






目录
1.物体级语义VSLAM系统架构
物体级语义VSLAM一般采用多线程的算法架构,分为前端和后端。前端主要由跟踪线程和检测 线程构成:跟踪线程负责图像特征提取,并通过帧 间特征匹配和局部BA(Bundle Adjustment) 优化求解 相机位姿;检测线程使用深度网络对输入图像进行 语义信息提取,并将其送入到跟踪线程中。图像语 义信息是基于当前帧的检测结果,因此,使用物体 数据关联对不同帧的检测信息进行处理,并进行物 体初始化。后端优化线程负责相机和物体位姿优 化,以及对物体建模的参数进行调整。最终,系统 构建了物体级的语义地图,实现环境的语义感知。 语义信息的获取形式可以分为 : 目 标 检 测 ,语义分割 ,实例分割 。 不同的语义信息获取方式会影响算法的实时性,通 常,语义分割网络耗时更长,且语义分割得到的像 素级分割结果存在信息冗余和误检,目标检测网络 效率更高,但在复杂场景下容易出现漏检和误检的 现象。后端优化方式可以分为独立优化和联合优化 策略,例如,OA-SLAM 使用独立的线程来优化 二次曲面参数,QuadricSLAM 则将物体和相机 放在局部BA 的统一框架下优化。 近年来,融合目标检测和实例分割的物体 级SLAM 成为研究的热点,该类方法通过多视图几何约束,利用物体检测框重建物体模型。重建模型 可以分为二次曲面,立方框等。实例分割可以获得更准确的物体实例掩码,通常用于辅助 物体特征提取和数据关联,实现更准确的目标跟踪 。常见的物体级VSLAM结构如图2所示。
近年来,融合目标检测和实例分割的物体 级SLAM 成为研究的热点,该类方法通过多视图几 何约束,利用物体检测框重建物体模型。重建模型 可以分为二次曲面,立方框等。实例分割可以获得更准确的物体实例掩码,通常用于辅助物体特征提取和数据关联,实现更准确的目标跟踪。常见的物体级VSLAM结构如图2所示。
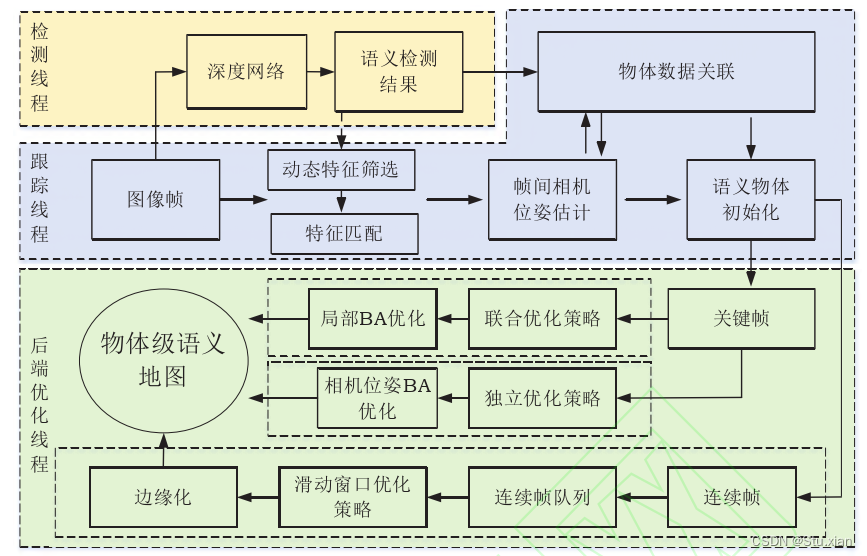
物体级语义VSLAM结构图
2.物体级语义VSLAM优势和应用
(1)动态干扰,当 前VSLAM 算法大多基于环境静态假设,特征匹配和 优化容易受到外点干扰,导致跟踪精度变差或者丢 失。
(2)光照变换,传统的视觉特征在光照变化或 者暗光条件下,特征匹配和图像光度误差匹配失败,导致无法实现位姿估计,算法鲁棒性降低。
(3)高层次的语义感知需求,传统的VSLAM在表征物体上具有局限性,不具有语义信息,无法满足人机交互等复杂任务的需求。
2.1利用物体信息提升定位精度
近年来,一些工作将物体检测结果的语义属性引 入VSLAM 中,对场景中物体的动静态进行判断,并 剔除动态物体的干扰。Detect-SLAM 通过目标检测剔除动态点,并通过特征匹配和扩展区 域进行运动概率传播,在提升定位精度的同时提升 了目标检测的稳定性。DS-SLAM使用实例分割 结果和运动一致性判断物体的运动属性,并将动态 特征进行剔除以提升定位精度。DynaSLAM将 落在运动物体掩码内的特征作为外点剔除,从而提 升其在动态场景下的定位鲁棒性。类似的,Kaveti 等人提出了Light Field SLAM,通过合成孔径 成像技术重建被遮挡的静态场景,不同于Bescos 等 人的算法,其进一步利用了重建背景的特征进 行位姿跟踪以实现更好的定位性能。
作为VSLAM对动态场景理解的扩展,结合运动 跟 踪 的VSLAM成 为 当 前 研 究 的 热 点 。Wang 等 人首先提出了带有运动物体跟踪的SLAM,将 自身位姿估计和动态物体位姿估计分解为两个独立 的 状 态 估 计 问 题 。Kundu 等 人 结 合SfM (Structure from Motion, SfM) 和运动物体跟踪来解决 运动场景下的SLAM 问题,该方法将系统输出统一 到包含静态结构和运动物体轨迹的三维动态地图 中。Huang 等人提出了ClusterVO,能够进行多 个物体的运动估计。该方法提出了一种多层概率关 联机制来高效地跟踪物体特征,利用异构条件随机 场(Conditional Random filed, CRF)聚类方法进行 物体关联,最后在滑动窗口内优化物体的运动轨 迹。Bescos等人将运动物体与自身状态估计问 题紧耦合到统一框架中,对跟踪点集使用主成分分 析(PCA)聚类和立方框建模,并使用动态路标点对自 身位姿进行约束
考虑到场景的先验约束,Twist SLAM使用 机械关节约束来限制物体在特定场景位姿估计的自 由度,结合3D目标检测获得先验物体估计,使用语 义信息来构建物体点簇地图,并利用静态簇(道路和 房屋)来估计相机位姿。动态簇则通过速度的变化进 行跟踪和约束。VDO SLAM使用聚类点的形式对物体进行状态估计,使用实例分割和稠密场景 流,提高了动态物体观测的数量和关联质量,该方 法将动态和静态结构集成到统一的估计框架中,实 现了对相机位姿和物体位姿的联合估计。
2.2利用物体信息提升定位鲁棒性
物体语义信息能有效克服大视角变换以及光 照变换等情况,为VSLAM 提供更鲁棒的定位。 实时的物体级单目SLAM算法SLAM++ 利用 了一个大型物体数据库,使用单词袋来识别对象, 实现鲁棒定位。Zins 等提出的OA-SLAM 利用 重建的物体级语义地图进行相机重定位。该方案结合了特征描述子和场景物体的重投影观测,利用物体的相对位置关系约束,在视角变化剧烈的场景下实现定位,提升了视觉定位的鲁棒性。Liu 等提出基于物体级描述符的定位方法。文献提出基于深度网络的物体描述符定位方法。 CubeSLAM利用物体立方框和当前帧的目标检测约束,提升系统在无纹理场景下的定位鲁棒性。QuadricSLAM提出基于二次曲面的物体观 测约束,首次使用3D 椭球作为路标,同时使用一个 联合优化框架,将相机位姿和二次曲面联合优化。利用单目视觉构建的物体级路标和物体先 验大小约束,减少了单目定位的尺度漂移,提升了单目视觉的定位精度和鲁棒 性 。EAO-SLAM则使用物体立方框约束构建观 测误差,减少了定位漂移。 可以看出,融合物体语义信息已经成为了提高视 觉定位精度和鲁棒性的有效途径之一。语义信息已 经广泛应用于SLAM 系统的初始化、后端优化、重 定位和闭环检测等阶段。因此,有效地处理和利用 语义信息是提高定位精度的关键。
2.3利用物体信息提升系统环境感知能力
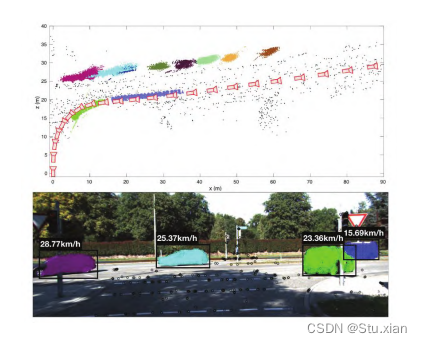
早期的物体SLAM,例如,SLAM++利用物 体CAD模型构建语义地图,通过目标检测和识别, 将先验物体数据库的物体加载在地图中。文献 [36] 将语义标签信息融合到稠密点云地图中,构建了稠 密语义地图。CubeSLAM和EAO-SLAM通过立方框构建物体级地图。 文献 构建了物体的二次曲面地图,同时 估计了物体的大小、旋转和位置。相比于二次曲面 和立方体的包络,超二次曲面可以通过调节二次模 型参数适应不同形状的物体,丰富环境物体的表 达。使用超二次曲面构建室内场景的物体级地图。一些工作将抽象的语义标识加入到地图表 达中,AVP-SLAM通过检测道路的车道线,交 通标识等信息构建了轻量级的语义地图,用于实现 准确的室外场景定位。 另外,一些研究者将运动物体的感知信息加入 到SLAM中,提出了SLAM-MOT,在构 建场景稀疏点云地图的同时,表达物体的运动轨 迹,构建包含运动信息的物体地图。例如,VDO SLAM提出利用语义信息构建环境结构,跟踪刚 性物体的运动并估计其三维运动轨迹,其地图表示 如图3 所示。 可以看出,融合语义信息后,VSLAM的地图表 达形式更加丰富。构建的物体级地图包含场景的高 层次语义信息,而且通过动态跟踪和联合位姿估 计,可以获得动态物体的速度和运动轨迹估计,使 得VSLAM可以实时估计环境物体的运动轨迹,具有更丰富的环境感知能力。
3.物体语义的表达形式和初始化方法
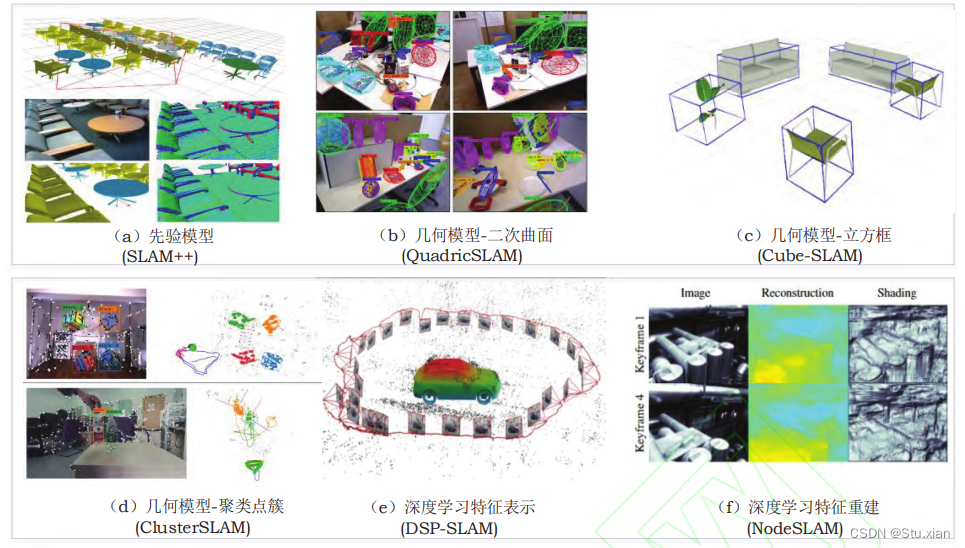
先验模型表达
先验模型表达使用预先建立的先验数据库,通过 检测-匹配的方式加载物体。
几何模型表达
几何模型通过参数化的二次曲面或者立方框实 现,
深度学习表征
粗略的几何模型往往不能表示物体的精确体积, 而稠密点云需要大量的内存占用来存储地图。最近 一些工作使用基于深度学习的特征进行模型表达, 结合学习表征的物体级路标实现室外定位。DSP-SLAM使用DeepSDF(Signed Distance Function)网络]提取物体特征,并通过网络参数 和表面重建损失函数进行物体表面恢复,构建场景的物体地图 , 如图(e) 所示 。SceneCode 和NodeSLAM则使用了深度网络中间层特征来表征物体。利用这些深度提取的特征和表面渲染误差函数,可以恢复物体的几何形状,如图(f) 所示。
以上可知,物体的初始化表征方法决定了物 体SLAM的地图表达形式,深度学习需要高算力的计算设备,且系统的实时性无法保证,几何模型可以 准确描述物体的大小、旋转和位置,能完整表达物 体的占据信息,且地图占用小,已经成为当前研究 的热点。
4.物体级语义信息的数据关联方法
基于概率关联方法
该方法将属于物体的观测约束建模为概率分布模型,根据模型分布关系来确定帧间物体关联。
基于分配算法的关联方法
5.融合物体级语义信息的后端优化方法
在物体完成初始化后,需要利用后续观测信息对 地图中的重建物体进行优化,根据物体是否参与相 机位姿优化,后端优化策略可以分为独立优化策略 和联合优化策略。根据是否需要跟踪场景中的动态 物体,联合优化策略的因子图也有不同的形式。后端优化策略示意图如图:
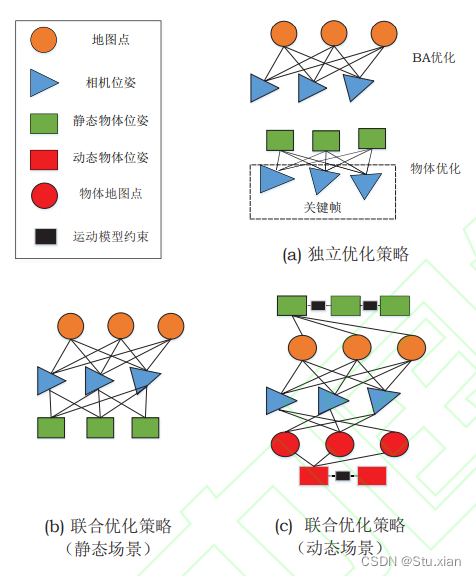
独立优化策略
如图5(a)所示,独立优化策略下,物体的位姿和 模型参数单独进行优化,物体模型利用跟踪线程中 提供的相机初始位姿进行优化。独立优化关注于物体重建,在进行物体位姿优化 调整时无法对相机定位结果进行修正,当相机定位失败时,系统无法实现准确的自身定位和语义地图构建,没有充分利用语义信息辅助定位。
联合优化策略
(1)联合因子图,该方案将物体参数和位姿估 计放在统一因子图中进行优化,并根据是否需要对 动态物体进行位姿估计分别采用不同的因子图。 静态场景的联合优化因子图如图5(b) 所示,该方 法通常适用于静态场景或采用动态特征剔除策略 的SLAM算法。
动态场景的因子图如图5(c)所示,引入了动态物 体 位 姿 估 计 和 模 型 参 数 优 化 的 误 差 因 子。
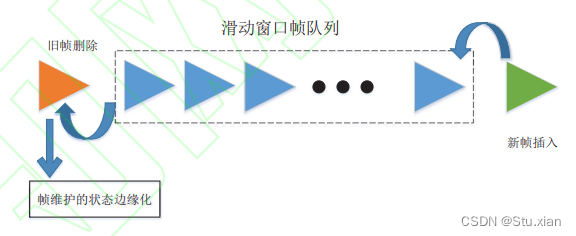
(2)滑动窗口优化策略,相比于静态场景,动 态场景下的物体观测容易受到漏检、遮挡等因素的干扰,基于关键帧的关联方案不能为动态物体提供 准确的数据关联信息。为了克服这些问题,一些基 于滑窗的优化方式被提出。滑动窗口由 固定帧数的观测队列组成,当新的帧观测加入队列 时,位于时序最早的帧观测被移出,同时其维护的 状态也通过滑窗边缘化的方式进行求解,如图所示。 滑动窗口优化将物体位姿和相机位姿放在统一优 化框架中,由于运动物体的特点,使用滑窗优化可以有效利用连续帧的特征信息。如DynaSLAM2将场景静态结构,相机位姿以及动态物体运动轨迹维 护在一个紧耦合的局部BA进行优化,通过目标检测 的二维检测框构建物体位姿约束,使用舒尔补加速 稀疏矩阵边缘化求解,解决滑窗优化的计算效率问题。
可以看出,滑窗的方式具有快速响应,参数优化 更准确的特点,适用于动态物体的跟踪和位姿估 计。基于因子图的联合优化可以有效利用关键帧信 息,对室内场景的物体优化更准确。

















 3764
3764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









