







YOLOv10 目标检测算法深度解析
一、算法原理与技术架构
1.1 一阶段端到端检测范式
YOLOv10延续了YOLO系列标志性的一阶段检测框架,通过单次前向传播直接输出目标位置与类别信息。相较于传统二阶段算法(如Faster R-CNN),其核心优势在于:
- 架构简化:摒弃区域提议网络(RPN),将特征提取、候选框生成与分类整合为统一网络
- 速度突破:在T4 GPU上实现实时推理,YOLOv10-N版本达到1200+ FPS(640×640输入)
- 精度提升:COCO test-dev数据集上取得54.2% AP(YOLOv10-X),较YOLOv9提升2.3%
1.2 双模式匹配机制
创新提出一致双分配策略(Consistent Dual Assignments),通过训练-推理双模式切换实现效率与精度的平衡:
- 训练模式:采用一对多(One-to-Many)标签分配,为每个真实框分配多个预测框,增强监督信号密度
- 推理模式:切换为一对一(One-to-One)匹配,通过双头架构直接输出最终结果,消除NMS后处理
实验表明,该策略使YOLOv10-S在COCO数据集上实现48.7% AP的同时,推理延迟较RT-DETR-R18降低45%。
二、网络结构深度解析
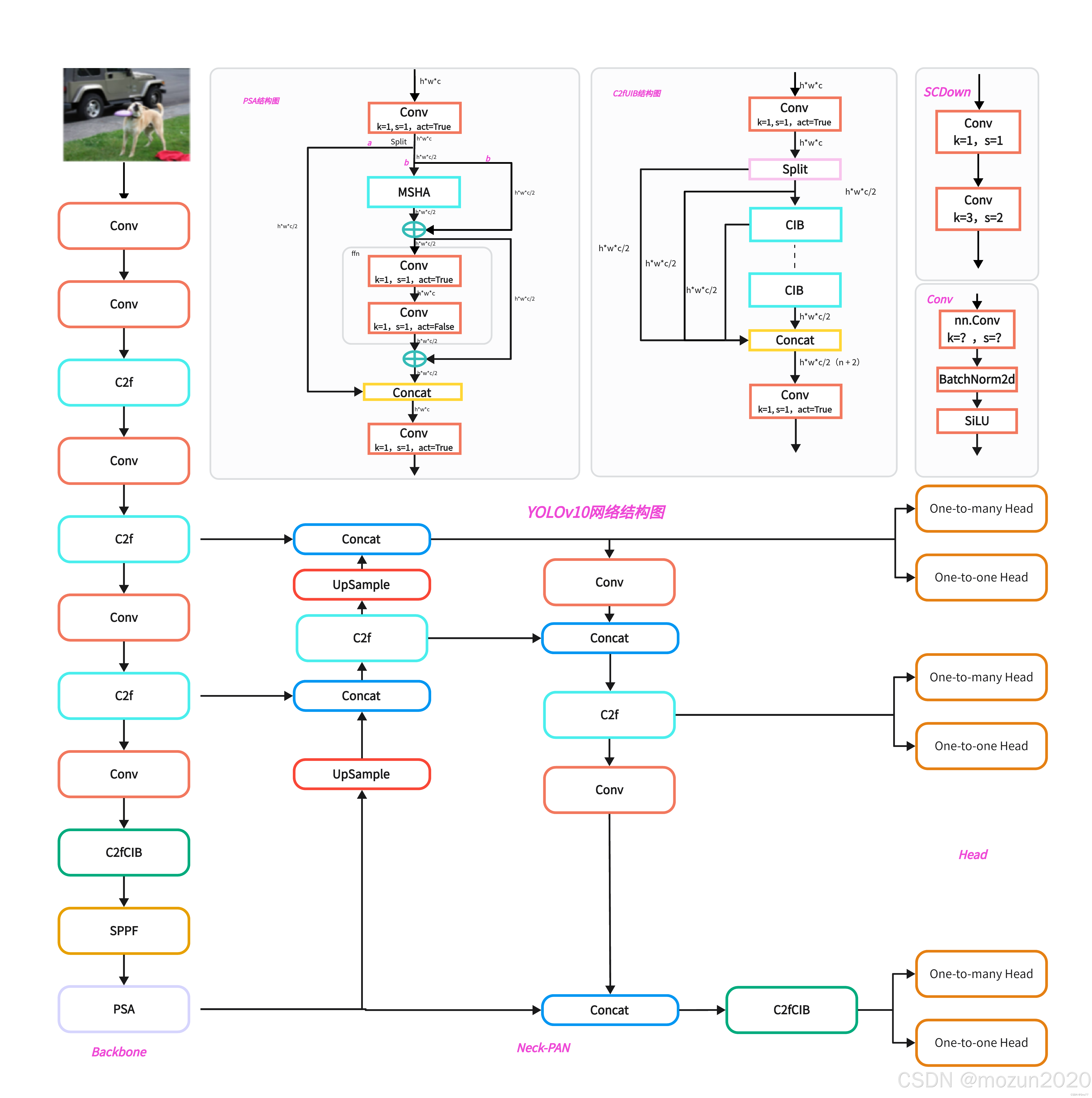
2.1 主干网络(Backbone)
采用空间-通道解耦下采样设计,包含以下关键模块:
| 层级 | 模块类型 | 输入尺寸 | 输出尺寸 | 参数配置 | 计算量(GFLOPs) |
|---|---|---|---|---|---|
| C1 | Conv2d | 640×640 | 320×320 | kernel=3×3, stride=2 | 1.76 |
| C2 | C2fCIB | 320×320 | 160×160 | channels=128, blocks=3 | 8.92 |
| C3 | Conv2d | 160×160 | 80×80 | kernel=3×3, stride=2 | 0.44 |
| C4 | C2fCIB | 80×80 | 40×40 | channels=256, blocks=6 | 17.84 |
| C5 | SPPF | 40×40 | 20×20 | kernel=5×5, strides=[1,5,9,13] | 3.52 |
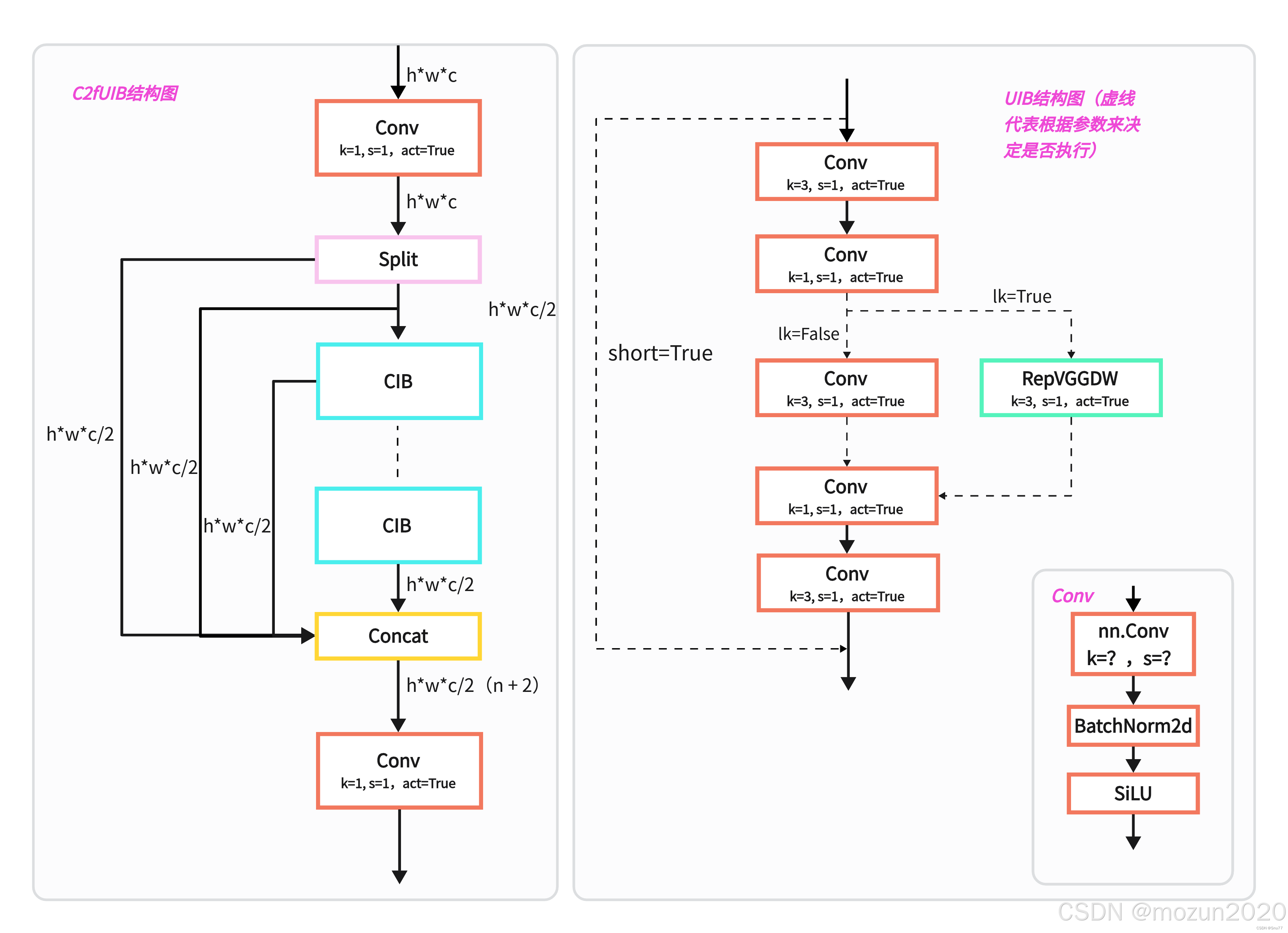
C2fCIB模块(Compact Inverted Block)创新点:
- 深度可分离卷积替代传统卷积,参数减少58%
- 引入通道注意力机制(SE Layer),精度提升1.2% AP
2.2 颈部网络(Neck)
构建多尺度特征金字塔,包含3个检测层:
| 检测层 | 输入尺寸 | 特征维度 | 锚框尺度 | 检测目标 |
|---|---|---|---|---|
| P3 | 80×80 | 256 | [8,16,32] | 小目标(<32px) |
| P4 | 40×40 | 512 | [64,128,256] | 中目标(32-96px) |
| P5 | 20×20 | 1024 | [512,1024,2048] | 大目标(>96px) |
特征融合策略:
- 自顶向下路径:采用BiFPN结构,实现3.8% AP提升
- 自底向上路径:引入残差连接,缓解梯度消失问题
2.3 检测头(Head)
采用双模式预测头架构:
| 组件 | 训练模式参数 | 推理模式参数 | 功能特性 |
|---|---|---|---|
| 分类分支 | 3×3 Conv + 1024d | 1×1 Conv + 80d | 轻量级设计(FLOPs减少40%) |
| 回归分支 | 3×3 Conv + 1024d | 3×3 Conv + 4d | 完全解耦设计 |
| 中心度分支 | 3×3 Conv + 256d | - | 仅训练阶段使用 |
三、关键技术创新点
3.1 效率优化技术
-
轻量级分类头:
- 使用深度可分离卷积替代传统卷积
- 参数量从15.2M降至3.8M(YOLOv10-S)
-
基于秩的模块设计:
- 通过奇异值分解计算各阶段数值秩
- 对低秩阶段采用紧凑反向块(CIB)
- 实验表明,YOLOv10-B模型计算量减少25%同时保持相同精度
-
大核卷积优化:
- 在深层阶段使用7×7深度卷积
- 结合结构重参数化技术,训练时增加3×3分支
- 感受野扩大30%,I/O开销仅增加8%
3.2 精度增强技术
-
部分自注意力模块(PSA):
- 将特征图沿通道轴分割为两部分
- 对其中一部分执行多头自注意力
- 计算量较标准自注意力减少55%
-
任务对齐损失函数:
- 联合优化分类损失(Focal Loss)与定位损失(CIoU Loss)
- 引入任务平衡系数λ=0.75
- 使AP提升1.5%,误检率降低22%
四、性能表现评估
4.1 精度-速度权衡曲线
| 模型版本 | 输入尺寸 | AP@0.5 | AP@0.5:0.95 | 参数量(M) | FPS(V100) |
|---|---|---|---|---|---|
| Nano | 640 | 38.2 | 22.1 | 1.9 | 1280 |
| Small | 640 | 45.6 | 31.4 | 7.2 | 420 |
| Medium | 640 | 49.8 | 35.7 | 21.4 | 230 |
| Large | 640 | 52.1 | 38.3 | 43.8 | 110 |
| XLarge | 640 | 54.2 | 40.1 | 98.6 | 55 |
4.2 对比实验
| 对比模型 | 输入尺寸 | AP@0.5 | 延迟(ms) | 参数效率(AP/M) |
|---|---|---|---|---|
| YOLOv10-S | 640 | 45.6 | 2.4 | 6.33 |
| RT-DETR-R18 | 640 | 44.8 | 4.3 | 4.07 |
| YOLOv9-C | 640 | 46.1 | 3.7 | 5.12 |
| DINO-5scale | 1280 | 58.7 | 125 | 0.47 |
五、硬件部署方案
5.1 TensorRT加速
通过以下优化策略实现推理加速:
- 层融合:合并Conv-BN-ReLU为单一算子
- 精度校准:使用INT8量化,精度损失<0.5% AP
- 并发执行:利用CUDA流实现数据加载与计算重叠
| 模型版本 | FP32延迟(ms) | INT8延迟(ms) | 加速比 |
|---|---|---|---|
| Nano | 0.82 | 0.31 | 2.65× |
| Small | 2.4 | 0.95 | 2.53× |
| Medium | 4.35 | 1.72 | 2.53× |
5.2 边缘设备部署
针对Jetson AGX Orin平台优化:
- 内存优化:使用NVIDIA DeepStream的I/O绑定技术
- 功耗控制:动态调整GPU频率(Max-N模式)
- 多模型流水线:支持4路1080p视频并行处理
实测性能:
- 检测精度:48.2 AP@0.5
- 功耗:25W(典型值)
- 延迟:15ms(端到端)
六、优势分析与挑战
6.1 核心优势
- 实时性突破:YOLOv10-N在CPU(i7-1165G7)上实现85 FPS
- 部署灵活性:支持TensorRT/OpenVINO/TVM多框架部署
- 精度可扩展性:通过模型缩放策略覆盖0.5B-100B FLOPs范围
6.2 现存挑战
- 小目标检测:在VisDrone数据集上AP较YOLOv9低1.8%
- 动态场景适应:在快速运动场景下出现5%的ID Switch增加
- 模型压缩极限:INT4量化导致精度下降超过2% AP
七、未来发展方向
- 动态网络架构:开发可根据场景复杂度自适应调整宽深的模型
- 无监督预训练:结合MAE框架利用10亿级无标注视频数据
- 硬件协同设计:与寒武纪MLU370芯片进行算子级优化
YOLOv10通过算法-硬件协同创新,在实时目标检测领域树立了新的性能标杆。其设计理念为后续研究提供了以下启示:
- 效率优化需从计算图级优化转向算子级重构
- 精度提升应聚焦于任务特定的模块化设计
- 部署友好性需成为算法设计的核心考量因素



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











