






前言
KAIST AI 与 KT 公司的研究人员提出了一种利用预训练和微调策略的多语言推测解码方法,通过训练专门的“草稿模型”来提高多语言环境下大型语言模型的推理效率,并实现了高达2.42倍的加速比。
论文介绍
自然语言处理 (NLP) 随着大型语言模型 (LLM) 的出现经历了快速发展,这些模型被应用于各种应用,例如文本生成、翻译和对话代理。这些模型可以以前所未有的水平处理和理解人类语言,从而实现机器与用户之间的无缝沟通。然而,尽管取得了成功,但由于所需的计算资源,在多种语言中部署这些模型带来了重大挑战。多语言环境的复杂性,包括不同的语言结构和词汇差异,进一步使 LLM 在实际应用中的高效部署变得复杂。
在多语言环境中部署 LLM 时,高推理时间是一个主要问题。推理时间是指模型根据给定输入生成响应所需的时间,并且该时间在多语言环境中会急剧增加。导致此问题的一个因素是语言之间标记化和词汇量大小的差异,这会导致编码长度的变化。例如,具有复杂语法结构或较大字符集的语言(例如日语或俄语)与英语相比,需要更多标记才能编码相同数量的信息。因此,LLM 在处理此类语言时往往表现出较慢的响应时间和更高的计算成本,因此难以在语言对之间保持一致的性能。
为了克服这些挑战,研究人员探索了各种优化 LLM 推理效率的方法。知识蒸馏和模型压缩等技术通过训练较小的模型来复制大型模型的输出,从而减小大型模型的大小。另一种有前途的技术是推测解码,它利用辅助模型(“起草器”)来生成目标 LLM 输出的初始草稿。此起草器模型可以比主 LLM 小得多,从而降低了计算成本。然而,推测解码方法通常以单语为中心进行设计,并且不能有效地推广到多语言场景,导致在应用于不同语言时性能欠佳。
来自 KAIST AI 和 KT Corporation 的研究人员引入了一种创新的多语言推测解码方法,利用了预训练和微调策略。该方法首先在通用语言建模任务上使用多语言数据集对起草器模型进行预训练。之后,针对每种特定语言对模型进行微调,以更好地与目标 LLM 的预测保持一致。此两步过程使起草器能够专注于处理每种语言的独特特征,从而产生更准确的初始草稿。研究人员通过对几种语言进行实验并评估起草器在涉及德语、法语、日语、中文和俄语的翻译任务中的性能来验证这种方法。
研究团队介绍的方法涉及一个称为草稿-验证-接受范式的三阶段过程。在初始的“草稿”阶段,起草器模型根据输入序列生成潜在的未来标记。“验证”阶段将这些起草的标记与主 LLM 做出的预测进行比较,以确保一致性。如果起草器的输出与 LLM 的预测一致,则接受标记;否则,它们将被丢弃或更正,并且重复该循环。此过程通过尽早过滤掉不正确的标记来有效地减少主 LLM 的计算负担,使其能够专注于验证和完善辅助模型提供的草稿。
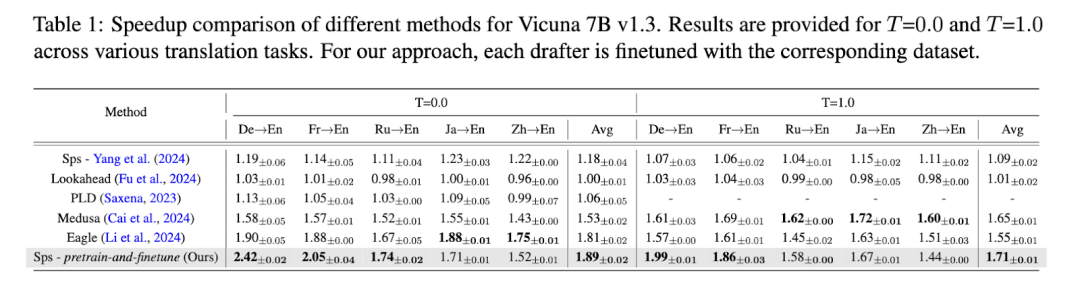
对这种方法的性能进行了全面测试,并取得了令人印象深刻的结果。研究小组观察到推理时间显着减少,与标准自回归解码方法相比,平均加速比达到 1.89 倍。在特定的多语言翻译任务中,当应用于德语-英语和法语-英语等语言对时,所提出的方法记录的加速比高达 2.42 倍。这些结果是使用 Vicuna 7B 模型作为主 LLM 获得的,而起草器模型要小得多。例如,德语起草器模型仅包含 6800 万个参数,但它成功地加速了翻译过程,而没有影响准确性。关于 GPT-4o 评判分数,研究人员报告说,在多个翻译数据集中,专门的起草器模型始终优于现有的推测解码技术。
对加速性能的进一步细分表明,专门的起草器模型在确定性设置 (T=0) 中实现了 1.19 的加速比,在更多样化的采样设置 (T=1) 中实现了 1.71 的加速比,证明了它们在不同场景下的稳健性。此外,结果表明,所提出的预训练和微调策略显着增强了起草器准确预测未来标记的能力,尤其是在多语言环境中。这一发现对于优先考虑跨语言保持性能一致性的应用程序至关重要,例如全球客户支持平台和多语言对话式 AI 系统。
该研究介绍了一种通过专门的起草器模型提高多语言应用程序中 LLM 推理效率的新策略。研究人员通过采用两步训练过程,成功地增强了起草器与主 LLM 之间的对齐,从而大大减少了推理时间。这些结果表明,起草器的目标预训练和微调比仅仅扩大模型规模更有效,从而为在不同语言环境中实际部署 LLM 树立了新的标杆。
论文下载
-
论文地址:https://arxiv.org/abs/2406.16758
-
Github地址:https://github.com/Kthyeon/Multilingual-SpecBench
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 9160
9160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









