






从海量行为数据中识别用户偏好更精准的为用户推荐相关内容,一方面能满足用户个性化的需求,另外一方面也能提高对应的转化率。本文参考和整理【数据化运营】书中用户画像章节来看如何用TF-IDF等算法从海量的行为数据中挖掘用户偏好并进行应用。
以购物网站的图书类目为例,在售图书有上百万种,用户规模上亿,用户关于图书的行为有浏览、收藏/取消收藏、加购、评论、购买等,来看如何通过行为识别个体偏好并推荐相关类目书籍,以及如何识别群体偏好来更好的为新用户做冷启动。
1 为什么TF-IDF能用来识别用户在标签上的偏好
问题的核心是用什么指标来识别用户在标签上的偏好,最容易想到的是根据用户身上标签出现的频率来代表偏好。但这样带来的问题是,热门类型的书籍标签频率较高时,可能忽视掉用户在某个小众品类上的偏好。TF-IDF的分母能够对热门的商品进行惩罚,提高小众偏好的权重,识别出用户更加长尾的需求。接下来会介绍TF-IDF算法的计算方法,以及具体案例中该算法与直接用标签占比即TF的差异。
1.1 TF-IDF算法介绍
TF-IDF算法的全称是Term Frequency - Inverse Document Frequency,即词频-逆文档频率,被用在文章自动打标签中,其出发点是一个词语的重要程度和该词语在本文章出现的频率成正比即TF,和这个词语在所有文章中出现的频率成反比即IDF,这样就能过滤掉“了”、“的”、“么”等这些高频出现的助词,保留对文章中真正重要的关键词。
将其用在用户对图书标签的偏好识别时,对于每个用户来说,统计出来的用户行为中,某个标签出现的次数越多,说明该标签对用户来说越重要,同时该标签在所有用户中的所有标签中出现的次数越高,该标签对用户的重要性越低。用代表某用户,
代表某标签,
表示标签
被标记到用户
上的次数,TF的计算公式如下:
IDF的计算公式如下:
用户和标签
之间的关系用
表示,其计算公式为:
1.2 TF-IDF计算出结果示例
如下是用户A、B、C在a、b、c、d、e五个标签下的浏览行为数据,(4,5,0)代表用户A、B、C在a这个标签下的浏览次数,将其处理为右侧的excel表,接下来看一下TF-IDF如何计算。
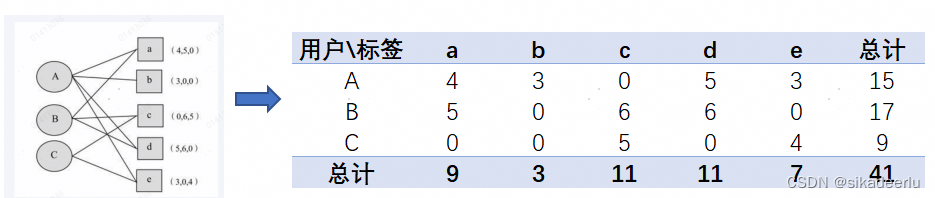
计算TF,以A用户下a标签为例,计算公式为 4/15 = 27%,得到结果如下,最后一列是按照TF即用户身上标签的频率计算出来的标签重要性排序:

计算IDF,以a标签为例,计算公式为 log(41/9) = 66%,结算结果如下:

计算TF-IDF,以A用户下a标签为例,计算公式为 4/15 * log(41/9) = 18%

可以看到两者计算出来的用户偏好排序差异还是挺大的,如果商品越来越多,这种差异会更明显。
2 如何在sql中计算用户对标签的偏好
2.1 用户特定行为下标签权重
以上一节的数据为例,将其存储在dwd.persona_user_tag_relation_public表中
drop table if exists dwd.persona_user_tag_relation_public;
create table dwd.persona_user_tag_relation_public --用户属性表
(
user_id string comment '用户编码',
tag_id string comment '标签id',
tag_name string comment '标签名称',
cnt int comment '行为次数',
date_id timestamp comment '行为日期',
tag_type_id int comment '标签类型',
act_type_id int comment '行为类型'
)
comment '用户画像-用户行为标签表';
insert into table dwd.persona_user_tag_relation_public
values('A', 'a', 'a', 4, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('B', 'a', 'a', 5, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('A', 'b', 'b', 3, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('B', 'c', 'c', 6, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('C', 'c', 'c', 5, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('A', 'd', 'd', 5, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('B', 'd', 'd', 6, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('A', 'e', 'e', 3, '2017-10-01', 1, 1);
insert into table dwd.persona_user_tag_relation_public
values('C', 'e', 'e', 4, '2017-10-01', 1, 1);计算每个用户身上标签的tf-ifd值
-- tf-idf 计算代码 计算的是用户身上被打上标签的权重
-- 分子:用户身上该标签总数/用户身上总标签数
drop table if exists dwd.tag_weight_of_tfidf_01;
CREATE TABLE dwd.tag_weight_of_tfidf_01
AS
SELECT t1.user_id
,t1.tag_id
,t1.tag_name
,t1.weight_m_p --用户身上每个标签个数
,t2.weight_m_s --用户身上标签总数
FROM
(
SELECT t.user_id
,t.tag_id
,t.tag_name
,COUNT(t.tag_id) AS weight_m_p --用户身上每个标签个数
FROM dwd.persona_user_tag_relation_public t
GROUP BY t.user_id
,t.tag_id
,t.tag_name
) t1
LEFT JOIN
(
SELECT t.user_id
,COUNT(t.tag_id) AS weight_m_s --用户身上标签总数
FROM dwd.persona_user_tag_relation_public t
GROUP BY t.user_id
) t2
ON t1.user_id = t2.user_id
GROUP BY t1.user_id
,t1.tag_id
,t1.tag_name
,t1.weight_m_p
,t2.weight_m_s;
-- 分母:该标签总数/总的标签数
drop table if exists dwd.tag_weight_of_tfidf_02;
CREATE TABLE dwd.tag_weight_of_tfidf_02
AS
SELECT t1.tag_id
,t1.tag_name
,t1.weight_w_p --每个标签在全体标签中共有多少个
,t2.weight_w_s --全体所有标签的总个数
FROM
(
SELECT t.tag_id
,t.tag_name
,SUM(weight_m_p) AS weight_w_p
FROM dwd.tag_weight_of_tfidf_01 t
GROUP BY t.tag_id
,t.tag_name
) t1
CROSS JOIN
(
SELECT SUM(t.weight_m_p) AS weight_w_s
FROM dwd.tag_weight_of_tfidf_01 t
) t2;
-- TF-IDF计算每个用户身上标签权重
drop TABLE IF EXISTS dwd.tag_weight_of_tfidf_03;
CREATE TABLE dwd.tag_weight_of_tfidf_03 AS
SELECT t1.user_id
,t1.tag_id
,t1.tag_name
,(t1.weight_m_p/t1.weight_m_s)*(log10(t2.weight_w_s/t2.weight_w_p)) AS ratio
FROM dwd.tag_weight_of_tfidf_01 t1
LEFT JOIN dwd.tag_weight_of_tfidf_02 t1
ON t1.tag_id = t2.tag_id
GROUP BY t1.user_id
,t1.tag_id
,t1.tag_name
,(t1.weight_m_p/t1.weight_m_s)*(log10(t2.weight_w_s/t2.weight_w_p));2.2 用户对标签的整体权重
2.2.1 行为类型权重表
对于行为类型来说,具有以下三个特征,首先不同的行为类型代表的业务复杂程度不同,复杂程度越高越说明用户对其的偏好越强,对应的权重就应该越高,购买行为的权重应该比浏览的重高。其次用户行为有正向、负向,收藏代表的用户偏好是正向的,而取消收藏应该为负向。最后用户行为有一定的时效性,很久之前的行为对于用户当前来说的意义越小。如下是用户行为类型权重表,记录行为类型权重对应的特征。
drop table if exists dwd.act_weight_plan_detail;
create table dwd.act_weight_plan_detail(
act_type_id int comment '行为类型',
act_weight_detail comment '行为权重',
date_id date comment '维表创建日期',
is_time_reduce int comment '是否时间衰减')
comment '用户画像-用户行为权重维表';
--向行为权重维表中插入数据
-- is_time_reduce: 1 衰减 0 不衰减
insert into dwd.act_weight_plan_detail
values(1, 1.5, '2017-10-01',1); --1:购买行为 权重 1.5
insert into dwd.act_weight_plan_detail
values(2, 0.3, '2017-10-01',1); --2:浏览行为 权重 0.3
insert into dwd.act_weight_plan_detail
values(3, 0.5, '2017-10-01',0); --3:评论行为 权重 0.5
insert into dwd.act_weight_plan_detail
values(4, 0.5, '2017-10-01',1); --4:收藏行为 权重 0.5
insert into dwd.act_weight_plan_detail
values(5, -0.5, '2017-10-01',0); --5:取消收藏行为 权重 -0.5
insert into dwd.act_weight_plan_detail
values(6, 1, '2017-10-01',0); --6:加入购物车行为 权重 1
insert into dwd.act_weight_plan_detail
values(7, 0.8, '2017-10-01',1) --7:搜索行为 权重 0.8
2.2.2 用户行为标签权重
考虑行为的三个特征,用户最终在标签下的权重计算公式为: 行为类型权重 * 时间衰减系数 * 行为次数 * TF-IDF值。
drop table if exists dwd.person_user_tag_relation_weight;
create table dwd.person_user_tag_relation_weight --用户行为标签权重表
(
user_id string comment '用户编码',
tag_id string comment '标签id',
tag_name string comment '标签名称',
cnt int comment '行为次数',
tag_type_id int comment '标签类型',
date_id date comment '行为日期',
act_weight int comment '权重值'
)
comment '用户画像-用户行为标签权重表';
INSERT INTO dwd.person_user_tag_relation_weight
SELECT t1.user_id
,t1.tag_id
,t1.tag_name
,t1.cnt
,t1.date_id
,t1.tag_type_id
,CASE WHEN t2.is_time_reduce = 1 THEN exp(datediff('2017-10-01',t1.date_id) * (-0.1556)) * t2.act_weight * t1.cnt * t3.ratio --随时间衰减行为
WHEN t2.is_time_reduce = 0 THEN t2.act_weight * t1.cnt * t3.ratio --不随时间衰减行为
END AS act_weight
FROM dwd.persona_user_tag_relation_public t1 --用户行为标签表
INNER JOIN dwd.act_weight_plan_detail t2 -- 行为权重维表
ON t1.tag_type_id = t2.act_type_id --通过行为类型关联
INNER JOIN dwd.tag_weight_of_tfidf_03 t3 --TF-IDF标签权重表
ON (t1.user_id = t3.user_id AND t1.tag_id = t3.tag_id) --用户id和标签id两个字段做主键关联
WHERE t1.date_id <= '2017-10-01' --以'2017-10-01'作为当前日期, 跑批历史数据
GROUP BY t1.user_id
,t1.tag_id
,t1.tag_name
,t1.cnt
,t1.date_id
,t1.tag_type_id
,CASE WHEN t2.is_time_reduce = 1 THEN exp(datediff('2017-10-01',t1.date_id) * (-0.1556)) * t2.act_weight * t1.cnt * t3.ratio --随时间衰减行为
WHEN t2.is_time_reduce = 0 THEN t2.act_weight * t1.cnt * t3.ratio END;2.2.3 用户关于标签的最终权重计算
用户最终在标签上的权重,只需要按用户对应标签的权重即可。
drop TABLE dwd.person_user_tag_relation_weight_finall;
CREATE TABLE dwd.person_user_tag_relation_weight_finall AS
SELECT user_id
,org_id
,org_name
,SUM(act_weight) AS weight
,ROW_NUMBER() over(order by SUM(act_weight) DESC) AS rank
FROM dwd.person_user_tag_relation_weight
GROUP BY user_id
,org_id
,org_name;3 如何根据用户偏好来推荐相关书籍
计算用户对各个标签的权重加总,然后从高到低排序,排名靠前的即为用户当前最关心的标签类型,接着基于物品的协同过滤找到用户偏好的标签,该方法先将用户标签表的数据以正交的方式相关联,找到两两标签共同拥有的用户人数即词频正交矩阵,然后通过余弦相似度来计算两两标签之间的相关性。举例来说:假设Na为喜欢a物品的人,Nb为喜欢b物品的人,N(a,b)为共同喜欢a和b的人,可以用N(a,b)/sqrt(N(a) * N(b)) 来标识物品a和b之间的相关性。如下是对应的代码:
drop table if exists dwd.user_prefer_peasona_tag;
create table dwd.user_prefer_peasona_tag --用户偏好画像表
(
user_id string comment '用户编码',
tag_id string comment '标签id',
tag_name string comment '标签名称',
recommend string comment '推荐值'
)
comment '用户画像-用户偏好画像表';
-- 01 取用户近期1个月的行为标签权重信息
drop TABLE dwd.user_prefer_peasona_user_tag_01;
CREATE TABLE dwd.user_prefer_peasona_user_tag_01 AS
SELECT user_id
,org_id
,org_name
,cnt
,date_id
,tag_type_id
,act_type_id
FROM dwd.persona_user_tag_relation_public --用户行为标签表
WHERE date_id >= date_sub(from_unixtime(unix_timestamp(), 'yyyy-MM-dd'), 31)
AND date_id <= date_sub(from_unixtime(unix_timestamp(), 'yyyy-MM-dd'), 1) --示例 抽取近一个月的标签行为
AND act_type_id IN (1, 3, 4, 6, 7) --取用户购买、评论、收藏、加入购物车、搜索行为带来的标签
GROUP BY user_id
,org_id
,org_name
,cnt
,date_id
,tag_type_id
,act_type_id;
-- 02 计算每个标签下对应的用户数
drop TABLE dwd.user_prefer_peasona_user_tag_02;
CREATE TABLE dwd.user_prefer_peasona_user_tag_02 AS
SELECT org_id --标签id
,org_name
,COUNT(distinct user_id) user_num --有该标签的用户数
,ROW_NUMBER() OVER (order by COUNT(distinct user_id) DESC) rank
FROM dwd.user_prefer_peasona_user_tag_01
GROUP BY org_id
,org_name;
-- 03 计算共现矩阵,即共同拥有两个标签的用户数
drop TABLE dwd.user_prefer_peasona_user_tag_03;
CREATE TABLE dwd.user_prefer_peasona_user_tag_03 AS
SELECT t.org_id_1
,t.org_name_1
,t.org_id_2
,t.org_name_2
,t.num
FROM
(
SELECT t1.org_id org_id_1
,t1.org_name org_name_1
,t2.org_id org_id_2
,t2.org_name org_name_2
,COUNT(distinct t1.user_id) AS num
FROM dwd.user_prefer_peasona_user_tag_01 t1
CROSS JOIN dwd.user_prefer_peasona_user_tag_01 t2
WHERE t1.user_id <> t2.user_id --不同的用户
GROUP BY t1.org_id
,t1.org_name
,t2.org_id
,t2.org_name
) t;
-- 04 通过余弦函数计算标签之间的相关性
drop TABLE dwd.user_prefer_peasona_user_tag_04
CREATE TABLE dwd.user_prefer_peasona_user_tag_04 AS
SELECT t1.org_id_1 --第一个标签id
,t1.org_name_1 --第一个标签名称
,t2.user_num_1 --第一个标签人数
,t1.org_id_2 --第二个标签id
,t1.org_name_2
,t3.user_num_2
,t1.num --两个标签共同的用户人数
,(t1.num/sqrt(t2.user_num_1 * t3.user_num_2)) AS power
,ROW_NUMBER() over(order by (t1.num/sqrt(t2.user_num_1 * t3.user_num_2)) DESC) rank
FROM dwd.user_prefer_peasona_user_tag_03 t1
LEFT JOIN
(
SELECT org_id
,user_num AS user_num_1
FROM dwd.user_prefer_peasona_user_tag_02
) t2
ON t1.org_id_1 = t2.org_id
LEFT JOIN
(
SELECT org_id
,user_num AS user_num_2
FROM dwd.user_prefer_peasona_user_tag_02
) t3
ON t1.org_id_2 = t3.org_id
GROUP BY t1.org_id_1
,t1.org_name_1
,t2.user_num_1
,t1.org_id_2
,t1.org_name_2
,t3.user_num_2
,t1.num
,(t1.num/sqrt(t2.user_num_1 * t3.user_num_2));
-- 05 汇总用户在标签下的所有行为权重之和
drop TABLE dwd.user_prefer_peasona_user_tag_05;
CREATE TABLE dwd.user_prefer_peasona_user_tag_05 AS
SELECT user_id
,org_id
,org_name
,SUM(act_weight) AS weight
,ROW_NUMBER() over(order by SUM(act_weight) DESC) AS rank
FROM dwd.person_user_tag_relation_weight --用户标签权重表
WHERE act_type_id IN (1, 3, 4, 6, 7)
--取用户购买、评论、收藏、加入购物车、搜索行为带来的标签
GROUP BY user_id
,org_id
,org_name;
-- 06 根据用户历史的偏好标签关联出相似的标签,并取前10个相关性高的标签
INSERT INTO dwd.user_prefer_peasona_tag --数据插入用户偏好画像表
SELECT t.user_id
,t.tag_id
,t.tag_name
,t.recommend
FROM
(
SELECT t1.user_id
,t2.org_id_2 AS tag_id --推荐的标签
,t1.org_name_2 AS tag_name
,SUM(t1.weight * t2.power) AS recommend
,ROW_NUMBER() OVER (order by SUM(t1.weight * t2.power) DESC) AS row_rank
FROM dwd.user_prefer_peasona_user_tag_05 t1 --用户历史偏好标签
LEFT JOIN dwd.user_prefer_peasona_user_tag_04 t2 --标签相似度表
ON t1.org_id = t2.org_id_1
GROUP BY t2.user_id
,t1.org_id_2
,t1.org_name_2
) t
WHERE t.row_rank <= 10 --每个用户取前10个推荐的标签
;4 获取用户群体的偏好标签
群体画像的偏好标签可通过每个用户的偏好标签表汇总得到,首先将用户打上对应的群体画像属性,然后按照群体画像的属性进行汇总计算对应的标签的偏好权重之和,接着同样利用tf-idf计算偏好。分子是:该群体下该标签的权重之和/该群体下所有标签的权重之和,分母是:该标签的权重之和/所有标签的权重之和。具体代码如下:
drop table if exists dwd.person_groups_perfer_books;
create table dwd.person_groups_perfer_books --群体用户画像表
(
age string comment '年龄段',
sex string comment '性别',
tag_id string comment '标签id',
tag_name string comment '标签名称'
)
comment '用户画像-群体用户画像';
drop TABLE IF EXISTS dwd.person_groups_temp_age;
CREATE TABLE dwd.person_groups_temp_age AS
SELECT user_id
,CASE WHEN gender_id = 0 THEN '男性'
WHEN gender_id = 1 THEN '女性' ELSE '其他' END AS user_sex
,CASE WHEN age >= 0 AND age <= 8 THEN '儿童'
WHEN age >= 8 AND age <= 16 THEN '少年'
WHEN age >= 17 AND age <= 40 THEN '青年'
WHEN age >= 41 AND age <= 60 THEN '中年'
WHEN age >= 61 THEN '老年' ELSE '其他' END AS user_age
FROM dwd.user_profile_basic_informatin --用户属性表
WHERE user_id is not null;
drop TABLE IF EXISTS dwd.tmp_person_groups_prefer_01;
CREATE TABLE dwd.tmp_person_groups_prefer_01 AS
SELECT t1.user_id
,t1.tag_id --标签id
,t1.tag_name --标签名称
,t1.act_weight --标签权重
,t2.user_sex --用户性别
,t2.user_age --用户年龄段
FROM dwd.person_user_tag_relation_weight t1 --用户标签权重表
INNER JOIN dwd.person_groups_temp_age t2 --用户年龄分段临时表
ON t1.user_id = t2.user_id
GROUP BY t1.user_id
,t1.tag_id
,t1.tag_name
,t1.act_weight
,t2.user_sex
,t2.user_age;
-- 使用TF-IDF计算用户人群标签总权重 drop TABLE dwd.tmp_person_groups_man_prefer_sum;
CREATE TABLE dwd.tmp_person_groups_man_prefer_sum AS
SELECT t1.tag_id
,t1.weight_w_p --全体用户中某个图书的总权重值
,t1.weight_w_s --全体用户中所有图书的总权重值
FROM
(
SELECT tag_id
,SUM(act_weight) AS weight_w_p
FROM dwd.tmp_person_groups_prefer_01
GROUP BY tag_id
) t1
CROSS JOIN
(
SELECT SUM(act_weight) AS weight_w_s
FROM dwd.tmp_person_groups_prefer_01
);
-- 使用TF-IDF算法计算男性各年龄段的偏好图书标签
drop TABLE IF EXISTS dwd.tmp_person_groups_man_prefer_01;
CREATE TABLE dwd.tmp_person_groups_man_prefer_01 AS
SELECT t1.user_sex
,t1.user_age
,t1.tag_id --标签id
,t1.tag_name --标签名称
,t1.weight_m_p --男性、儿童中某个图书的总权重值
,t2.weight_m_s --男性、儿童中所有图书的总权重值
FROM
(
SELECT user_sex
,user_age
,tag_id
,tag_name
,SUM(act_weight) AS weight_m_p
,
FROM dwd.tmp_person_groups_prefer_01
WHERE user_age = '儿童'
AND user_sex = '男性'
GROUP BY user_sex
,user_age
,tag_id
,tag_name
) t1
CROSS JOIN
(
SELECT SUM(act_weight) AS weight_m_s
FROM dwd.tmp_person_groups_prefer_01
WHERE user_age = '儿童'
AND user_sex = '男性'
) t2;
-- 单个图书标签对男性 儿童的相关度
drop TABLE IF EXISTS dwd.tmp_person_groups_man_tfidf_prefer_01;
CREATE TABLE dwd.tmp_person_groups_man_tfidf_prefer_01 AS
SELECT t1.user_sex --用户性别
,t1.user_age --用户年龄段
,t1.tag_id --标签id
,t1.tag_name --标签类型
,t1.weight_m_p
,t1.weight_m_s
,t2.weight_w_p
,t2.weight_w_s
,(t1.weight_m_p/t1.weight_m_s)/(t2.weight_w_p/t2.weight_w_s) AS ratio
FROM dwd.tmp_person_groups_man_prefer_01 t1 --t1记录男性、儿童中某个图书的总权重值及所有图书的总权重值
LEFT JOIN dwd.tmp_person_groups_man_prefer_sum t2
--t2表记录某个图书的总权重值及全部图书总权重值
ON t1.tag_id = t2.tag_id;
-- 取出男性儿童人群中最偏好的前10个图书标签
drop TABLE IF EXISTS dwd.person_groups_perfer_books;
CREATE TABLE dwd.person_groups_perfer_books AS
SELECT '儿童' AS age
,'男性' AS sex
,tag_id
,tag_name
FROM dwd.tmp_person_groups_man_tfidf_prefer_01
ORDER BY ratio DESC --按相关度的大小做倒排序
LIMIT 10;
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









