







本文的原作者决定重新回顾了开源机器学习生态系统这个主题,并对模型相关的技术栈进行了分析。
原文链接:https://huyenchip.com/2024/03/14/ai-oss.html
未经允许,禁止转载!
作者 | Chip Huyen 译者 | 弯月
出品 | CSDN(ID:CSDNnews)
四年前,我分析了开源机器学习生态系统。此后,情况又发生了很多变化,所以我决定重新回顾一下这个主题。这一次,我主要分析基础模型相关的技术栈。
完整的开源人工智能存储库列表托管在 llama-police 上。该列表每 6 小时更新一次。你也可以浏览我的GitHub库的 cool-llm-repos 列表(https://github.com/stars/chiphuyen/lists/cool-llm-repos)。

数据
我使用关键词 gpt、llm 和 generative ai 在 GitHub 上搜索了一番。如今 AI 的热门绝非虚言,仅 gpt 一词就搜到了 118,000 个结果。
为了缩小范围,我将搜索限制在至少有 500 颗星的存储库中。llm 有 590 个结果,gpt 有 531 个结果,generative ai 有 38 个结果。我还查看了 GitHub 趋势和社交媒体,找到了几个新存储库。
经过多个小时的努力,我找到了 896 个存储库,其中有 51 个是教程(例如 dair-ai/Prompt-Engineering-Guide)和合集(例如 f/awesome-chatgpt-prompts)。尽管这些教程和合集很有帮助,但我更感兴趣的是软件,所以最后分析了845 个软件存储库。

添加缺失的存储库
毫无疑问,还有很多存储库没有添加进来,欢迎各位提交星星少于 500 的存储库,我会持续关注,并将达到 500 星的存储库添加到列表中。

新的AI技术栈
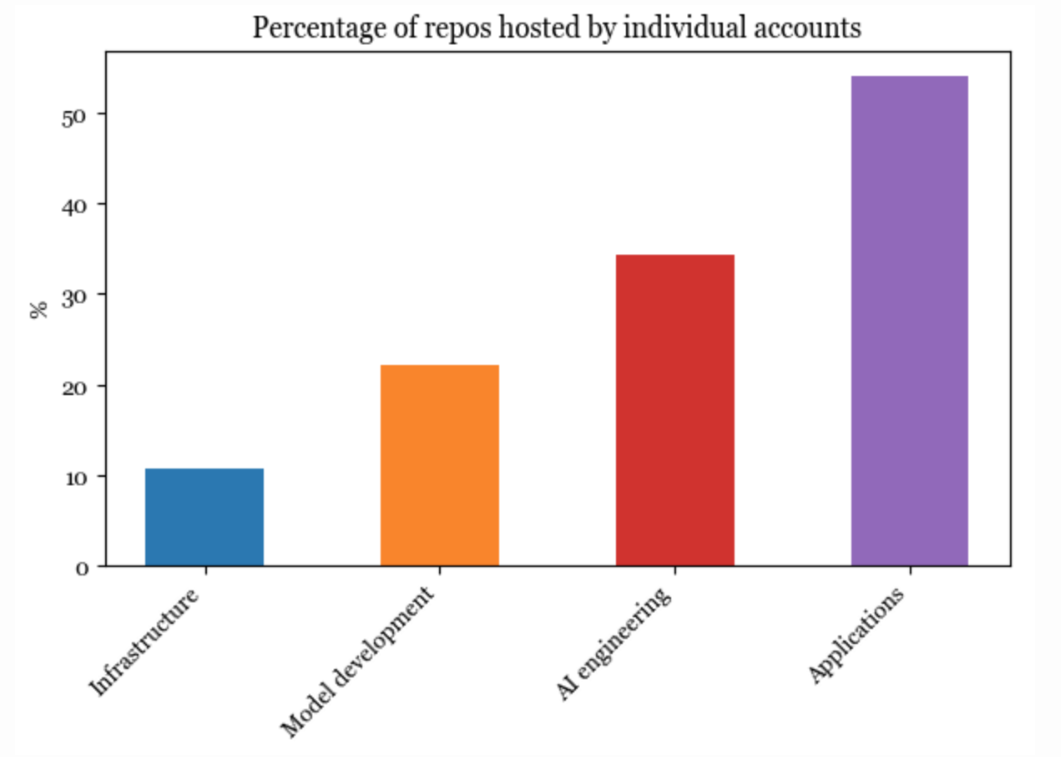
我将 AI 技术栈分为了 4 层:基础设施、模型开发、应用开发和应用程序。
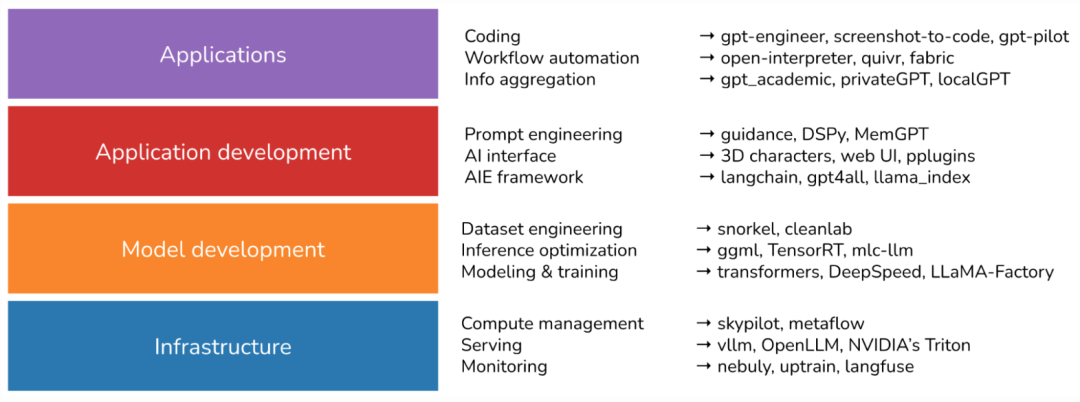
1. 基础设施
AI 技术栈中的最底层是基础设施,其中包括服务(vllm、NVIDIA 的 Triton)、计算管理(skypilot)、向量搜索和数据库(faiss、milvus、qdrant、lancedb)等工具。
2. 模型开发
这一层提供了开发模型的工具,包括建模和训练的框架(transformers、pytorch、DeepSpeed)、推理优化(ggml、openai/triton)、数据集工程、评估等。所有修改模型权重的操作都在这一层进行,包括微调。
3. 应用开发
有了现成的模型,任何人都可以在其上开发应用程序。在过去的两年中,这一层的变化最大,并且仍在迅速发展。这一层也被称为人工智能工程。
应用开发包括提示工程、RAG、人工智能界面等等。
4. 应用程序
在现有模型的基础之上构建的开源应用程序有很多,最流行的应用程序类型包括编程、工作流自动化、信息聚合等。
除了上述四层之外,还有一个类别:模型存储库,由各家公司和研究人员创建,用于分享与其模型相关的代码。此类别的示例存储库包括 CompVis/stable-diffusion、openai/whisper 和 facebookresearch/llama。

随着时间推移 AI 技术栈的发展
我绘制了一张图,展现了每个月每个类别中存储库的累积数量。在 2023 年 Stable Diffusion 和 ChatGPT 推出后,新工具的数量呈现出爆炸式增长。在 2023 年 9 月趋于平缓,潜在原因可能有三个。
1.我的分析只考虑了星星数多于500颗的存储库,但积累这么多星星需要一定的时间。
2.大部分比较容易实现的解决方案都已经有人占了,剩下的技术需要更多的努力来构建,因此可以构建的人数较少。
3.人们已经意识到在生成式人工智能领域保持竞争力的难度非常大,因此兴奋劲儿逐渐平息了。据我所知,2023 年初,我与各个公司在谈论AI时都集中在生成式AI上,但最近的对话更加务实了。
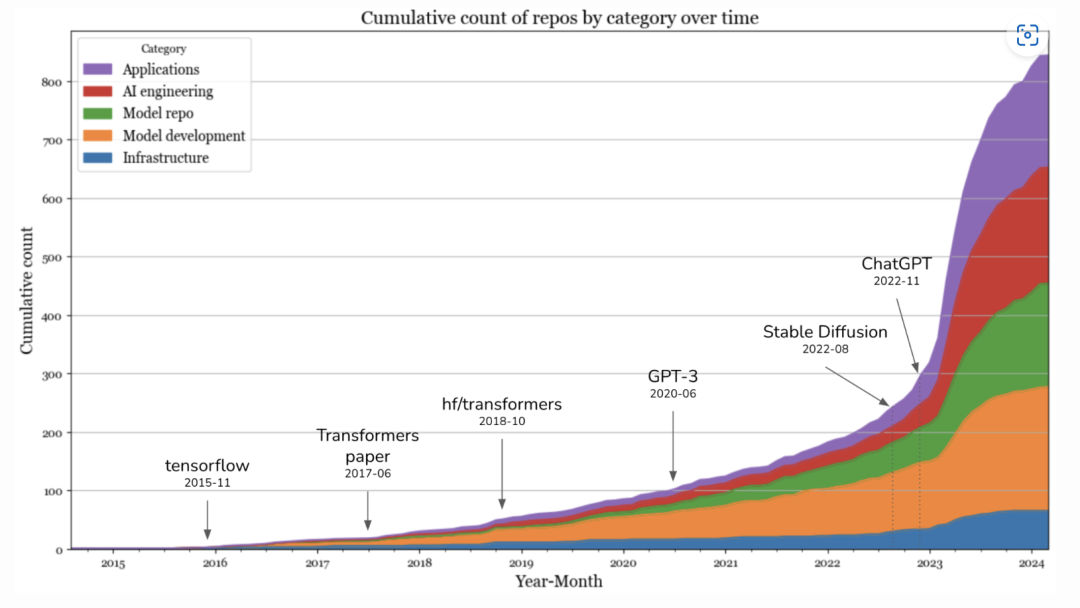
2023 年,应用程序和应用开发层的增长幅度最大。基础设施层也增长了,但远不及其他层次。

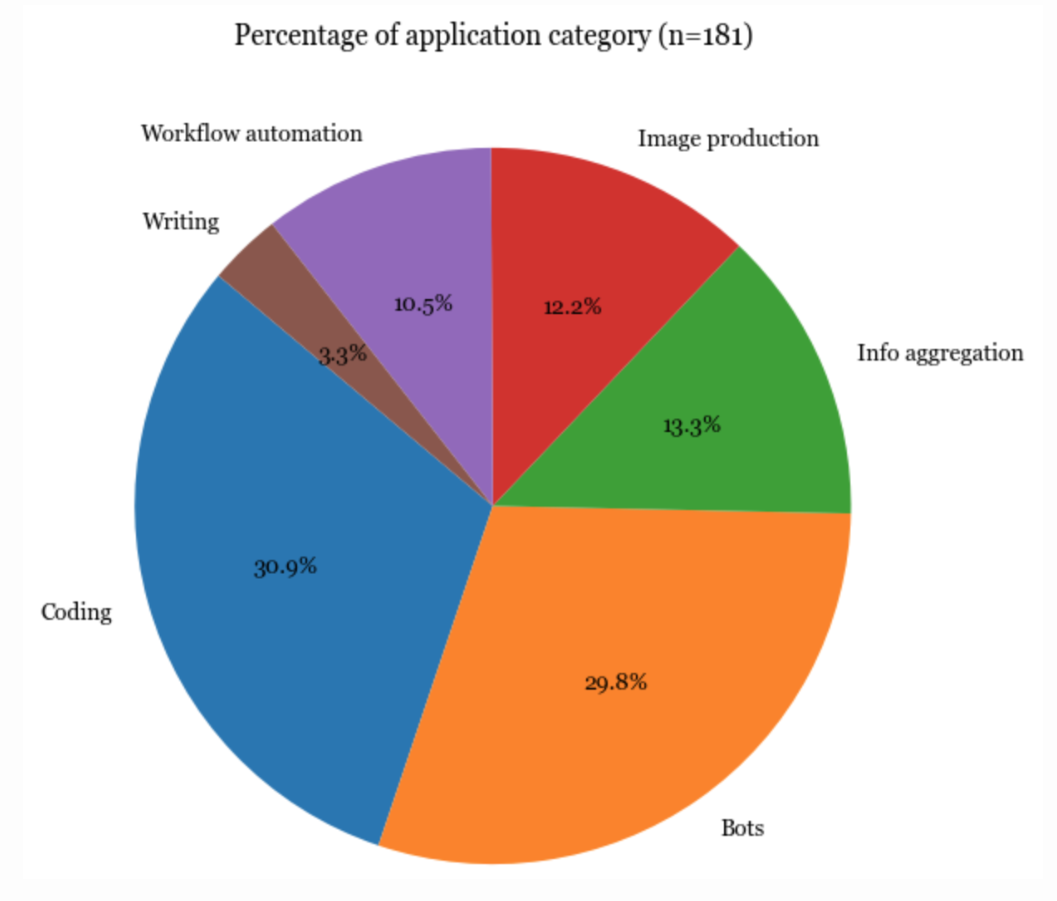
应用程序
毫无疑问,最受欢迎的应用程序类型是编程、机器人(例如角色扮演、WhatsApp 机器人、Slack 机器人)以及信息聚合(例如“连接到Slack 并汇总每天的消息”)。

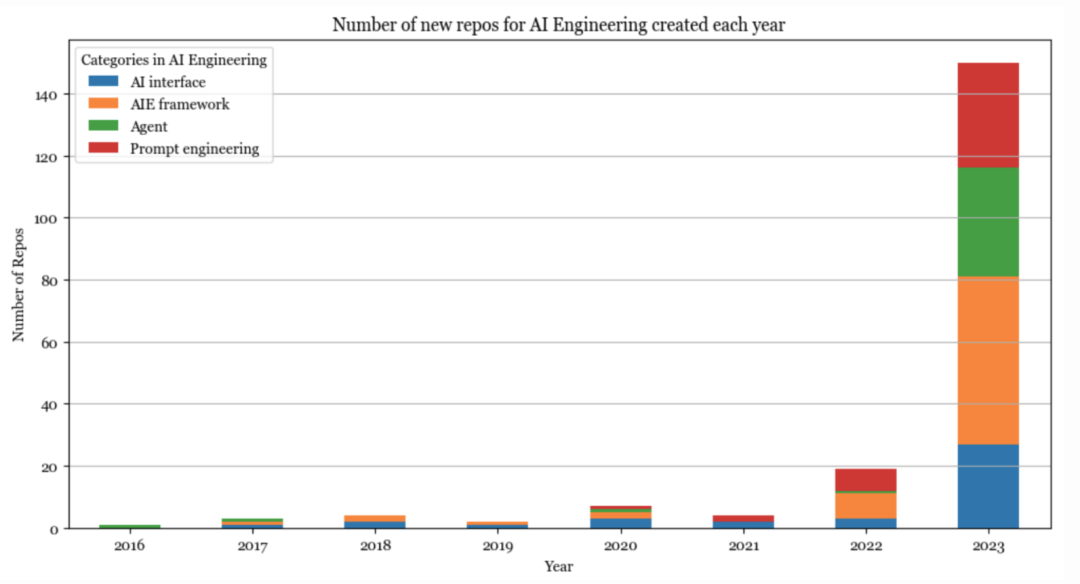
AI工程
2023 年是 AI 工程年,许多工具都很相似,很难分类。我姑且将它们分为以下几类:提示工程、AI 界面、代理和 AI 工程(AIE)框架。
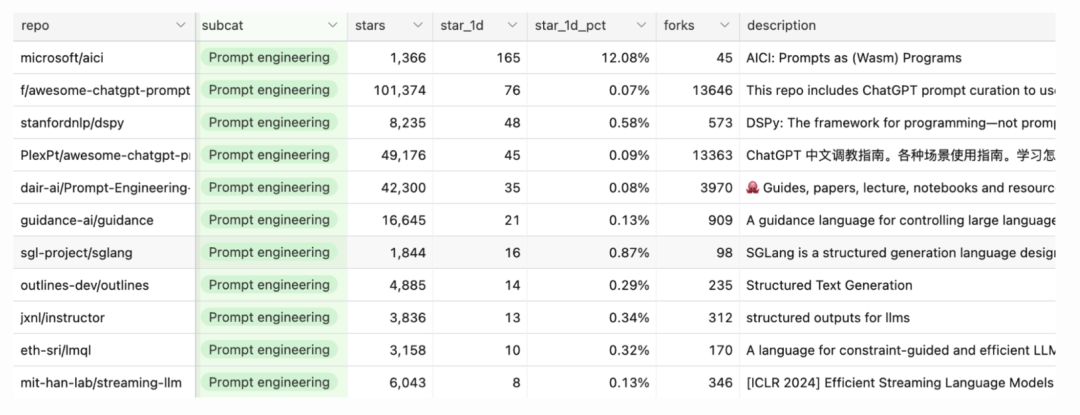
提示工程远不止简单地调整提示,还涉及限制抽样(结构化输出)、长期记忆管理、提示测试与评估等。
AI界面可以提供接口,供最终用户与AI应用程序进行交互。这是我最感兴趣的类别之一。目前较为流行的接口包括:
Web 和桌面应用程序。
浏览器扩展,方便用户在浏览时快速查询 AI 模型。
Slack、Discord、微信和 WhatsApp 等聊天应用机器人。
插件,允许开发人员将 AI 应用程序嵌入到 VSCode、Shopify 以及微软Office 等应用程序。对于可以使用工具完成复杂任务的 AI 应用程序(代理),使用插件更为常见。
AI 工程框架是一个总称,指代所有开发 AI 应用程序的平台,其中许多是围绕RAG 构建的,但也提供其他工具,如监控、评估等。
代理是一个奇怪的类别,因为许多代理工具实际上只是复杂的提示工程,可以限制AI生成的内容(例如,模型只能输出预先确定的操作)和插件集成(例如,让代理使用工具)。

模型开发
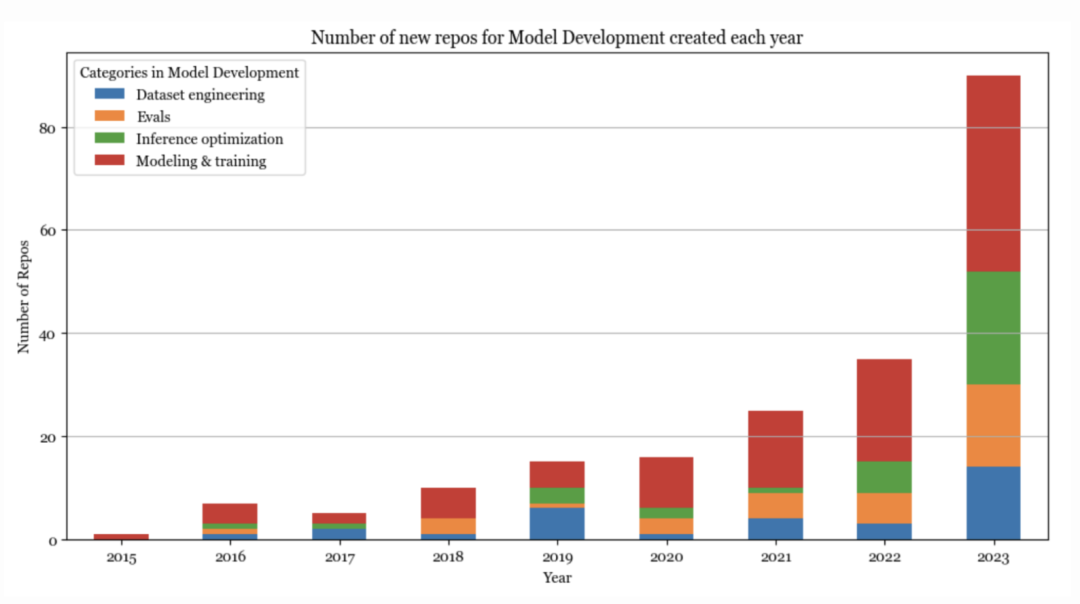
在 ChatGPT 之前,AI 领域主要由模型开发主导。2023 年,模型开发的增长率达到巅峰,主要来自推理优化、评估和参数高效微调(属于建模与训练)等。
推理优化一直很重要,但在当前基础模型规模的推波助澜下,推理优化已成为降低延迟和成本的关键。优化的核心方法仍然没有变(量化、低秩矩阵分解、修剪、蒸馏),但 transformer 架构和新一代硬件发展出了许多新技术。例如,2020 年 16 位量化是最先进的技术。而如今,我们看到了 2 位量化,甚至是低于 2 位的量化。
同样,评估也不可或缺,但随着如今许多人将模型视为黑匣子,评估的重要性愈发突出了。新出现的评估基准和评估方法也很多,例如比较评估和 AI 裁判等。

基础设施
基础设施涉及数据、计算以及服务、监控和其他平台工作的工具的管理。尽管生成式人工智能带来了诸多变化,但开源人工智能基础设施层基本保持不变。这也可能是因为基础设施产品通常都不是开源的。
这一层最新出现的一个类别是向量数据库,比如Qdrant、Pinecone 和 LanceDB 等公司。然而,许多人认为这根本不应该是一个类别。向量搜索已经存在很长时间了。除了为向量搜索构建的新数据库外,DataStax 和 Redis等现有的数据库公司也引入了向量搜索。

开源AI开发者
与许多其他事物一样,开源软件也有着长尾分布,少数几个大账号控制着大部分存储库。
个人与组织
此次我分析的 845 个存储库托管在 594 个 GitHub 账号上,其中有 20 个账号拥有至少 4 个存储库。排名前 20 的账号托管了 195 个存储库,占列表中所有存储库的 23%。这 195 个存储库总共获得了 1,650,000 个星星。
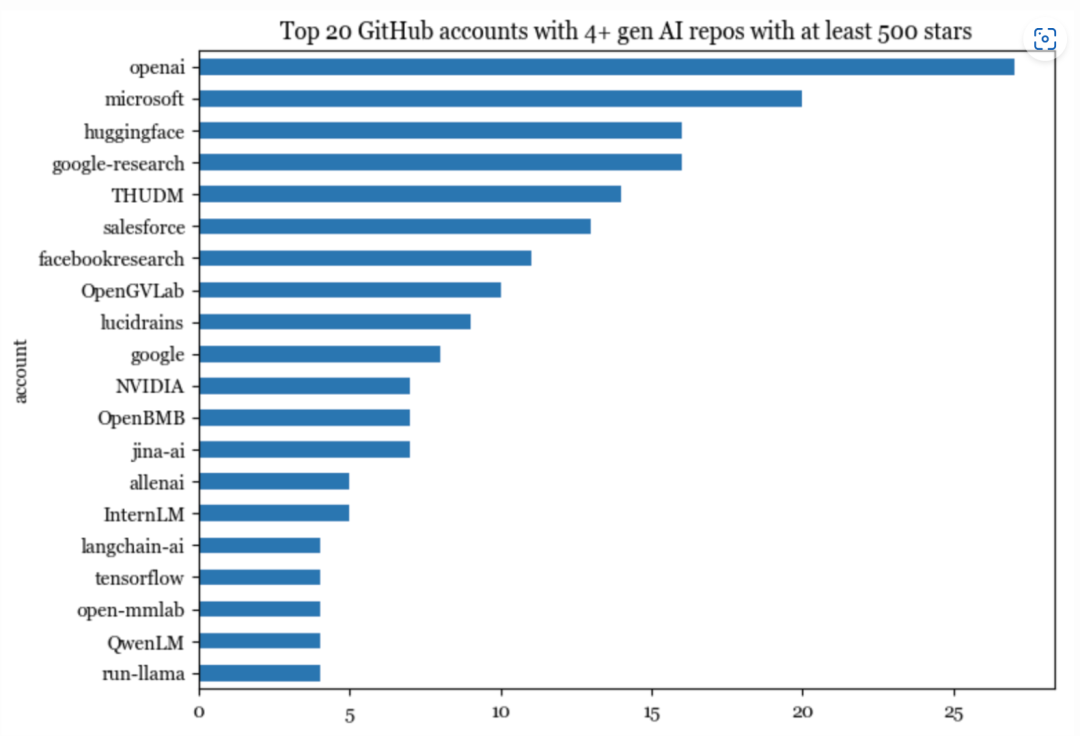
GitHub 账号可以是组织,也可以是个人。排名前 20 的账号中有 19 个是组织,其中谷歌占了3个:google-research、google、tensorflow。
排名前 20 的账号中仅有一个是个人账号lucidrains。星星数量最多的 20 个账号中(仅统计了生成式AI存储库),有 4 个是个人账号:
lucidrains(Phil Wang):能够以惊人的速度实现最先进的模型。
ggerganov(Georgi Gerganov):一个优化专家,拥有物理学背景。
Illyasviel(Lyumin Zhang):Foocus 和 ControlNet 的创建者,目前在斯坦福攻读博士学位。
xtekky:一位全栈开发者,创建了 gpt4free。
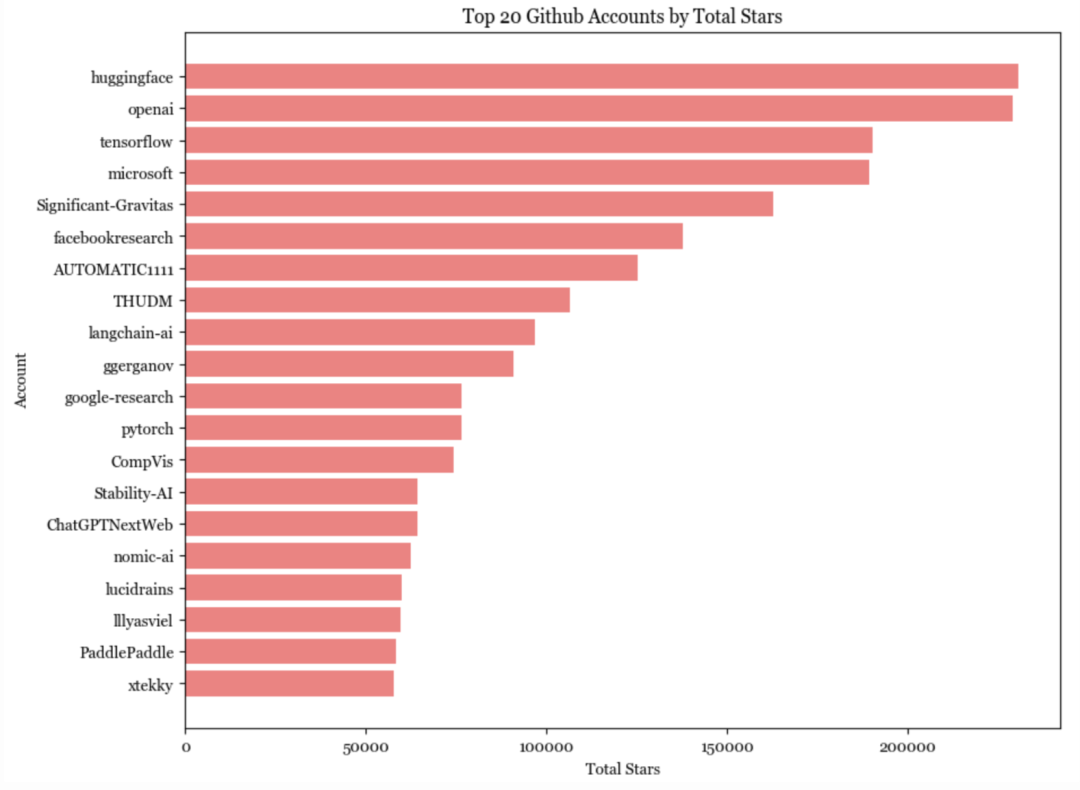
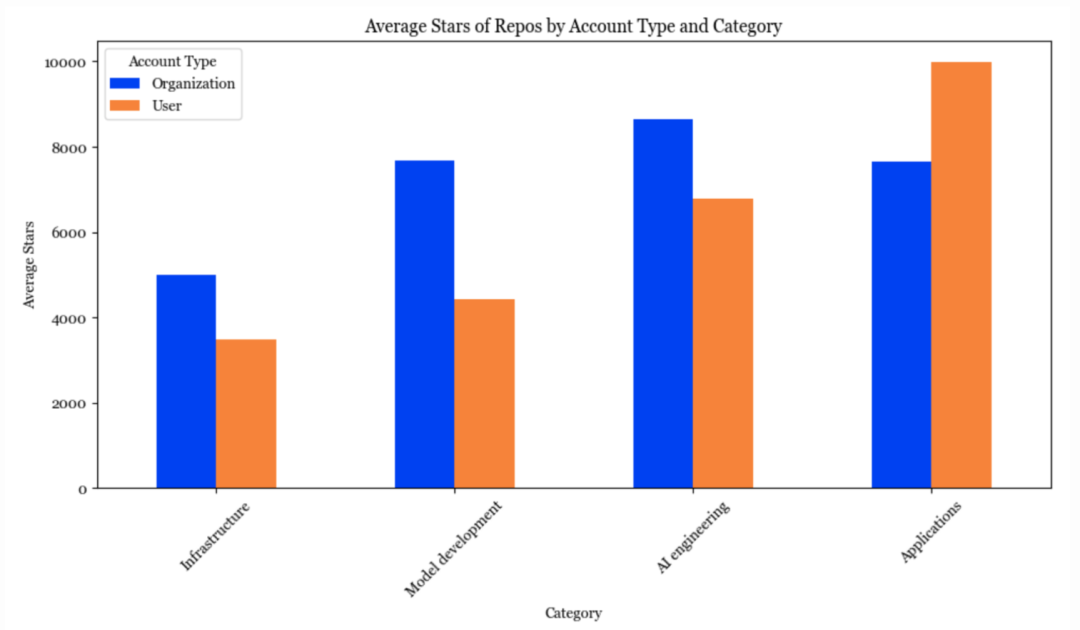
这也不奇怪,越是靠近底层,靠个人力量构建代码库的难度就越大。个人账户几乎不太可能建立并托管基础设施层的软件,而应用程序代码库中,超过一半都来自个人。
个人创建的应用程序平均获得的星星数量超过了组织。一些人认为我们会看到很多非常有价值的个人公司,我也认同他们的看法。

100 万次提交
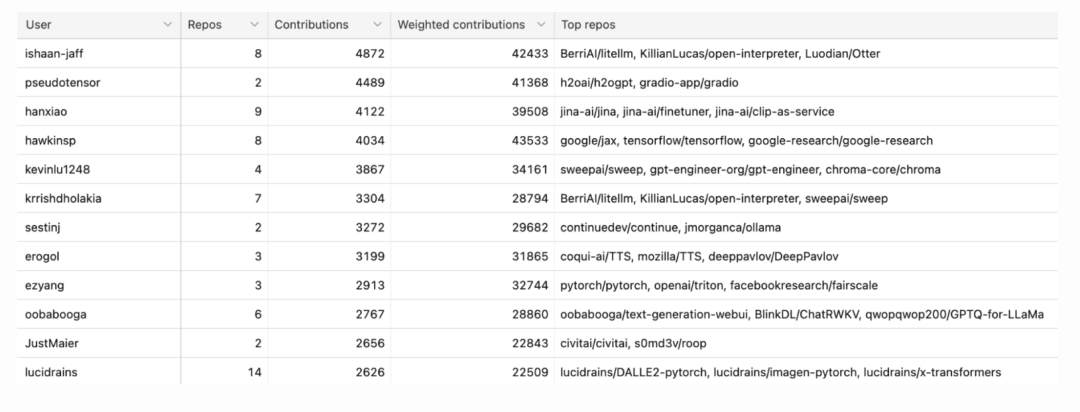
共计 2 万多名开发人员为这 845 个存储库做出了贡献。代码提交次数近 100万!
其中,最活跃的 50 名开发人员共提交了 10 万多次,人均提交次数超过了 2 千次。

中国开源生态系统的发展
GitHub 排名前 20 的账号中,有6个来自中国:
THUDM:清华大学知识工程组和数据挖掘团队。
OpenGVLab:上海人工智能实验室通用视觉团队。
OpenBMB:由ModelBest和清华大学NLP团队共同创建的大模型基地开放实验室。
InternLM:来自上海人工智能实验室。
OpenMMLab:来自香港中文大学。
QwenLM:阿里巴巴人工智能实验室,发布了Qwen模型系列。

来也匆匆,去也匆匆
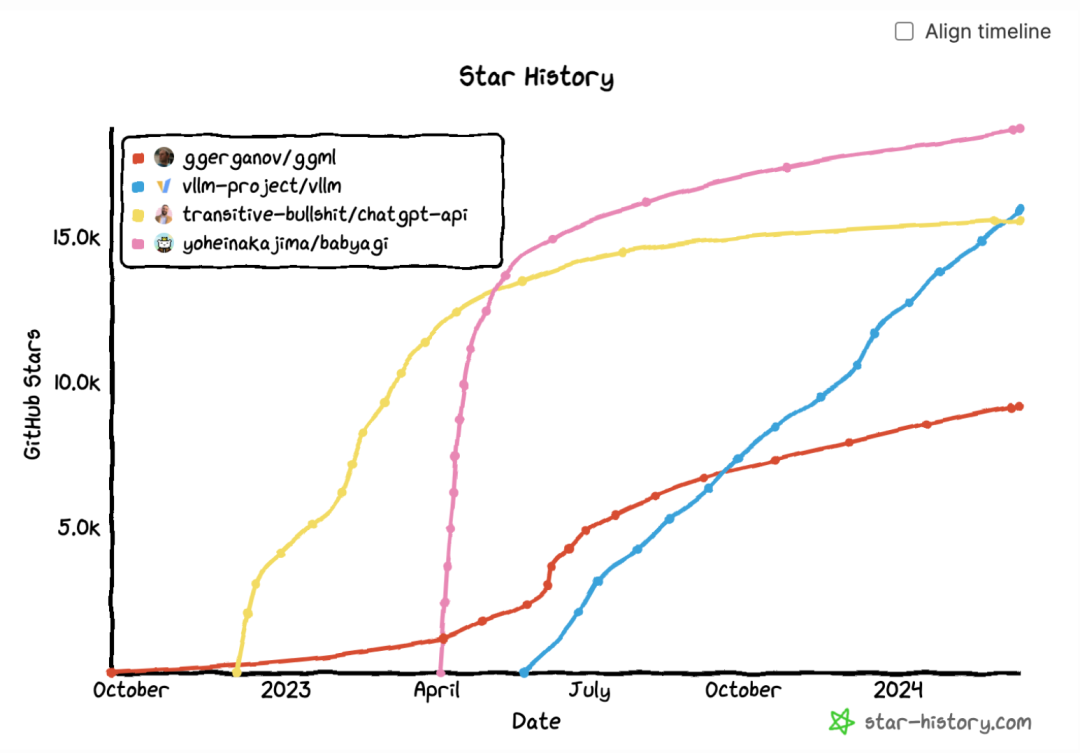
去年,我发现许多存储库在短时间内获得了大量的关注,然后又迅速消失了。我的一些朋友称之为“炒作曲线”。在这 845 个拥有至少 500 个 GitHub 星星的存储库中,有 158 个存储库(18.8%)在过去的 24 小时内没有获得任何新的星星,而有 37 个存储库(4.5%)在过去的一周内没有获得任何新的星星。
以下增长轨迹示意图对比了两个此类存储库以及两个持续增长的存储库。尽管这里显示的两个示例已经没有人使用了,但我认为通过二者可以看出代码库发展的可能性。

个人最喜欢的项目
各个社区不断推出许多酷炫的想法。以下是我最喜欢的一些项目:
批量推理优化:FlexGen,llama.cpp
快速解码器:采用 Medusa、LookaheadDecoding 等技术
模型合并:mergekit
限制采样:outlines,guidance,SGLang
看似小众却能很好地解决一个问题的工具,如 einops 和 safetensors。

总结
此次分析只考虑了 845 个存储库,但我查看了数千个存储库。对于我来说,这对于理解看似庞大的人工智能生态系统很有帮助,希望对你也有所帮助。
推荐阅读:
▶马斯克刚开源10天的Grok遭吊打!132B参数DBRX大模型横空出世,2个月砸1000万美元让最强开源模型易了主
▶悼念!PostgreSQL 重要贡献者 Simon Riggs 因坠机离世
▶数据库规模四年增长近100倍,Figma 如何“活”下来?
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「全球机器学习技术大会」将在上海环球港凯悦酒店举行,特邀近 50 位技术领袖和行业应用专家,与 1000+ 来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。欢迎所有开发者朋友访问官网 http://ml-summit.org、点击「阅读原文」或扫码进一步了解详情。



















 4543
4543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











