









7.3.3 实现Seq2Seq 模型
循环神经网络(RNN)是在序列上运行并将其自身的输出用作后续步骤的输入的网络。序列到序列网络或 seq2seq 网络或编码器解码器网络是由两个称为编码器和解码器的 RNN 组成的模型。编码器读取输入序列并输出单个向量,而解码器读取该向量以产生输出序列。如图7-5所示。
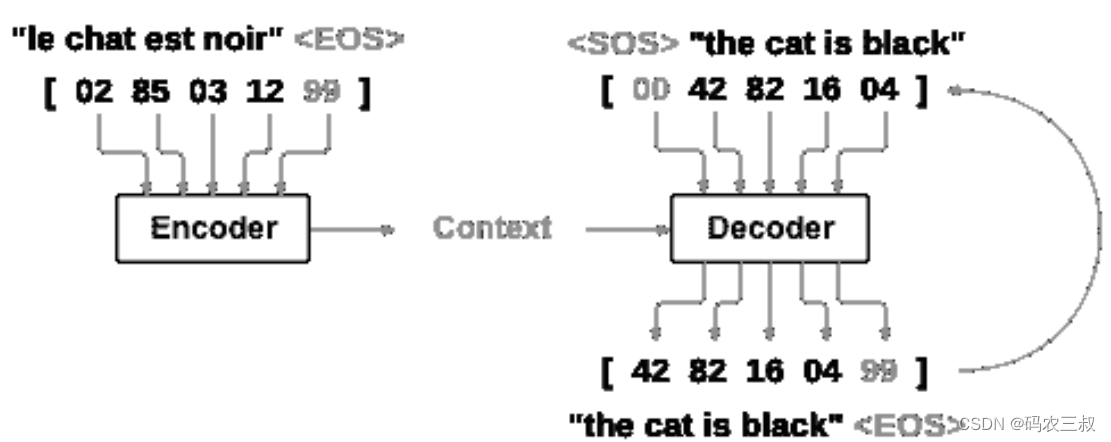
图7-5 Seq2Seq结构
与使用单个 RNN 进行序列预测(每个输入对应一个输出)不同,seq2seq 模型使我们摆脱了序列长度和顺序的限制,这使其非常适合两种语言之间的翻译。考虑一下下面句子的翻译过程:
Je ne suis pas le chat noir -> I am not the black cat
在输入句子中的大多数单词在输出句子中具有直接翻译,但是顺序略有不同,例如chat noir和black cat。由于采用ne/pas结构,因此在输入句子中还有一个单词。直接从输入单词的序列中产生正确的翻译将是困难的。通过使用 seq2seq 模型,在编码器中创建单个向量,在理想情况下,该向量将输入序列的“含义”编码为单个向量—在句子的 N 维空间中的单个点。
1. 编码器
seq2seq 网络的编码器是 RNN,它为输入句子中的每个单词输出一些值。 对于每个输入字,编码器输出一个向量和一个隐藏状态,并将隐藏状态用于下一个输入字。编码过程如图7-6所示。
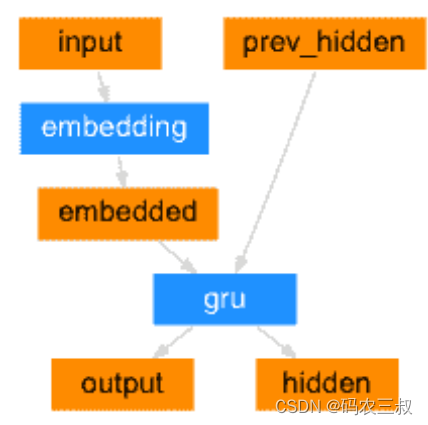
图7-6 编码过程
编写类EncoderRNN ,它是一个循环神经网络(Recurrent Neural Network,RNN)的编码器。这个类定义了编码器的结构和前向传播逻辑。编码器使用嵌入层将输入序列中的单词索引映射为密集向量表示,并将其作为 GRU 层的输入。GRU 层负责对输入序列进行编码,生成输出序列和隐藏状态。编码器的输出可以用作解码器的输入,用于进行序列到序列的任务,例如机器翻译。函数initHidden()用于初始化隐藏状态张量,作为编码器的初始隐藏状态。对应的实现代码如下所示:
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)2. 解码器
解码器是另一个 RNN,它采用编码器输出向量并输出单词序列来创建翻译。
(1)简单解码器
在最简单的 seq2seq 解码器中,仅使用编码器的最后一个输出。最后的输出有时称为上下文向量,因为它从整个序列中编码上下文。 该上下文向量用作解码器的初始隐藏状态。在解码的每个步骤中,为解码器提供输入标记和隐藏状态。 初始输入标记是字符串开始<SOS>标记,第一个隐藏状态是上下文向量(编码器的最后一个隐藏状态)。如图7-7所示。
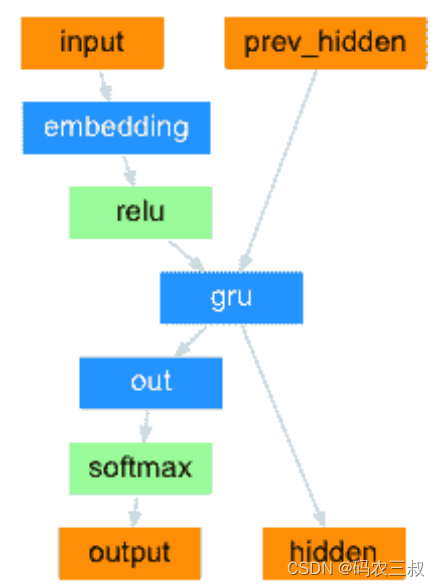
图7-7 简单解码器
定义类 DecoderRNN,这是一个循环神经网络(Recurrent Neural Network,RNN)的解码器。这个类定义了解码器的结构和前向传播逻辑。解码器使用嵌入层将输出序列中的单词索引映射为密集向量表示,并将其作为 GRU 层的输入。GRU 层负责对输入序列进行解码,生成输出序列和隐藏状态。解码器的输出通过线性层进行映射,然后经过 softmax 层进行概率归一化,得到最终的输出概率分布。initHidden 方法用于初始化隐藏状态张量,作为解码器的初始隐藏状态。对应的实现代码如下所示:
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)(2)注意力解码器
如果仅上下文向量在编码器和解码器之间传递,则该单个向量承担对整个句子进行编码的负担。使用注意使解码器网络可以针对解码器自身输出的每一步,“专注”于编码器输出的不同部分。 首先,计算一组注意力权重,将这些与编码器输出向量相乘以创建加权组合。 结果(在代码中称为attn_applied)应包含有关输入序列特定部分的信息,从而帮助解码器选择正确的输出字。如图7-8所示。
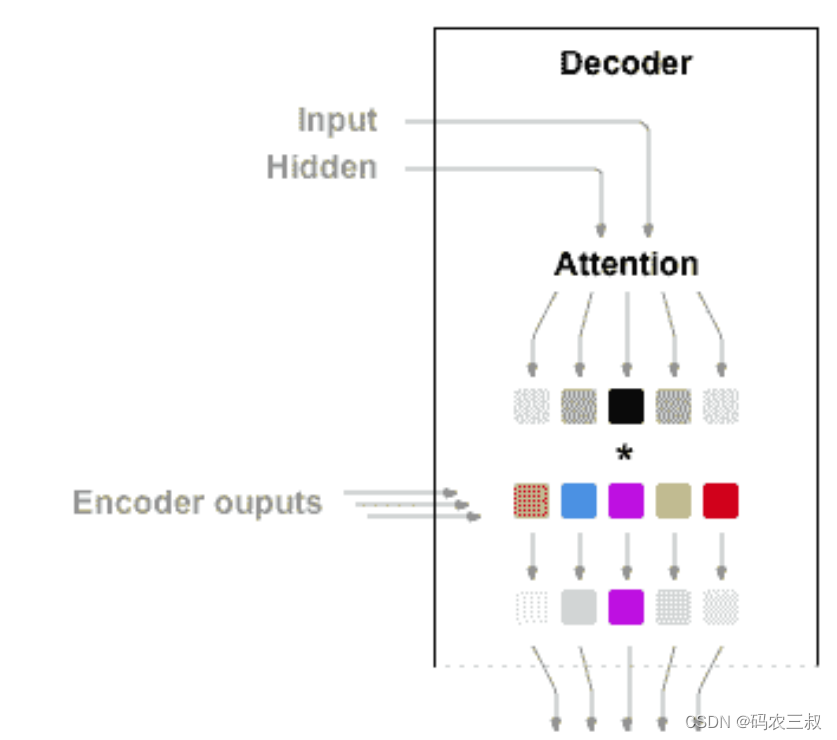
图7-8 注意力解码器
另一个前馈层attn使用解码器的输入和隐藏状态作为输入来计算注意力权重。 由于训练数据中包含各种大小的句子,因此要实际创建和训练该层,我们必须选择可以应用的最大句子长度(输入长度,用于编码器输出)。最大长度的句子将使用所有注意权重,而较短的句子将仅使用前几个。如图7-9所示。
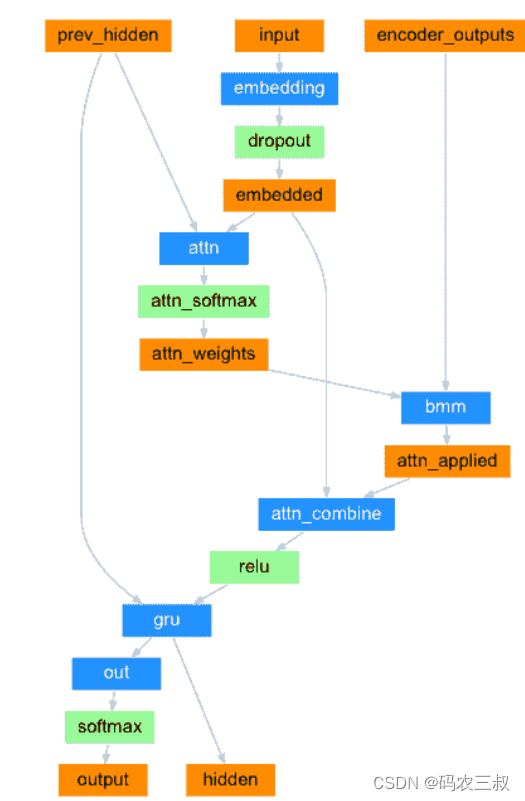
图7-9 前馈层attn
编写类AttnDecoderRNN实现具有注意力机制的解码器,对应的实现代码如下所示:
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)对类参数的具体说明如下:
- hidden_size:隐藏状态的维度大小。
- output_size:输出的词汇表大小(即词汇表中的单词数量)。
- dropout_p:dropout 概率,用于控制在训练过程中的随机失活。
- max_length:输入序列的最大长度。
对__init__()方法的具体说明如下:
- 初始化函数,用于创建并初始化 AttnDecoderRNN 类的实例。
- 调用父类的初始化方法 super(AttnDecoderRNN, self).__init__()。
- 将 hidden_size、output_size、dropout_p 和 max_length 存储为实例属性。
- 创建一个嵌入层(Embedding layer),用于将输出的单词索引映射为密集向量表示。该嵌入层的输入大小为 output_size,输出大小为 hidden_size。
- 创建一个线性层 attn,用于计算注意力权重。该线性层将输入的两个向量拼接起来,然后通过一个线性变换得到注意力权重的分布。
- 创建一个线性层 attn_combine,用于将嵌入的输入和注意力应用的上下文向量进行结合,以生成解码器的输入。
- 创建一个 dropout 层,用于在训练过程中进行随机失活。
- 创建一个 GRU 层,用于处理输入序列。该 GRU 层的输入和隐藏状态的大小都为 hidden_size。
- 创建一个全连接线性层,用于将 GRU 层的输出映射到输出大小 output_size。
对forward ()方法的具体说明如下:
- 前向传播函数,用于对输入进行解码并生成输出、隐藏状态和注意力权重。
- 接受输入张量 input、隐藏状态张量 hidden 和编码器的输出张量 encoder_outputs 作为输入。
- 将输入张量通过嵌入层进行词嵌入,然后进行随机失活处理。
- 将嵌入后的张量与隐藏状态张量拼接起来,并通过线性层 attn 计算注意力权重的分布。
- 使用注意力权重将编码器的输出进行加权求和,得到注意力应用的上下文向量。
- 将嵌入的输入和注意力应用的上下文向量拼接起来,并通过线性层 attn_combine 进行结合,得到解码器的输入。
- 将解码器的输入通过激活函数 ReLU 进行非线性变换。
- 将变换后的张量作为输入传递给 GRU 层,得到输出和更新后的隐藏状态。
- 将 GRU 的输出通过线性层 out 进行映射,并通过 LogSoftmax 函数计算输出的概率分布。
- 返回输出、隐藏状态和注意力权重。
对initHidden()方法的具体说明如下:
- 用于初始化隐藏状态张量,作为解码器的初始隐藏状态。
- 返回一个大小为 (1, 1, hidden_size) 的全零张量,其中 hidden_size 是隐藏状态的维度大小。

















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











