










本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:使用 YOLOv10 实现姿态检测
什么是姿态检测
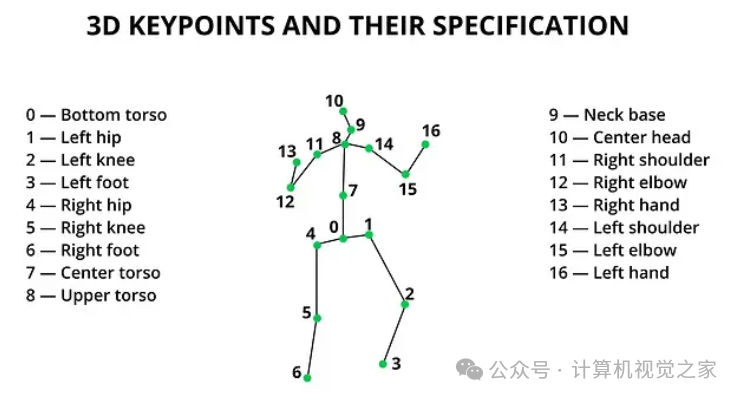
简单来说,姿态估计就是从给定的输入图像中识别出称为关键点的特殊坐标。如上图所示,人体关节、面部特征就是关键点。从技术上讲,人工智能算法必须从大量带注释的图像中学习这些关键点的物理表征,然后在新的未见过的图像上预测这些关键点。
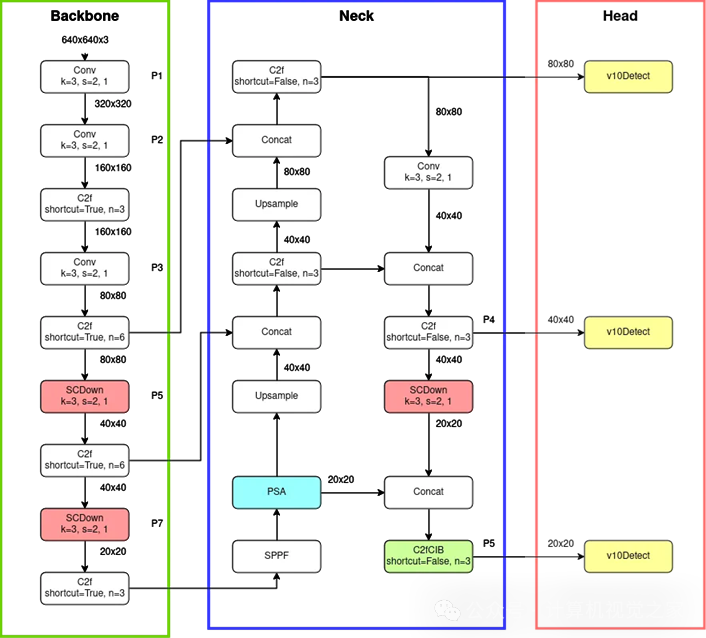
YOLOv10 架构
什么是NMS(非最大抑制)

YOLO 系列的早期版本会为给定图像中的目标预测多个边界框。NMS 算法用于从多个预测中筛选出一个边界框。上图展示了 YOLO 模型在 NMS 处理前后的预测对比。NMS 是一个后处理步骤。有关该算法的更多详细信息,请参阅。
YOLOv10 训练流程:
一般来说,我们如何训练就是我们如何推断。旧版 yolo 使用 TAL(任务对齐器)(ref1,ref2)为单个真实边界框提供多个(通常 k=10)正例框。这简化了模型目标函数,提供了强监督和更快的收敛速度,但在推断过程中会产生非极大值抑制 (NMS) 的代价。
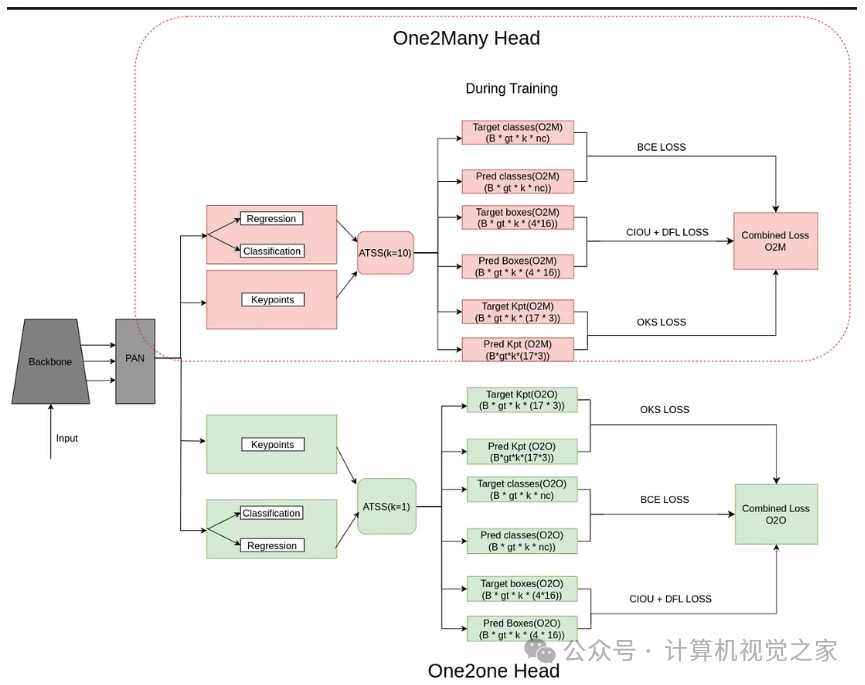
在 v10 中,我们引入了 one2many 和 one2one 两个 head。我们将 head 与骨干网络和颈部网络联合训练。one2many 会分配多个正边界框,而 one2one 则每个 ground truth 只分配一个正边界框。因此,在训练过程中,模型会学习特征,并从 one2many head 获得监督。在推理过程中,我们排除 one2many head,只考虑 one2one head 的输出。该 head 已经学会为每个 ground truth 预测一个边界框。因此,无需 NMS。
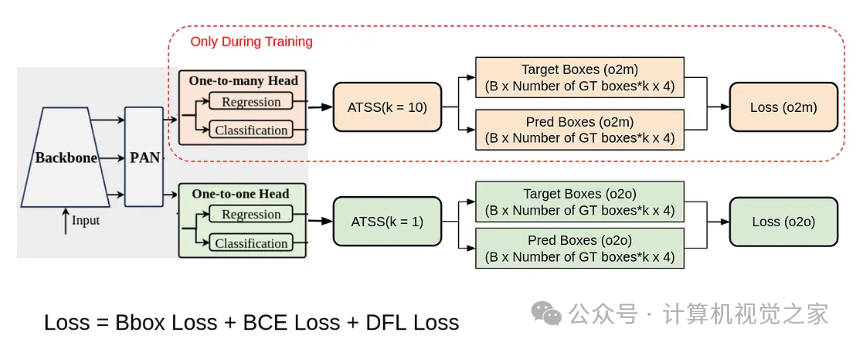
如图所示,两个模型使用相同的损失函数。在 one2many 中,我们保持(每个 ground truth 对应的正样本)k=10,而在 one2one 中,我们保持 k=1。
它使用二元交叉熵进行分类,使用 CIOU(完全 iou 损失)和 DFL(分布式焦点损失)进行回归(预测边界框)。
后处理(无 NMS)
在 YOLOv10 中,我们采用了 2 个检测头,分别命名为:
- 一对多
- 一对一头
one2many 头部训练与 Yolo 的早期版本(尤其是 YOLOv8)类似,其中每个地面实况的多个检测用于计算损失,因此导致每个对象有多个框检测。
但是新增加的 one2one 头经过了这样的训练:只使用与地面实况框最匹配的一个预测来计算损失。
添加结构
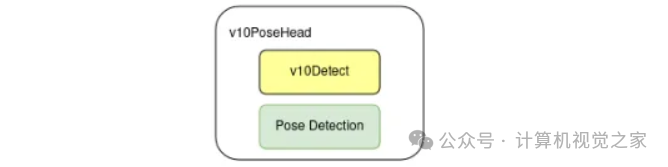
我们用 v10Pose 头替换了 v10Detect 头,它可以同时进行框检测和关键点检测。
YOLOv10-姿势训练流程
除了 v10detect 之外,我们还添加了 one2many 和 one2one 关键点头,并将其称为 v10pose。
与 YOLOv10 相同,在训练过程中,我们除了训练两个检测头之外,还联合训练了 one2many 和 one2one 关键点头,并进行了姿态损失训练。在推理阶段,我们排除了 one2many 头,仅使用 one2one 关键点头的输出作为关键点预测。
人脸关键点检测
数据集描述
本次实验我们使用 WiderFace 数据集,该数据集包含人脸边界框以及眼、鼻、口 5 个关键点。数据集被划分为 80% 用于训练,20% 用于验证。训练数据集包含约 12646 张图像,验证集包含 3162 张图像。
用例
人脸检测和姿态估计是人脸识别流程的第一步。我们检测人脸的边界框和 5 个关键点。之后,我们使用预测的关键点将人脸裁剪并对齐到 112x112 大小的图像中。这是人脸识别中一个重要的预处理步骤,因为它将眼睛、鼻子和嘴巴对齐到固定位置,以便于与其他脸部图像进行比较。简单来说,它是对人脸图像进行归一化。
实验设置
我们使用 WiderFace 数据集训练了 YOLOv10 nano 模型,并添加了一个姿态检测分支。所有图像均保持原有的宽高比,并调整为 640x640 像素,并使用了旋转、水平翻转、平移和缩放等数据增强技术。该模型训练了 80 个 epoch,批次大小为 8,并使用了 SGD 优化器,初始 lr 为 0.01。
结果
下图展示了使用 WiderFace 数据集训练的 yolov10-pose 模型的结果。第一列显示原始图像,第二列显示 Ground Truth 标注,最后一列显示模型的预测结果。第一行显示一张包含单张人脸的图像,其余两行显示一张包含多张人脸的图像。我们的模型能够检测图像中的多张人脸及其关键点。

下图展示了 YOLOv10-Pose 模型在一张未见过的 PID 卡图像上的测试结果。我们的新模型能够成功检测出人脸和关键点。

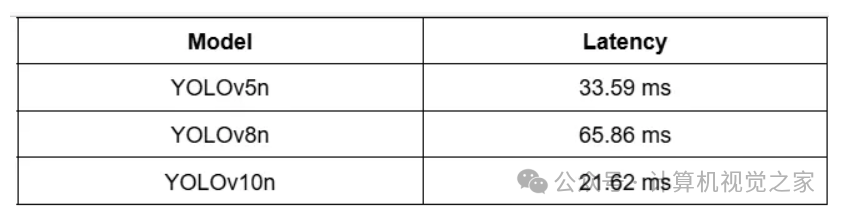
下表显示了 yolov5-face 模型与 yolov10 模型的延迟对比。这两个模型都预测了边界框以及 5 个关键点,并在 WiderFace 数据集上进行训练。我们可以清楚地看到,YOLOv10-pose 的延迟更低,因为无需后处理步骤(NMS)。
Coco Human Pose
数据集描述

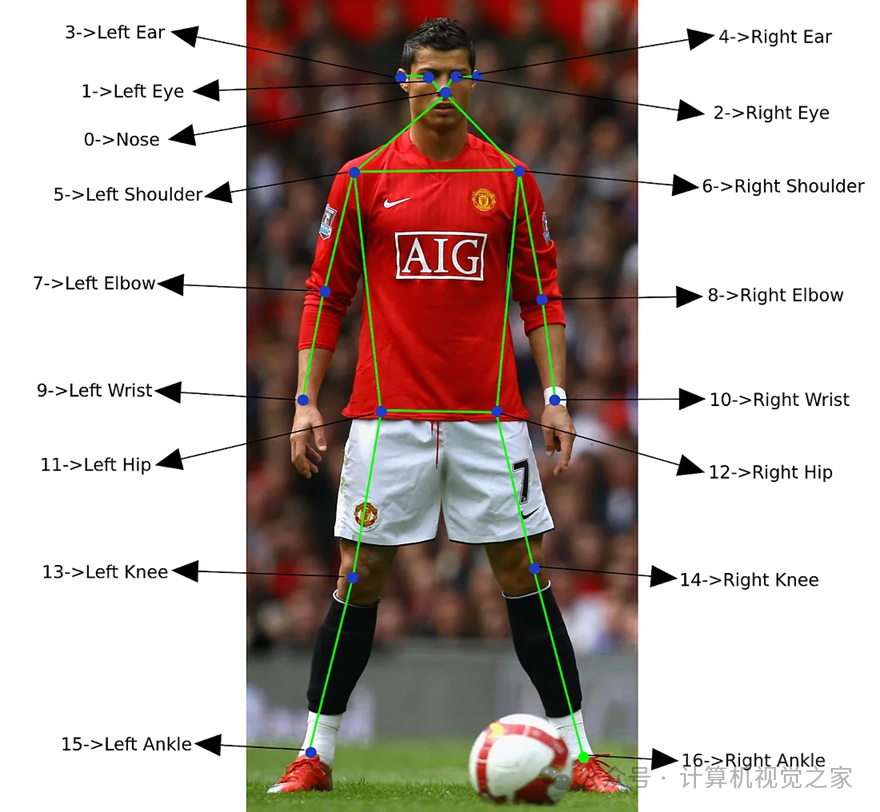
我们使用了“COCO 2017 关键点检测任务”提供的数据集。该数据集提供不受控制场景下的人物图像,每个人物都带有一个边界框注释,并包含最多 17 个描述人物姿势的关键点。
关键点标记如下:
我们使用的数据集分为两部分:
-
-
Train2017(训练集)包含 56599 张图片
-
Val2017(验证集)包含 2346 张图片
-
用例
-
-
姿势检测可以帮助健身房训练分析一个人的姿势并帮助纠正姿势或相应地计划锻炼。
-
生成建模中的姿势迁移,即将一个人的姿势迁移到另一个人的图像或 3D 模型上,以模仿源姿势。它可用于机器人技术、AR/VR、游戏和电影中的视觉效果。
-
在体育运动中,可以分析运动员的姿势,以便进行有效的表现分析和训练。
-
实验设置
我们通过将图像调整为 640x640 尺寸在训练集上训练 YOLOv10,并应用了许多随机增强技术,如颜色抖动、模糊、裁剪、仿射变换、水平和垂直翻转。
我们使用了 YOLOv10 的 nano 版本,它是 v10 系列中最小的模型,并使用 YOLOv10 检测模型的预训练权重来加载网络主干的权重。头部保留了原始的初始化权重。
在训练期间,我们使用了 16 的批量大小,在 T4 GPU 上运行了 100 个 epoch,持续 30 小时。
结果
YOLOv10 姿态模型的真值与预测的定性比较

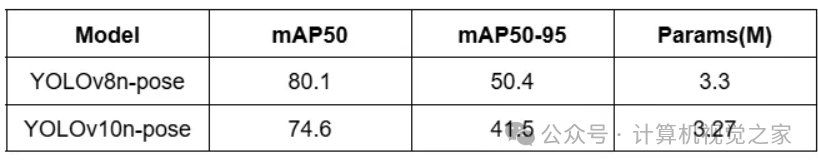
与 YOLOv8 的比较
结 论
我们在 WiderFace 和 COCO 数据集上训练了 YOLOv10,并添加了一个姿态估计模块。这些是我们的初步实验,展示了在 YOLOv10 框架(无 NMS 模型)中实现姿态估计的潜力。
此外,指标和损失图表明,如果训练/微调更多轮次,则有可能获得更好的结果。由于仍有改进空间,因此在一些明显的情况下,该模型未能给出正确的结果。

YOLO框架不断进步,最新版本为YOLO12。
它采用以注意力为中心的方法,而非先前版本中基于 CNN 的经典方法。这一方法与其他网络架构改进相结合,使其能够以更少的参数实现更高的准确率,同时保持实时推理速度。
未来研究将探索 YOLO12 中无 NMS 方法在物体和姿态检测方面的潜在应用。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









