







主要讲解了贝叶斯概率与统计派概率的不同。概率论,决策论,信息论(probability theory, decision theory, and information theory)是以后用到的三个重要工具,本节主要介绍概率论,这里的介绍还是结合前面的多项式拟合的例子讲解。
1 引言
模式识别中一个重要的概念就是不确定性,而概率论可以很好的解释不确定性,在结合后面讲学到的决策论时,会利用概率论的方法,充分利用现有的信息得到一个最优解。
这部分需要提前了解以下三个概念和三个理论:


下面开始进入例子:
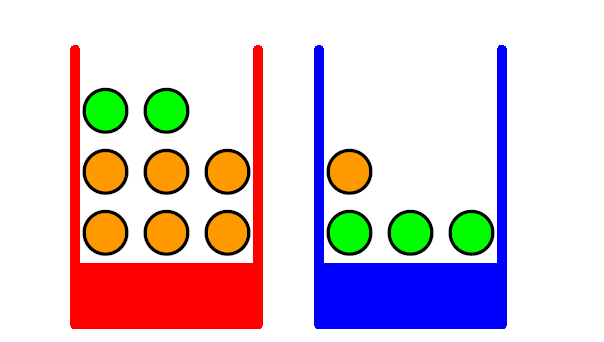
有两个盒子(box记为B),红色记为r蓝色记为b,也就是B(r),B(b)
里面有苹果与橘子,黄色代表橘子o,绿色代表苹果a。
假设: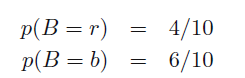
(也可认为有红盒子4个,蓝盒子6个)
那么我们可以知道一下四个条件概率:
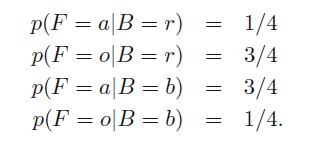
问题1:抓到红色苹果的概率是多少?
想必这问题还是挺简单的
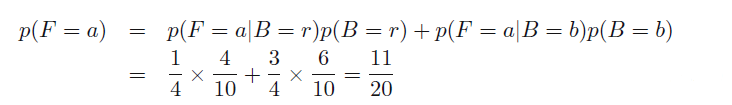
问题2:如果抓到的是橘子,那么是从红色箱子拿出来的概率是多少?
这里要用到贝叶斯概率了
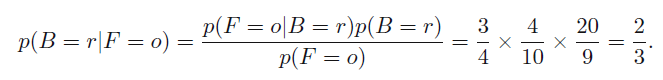
这里p(B)是先验概率,p(B|F)是后验概率
另外还需要知道的一个概念就是独立变量,如果两个变量独立,那么P(x,y)=p(x)p(y).或者p(x|y)=p(x),这个例子中如果两个盒子的橘子和苹果的比例相同,那么选取盒子和选取水果这个两个变量就是相互独立的。
明白上面的知识,就可以继续向下看了。
2 概率密度
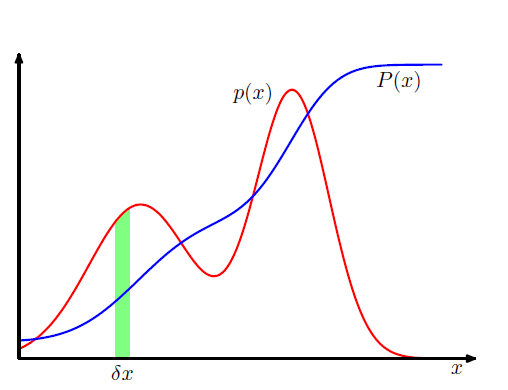
对于连续变量,如果x在
(x,x+δ)
中的概率为
p(x)δx
那么这里的p(x)就是概率密度,这里定义累积分布函数
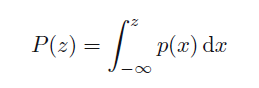
可以看到概率密度是累积分布函数的微分
这里还需要知道自变量函数的概率密度的,假设x=g(y),因为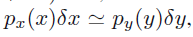
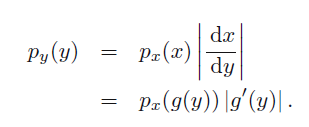
当x为多个变量时,此时的密度函数为联合概率密度。
引言中提到的三个理论同样适用于概率密度函数,其sum rule 和product rule 如下:
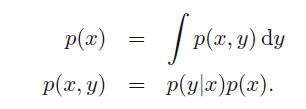
3 期望和协方差 Expectations and covariances
3.1加权平均值
在离散变量中的加权平均值计算公式如下:
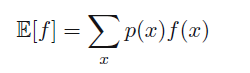
相应的连续变量的为:
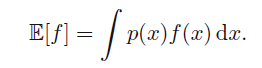
其中
f(x)
为权重函数。
如果已知N个点的值,我们可以按照下式估计其加权平均值,如果N趋于无穷,那么他的值应该与上面的式子结果相同。
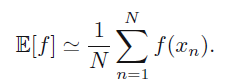
3.2 多变量权重
另外,还有一种可能是,我们的权重函数是多变量的,这时候我们可以通过添加下标来表明是求那个变量的加权平均值,下式是求x的加权平均值:
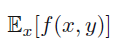
值得注意的是其结果不是一个常数,而是一个关于y的函数。
3.3 条件期望
还有一种条件期望,下式为离散变量的形式
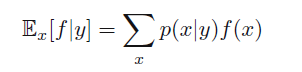
3.4 函数方差
变量函数的方差为:
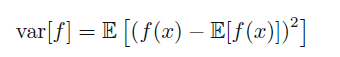
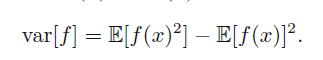
3.5 协方差
变量的协方差为:
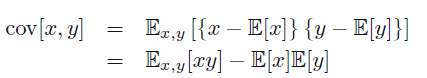
协方差矩阵为:
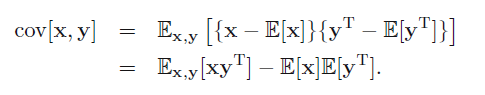
4 Bayesian Probability
目前为止我们都是以随机可重复事件的频率出发,来看待概率的,这样的视角叫作经典概率或者频率派概率。现在我们将用贝叶斯的视角重新审视人生,这种Bayesian 概率,它的不同在于引入了不确定的因素。
我们用概率来表达不确定性,在上节多项式拟合中,使用频率派的观点已经很合理的解决了这个问题,但是我们还可以通过贝叶斯的观点来定性和定量的分析各个参数的不确定性。
之前我们在研究拿水果的问题时,我们通过贝叶斯公式用先验概率求得了后验概率,在后面我们也会用类似的方法来求多项式拟合中参数的不确定性,其公式如下:
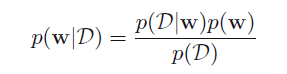
(从这里开始就不太好理解了,建议结合原书和后面给的链接多读几遍)
p(w|D)的意思就是在现有观察的数据D的前提下w的不确定性。
p(D|w)是在w的条件下出现D的可能性,也叫作似然函数。
在频率派中p(D|w)是将w看做确定数值,误差是由D的分布决定的;而贝叶斯派则是将w看作是不确定的,误差是由w的分布决定的。
http://www.aiweibang.com/yuedu/52652665.html有个好点的解释

里面也解释了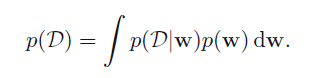
5高斯分布
高斯分布也叫正态分布,其一元表达式如下:
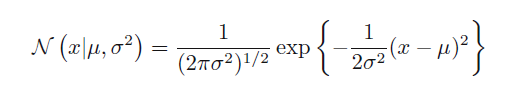
一阶矩:
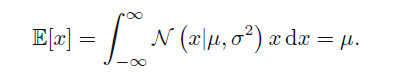
二阶矩:
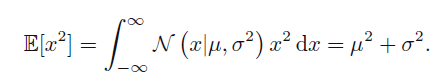
方差:
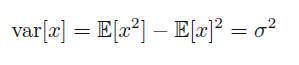
多元表达式:
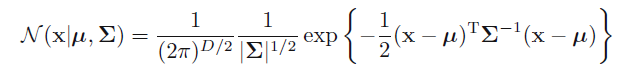
μ
是n维均值,
Σ
是协方差矩阵,
|Σ|
是它的行列式。
设x独立同分布,其似然函数为:
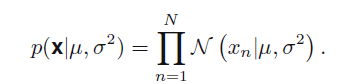
这里文中之处,在求p(x|参数)的最大似然估计和p(参数|x)是有联系的。
现在利用上式求最大似然估计的
μ、σ2
的值。对其求对数,然后加负号,求极小值得到以下结果:
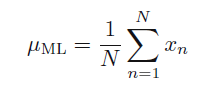
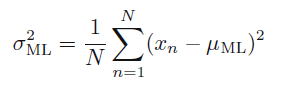
高斯分布中
μ、σ2
相互独立,可以计算出
μ
的值之后代入
sigma
的计算公式中。
对其计算结果求均值得到:
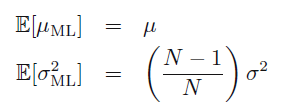
可以看出方差并不是无偏估计,下图是只有两个点的时候的计算的方差和均值:
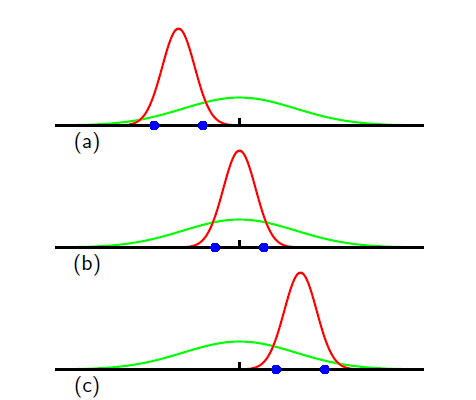
绿色是真实情况,蓝色是样本点。可以看出样本数量较少的情况得到的结果不太好,但是如果样本数量很大,其偏差就可以忽略不计了。但是参数越多的时候其偏差就会越明显。
6 重回多项式拟合
这次从概率的角度重新审视误差函数和规则化的含义,另外感受下beyas方案。
之前我们想要通过现有的x和t,来预测新的x对应的t,之前并没有给出预测的不确定程度,现在通过beyas方法来计算。
假设我们的预测函数是以y为均值的高斯分布函数,如下图所示:
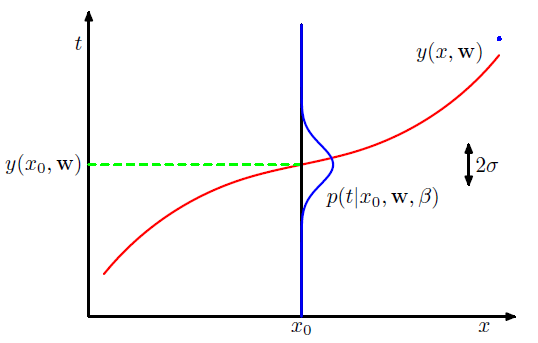
其中的
β=1/σ2
.也就是新的预测值的概率密度为:
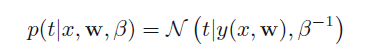
这样就表征出了预测值的不确定性。
其似然函数为:
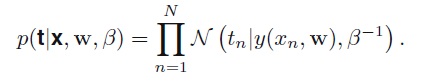
利用最大似然函数就可以求出w和
β
注意这里依然由于他们二者不会由于比赛改变自己的极值所以可以分别求出。
6.1理解误差函数
在求的过程中可以发现,最小二乘法就是其求解的一种特殊情况。
在如果求出两者,那么我们就有一个预测模型了,这样代入即可求出预测值的分布(之前的拟合只能到处一个数值)。
6.2 理解规则化
我们进一步利用beyas概论,还记得下面的图片么?
这里可以写成下式:

如果我们考虑w的先验分布,那么其后验分布应该满足上式,这时候的w应该使后验概率最大化,This technique is called maximum posterior, or simply MAP.其求解结果是:
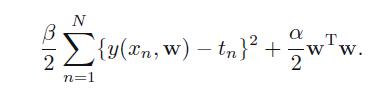
总是那么神奇,可以看出这样的形式类似于有惩罚项的最小二乘法的代价函数。
其中w的先验概率的条件变量
α/β
可以看成惩罚因子。
从这里可以看出概率派和频率派只是一个问题的不同解决方式,并没有绝对的谁对谁错。
7 贝叶斯曲线拟合
上面虽然得到了预测值的不确定性,但是并不是完整的贝叶斯的方法,因为我们的参数的不确定性还没有给出。
拟合问题中我们是要求在知道已知向量x,t及新的向量数值x时预测一个新的t,他可以用下式表示:
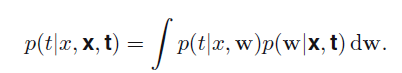
其中左边是我们刚才说想要求的,右边整体是用了sum rule 在连续变量中就是求边缘密度,中间里面的乘法用的是product rule。
其中的
p(t|x,w)
为在参数为W的条件下,对应x的预测值为t的概率,也就是前面的方程: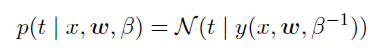
p(w|x,t)
为在输入为x,t条件下参数为w的概率。他们的乘积就是参数为w输入为x,t时的概率。
要注意,这里我们并不是把参数设为固定值,因此如果想得到最终的
p(t|x,x,t)
必须要利用sum rule 将其求积分,求解方法暂时没有详细列出,结果如下:
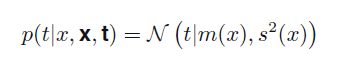
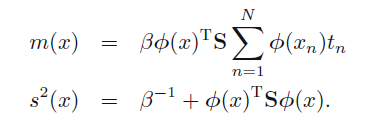
其中
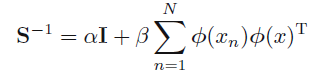
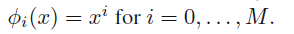
注意这里的
s2
包含两项,第一项是前面已经用似然函数得到的由于目标函数的噪声产生的
β−1
,而第二项是由w的不确定产生的。
其拟合结果如下:
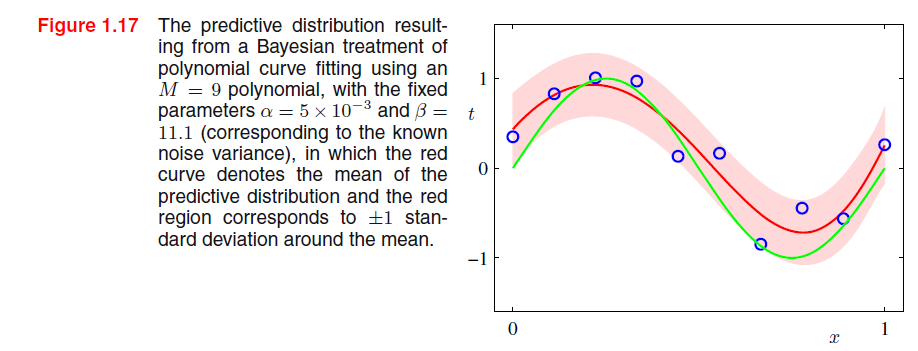
这里只是讲解了beyas方法求解拟合问题的一般过程,其具体求解步骤还没有详细叙述,后面应该会有讲解。















 9008
9008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









