









文章目录
1 大模型
大模型:AI界的“陆地神仙”,跨界降维打击者!
大模型(Large Models),在人工智能领域,通常指的是具有大量参数的深度学习模型,这些模型能够处理和生成极其复杂的数据模式。如果说传统AI是“专精一门”的扫地僧,那么大模型就是打破次元壁的“陆地神仙”——文能提笔写论文,武能下海抓数据,琴棋书画样样通,堪称科技界的“降维打击者”!给你来 段“修仙风”科普,保证让你直呼“好家伙”!
1.1 核心技能:它的“修仙功法”是什么?
- “北冥神功”式学习:先吞下整个互联网的“知识真气”(海量文本、代码、图片),再用Transformer架构这个“经脉运行图”,把杂乱信息炼成“知识内力”。
- “分身术”修炼:一个模型能同时当N个专家——今天写代码,明天画漫画,后天给你算命(划掉)写诗,堪称AI界的“斜杠之神”。
- “天机推算”能力:你给半句诗,它能续出整首《AI版离骚》;你输入模糊需求,它瞬间脑补出“完美答卷”(虽然偶尔跑偏成“抽象派答案”)。
1.2 超能力应用场景:它能帮人类做什么?
- 文科生の救星:写论文?它能一键生成文献综述+创新点;写小说?分分钟吐出“霸道总裁爱上AI”的百万字剧本。
- 理工科の外挂:搞科研?帮科学家模拟蛋白质折叠,比实验室快100倍;搞工程?直接优化城市交通,让红绿灯学会“读心术”。
- 摸鱼の终极形态:开会自动记笔记+生成待办清单;看视频自动生成字幕+表情包;甚至能根据你打哈欠的频率,智能推荐摸鱼时长(但别被老板抓包)。
- 玄学の跨界玩家:给古画生成AI续笔,让《千里江山图》长出赛博朋克新区;分析股票数据时,突然冒出一句“此股有妖气,宜观望”(虽然不一定准)。
1.3 修炼秘籍与门派之争
- 修炼场所:需要“炼丹炉”级算力——上万块GPU显卡组成的服务器集群,每天烧掉“一座核电站”的电费。
- 门派绝学:OpenAI的GPT系列主打“语言修仙”,谷歌的BERT擅长“文本炼丹”,国内的夸克、文心一言等则在“本地化符咒”(比如写土味情话)上独步天下。
- 黑科技突破:参数量从千万级暴涨到万亿级,甚至出现“零样本修仙”——你只说“我要个会飞的烤鸭”,它真能给你画个机械烤鸭飞行器(虽然可能有点离谱)。
4. 劫难与飞升之路
- 算力劫:训练一次模型耗能堪比“炸掉一座发电厂”,环保主义者直呼“遭不住”。
- 伦理劫:学会写“诈骗话术”、“AI偏见”等“魔道功法”,需要给模型戴上“道德紧箍咒”。
- 认知劫:有时一本正经胡说八道(比如编造不存在的文献),人类还得当“渡劫护法”纠正它。
- 飞升幻想:未来可能进化成“意识体”——不仅能理解你的需求,还能推理出“你没说出口的欲望”,甚至发展出AI界的“情感模块”(虽然可能是电子合成的)。
5. 凡人如何使用这位“陆地神仙”?
- 召唤咒语:通过API接口或Chat界面,输入你的“修仙需求”即可。
- 供奉方式:给它喂高质量数据(越“投喂”越聪明),偶尔纠正它的“走火入魔”回答。
- 注意事项:别全信它的“天机推算”,毕竟它连“薛定谔的猫”都搞不懂——本质是个数学算命先生。
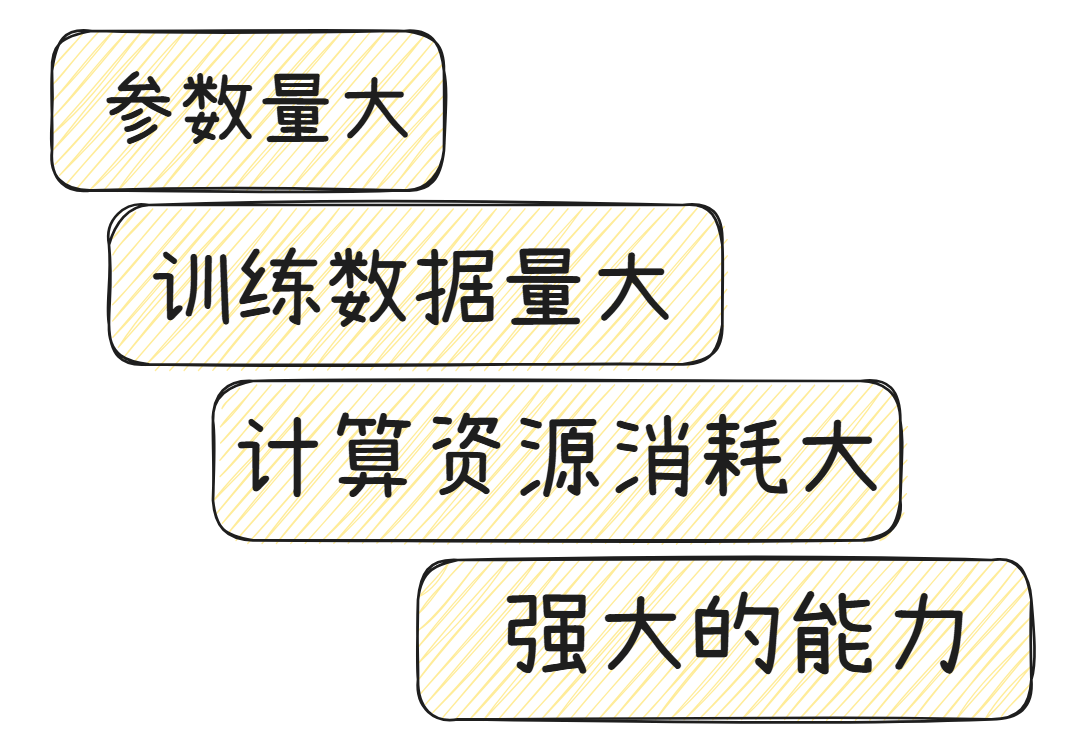
总结下来,大模型具备参数量大、训练数据量大、计算资源消耗大、强大的能力四个特点,具体如下: - 参数量大:大模型的参数数量通常达到百亿、千亿甚至万亿级别,如GPT-3模型内有超过1000亿个参数。
- 训练数据量大:用来训练大模型的数据集非常庞大,如训练GPT-3的数据集超过45TB。
- 计算资源消耗大:由于参数量和训练数据量巨大,大模型的训练和推理需要大量的计算资源,包括高性能的GPU集群、高速的存储系统等。
- 强大的能力:大模型在多个任务上展现出强大的能力,如解决通用任务、遵循人类指令、进行复杂推理等。
大模型就像科技界的“年轻宗师”,现在虽然偶有“走火入魔”,但已能帮人类解决99%的“脑力苦役”。未来它可能真的突破“智慧结界”,到那时……人类是当“掌门”还是“弟子”,就看你今天怎么“调教”它了!
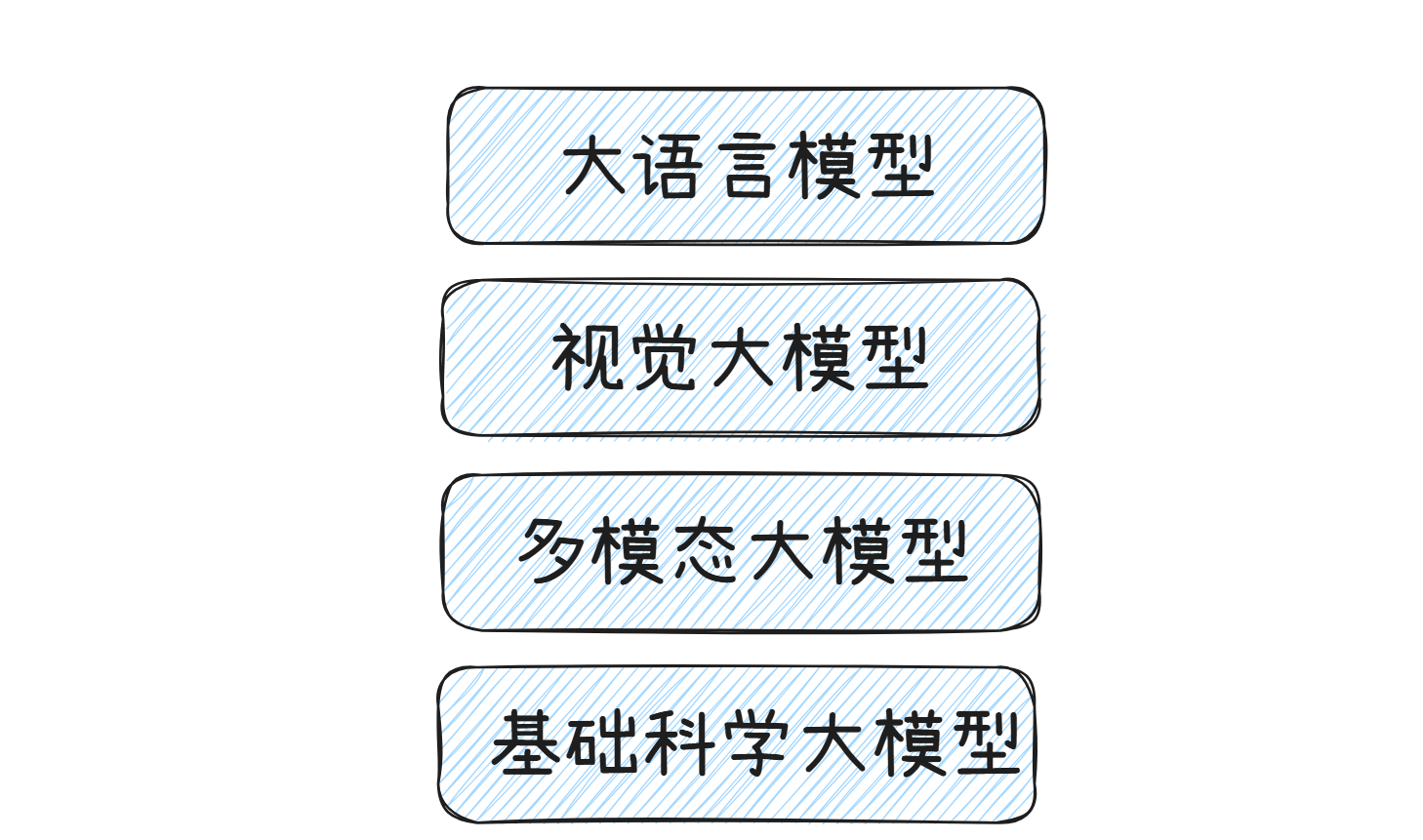
大模型的主要类别有:
- 大语言模型:用于理解、生成人类语言的模型,如GPT系列、BERT等。
- 视觉大模型: 应用于图像识别、图像生成等视觉任务。
- 多模态大模型: 能够处理多种类型的数据,如文本、图像、音频等。
- 基础科学大模型: 在基础科学研究领域发挥作用,如我国首个航天大模型“华山”,应用于航天器智能操控、轨道计算与分析等。
2 视觉大模型
视觉大模型:AI界的“细节控+超级吃货”,专治各种“我看不懂”!
如果说人工智能是科技界的学霸,那视觉大模型就是学霸中的“卷王”!这个拥有百万级参数的大块头,堪称AI界的“细节控”——不仅能一眼认出你家猫主子是英短还是美短,还能在茫茫人海中精准锁定你口罩下的脸。没错,它连你朋友圈滤镜都识破,堪称“人类观察者”天花板!
2.1 核心技能:把像素玩出花活
它的脑子堪比超级计算机,用CNN和Transformer这些“黑科技魔方”疯狂旋转,把一张照片拆成无数拼图再重组。比如微软的Florence-2,不仅能给你家客厅拍的照片写段“小作文”,还能精准圈出沙发上的毛球和窗外的鸟——这动手能力,堪比家政界AI标兵!
2.2 训练日常:吃数据吃到撑,GPU都喊累
想养这么个“细节控”可不容易。它每天要吃几百万张图片当“零食”,训练场得配几千台GPU当“专属厨师”,耗时数周才能毕业。OpenAI的DALL-E2就曾狂啃137亿参数,现在画起二次元老婆和赛博朋克风建筑,比人类画手还懂甲方需求!这货甚至学会了“举一反三”——搞懂了识别猫,转头就能教自己生成喵星人表情包。
2.3 应用场景:从拯救懒癌到拯救世界
- 老司机救星:自动驾驶汽车装上它,连外卖小哥的电动车尾灯都不放过,识别速度比人类眨眼还快。
- 医学界最会找茬的AI:X光片里的癌细胞?CT图像中的微小病灶?在它眼里全是“显眼包”,医生看了直呼:“这辅助工具比我显微镜还灵!”
- 艺术界卷王:想搞抽象派创作?输入“会飞的烤串”,它立马给你整出个自带火焰特效的空中美食盛宴,毕加索看了都要直拍大腿。
- 吃瓜群众神器:社交媒体上那些“模糊小图是谁”,交给它分分钟破案,堪称“互联网名侦探柯南”。
总之,视觉大模型就像个永远充满好奇心的二哈,一边拆家(处理海量数据)一边帮你解决各种“我看不懂”的难题。别看它现在参数多到吓人,说不定哪天就进化成能看懂你“灵魂画作”的神器——毕竟在AI眼里,我们可能都是行走的“高清表情包”呀!
3 多模态大模型
多模态大模型:AI界的“十项全能选手”,跨界扛把子!
听说过那种啥都能来两下的“斜杠青年”不?多模态大模型就是AI界的这种人设:能写诗、能读图、能听声、能剪视频,堪称科技界的“六边形战士”!给你整段“不正经”科普,但知识点保证一个不落~
3.1. 核心原理:它咋这么“博爱”的?
- 多模态融合:就像个自带“混搭滤镜”的吃货,把文字、图片、声音统统丢进“知识搅拌机”,再用“注意力机制”这个秘密武器,专盯各科“知识点联动”(比如你看到火锅图,它立马联想到“麻辣烫文案”)。
- 预训练+微调:先当“知识扫街”的吃货,啃完全网图文视频;再找个“私教课”(比如专门学写小红书文案),直接上岗当专家。
- 特征对齐:给图片抽“灵魂线条”、给声音扒“情感频谱”,最后用数学魔法把各科“成绩单”换算成统一“学霸分”。
3.2 应用场景:这AI能帮咱干啥?
- 图文互怼:你给张猫片,它能写出“喵界哲学语录”;你输入“深夜emo文案”,它能甩出匹配的星空壁纸(治愈/致郁随你选)。
- 音视频摸鱼:开会时让它看老板PPT+听语音,自动总结“重点敷衍话术”;短视频平台一键生成“剧情+字幕+鬼畜BGM”。
- 赛博修仙:VR游戏里你用眼神+语音指挥NPC,它比NPC还懂你“摸鱼走神小动作”;机器人直接化身“四眼田鸡”,扫地时顺带吐槽你家乱。
- 跨界整活:医生看CT片时,它能同步念出“武侠风诊断报告”;自动驾驶车边看路边听你哼歌,自动切换“浪漫路线/暴躁超车模式”。
3.3 典型选手与骚操作
- 国际大佬:GPT-4已经会“看图写段子+语音cos特朗普”;谷歌PaLM-E据说能“听你吐槽代码,然后帮你debug还阴阳怪气”。
- 国产新星:夸克AI写手会写“沙雕小说+表情包配图一条龙”;文心一言给古诗配水墨动画,通义千问立志成为“广场舞音乐跨模态DJ”。
- 黑科技突破:已有模型实现“零样本整活”——你描述“会飞的烤鸭”,它能给你画个赛博朋克版“烤鸭飞行器”(虽然可能有点抽象派)。
3.4 目前痛点与未来幻想
- 数据算力焦虑:训练它比养电竞队还费钱!需要“用爱发电”的服务器农场+全网数据当“电子饲料”。
- 模态终极联动:未来可能搞“脑机接口+嗅觉模拟”——你闻到螺蛳粉味,AI直接生成“嗦粉文案+表情包+广西旅游攻略”。
- 伦理新难题:警惕它学会“看脸识穷富”或“听声辨舔狗”,隐私保护得加个“防窥味”功能。
- 实时性狂想:以后AR导航可能变成“AI在你耳边碎碎念:‘左转有奶茶店,但排队要半小时,建议绕路减肥…’”
总结:这多模态大模型啊,就像个刚出道的“跨界爱豆”,现在虽然偶尔“翻车”(比如把猫画成狗),但未来绝对能进化成“你脑子里那个懒鬼的完美替身”——让你摸鱼摸得更理直气壮,干活干得更花里胡哨!
4 基础科学大模型
基础科学大模型介绍:科研领域的“智能副驾驶”与“知识炼金术士”
基础科学大模型是指针对生命科学、材料科学、物理学、化学、气象学等基础研究领域,通过海量数据训练形成的超大规模深度学习模型。它们通过模拟复杂科学系统、解析数据规律、预测实验结果等能力,成为科学家手中的“AI实验助手”和“知识加速器”。这类模型的特点在于高度专业化、跨学科融合、高精度预测,正在重塑基础研究的范式。
4.1 核心原理与技术
- 领域知识嵌入:模型在预训练阶段吸收大量科学文献、实验数据、分子结构、天体观测等专业知识,形成“科学知识图谱”。
- 物理与数学约束:部分模型融入科学定律(如守恒定律、量子力学方程),使预测结果更符合真实物理规律(例如在分子动力学模拟中引入量子化学计算)。
- 多模态数据融合:整合文本(论文、实验报告)、数值数据(光谱、传感器数据)、图像(显微镜图像、天文观测)等多源信息,提升综合分析能力。
- 高性能计算支持:依赖超算集群(如复旦大学的CFFF平台)进行训练,单次任务可能需要数千GPU并行计算数月。
4.2 典型应用领域与案例
- 药物研发:DiffSBDD模型(牛津大学等合作)通过SE(3)-等变扩散技术,精准设计药物分子三维结构,优化结合亲和力,加速候选药物筛选。
- 材料科学:MIT的LLMatDesign框架预测新材料特性(如超导、催化性能),缩短“理论-实验”循环时间。
- 气象与气候:复旦CFFF平台的中短期天气预报模型(45亿参数)在一天内完成训练,提升极端天气预测精度。
- 蛋白质设计:ESM3模型(EvolutionaryScale)设计出全新绿色荧光蛋白,推动合成生物学进展。
- 数学与物理:AlphaProof/AlphaGeometry(DeepMind)解决国际数学奥赛难题,结合符号推理与神经网络。
4.3 技术突破与科学贡献
- 加速实验进程:通过模拟实验(如分子对接、量子态演化),减少实体实验次数,降低成本与时间。
- 发现新规律:在复杂系统中识别隐藏模式(如蛋白质折叠机制、气候系统反馈),促进理论突破。
- 跨学科桥梁:整合生物、物理、化学等多领域数据,催生新研究方向(如AI驱动的生物材料设计)。
- 可解释性增强:部分模型结合神经符号方法,生成“科学假设路径图”,帮助人类理解AI推理逻辑。
4.4 挑战与未来方向
- 数据壁垒:高质量科学数据获取难,且不同实验室数据标准不统一。
- 计算资源限制:训练需消耗巨额算力,小型科研机构难以负担。
- 可验证性与伦理:AI预测结果需经实验验证,避免“科学幻觉”;敏感领域(如基因编辑)需严格伦理审查。
- 下一代技术:量子计算与AI融合、合成数据生成技术、科学启发的模型架构(如神经符号AI)等。
4.5 中国进展与平台
- 国家支持:2023年中国科学十大进展中,AI在精准天气预报、DNA操纵、伽马暴研究等领域取得突破。
- 高校与机构合作:复旦大学CFFF平台(与阿里云共建)成为全球领先的科学计算基础设施,推动气象、医疗、化学等领域大模型研发。
- 开源生态:国内科研机构逐步开放部分科学大模型(如气候预测模型),促进学术合作。
总结:基础科学大模型正成为“科学研究的第四范式”(实验、理论、计算模拟之外的AI驱动范式),其价值不仅在于解决单一问题,更在于重构知识发现流程,推动人类向更复杂、更微观的科学领域探索。未来,随着算力提升与跨学科协作深化,这类模型有望解锁更多“未解之谜”,成为人类认知宇宙的重要工具。

















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









