







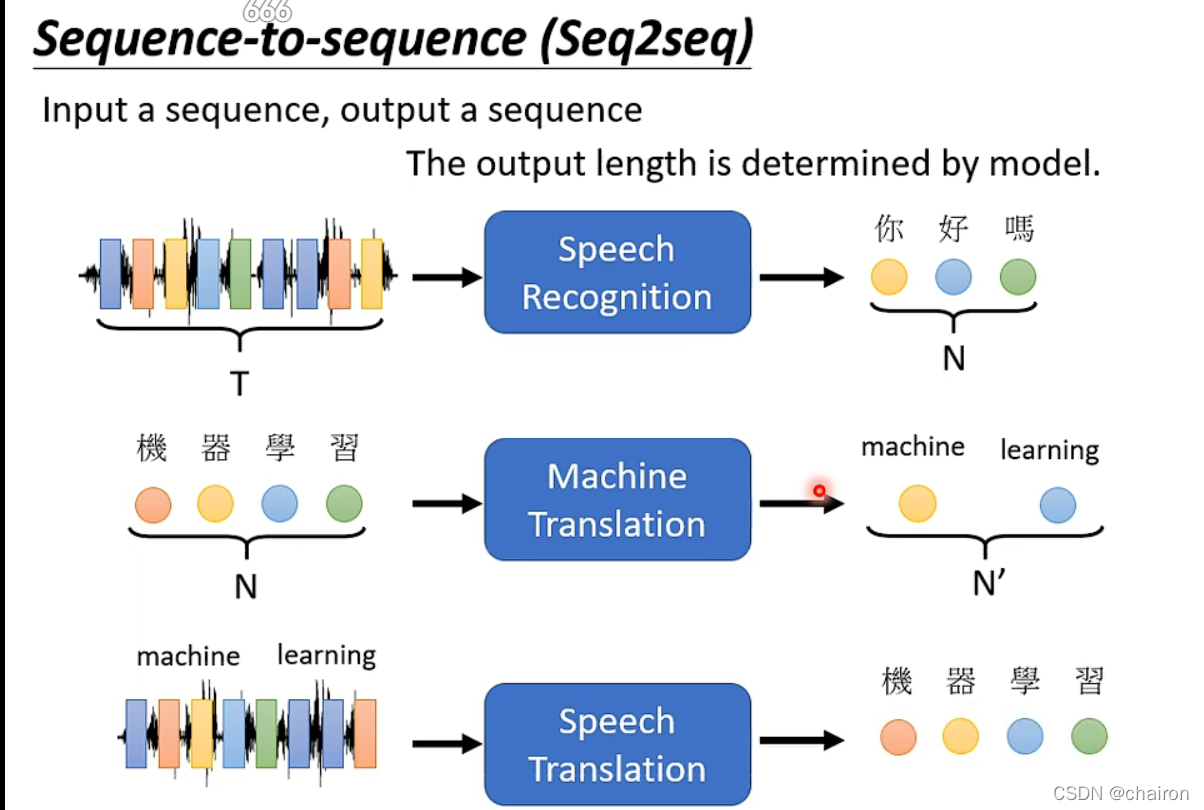
Seq2seq
输入一串序列,输出一串序列,但不知道序列长度,由机器自己决定。eg.语音识别、翻译、多标签分类、目标检测
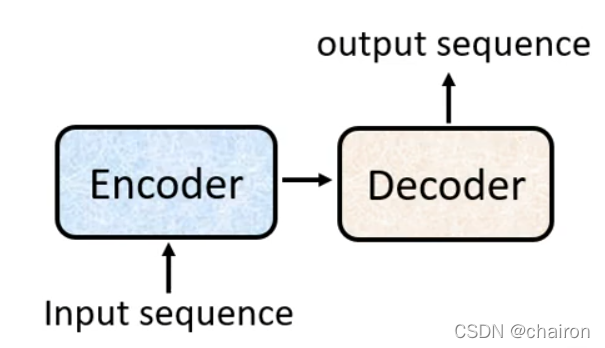
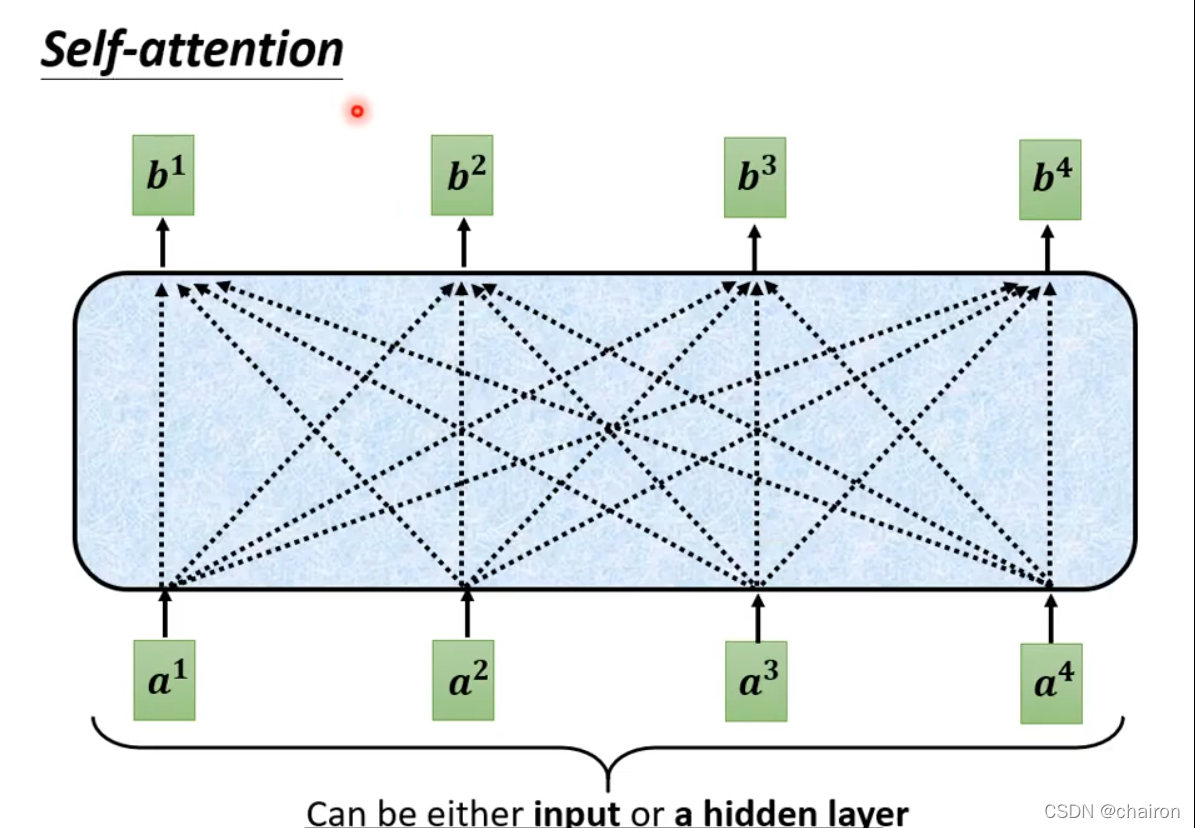
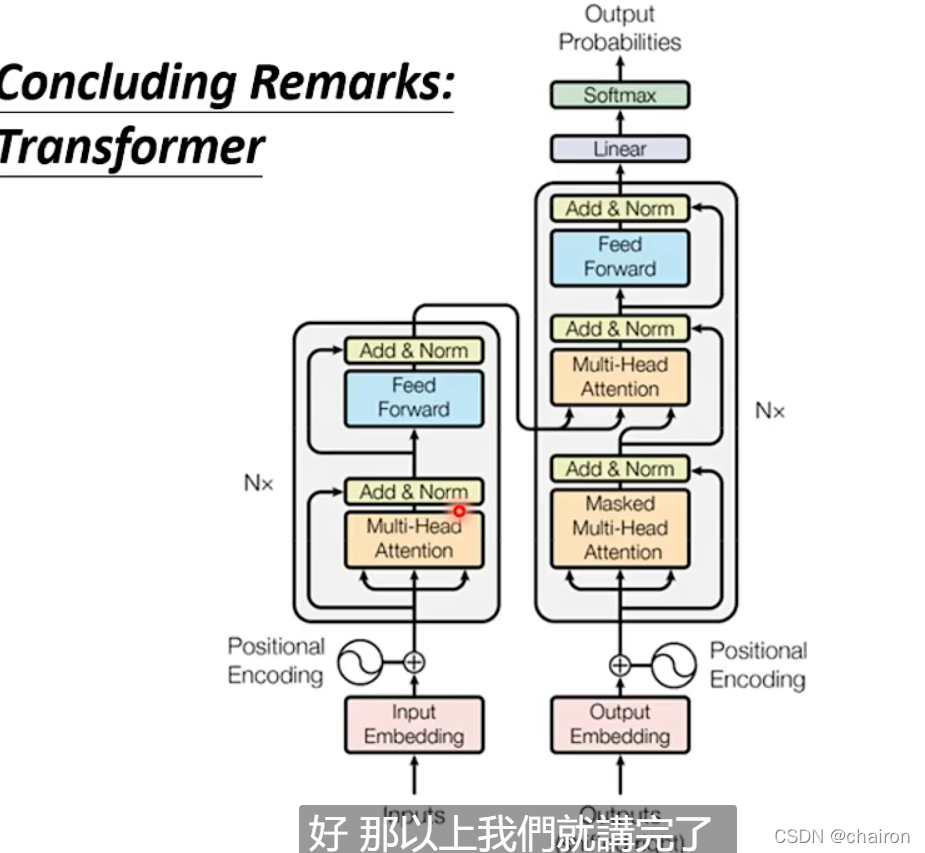
Transfomer
Encoder
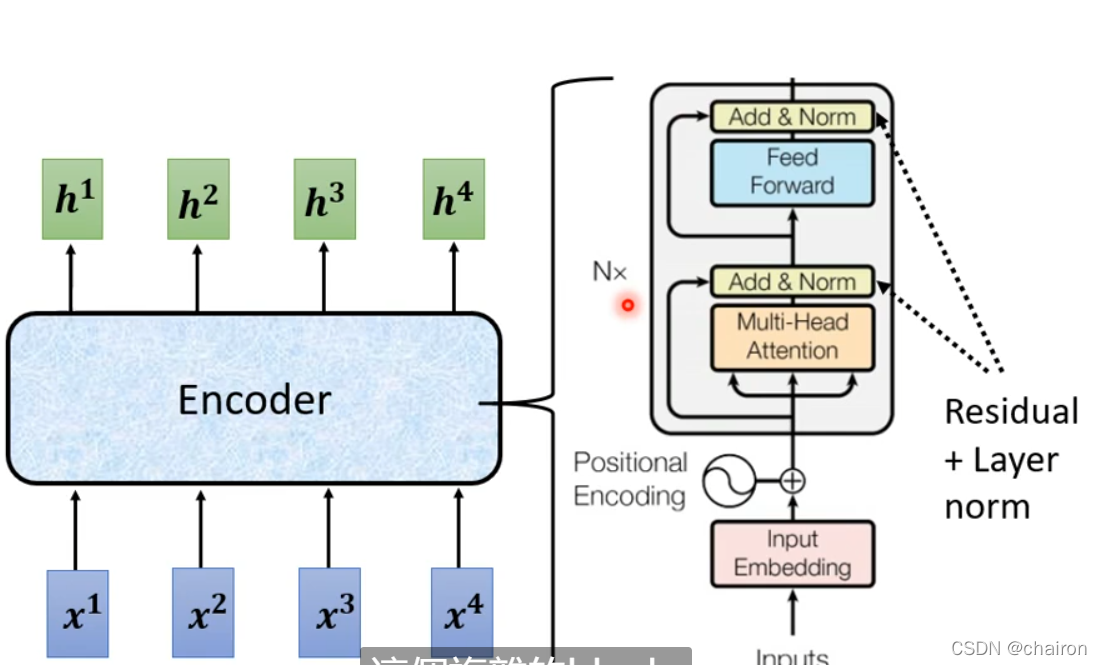
Transform用的layer Nomination
decoder
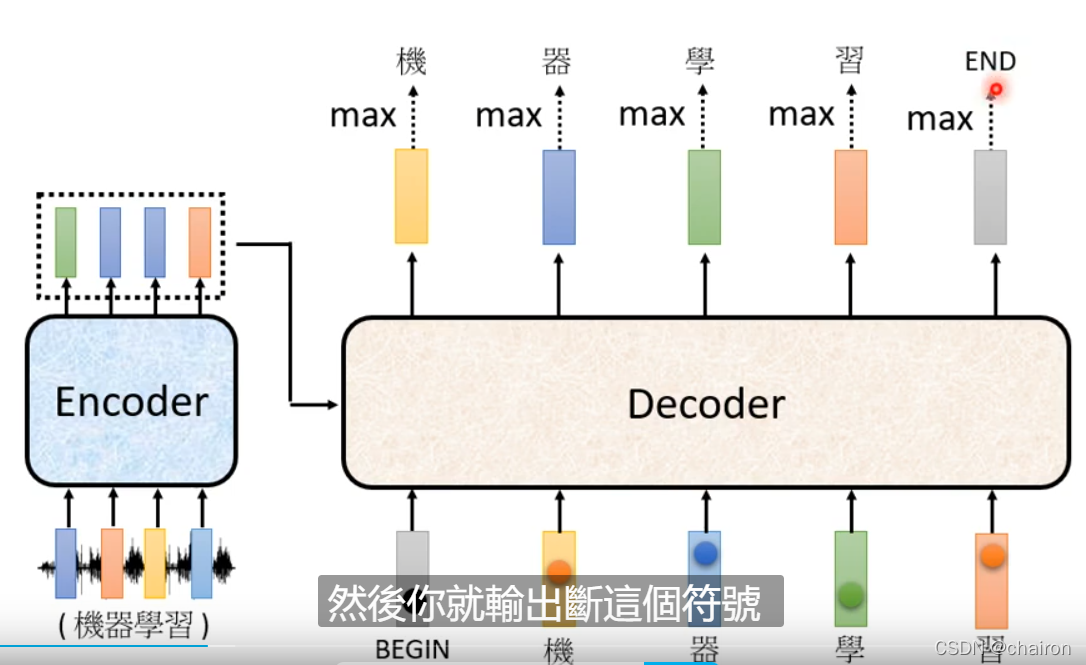
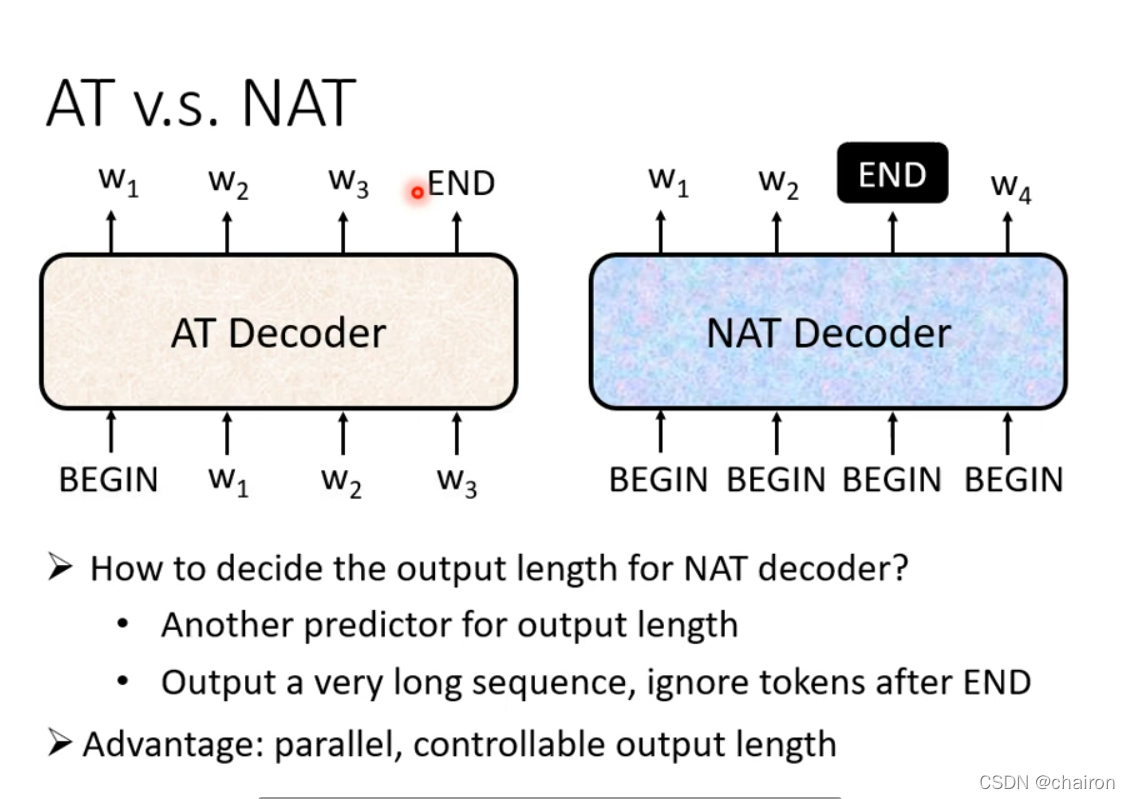
1. Autorgressive
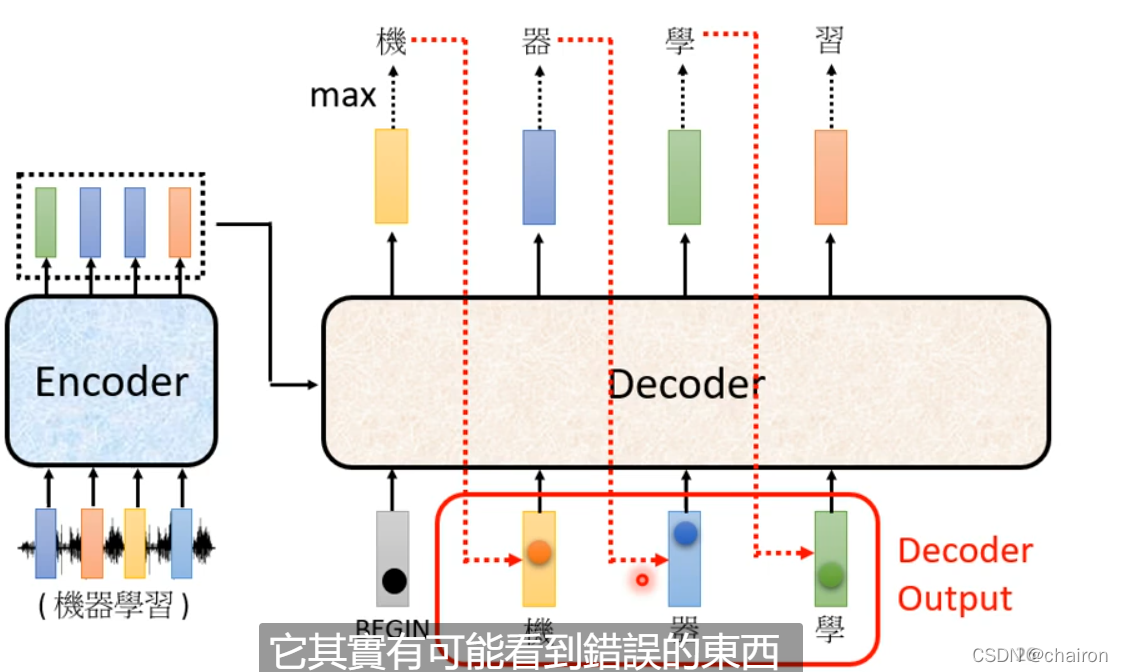
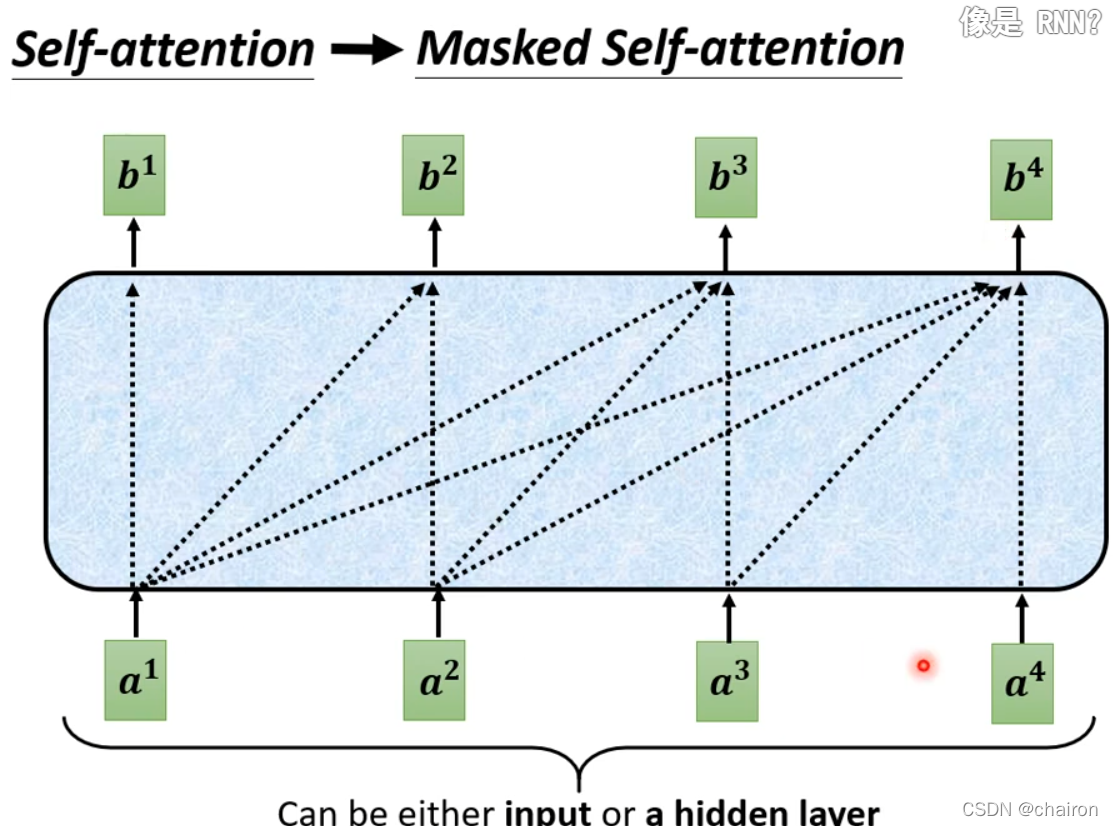
- 上一个decoder的输入是下一个的输入:如果上一个输出错误,也会影响下一步的预测;输出是一个个产生的,串行,只能考虑左边的
- 拥有begin和end标志
mask self-attention:只考虑左边的输入;self-attention考虑全部的输入
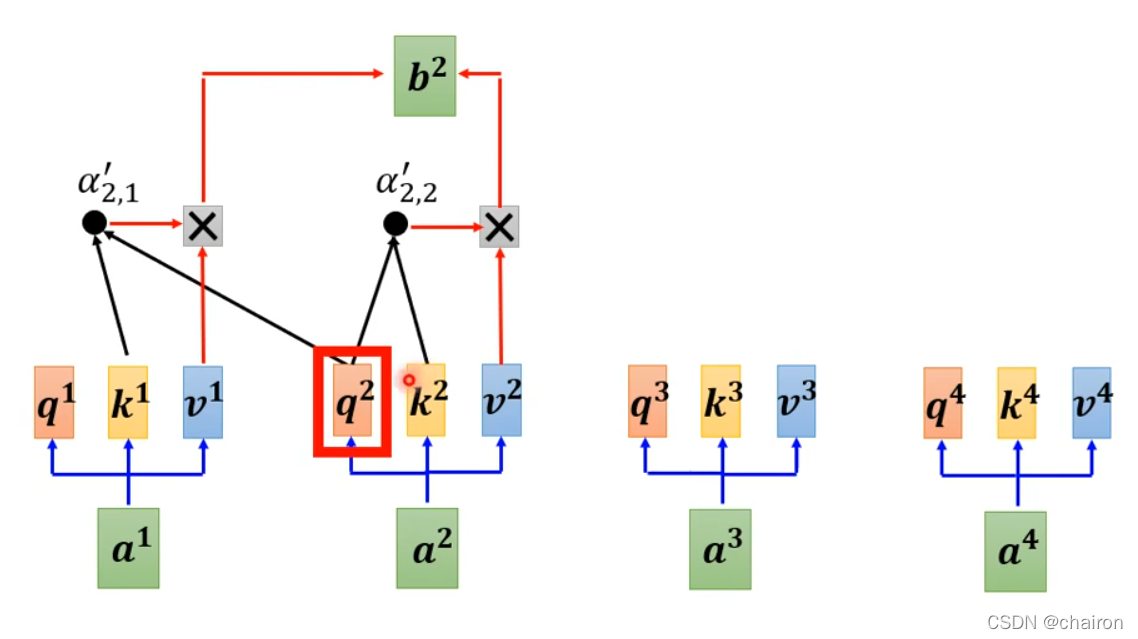
比如:计算b2就只考虑a1和a2
2. Non-autorgressive(NAT)
NAT:输入一排begin,同时产生所有输出。并行的,快,但是不如AT效果好
怎么知道该输入多少个begin信号呢?
- 在decoder之前用一个分类器,输入为encoder的结果,输入为一个数字,即该输入decoder的数目
- 设置一个长度上限比如300,同时输入300个begin信号,如果遇到end,end后面的就不输出
Cross attention
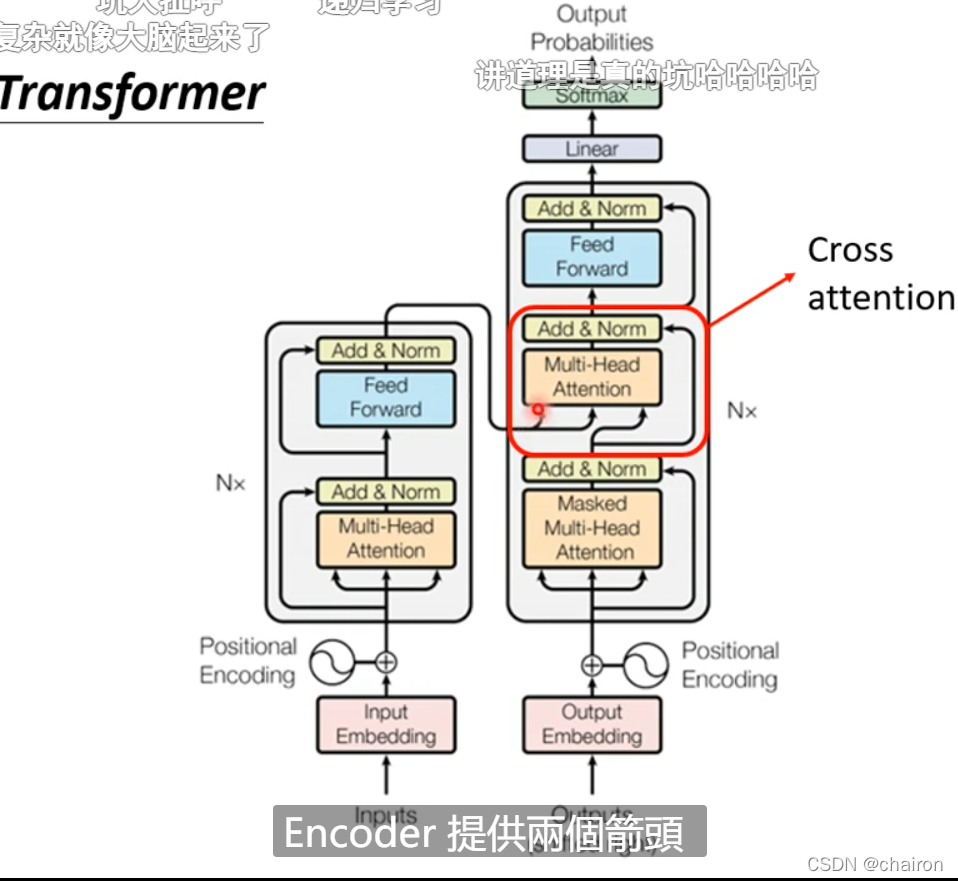

Cross attention:用Encoder产生的所有的K、V和decoder中的Mask self-attention产生的q分别再做attention计算
traning
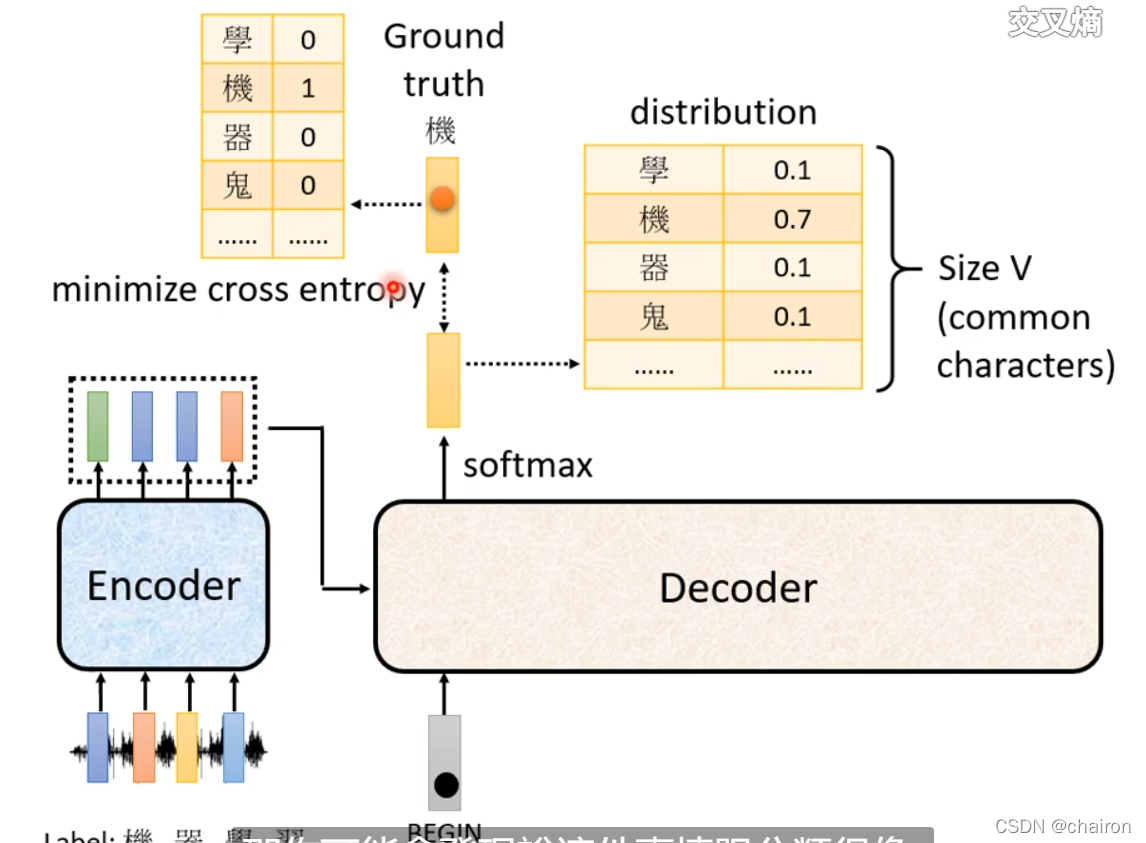
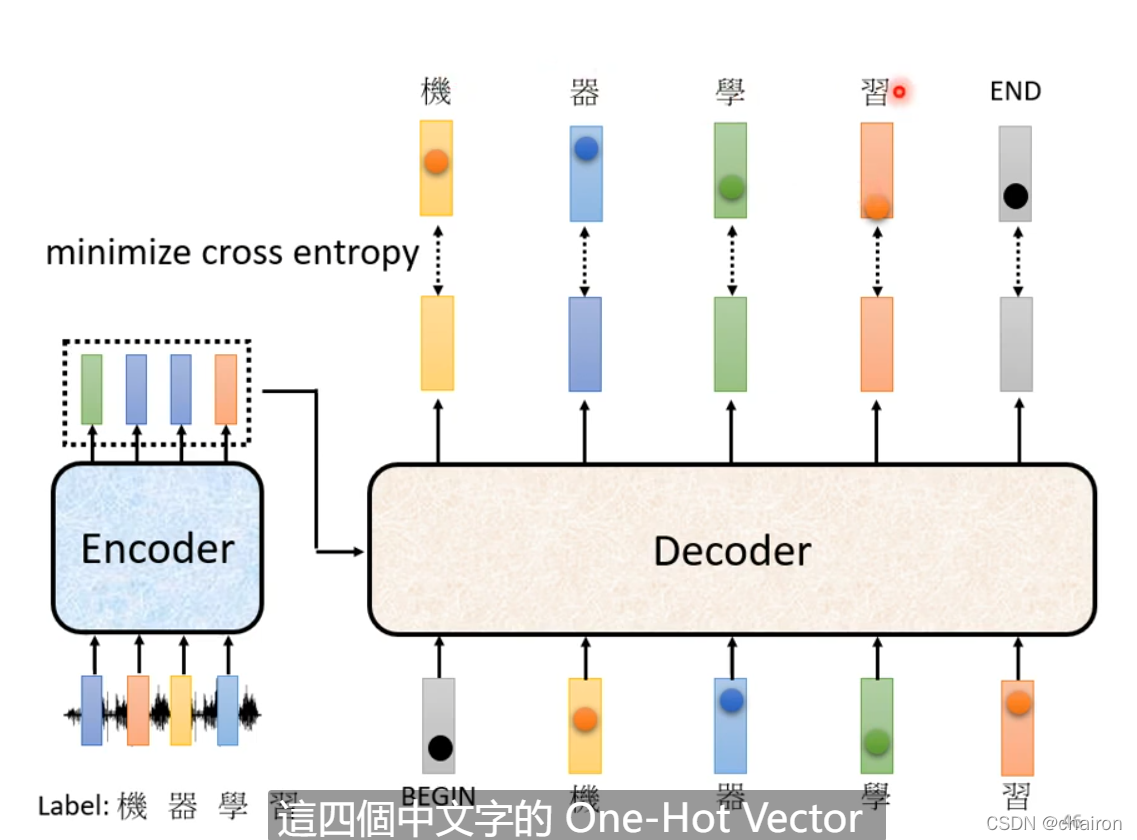
Teacher Forecing:将正确答案作为decoder输入
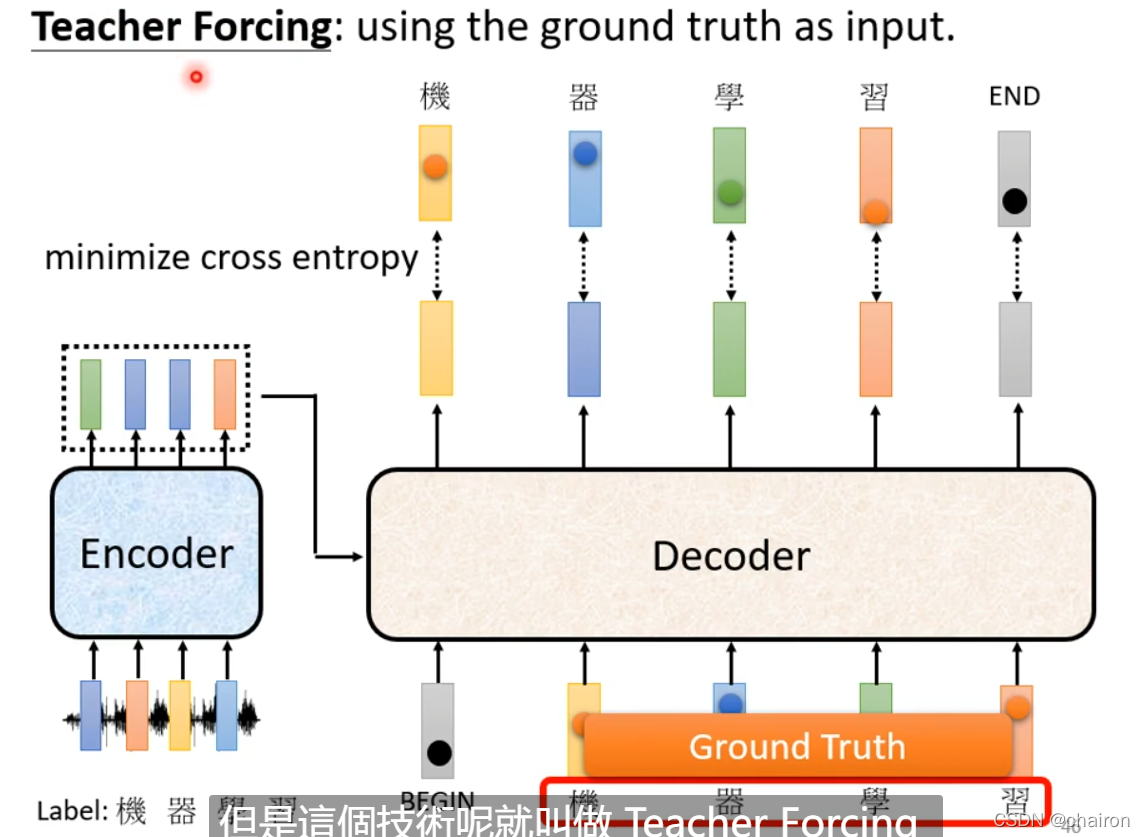
tips
- Copy Mechanism
有些信息可以从输入的信息中复制过来,不需要机器生成(可以从文章中训练生成摘要)

(李宏毅大佬居然还看《全职猎人》,我幻影旅团团长库洛洛·鲁西鲁!!!居然被提到了,还有小杰!其实我更喜欢犽奇耶
-
Guided Attention
在一些任务中,机器可以会忽略掉一些内容,影响效果,比如语音合成、语言识别,可以通过Guided Attention处理
Guided Attention强迫你的attention有固定的样貌(顺序、限制) -
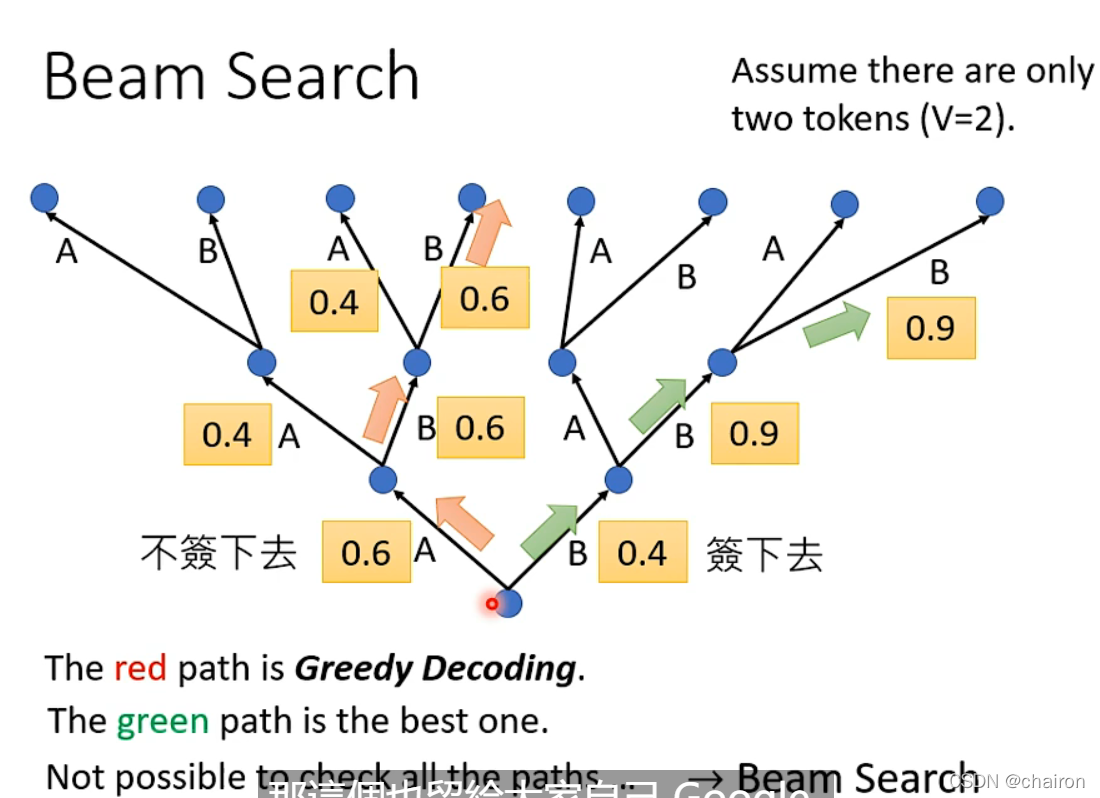
Beam Search
寻找最优路径的一个比较好的方法(有时有用,有时没用,看任务本身,任务目标本事很明确,结果确定的比较有用;有时候decoder有一些随机性比较好,比如语音合成TTS)
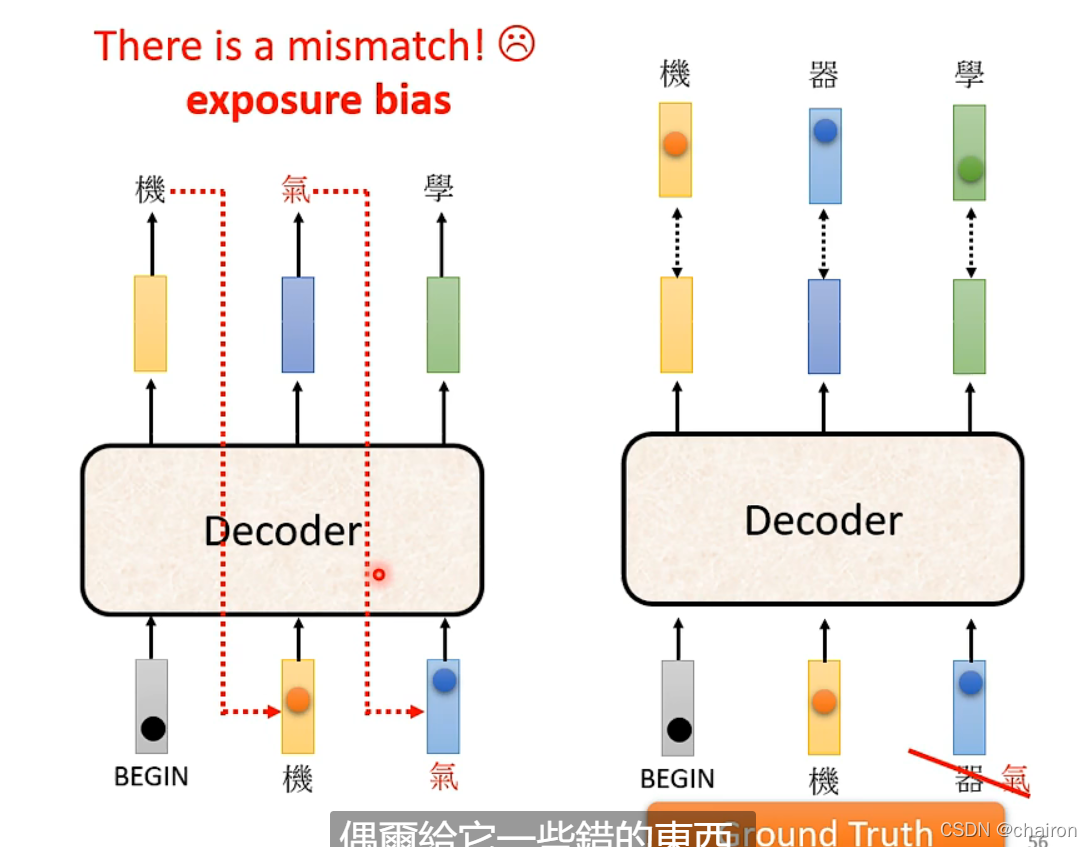
exposure bias
在训练时,一直给Decoder 正确的数据进行训练,会产生正确的答案,但是在测试的时候可能会出错,一步错步步错,因为decoder是要利用上一个的输出进行预测,如果上一个就错了…这个现象叫exposure bias
解决办法:在decoder进行训练的时候就给一些噪声(错误数据)即Scheduled Sampling,但会伤害到transfomer的平行化能力

















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









