







 本文介绍了自恺明提出MAE以来,该方法在计算机视觉领域的最新进展,包括图像MAE的优化如MixMIM、Uniform Masking以及在视频和多模态数据上的应用。MixMIM解决了预训练与微调的一致性和计算效率问题,Uniform Masking适应了金字塔结构的Transformer,而VideoMAE和M3AE分别拓展了MAE在视频和多模态学习中的应用。
本文介绍了自恺明提出MAE以来,该方法在计算机视觉领域的最新进展,包括图像MAE的优化如MixMIM、Uniform Masking以及在视频和多模态数据上的应用。MixMIM解决了预训练与微调的一致性和计算效率问题,Uniform Masking适应了金字塔结构的Transformer,而VideoMAE和M3AE分别拓展了MAE在视频和多模态学习中的应用。

©PaperWeekly 原创 · 作者 | Jason
研究方向 | 计算机视觉

写在前面
自去年 11 月份恺明大神提出 MAE 来,大家都被 MAE 简单的实现、极高的效率和惊艳的性能所吸引。近几个月,大家也纷纷 follow 恺明的工作,在 MAE 进行改进(如将 MAE 用到层次 Transformer 结构)或将 MAE 应用于图片之外的数据(如视频、多模态)。在本文中,我们将介绍关于 MAE 的一些先验知识,以及最近基于 MAE 所做的最新工作!

先验知识
2.1 自监督学习
在深度学习模型中,数据通常会通过 Backbone 来提取特征,常见的 Backbone 包括 ResNet、ResNeXt 和 Transformer 等。Backbone 之所有能够提取出对任务有用的特征,是因为它通常已经在带标签的大数据集(如 ImageNet)中已经进行训练。然而,人工进行标注数据是昂贵和费时的,如何在没有标注数据的情况下获得一个 strong 的 Backbone 是一个非常重要的问题。
自监督学习(Self-supervised learning)可以解决这个问题,它的目标是基于无标注的数据,设计辅助任务来将数据本身的某一部分的信息作为监督信号,从而基于这个监督信号来训练模型。基于这些无标签的数据,可以学习到一个模型,这个过程可以称为预训练(pre-train)。
由于这个预训练之后的模型已经具备一定的知识,因此在进行具体的下游任务时,可以将它作为 Backbone 的初始化,进行下游任务的训练,这个过程成为微调(fine-tuning)。由于模型在预训练阶段已经学习到了一定的知识,因此就可以大大减少微调阶段所需的数据集和训练时间。由于预训练阶段的数据是无需标注的,因此也就大大减少的标注数据的成本。
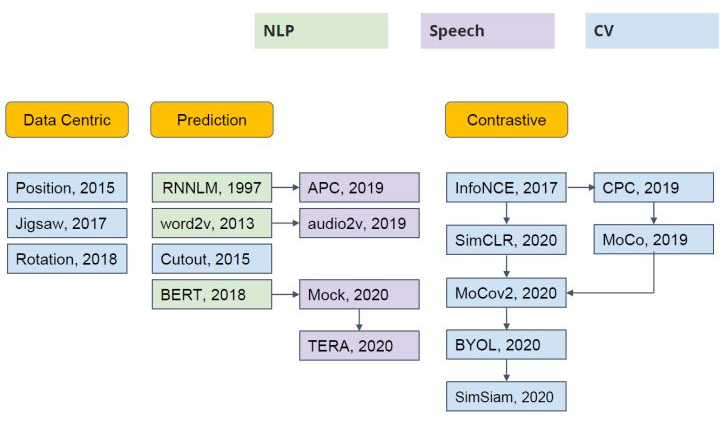
根据自监督训练阶段的辅助任务不同,可以大致将目前的自监督学习工作分为三类:Data Centric, Prediction 和 Contrastive(如下所示)。由于本文介绍的 MAE 的辅助任务为预测 Mask 部分的图像内容,因此属于 Prediction 这一类别。
2.2. MAE(Masked Autoencoders)

论文标题:
Masked Autoencoders Are Scalable Vision Learners
论文地址:
https://arxiv.org/abs/2111.06377
代码地址:
https://github.com/facebookresearch/mae
论文动机:

随着 BERT 的出现,Mask Language Modeling(MLM)的自监督学习方法逐渐进入人们的视野,这一方法在 NLP 领域中得到了广泛的应用。受到 MLM 的启发,一些工作也尝试在图像上进行 Mask Modeling(即,mask 图片的部分区域,然后对区域的内容进行重建),并且也取得了不错的效果。但目前的方法通常都采用对称的 encoder 和 decoder 结构,在 encoder 中,mask token 也需要消耗大量的计算,因此作者提出了一个非对称 encoder-decoder 的结构——masked autoencoders(MAE)。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2779
2779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









