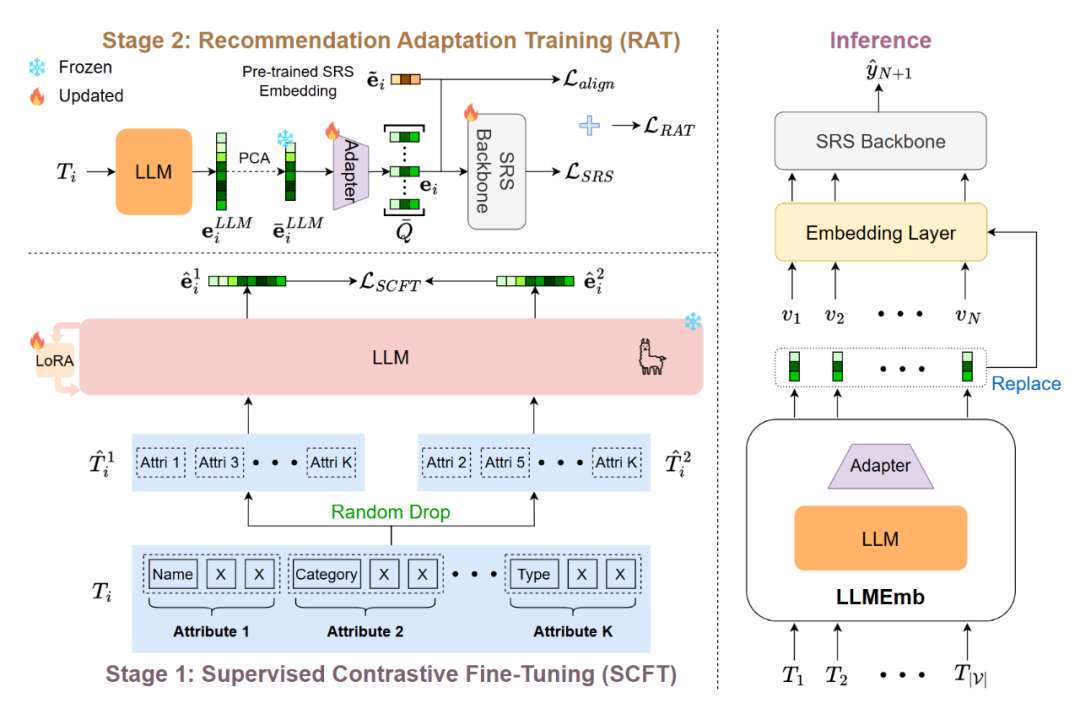
在本文中,我们介绍了一种新方法LLMEmb,利用LLM生成项目嵌入,以提升SRS的性能。为了弥合通用LLM与推荐领域之间的差距,我们提出了一种监督对比微调(SCFT)方法。该方法包括属性级数据增强和定制的对比损失,使LLM更适合推荐任务。此外,我们强调了将协同信号整合到LLM生成的嵌入中的重要性,为此我们提出了推荐适应训练(RAT)。这进一步优化了嵌入,以便在SRS中达到最佳效果。
LLMEmb生成的嵌入可以无缝集成到任何SRS模型中,突显其实用价值。在三个真实世界数据集上进行的综合实验表明,LLMEmb在多个SRS模型中显著优于现有方法。
视觉语言模型重编程下的通用深度伪造检测
Standing on the Shoulders of Giants: Reprogramming Visual-Language Model for General Deepfake Detection
Kaiqing Lin(深大), Yuzhen Lin(深大), Weixiang Li(深大), Taiping Yao, Bin Li(深大)
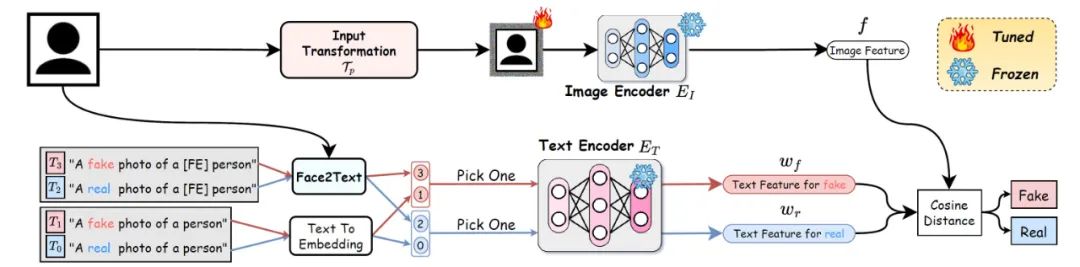
深度伪造技术的快速演进,不可避免地带来了一系列安全挑战。尽管近年来在深度伪造检测方面取得了实质性进展,但现有方法在应对来自未见过的数据集或由新兴生成模型创建的伪造图像时,其检测的泛化能力仍然受限。在本文中,考虑到视觉-语言模型(VLMs)的优秀泛化性,我们提出了一种新颖的方法,将一个训练良好的VLM迁移到通用深度伪造检测任务上。受模型重编程范式的启发,我们的方法仅通过调整输入来使用预训练的VLM模型(例如CLIP)进行深度伪造检测,而无需调整其内部参数。首先,我们使用可学习的视觉扰动来优化模型的特征提取以进行深度伪造检测。然后,我们利用人脸特征的信息创建样本级自适应文本提示,从而提高性能。在多个流行的基准数据集上进行的大量实验表明:(1)我们的方法在深度伪造检测中跨数据集和跨伪造方法的设置上可以显著地提高性能(例如,在从FF++到WildDeepfake的跨数据集设置中,模型性能AUC超过88%);(2)我们通过较少的可训练参数实现了卓越的性能,以更为高效地方式完成模型迁移
基于预训练文生图扩散模型的能量引导优化个性化图像编辑方法
Energy-Guided Optimization for Personalized Image Editing with Pretrained Text-to-Image Diffusion Models
Rui Jiang(浙大), Xinghe Fu(浙大), Guangcong Zheng(浙大), Teng Li, Taiping Yao, Xi Li(浙大)
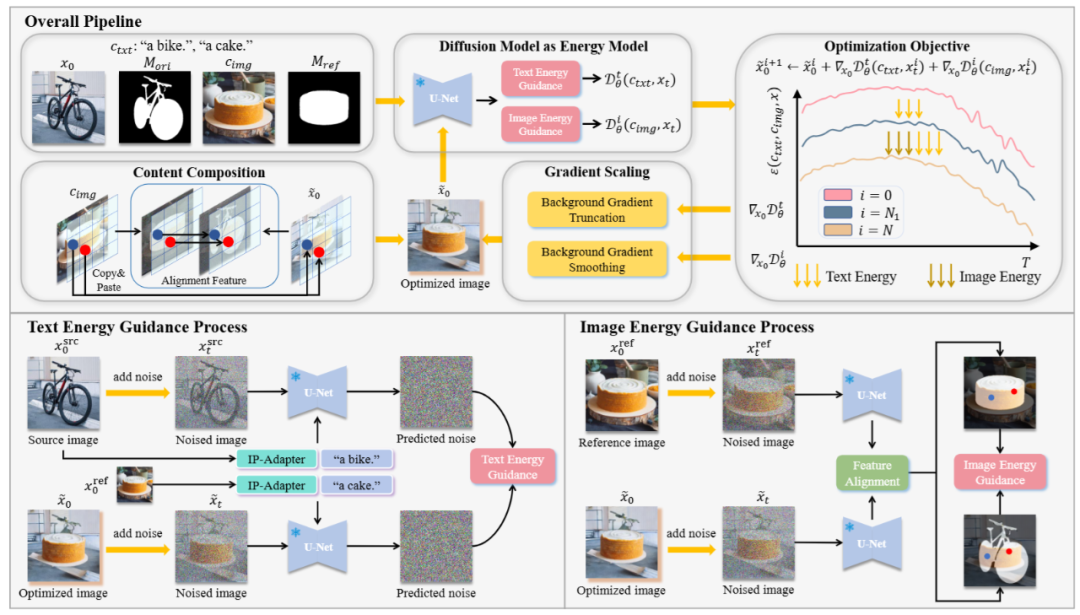
预训练文本驱动扩散模型的快速发展极大地丰富了图像生成和编辑中的应用。然而,随着个性化内容编辑需求的增加,新的挑战也随之出现,尤其是在处理任意目标对象和复杂场景时。现有方法通常将掩码认为是对象形状先验,难以实现目标物体的无缝合成。最常用的反转噪声初始化也阻碍了对目标对象的身份一致性。为了应对这些挑战,我们提出了一种新颖的免训练框架,将个性化内容编辑建模为隐空间中对图像的能量函数优化问题,使用扩散模型作为参考文本-图像对的能量函数指导。我们提出了一种由粗到细的策略,在早期阶段采用文本能量指导实现向目标类的自然过渡,并使用点对点特征级图像能量指导与目标对象进行细粒度外观对齐。此外,我们引入了隐空间内容组合以增强与目标的整体身份一致性。大量实验表明,即使原始图像和目标差异较大,我们的方法在对象替换方面也表现出色,凸显了其在高质量、个性化图像编辑方面的潜力。
基于球面线性插值的人脸模板保护
SlerpFace: Face Template Protection via Spherical Linear Interpolation
Zhizhou Zhong (复旦), Yuxi Mi(复旦), Yuge Huang, Jianqing Xu, Guodong Mu, Shouhong Ding, Jingyun Zhang(微信支付33号实验室), Rizen Guo(微信支付33号实验室), Yunsheng Wu, Shuigeng Zhou(复旦)
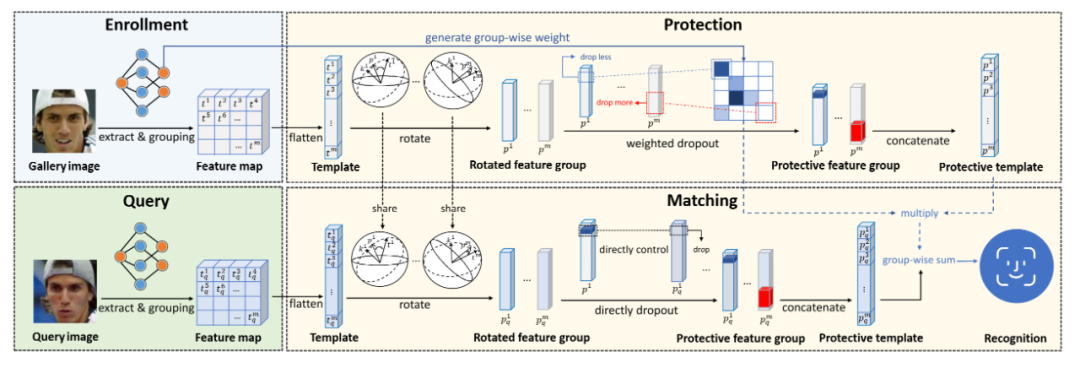
当前的人脸识别系统通常需要从人脸图像中提取特征来进行注册,这些特征被称为模板。这些模板包含了用户的相关信息,因此需要通过人脸模板保护技术来隐藏存储在模板中的属性信息。本文发现了一种新的基于扩散模型的人脸模板攻击方式,该方式可以从人脸特征中恢复原始人脸图像,使得以往的人脸特征保护方案效果不佳。基于对扩散模型生成能力的特性观察,本文提出了一种通过将模板旋转到近似高斯噪声的分布来进行防御的方法,名为SlerpFace。该方法通过在模板超球面上进行线性插值来有效实现特征模板保护,并进一步将旋转后的模板的特征进行分组和应用dropout,以增强旋转模板的不可逆性。通过各类实验证明,SlerpFace在识别效率、识别准确性和保护安全性方面均优于以往的方法。
论文链接:
https://arxiv.org/abs/2407.03043
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









