







论文地址:Lift,Splat,Shoot:Encoding images from Arbitrary Camera Rigs by implicitly Unprojecting to 3D
1 前言:
Lift Splat Shoot算法是自动驾驶感知算法的开山之作,由NVIDIA于2020年提出,也是从2D到3D正投影算法的开山之作。其主要思想是通过车顶的6个环状相机进行360°视野感知,通过每个相机的图像特征进行深度估计D,构建出一个空间的伪点云(不是真实的点云,其本质是一个视锥),也就是lift操作;之后再通过Splat操作,将3D的特征拍扁到一个200 X 200的一个二维俯视特征图中(也就是熟知的BEV特征),之后再通过常用的一些二维图像的处理方法(卷积、池化等)对BEV特征进行图像特征提取。这样就巧妙地将不同视角的相机提取出的特征都投射到一个共同的一个特征图上进行特征提取。
在自动驾驶感知算法的设计中,Lift Splat Shoot算法的核心考量在于如何精准设定BEV(鸟瞰图)的感知范围、BEV单元格尺寸以及深度估计的阈值。感知范围的设置决定了算法在水平方向上(即x轴和y轴)能够覆盖的感知距离;BEV单元格尺寸的确定则影响了BEV图像中每个独立单元的大小;而深度估计的阈值则限定了算法在Lift Splat Shoot过程中需要预测和计算的离散深度值的范围。
2 pipeline
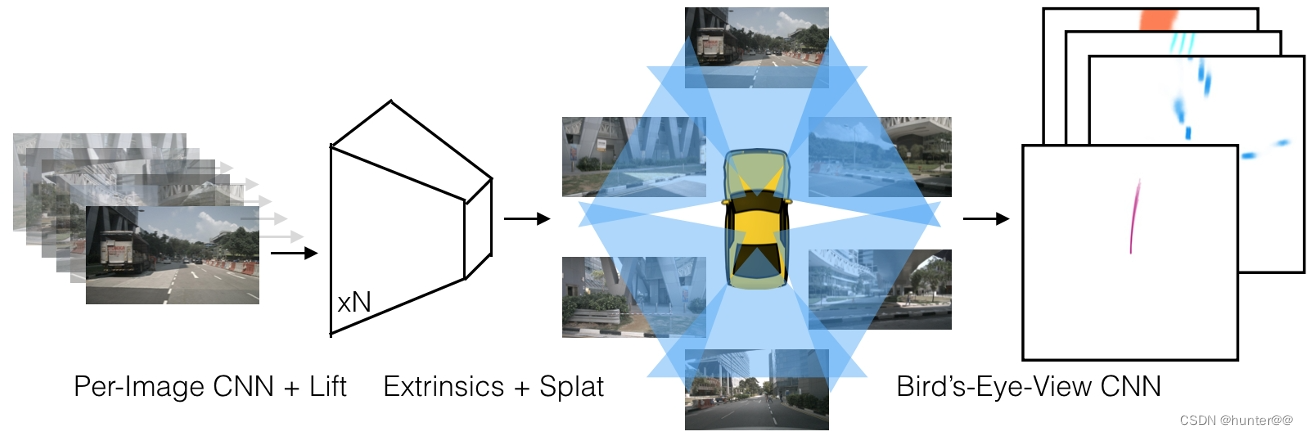
个人理解:
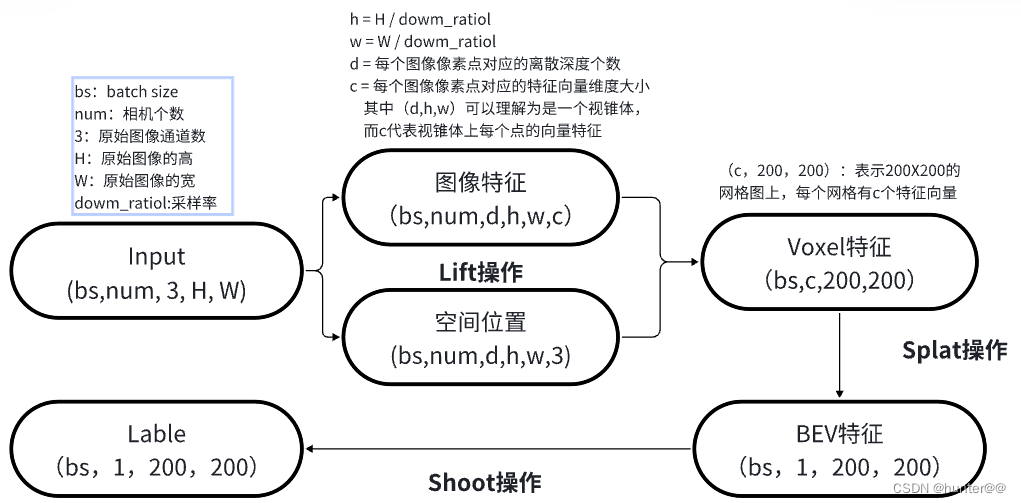
2.1 Lift:2D → 3D 转换模块
Lift 操作主要分为两部分,一个是图像特征的提取,另一个是空间视锥体的建立,其构建过程如图2所示,下面主要分别介绍一下这两个部分。
2.1.1 图像特征提取
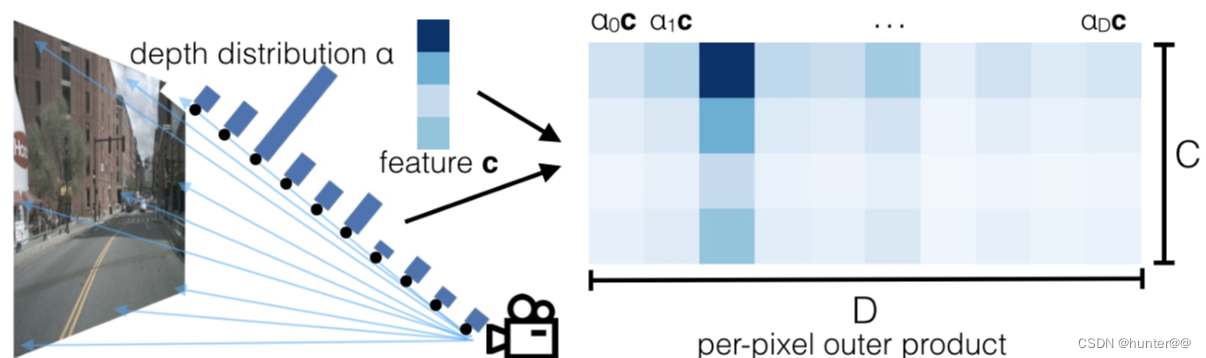
2.1.1.1 原理:
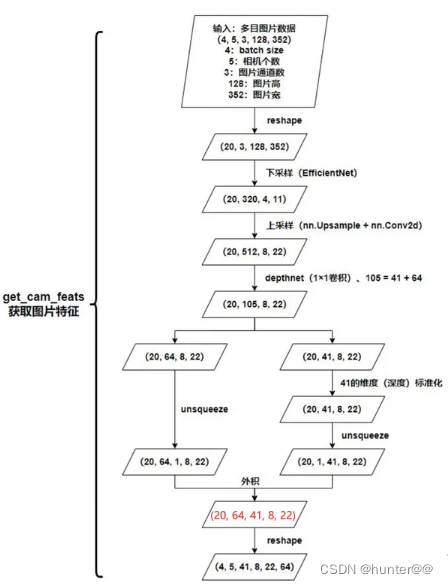
图像特征抽取是 lift 操作中最简单易懂的一环,极其类似于2D图像中处理方式。使用2D图像的backbone进行特征抽取(论文中选择的是EfficientNet网络),其与2D图像处理任务的最大区别主要体现在head上,一般常见的图像分类任务最后将 H,W 这两个维度进行合并,然后max pooling操作,取 C 维度进行特征分类,之后会再接一个分类头(其维度大小等于num_class,也就是数据集类别的数目)。但是LSS中图像特征提取模块没有这么做,它其实接的head的维度大小是D,也就是depth,这里可以理解为它对每一个像素都预测了 D 个深度,如图4左侧所示;然后其最后输出的特征维度大小一般为(bs,num,d,h,w,c),这里(d,h,w)其实就可以理解为一个空间中 d x h x w 个点的集合,而 c 就表示这个集合中点的特征, 这里用一个比较抽象的图像来简单说明一下,如图4右侧所示(每一个点其实表示的是一个特征向量)。
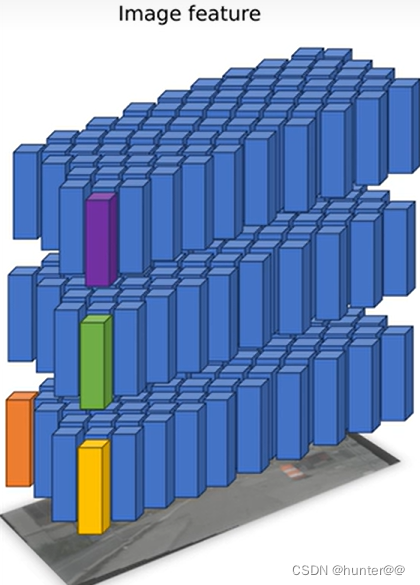
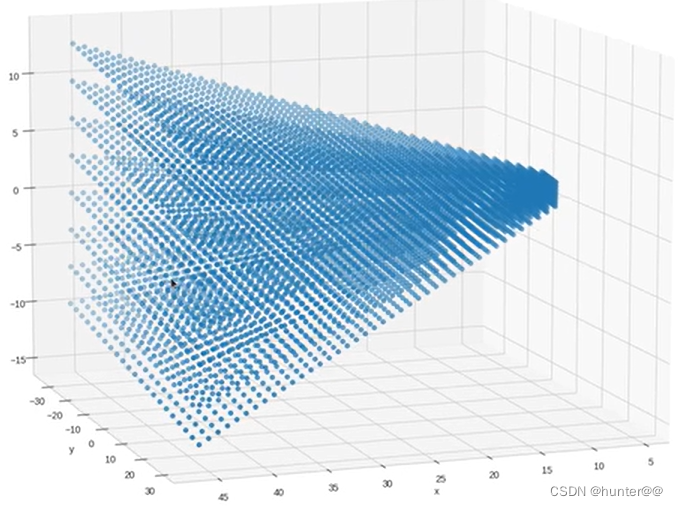
图 4
这里我也放一张别人画的图像经过 EfficientNet网络进行特征压缩的流程图,也将每一层特征变化的过程画了出来,可以参考一下。
2.1.1.2 代码:
代码如下,其实这部分代码都比较熟悉,此处就不做过多的概述了(get_eff_depth函数其实可以理解为对加载的预训练EfficientNet网络的权重做了一些dropout处理)。
class Up(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super().__init__()
self.up = nn.Upsample(scale_factor=scale_factor, mode='bilinear',
align_corners=True)
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x1, x2):
x1 = self.up(x1)
x1 = torch.cat([x2, x1], dim=1)
return self.conv(x1)
class CamEncode(nn.Module):
def __init__(self, D, C, downsample):
super(CamEncode, self).__init__()
self.D = D
self.C = C
self.trunk = EfficientNet.from_pretrained("efficientnet-b0")
self.up1 = Up(320+112, 512)
self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)
def get_depth_dist(self, x, eps=1e-20):
return x.softmax(dim=1)
def get_depth_feat(self, x):
x = self.get_eff_depth(x)
# Depth
x = self.depthnet(x) # 每个像素预测 D + C 个深度信息
depth = self.get_depth_dist(x[:, :self.D]) # 但是只选择D个深度
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)
return depth, new_x
def get_eff_depth(self, x):
# adapted from https://github.com/lukemelas/EfficientNet-PyTorch/blob/master/efficientnet_pytorch/model.py#L231
endpoints = dict()
# Stem 主干部分
x = self.trunk._swish(self.trunk._bn0(self.trunk._conv_stem(x)))
prev_x = x
# Blocks 模型块部分
for idx, block in enumerate(self.trunk._blocks):
drop_connect_rate = self.trunk._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self.trunk._blocks) # scale drop connect_rate
x = block(x, drop_connect_rate=drop_connect_rate)
if prev_x.size(2) > x.size(2):
endpoints['reduction_{}'.format(len(endpoints)+1)] = prev_x
prev_x = x
# Head 模型的预测头部分
endpoints['reduction_{}'.format(len(endpoints)+1)] = x
x = self.up1(endpoints['reduction_5'], endpoints['reduction_4']) # concat操作
return x
def forward(self, x):
depth, x = self.get_depth_feat(x)
return x2.1.2 空间视锥建立
2.1.2.1 原理:
在讲这里之前,大家可以思考一下,就是都已经有之前图像提取的3d特征(伪点云),但是为什么还需要构建3D视锥,它的作用是啥?它为啥这里要用到相机的内外参,而不是在之前提取图像特征的时候使用?
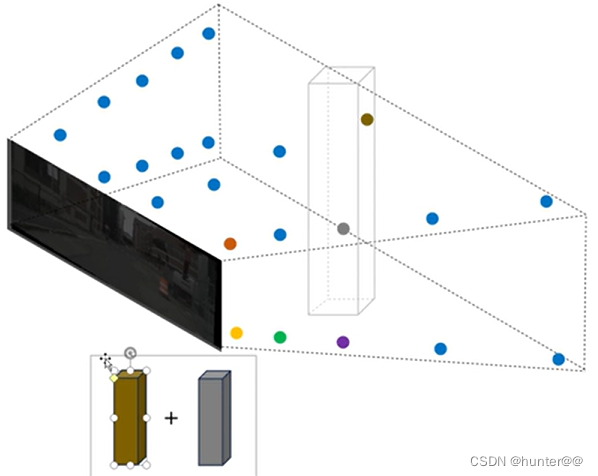
首先这里 create_frustum 的主要目的是创建一个映射表,使得我们的每一视锥上的点都有对应的特征值,简单来说就是(D X H X W)个点的集合,都对应一个(x,y,z)坐标,这里使用的是python中的expend机制,其实就是扩维,然后进行复制,最后在torch.stack起来,这样就构成了(D X H X W X 3)这个维度,通俗来说,就是D X H X W 个集合中的点,每一个都对应3个值,分别(x,y,z)。这里也简单做了一张可视化的图,展示一下stack后的结果。
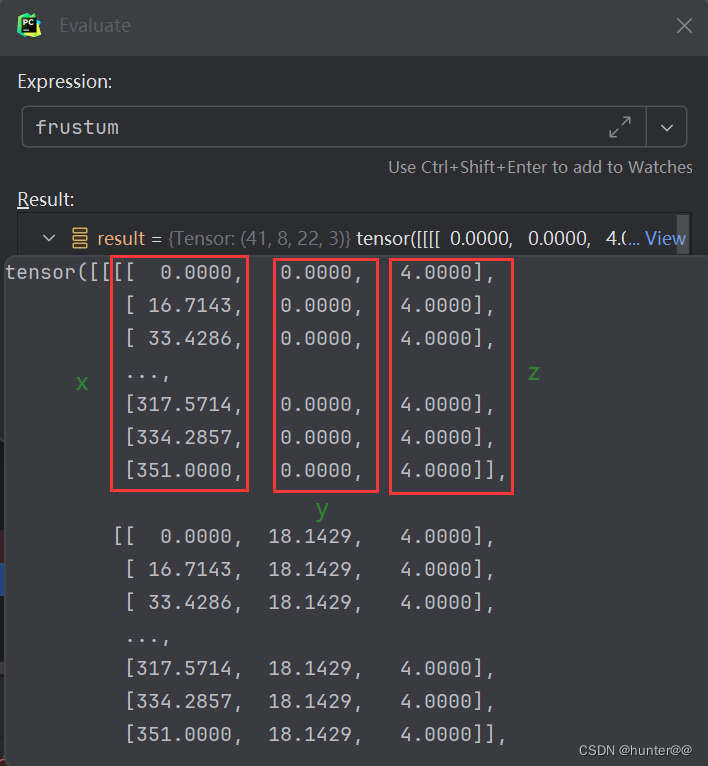
但是这里构建的点(x,y,z)主要是在相机坐标系下,但是我们需要的是鸟瞰图下的坐标信息,也就是车体坐标系下的(x,y,z),这中间就会涉及到一个坐标系的变化。其实在get_memory函数中就可以看到,其主要是对point变量中的最后一个维度进行矩阵变换,因为其中存储的是(x,y,z)坐标信息。(注意:(D,H,W )其实都是特征,不能对特征进行空间变化)
注意:这里(x,y,z)为啥一开始就表示相机坐标系下的坐标信息,而不是车体坐标系下的坐标信息,其实我也不太理解,我个人理解,可能是它创建方式的问题:因为它是构建映射表的过程完全是对标图像特征提取的过程,连前面的shape和H、W都一样的,所以自然而然就认为其是相机坐标系下的坐标信息。
2.1.2.2 代码:
创建视锥的代码部分
def create_frustum(self):
# make grid in image plane 创建视锥
ogfH, ogfW = self.data_aug_conf['final_dim'] # 数据增强后图像的最终尺寸或维度 ogfh: 128, ogfw: 352
fH, fW = ogfH // self.downsample, ogfW // self.downsample # 卷积神经网络下采样之后的图像尺寸大小 fH: 8 fW: 22
# 关于torch.expand()的描述,关键的理解是它不会真正地“扩展”或“复制”张量中的数据,而是创建了一个新的张量视图(view),这个视图在逻辑上拥有不同的形状,但实际上在物理内存中仍然引用原始张量的数据。
# xs 是一个包含所有点 x 坐标的张量,形状为[D, fH, fW]。
# ys 是一个包含所有点 y 坐标的张量,形状也为[D, fH, fW]。
# ds 是一个包含所有点深度值的张量,形状同样为[D, fH, fW]。
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW) # ds.shape [41, 8, 22]
D, _, _ = ds.shape # 表示深度 D = 41
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW) # xs.shape [41, 8, 22]
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW) # ys.shape [41, 8, 22]
# D x H x W x 3 shape 为 [41, 8, 22, 3]
frustum = torch.stack((xs, ys, ds), -1) # frustum.shape [41, 8, 22, 3]
return nn.Parameter(frustum, requires_grad=False)坐标系变换的部分代码(这部分代码需要一定的3D空间中坐标系旋转平移的知识和相机成像原理的知识,建议阅读前,先学习一下)
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""Determine the (x,y,z) locations (in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/downsample x W/downsample x 3
确定点云中的点在自我(ego)坐标系中的(x, y, z)位置。点云通常是从相机捕获的,并可能经过多个变换(如旋转和平移)才能转换到自我坐标系中
注意: 相机坐标系 坐标系的变化 车辆
rots: 旋转矩阵
trans: 平移矩阵
intrins: 相机内参矩阵
post_rots: 后处理旋转矩阵
post_trans: 后处理平移矩阵
"""
B, N, _ = trans.shape
# undo post-transformation 后处理变换的逆操作
# B x N x D x H x W x 3
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))
# cam_to_ego
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3] , points[:, :, :, :, :, 2:3]), 5)
combine = rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3)
return points # points 的 shape [4,5,41,8,22,3]2.2 Splat:3D → BEV 转换模块
2.2.1 原理:
由图2所知,我们构建的图像特征和空间位置特征是一一对应的,从它们的shape就可以看出,图像特征的shape为(bs,num,d,h,w,c),空间位置的shape为(bs,num,d,h,w,3)。
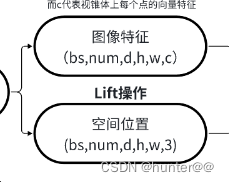
因此,Splat操作的目的就是将我们提取的出的空间3D信息转换为BEV特征 。具体做法如下:
首先就是将数据拍扁,合并 B x N x D x H x W的维度,只保留C维度,为什么这么做呢,本人觉得可能是为了后面的累积求和操作进行维度变换。
然后,因为拍扁之后容易丢失batch信息,所以代码中构建了一个batch_idx索引concat在空间位置geom_feats特征[B x N x D x H x W, 3]上,使得空间位置特征变维度变为了[B x N x D x H x W, 4],之后又进行了一个位置限制,对geom_feat的最后一个维度的前3个值(分别表示x,y,z)进行过滤,过滤到掉在边界线之后的点:x:0~199,y:0~199,z:0。
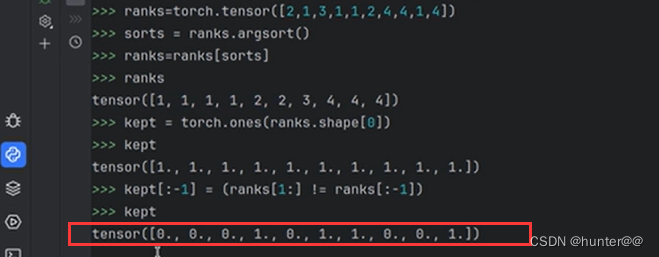
最后,再对其进行排序,也就是rank操作,个人理解它可能是为了splat拍扁的时候的顺序问题,并且这个排序是基于深度、位置与其他遮挡关系的加权和。再进行cumsum_trick操作,也就是累积求和操作,这里借用一张b站up主的ppt来解释一下这个问题。
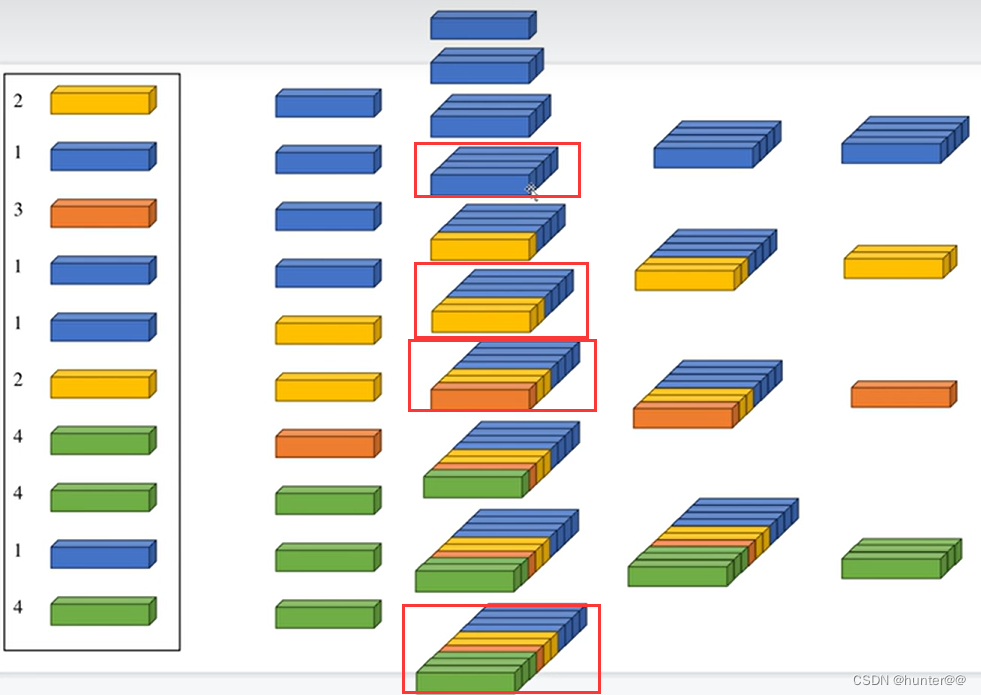
图 7 就很好的解释了ranking和cumsum_trick操作的作用 :首先ranking对不同的特征向量进行排序,排序完的结果如图的左边第二列。x = x.cumsum(0)的作用主要是进行累加,具体来说,就是第2个结果等于第1个结果和第2个结果相加,第3个结果等于第1、2、3个结果相加,依次类推,如图7的左边第三列所示。kept[:-1] = (ranks[1:] != ranks[:-1])的作用是错位对齐:如果ranks中的第i+1个元素与第i个元素不同,则kept的第i个元素被设置为True;否则为False。它这么做的目的就是找出错位之后不一样的特征,也就是前后发生变化的特征,得出的结果为左边第四列。之后的x = torch.cat((x[:1], x[1:] - x[:-1])),则就是输出右边第一列的一个结果。
综合来看cumsum_trick的目的就是将同一栅格中相同ranking的向量聚合到一起,方便后续的拍扁操作,如图9所示。
2.2.2 代码:
这部分其实大多数同学第一次看都比较蒙,但是这确实是论文中最精彩的操作。
def voxel_pooling(self, geom_feats, x):
"""
利用ego坐标系下的坐标点与图像特征点云,利用Voxel Pooling构建BEV特征
3D点云数据(或类似的三维数据)的体素池化(voxel pooling)操作
geom_feats: 点云数据的几何特征(如三维坐标)
x: 与点云数据对应的特征张量
"""
B, N, D, H, W, C = x.shape
Nprime = B * N * D * H * W # 144320
# flatten x 数据扁平化
x = x.reshape(Nprime, C) # [144320, 64]
# flatten indices 添加批次索引
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long() #平移缩放操作,防止出现BEV特征为负数
geom_feats = geom_feats.view(Nprime, 3) # [144320, 3] 表示一堆坐标的集合 {x, y, z}
batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,device=x.device, dtype=torch.long) for ix in range(B)]) # 生成 batch 的索引 [144320, 1]
geom_feats = torch.cat((geom_feats, batch_ix), 1) # 此时的 geom_feats 的shape [144320,4] ,其中 4 表示的是 {x,y,z,batch_ix}
# filter out points that are outside box
# 过滤掉在边界线之外的点 x:0~199 y: 0~199 z: 0
# geom_feats[:, 0] 表示的 x 坐标
# geom_feats[:, 1] 表示的 y 坐标
# geom_feats[:, 2] 表示的 z 坐标
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2]) # 144320
x = x[kept] # [137781, 64]
geom_feats = geom_feats[kept] # [137781, 4 ]
# get tensors from the same voxel next to each other 排序和索引
# 投影的 2D 高斯被按照其深度值进行排序,以便在后续的渲染过程中正确地处理遮挡关系。nx表示深度信息
# 排名可能是基于深度、位置或其他与遮挡关系相关的几何属性
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\
+ geom_feats[:, 1] * (self.nx[2] * B)\
+ geom_feats[:, 2] * B\
+ geom_feats[:, 3] # 137781
sorts = ranks.argsort() # 137781
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts] # x:[137781,64],geom_feats:[137781,4],ranks:[137781]
# cumsum trick 累积求和操作,对同一个栅格网络中的特征向量进行求和
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks) # x:[ 42291,64 ],geom_feats:[42291,4]
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)
# griddify (B x C x Z x X x Y) 网格化 : splat操作
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device) # 4 x 64 x 1 x 200 x 200
# final的一些理解:
# geom_feats[:, 3]:表示batch_size
# ::表示所有的特征C
# geom_feats[:, 2]: 表示坐标 Z
# geom_feats[:, 0]: 表示坐标 X
# geom_feats[:, 1]: 表示坐标 Y
# 这里其实是一个numpy数据的查询机制,从geom_feats:[42291,4]中(x,y,z,bs)去查询x:[ 42291,64 ]中的64个特征向量,当然一共有42291个查询对
# 注意:4 x 64 x 1 x 200 x 200 一定会比 42291 x 64 大,不然就超出BEV栅格了
final[ geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1] ] = x # 将x按照栅格坐标放到final中
# collapse Z 合并 Z 轴
final = torch.cat(final.unbind(dim=2), 1) # (64,200,200)
return finalcumsum_trick函数,比较重要,也是splat操作中的一个难点。
def cumsum_trick(x, geom_feats, ranks): # x:[137626,64],geom_feats:[137626,4],ranks:[137626]
x = x.cumsum(0) # x:[ 137626,64 ]
kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool) # kept [137626]
kept[:-1] = (ranks[1:] != ranks[:-1]) # 错位对齐:如果ranks中的第i+1个元素与第i个元素不同,则kept的第i个元素被设置为True;否则为False
x, geom_feats = x[kept], geom_feats[kept] # x : [42291,64] geom_feats : [42291,4]
x = torch.cat((x[:1], x[1:] - x[:-1])) # x:[42291,64]
return x, geom_feats2.3 Shoot:BEV特征图上进行检测、分割等
2.3.1 原理:
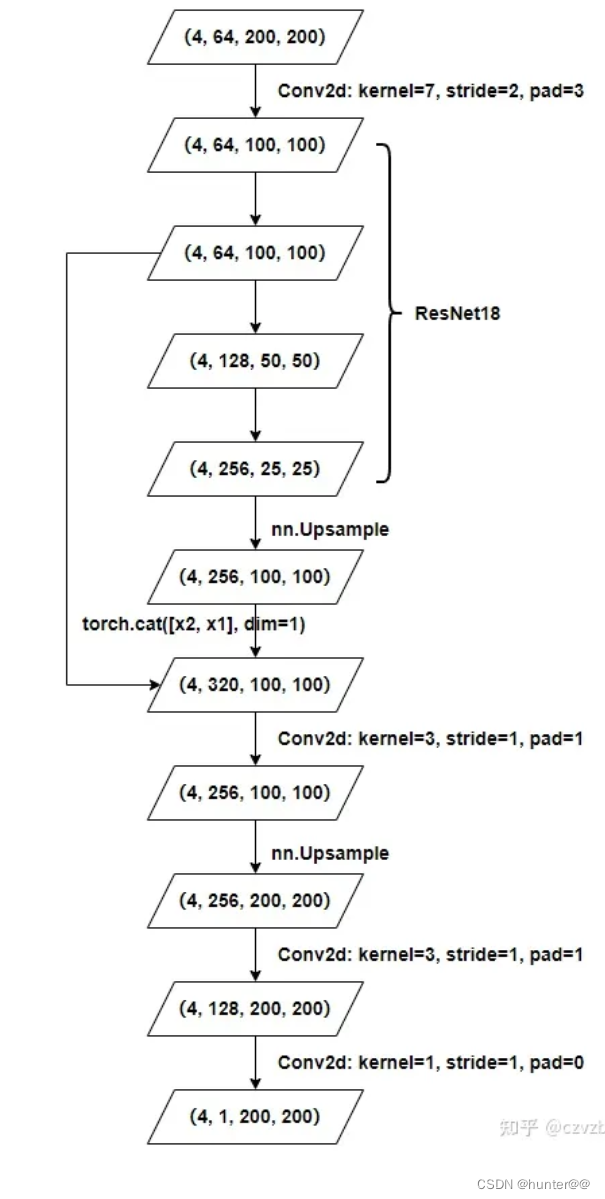
这一部分原理也极其类似2d图像卷积的任务,就是将二维卷积用在了BEV特征图上。这里我就直接引用了别人画的一张BEV特征提取的流程图。
2.3.2 代码:
class BevEncode(nn.Module):
def __init__(self, inC, outC):
super(BevEncode, self).__init__()
trunk = resnet18(pretrained=False, zero_init_residual=True)
self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = trunk.bn1
self.relu = trunk.relu
self.layer1 = trunk.layer1
self.layer2 = trunk.layer2
self.layer3 = trunk.layer3
self.up1 = Up(64+256, 256, scale_factor=4)
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear',
align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, outC, kernel_size=1, padding=0),
)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x1 = self.layer1(x)
x = self.layer2(x1)
x = self.layer3(x)
x = self.up1(x, x1)
x = self.up2(x)
return x2.3.3 部分细节理解:
2.3.3.1
label信息
3 结论
LSS确实是BEV感知的开山之作,其主要贡献有以下几点:
- 提出了一种将图像从2d转换到3d的方法(Lift);
- 提出了一种end-to-end模型,可以将来自多个相机的图像特征转换到统一的BEV空间;
- LSS是纯视觉模型,为后续的纯视觉BEV感知算法研究奠定了基础。
4 参考
https://zhuanlan.zhihu.com/p/589146284
https://zhuanlan.zhihu.com/p/542943128
https://blog.csdn.net/baobei0112/article/details/133648917
https://www.bilibili.com/video/BV1iK411x7QZ/
http://手撕BEV的开山之作:lift, splat, shoot(没完全shoot)_哔哩哔哩_bilibili


















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









