







©作者 | 王治海
单位 | 中国科学技术大学
研究方向 | 强化学习
近日,中科大王杰教授团队(MIRA Lab)和华为诺亚方舟实验室(Huawei Noah’s Ark Lab)联合提出了分层序列/集合模型,并开发了基于该分层模型的智能决策训练方法。显著提升混合整数线性规划(MILP)求解器求解效率,取得最高 3 倍无损提速。

论文题目:
Learning to Cut via Hierarchical Sequence/Set Model for Efficient Mixed-Integer Programming
论文链接:
https://ieeexplore.ieee.org/document/10607926
代码链接:
https://github.com/MIRALab-USTC/L2O-HEM-Torch
数据链接:
https://drive.google.com/drive/folders/1LXLZ8vq3L7v00XH-Tx3U6hiTJ79sCzxY
华为MindSpore ModelZoo模型库:
https://gitee.com/mindspore/models/tree/master/research/l2o/hem-learning-to-cut
数学规划求解器因其重要性和通用性,被誉为运筹优化领域的“光刻机”。其中,MILP 求解器是数学规划求解器的关键组件,可建模大量实际应用。打个比方,MILP 求解器就像一个智能助手,能通过数学方法和算法帮助寻找最优解。在更复杂的情况下,比如物流调度、生产计划、金融投资等领域,MILP 求解器可以帮助决策者在复杂约束条件下做出最优选择。
目前论文发表在人工智能顶级期刊 IEEE TPAMI 2024。

背景与问题介绍
割平面(cutting planes, cuts)在加速求解混合整数线性规划(MILP)问题中发挥着至关重要的作用。自上世纪 50 年代以来,割平面法作为求解 MILP 问题的强大工具,已成为学术界和工业界广泛研究的重点。经过多年的实践验证,割平面法已被公认为快速求解 MILP 问题的关键技术。
其中割平面选择(cut selection)目标是:选择待选割平面的恰当子集以无损提高求解MILP的效率。
据介绍,割平面选择在很大程度上取决于两个子问题:
(P1) 应优先选哪些割平面
(P2) 应选择多少割平面
研究人员认为,尽管许多现代MILP求解器通过手动设计的启发式方法来处理 (P1) 和 (P2),但机器学习方法有潜力学习更有效的启发式方法。
然而,许多现有的学习类方法侧重于学习应该优先选择哪些割平面,而忽略了学习应该选择多少割平面。
此外,研究人员从大量的实验结果中发现又一子问题对求解MILP的效率有重大影响。
(P3) 应该优先选择哪种割平面顺序
针对上述挑战,研究人员提出了一种新的分层序列/集合模型(Hierarchical Sequence/Set Model,HEM++),并构建了基于该模型的强化学习框架来学习割平面选择策略。
下面具体展开。
割平面介绍
混合整数线性规划(MILP)是一种可广泛应用于多种实际应用领域的通用优化模型,例如供应链管理、排产规划、规划调度、工厂选址、装箱问题等。
标准的 MILP 具有以下形式:
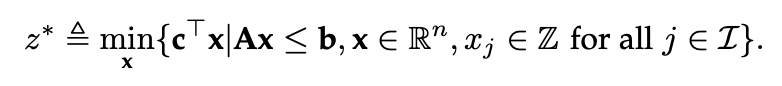
给定上述问题,丢弃其所有整数约束,可得到线性规划松弛(linear programming relaxation,LPR)问题,它的形式为:
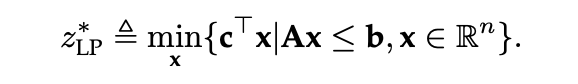
由于松弛问题扩展了原始问题的可行域,因此可有 ,即 LPR 问题的最优值是原 MILP 问题的下界。
给定松弛问题,割平面是一类合法线性不等式,这些不等式在添加到线性规划松弛问题中后,可收缩 LPR 问题中的可行域空间,且不去除任何原MILP问题中任何整数可行解。
割平面选择介绍
MILP 求解器在求解 MILP 问题过程中可生成大量的割平面,且生成的割平面会在连续的回合中不断向原问题中添加割平面。
具体而言,每一回合中包括五个步骤:
(1) 求解当前的 LPR 问题;
(2) 生成一系列待选割平面;
(3) 从待选割平面中选择一个合适的子集;
(4) 将选择的子集添加到 (1) 中的 LPR 问题,以得到一个新的 LPR 问题;
(5) 循环重复,基于新的 LPR 问题,进入下一个回合。
将所有生成的割平面添加到 LPR 问题中可最大程度地收缩该问题的可行域空间,以最大程度提高下界。然而,添加过多的割平面可能会导致问题约束过多,增加问题求解计算开销并出现数值不稳定问题。因此,研究者们提出了割平面选择,它的目标是选择候选割平面的适当子集,以尽可能提升 MILP 问题求解效率。

启发实验:割平面添加顺序
研究人员设计了两种割平面选择启发式算法,分别为 RandomAll 和 RandomNV(详见原论文第 3 章节)。它们都在选择了一批割平面后,以随机顺序将选择的割平面添加到 MILP 问题中。
结果显示,选定同一批割平面的情况下,以不同的顺序添加这些选定割平面对求解器求解效率有极大的影响(详细结果分析见原论文第 3 章节)。
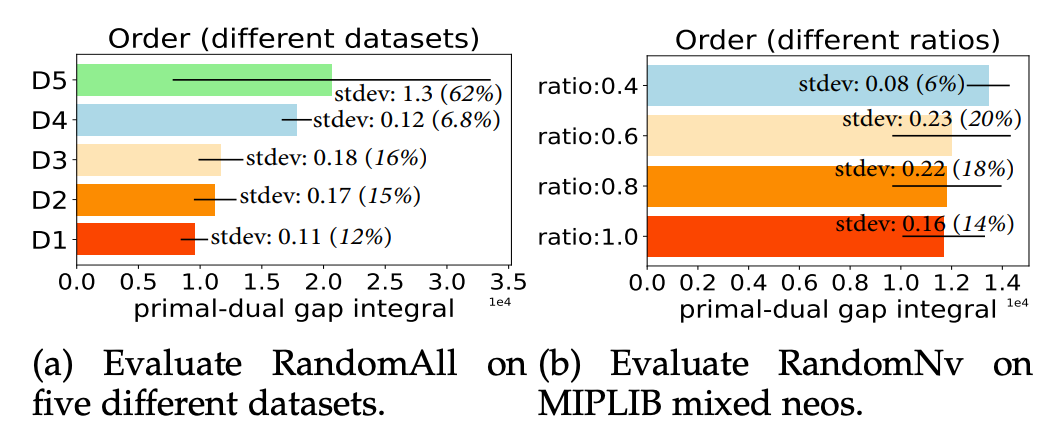
▲ 图2. 每一个柱子代表在求解器中,选定相同的一批割平面,以10轮不同的顺序添加这些选定割平面,求解器最终的求解效率的均值,柱子中的标准差线代表不同顺序下求解效率的标准差。标准差越大,代表顺序对求解器求解效率影响越大。

方法介绍
据介绍,在割平面选择任务中,应该选择的最优子集是不可事先获取的。不过,研究人员可以使用求解器评估所选任意子集的质量,并以此评估作为学习算法的反馈。因此,团队利用强化学习(Reinforcement Learning, RL)范式来试错学习割平面选择策略。
研究人员详细阐述了提出的 RL 框架(整体的 RL 框架图如图 2 所示)。首先,他们将割平面选择任务建模为马尔科夫决策过程(Markov Decision Process, MDP)。然后,详细介绍了提出的分层序列/集合模型 HEM++。最后,推导可高效训练 HEM++ 的分层近端策略优化(hierarchical proximal policy optimization, HPPO)方法。
下面一一展开。
问题建模:序列决策建模
状态空间:由于当前的 LP 松弛和生成的待选 cuts 包含割平面选择的核心信息,研究人员通过(𝑀𝐿𝑃, 𝐶,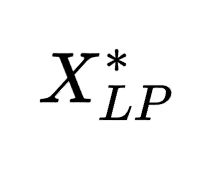 )定义状态 s。
)定义状态 s。
这里 𝑀𝐿𝑃 表示当前 LP 松弛的数学模型,𝐶 表示候选割平面的集合,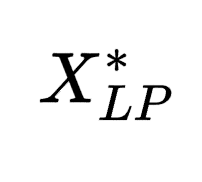 表示 LP 松弛的最优解。
表示 LP 松弛的最优解。
为了编码状态信息,研究人员根据(𝑀𝐿𝑃, 𝐶,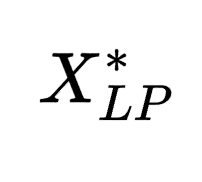 )的信息为每个待选割平面设计 13 个特征。
)的信息为每个待选割平面设计 13 个特征。
也就是说,通过一个 13 维特征向量来表示状态 s(具体细节请见原文第 5 和第 6 章节)。
动作空间:为了同时考虑所选 cut 的比例和顺序,研究人员以候选割平面集合的所有有序子集构成的集合 𝐴 和选择 cut 的比例空间 [0,1] 的直积,即动作空间 𝐴HEM++=𝐴 x [0,1]。
奖励函数:为了评估添加 cut 对求解 MILP 的影响,可通过求解时间,原始对偶间隙积分(primaldual gap integral),对偶界提升(dual bound improvement)。
转移函数:转移函数给定当前状态 s 和采取的动作 𝑎,输出下一状态 s’。割平面选择任务中转移函数隐式地由求解器提供。
更多建模细节请见原文第 5 和第 6 章节。
策略模型:分层序列/集合模型
如图所示,研究人员将 MILP 求解器建模为环境,将 HEM++ 建模为智能体,下面详细介绍所提出的 HEM++ 模型。可以看出,HEM ++ 由上下层策略模型组成。上下层模型分别学习上层策略 (policy) 和下层 (policy) 。
首先,上层策略通过预测恰当的比例来学习应该选择的 cuts 的数量。
假设状态长度为 N,预测比率为 k,那么预测应该选择的 cut 数为 ,其中 表示向下取整函数。研究人员定义 。
其次,下层策略学习选择给定大小的有序子集。下层策略可以定义 S x [0, 1] ,其中 表示给定状态 s 和比例 k 的动作空间上的概率分布。具体来说,研究人员将下层策略建模为一个序列到序列或者集合到序列模型 (sequence/set to sequence model, sequence/set model)。
最后,通过概率乘法定理可得分层 cut 选 择 策 略,即:。
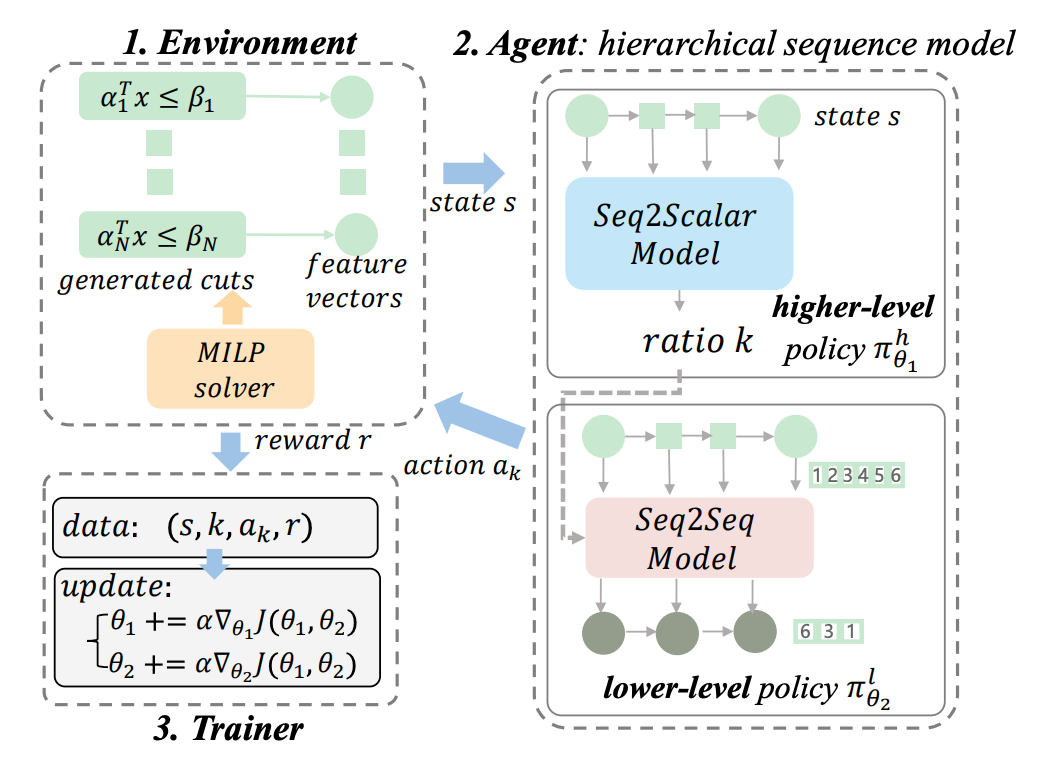
▲ 图3. 我们所提出的整体RL框架图。我们将MILP求解器建模为环境,将HEM++模型建模为智能体,我们通过智能体和环境不断交互采集训练数据,并使用分层近端策略优化训练HEM++模型。
训练方法:分层近端策略优化方法
研究人员用 表示动作空间,用 表示分层割平面策略。
最终推导出 HPPO,当前策略和旧策略的概率比表示如下:
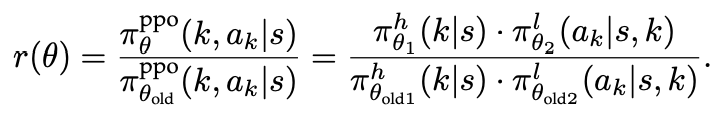
为了避免过大的策略更新,研究人员对此概率比进行裁剪得到rclip。
进一步地,给定优势函数的估计器,优化目标为:
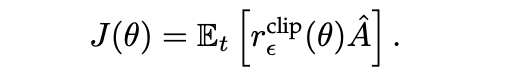
最后,分层策略梯度如下:
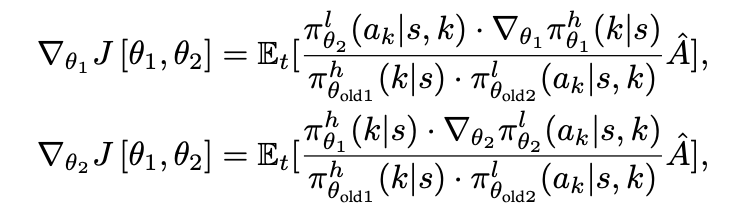
具体细节请见原文第 6 章节。

实验介绍
实验共有五个主要部分。
实验 1. 在 3 个人工生成的 MILP 问题和来自不同应用领域的 6 个具有挑战性的 MILP 问题基准上评估新方法;
实验 2. 进行消融实验,以提供对 HEM++ 的深入洞察;
实验 3. 测试 HEM++ 针对问题规模的泛化性能;
实验 4. 可视化新方法与基线所选择的割平面特点;
实验 5. 将新方法部署到华为实际的排产规划问题中,验证 HEM++ 的优越性;
下面仅简单介绍下实验 1,更多实验结果,可参见原论文第 8 章节。
研究人员提醒道,论文中汇报的所有实验结果都是基于 PyTorch 版本代码训练得到的结果。
如图所示,在多个开源数据集和工业数据集上对比了 HEM++ 和最先进开源求解器 SCIP 基线。
实验结果显示,HEM++ 可在保持求解精度不变的情况下,大幅提升求解效率。
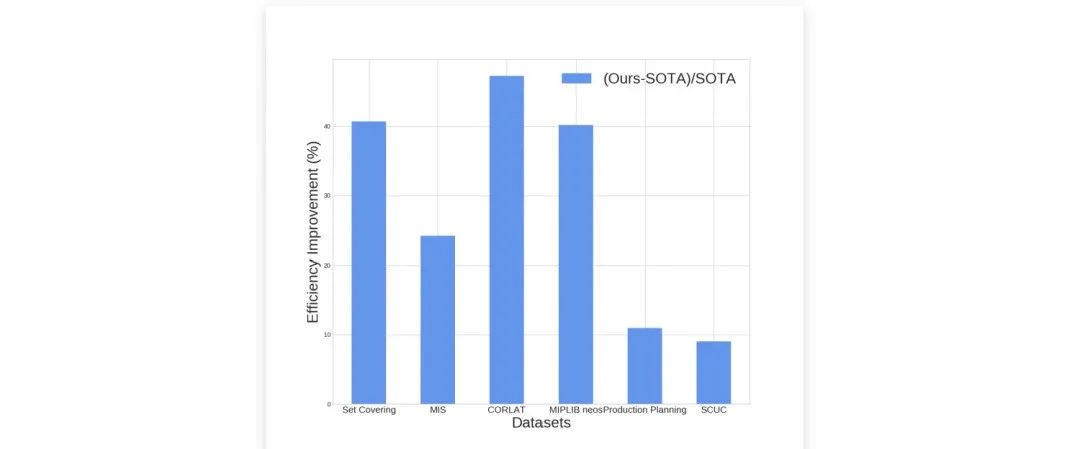
▲ 图1. HEM++与SOTA开源求解器SCIP求解效率对比,保持求解精度不变的前提下,显著提升求解效率。
据团队介绍,相关技术和能力整合入华为天筹(OptVerse)AI 求解器,助力提升天筹 AI 求解器竞争力,成为其首批关键AI特性。
天筹 AI 求解器将运筹学和 AI 相结合,针对线性和整数模型寻找最优解,以通用形式描述问题,高效计算最优方案,助力企业量化决策和精细化运营。天筹 AI 求解器曾获世界人工智能大会最高奖“卓越人工智能引领者” SAIL 奖,并在国际权威数学优化求解器榜单中的 5 项重量级榜单登上榜首。
相关算法整合入华为 MindSpore ModelZoo 模型库,助力国产开源生态。
华为 MindSpore 是一个全场景深度学习框架,目标是实现易开发、高效执行、全场景覆盖三大目标。更多细节欢迎查阅原论文。
关于作者

本论文作者王治海是中国科学技术大学 2020 级硕博连读生,师从王杰教授,主要研究方向为强化学习与学习优化理论及方法,人工智能驱动的芯片设计等。他曾以第一作者在 TPAMI、ICML、ICLR、AAAI 等顶级期刊与会议上发表论文六篇,一篇入选 ICML 亮点论文(前 3.5%),曾获华为优秀实习生(5/400+)、国家奖学金等荣誉。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









