









美国国家健康与营养调查( NHANES, National Health and Nutrition Examination Survey)是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息。
地址为:https://wwwn.cdc.gov/nchs/nhanes/Default.aspx
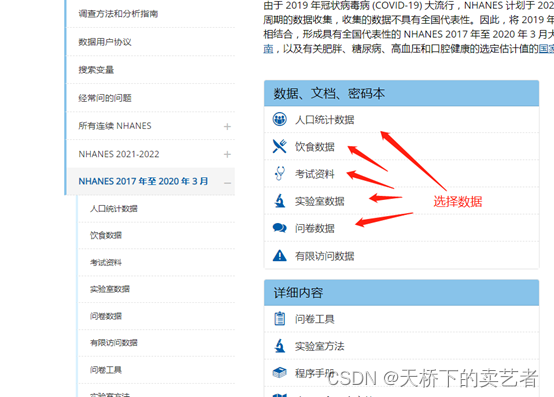
数据库有5个信息栏:DEMO:人口统计学DIET: 饮食EXAM: 检查 LAB: 实验室指标Q: 问卷调查

我以论文Zhang RH, Zhou JB, Cai YH, Shu LP, Simó R, Lecube A. Non-linear association between diabetes mellitus and pulmonary function: a population-based study. Respir Res. 2020 Nov 4;21(1):292.为参照(糖尿病与肺功能之间的非线性关联:一项基于人群的研究)为参照,

对数据进行下载,作者取的是2007-2012年的数据,我这里取的是2007-2008的数据。下载nhanes数据库有两种方法,1是直接从页面下载,2是通过R包nhanesA下载。页面下载为:
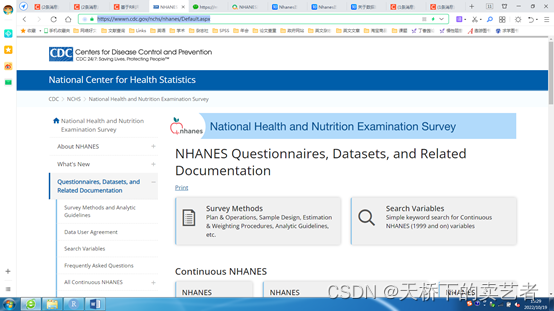
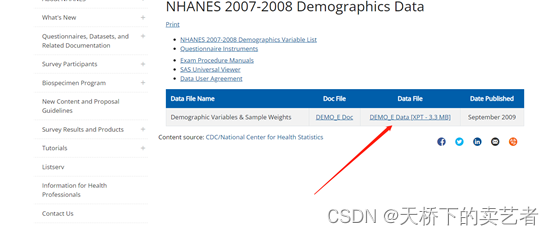
点击:Questionnaires, Datasets, and Related Documentation,再点击2007-2018
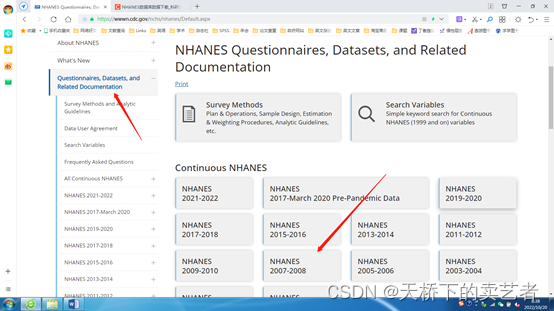
然后从右边选择需要的数据
根据文章Non-linear association between diabetes mellitus and pulmonary function: a population-based study. Respir Res. 2020 Nov 4;21(1):292.的基线资料表列出的数据
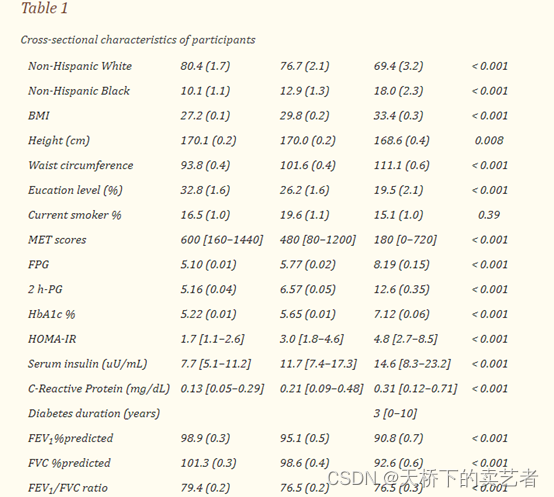
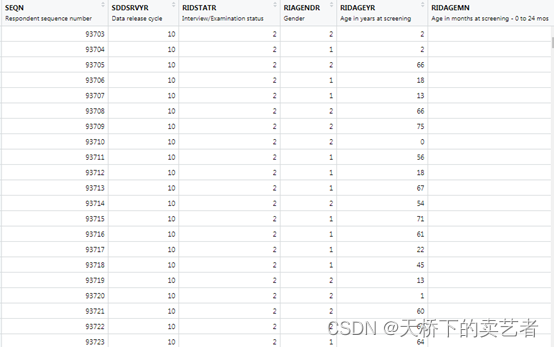
需要找到年龄、性别、种族、体重指数、血糖、FVC等相关指标,这是一个花时间的过程,需要慢慢找,先把人口统计数据下载下来看看,使用haven包的函数把数据打开
library(haven)
library(nhanesA)
library(tidyverse)
mydata <- read_xpt("e:/nhanes/DEMO_E.XPT")
使用R包下载也是一样的,要记住数据的标识
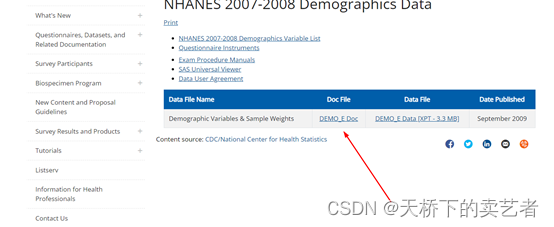
mydata1<- nhanes(‘DEMO_E’)
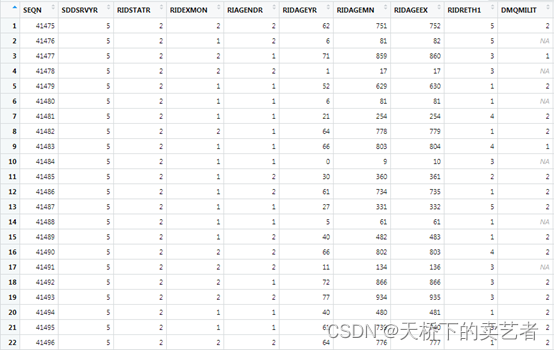
对照变量说明提取需要的变量

我做演示,随便抽取一些
dat1 <- mydata %>% select(SEQN, # 序列号
RIAGENDR, # 性别
RIDAGEYR, # 年龄
RIDRETH3, # 种族
DMDMARTL, # 婚姻状况
WTINT2YR,WTMEC2YR, # 权重
SDMVPSU, # psu
SDMVSTRA) # strata
还需要关键的血糖和肺功能的指标,血糖应该在化验室指标那里,这次我们使用nhanesA包来下载
先查看血糖文档编号:GLU_E
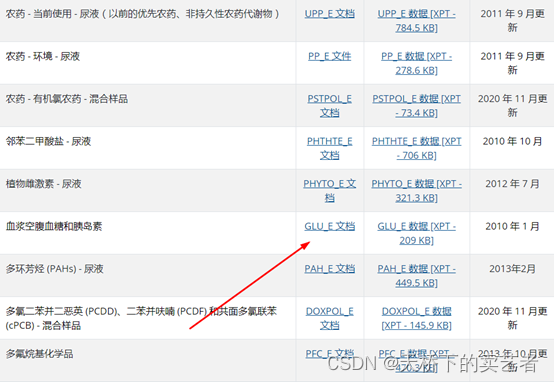
xuetang <- nhanes('GLU_E')
数据小的话还是很快的
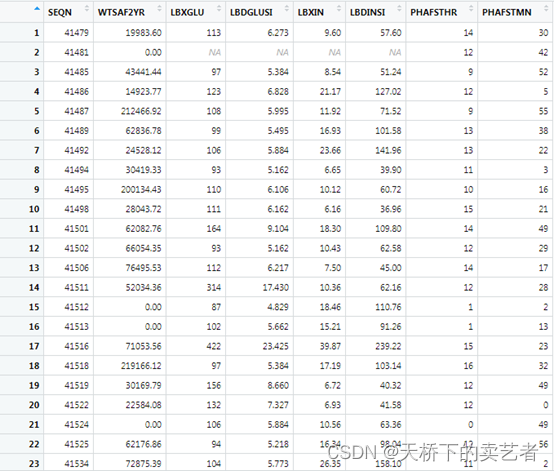
对数据进行提取,序列号都要提取,等下对数据进行合并用的
xuetang1 <- xuetang %>% select(SEQN, # 序列号
LBDGLUSI, #血糖mmol表示
LBDINSI, #胰岛素( pmmol/L)
PHAFSTHR #餐后血糖
)
同理依次取糖化血红蛋白、肺功能数据
tanghuadb <- nhanes('GHB_E')
tanghuadb1<- tanghuadb %>% select(SEQN, # 序列号
LBXGH #糖化血红蛋白
feihuoliang <- nhanes('SPXRAW_E ')
feihuoliang1<- feihuoliang %>% select(SEQN, # 序列号
SPXNFEV1, #FEV1:第一秒用力呼气量
SPXNFVC #FVC:用力肺活量,ml(估计肺容量)
)
处理好数据以后把数据合并就好了
hdata<-join_all(list(dat1, xuetang1,tanghuadb1,feihuoliang1), by = 'SEQN', type = 'full')
我们把它保存起来,今后的操作将在这个数据展开
write.csv(hdata,file = "1.csv",row.names = F)

参考文献:
- nhanes数据库使用手册
- https://blog.csdn.net/weixin_40563866/article/details/120113073?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-5-120113073-blog-121296965.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-5-120113073-blog-121296965.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=7


















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











