







CNCV 结合寒武纪的硬件架构特点,使CV 算子达到最佳性能,并减少内存占用。
20231121:修订错误,各个队列可以并行执行,队列内部是顺序执行。
文章目录
- CNCV
- CNNL库
- CNNL_Extra
- 支持算子
- 1、cnnlDetectionOutput
- 2、cnnlFuseLayerNorm
- 3、cnnlFuseNorm
- 4、cnnlProposal
- 5\cnnlRelPositionMultiHeadAttention
- 6、cnnlRoialign
- 7、cnnlRoiPool
- 8、cnnlSiamRPNPost
- 9、cnnlTransformerAttention
- 11、cnnlTransformerAttnProj
- 12、cnnlTransformerBeamRearange
- 13、cnnlTransformerBeamSearch
- 14、cnnlTransformerEmbedding
- 15、cnnlTransformerEncDecAttn算子
- 16、cnnlTransformerEncoderOutput
- 17、cnnlTransformerFcTopk
- 18、cnnlTransformerFeedForward/FFN
- 19、cnnlTransformerPositionEncoding
- 20、cnnlTransformerSelfAttention
- 21、cnnlMaskedSoftmax
- 22、cnnlWIndowAttention
- 参考文件
CNCV
软件包
1、cncv.h
2、lib so库
2、samples/cncv
台式机安装位置:/usr/local/neuware
嵌入式:sdk/board/package/inference.tar.gz
需要安装OpenCV,嵌入式也需要嵌入式的版本。
CNCV samples编译运行需依赖CNToolkit,至少需要包括 CNRT, CNDrv, CNCV(CNToolkit 2.0之后还需增加CNBin依赖),依赖目录需要用户通过NEUWARE_HOME指定,例如:export NEUWARE_HOME=xxx。
|-- ${NEUWARE_HOME}
| |-- include
| | |-- cncv.h
| | |-- cnrt.h
| | |-- ...
| |-- lib64
| | |-- libcncv.so
| | |-- libcnrt.so
| | |-- libcndrv.so
CNCV samples编译运行依赖第三方开源库opencv:
- 有可用OPENCV时,可以直接通过指定
export OPENCV_DIR=xxx指定依赖的opencv,默认需要的组织目录(aarch64架构下建议使用该种形式):
|-- ${OPENCV_DIR}
| |-- include
| | |-- opencv2
| |-- lib
| | |-- libxxx
- 如果系统中已经安装了opencv,可以通过cmake的find_package查找使用系统安装的opencv(OPENCV_DIR未指定时,默认使用该种方式)。
异构编程模型
Host端进行调度,MLU进行大规模并行计算。
Host 调用 CNRT 接口来:初始MLU,管理MLU内存,准备CNCV参数,调用CNCV接口,释放MLU资源。
CNCV 底层依赖软件栈CNRT运行时库和CNDrv驱动接口库。
基本概念
1、句柄
2、MLU工作空间
3、CPU和MLU aux辅助空间
4、BufferList
这个为专业名词,具体查阅《Cambricon-CNCV-User-Guide-CN-v2.0.0.pdf》。
编程指南
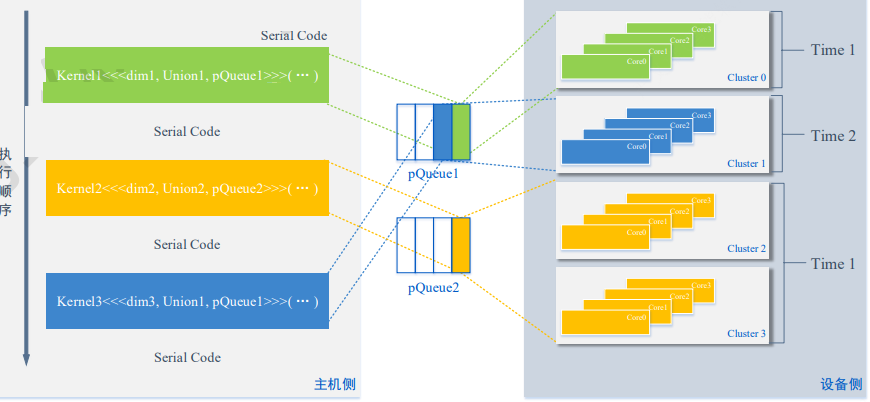
1、每个算子需要绑定句柄,用于保存当前环境的上下文,计算设备信息和队列信息。算子可以在不同队列中。
2、各个队列可以并行执行,队列内部是顺序执行。
2、部分CNCV算子需要申请内存空间workspace,需要调用相关接口申请所需的workspace,并将workspace大小传入算子接口。
3、需要使用cncvSynQueue()同步Host和MLU的队列中的任务

算子描述符
这是寒武纪的使用算子描述符来描述算子固有属性,并提供相关的接口创建、设置和销毁的描述符,简化算子接口中的参数数量
无算子描述符的简单算子

算子描述符的复杂算子

CNNL库
/EF2301-doc-0.10.0/EF2301-doc-0.10.0/doc/01-software/inference/cnnl/Cambricon-CNNL-User-Guide-CN-v1.19.1.pdf
基于CNToolKit工具包的神经网络库
头文件:cnnl.h
库:libcnnl.so libcnnl.a
位置: /uar/local/neuware/lib64
1、使用句柄handle调用MLU,句柄绑定MLU设备
2、句柄需要绑定一个队列,使CNNL 算子在队列中执行。
3、CNNL 算子可能需要 workspace 空间和extraInput空间,两者的区别是用户无需关心workspace的内存数据,也无需对内存数据进行任何操作,只需要在MLU 端申请合适大小的workspace空间;extraInput 需要用户分配和初始CPU的内存以及内存从CPU拷贝数据到MLU端。
使用算子描述符
执行下列步骤使用算子描述符

编程模型
寒武纪异构编程模型,实现不同架构和指令集的混合编程。
CNNL 算子由 Host 端发射,在MLU 端进行异步执行。
CNNL 作为网络运行库,提供人工智能计算所需的算子接口。
在框架层如Pytorch 调用 CNNL 算子接口,实现对框架层算子在MLU 的高性能加速计算。
CNNL 的算子的计算通过软件栈底层CNRT 和CNDrv 完成于MLU设备的驱动交互和计算任务。
cnnl.h 头文件,包含算子接口和数据类型申明。
单算子编程指南

多算子编程指南
多算子要实现空间复用的效果

CNNL 特性1:定点量化
用一组共享指数位的定点数来表述一组浮点数
共享指数确定了二级制小数点的位置。
将float32 量化为int8后,保证精度的前提下,存储空间减少为原来的1/4 ,IO吞吐量变为原来的4倍。
此外,使用定点数据进行卷积计算,可价款网络的训练和推理速度。
量化模式;
- 无缩放系数量化
- 有缩放系数量化
- 非对称量化
量化涉及到的参数:
- position :量化参数的定点位置
- scale:缩放系数
- offset:中心偏移
寒武纪的CNNL 支持的position 范围是[-128,127]。如果超过该范围,需要尝试使用scale 进行缩放进行解决。
无缩放系数量化
只有position,不使用scale 时,速度快,量化损失大,只要应用在量化训练场景。

import math
# 计算以 2 为底的对数
# y = math.log(10, 2)
absmax = 2047
print("原始值",absmax )
position = math.floor(math.log(absmax,2))-6
print("定点位置",position)
xx=round(1000/ math.pow(2,position))
print("量化",xx)
xxx = xx*math.pow(2,position)
print("反量化",xxx)
结果
原始值 2047
定点位置 4
量化 62
反量化 992.0
相当于把 float数进行映射到int8 里面,“误差”就是每一个量化位的间隔,这更准确的说法应该是“精度”。就像是一把尺子,最小的刻度不是毫米,而是米,因此精度就是米,所有误差很大。
有缩放量化
速度快,误差较大,主要用在一般的量化推理。

非对称量化,
计算速度慢,量化损失小。一般用于卷积的输入量化,主要原因是卷积输入经过激活后位非对称分布。

量化类
- 量化参数算子
- 量化算子
- 量化策略算子
量化参数算子:执行量化参数的计算,根据输入的浮点数和量化的位宽信息,计算量化参数 position、scale、offset。用于推理和训练。
调用cnnlQuantizeParam实现
量化算子:执行量化,根据量化位宽信息将浮点数转换为定点数。量化算子的输入是待量化的浮点数,主要用于卷积的输入,滤波、反向梯度等,输出位定点数,用于推理和训练。
调用 cnnlQuantizeV1(Host量化输入)和cnnlQuantizeV2(MLU量化输入)
量化策略算子:在自适应位宽量化过程中,更新量化位宽、量化周期和量化参数position。只用于训练场景。
量化策略算子
为减少训练过程中量化参数带来的计算消耗,自适应调整量化位宽、量化周期(下一次更新量化参数和当前更新量化参数的间隔代数)。逻辑如下:
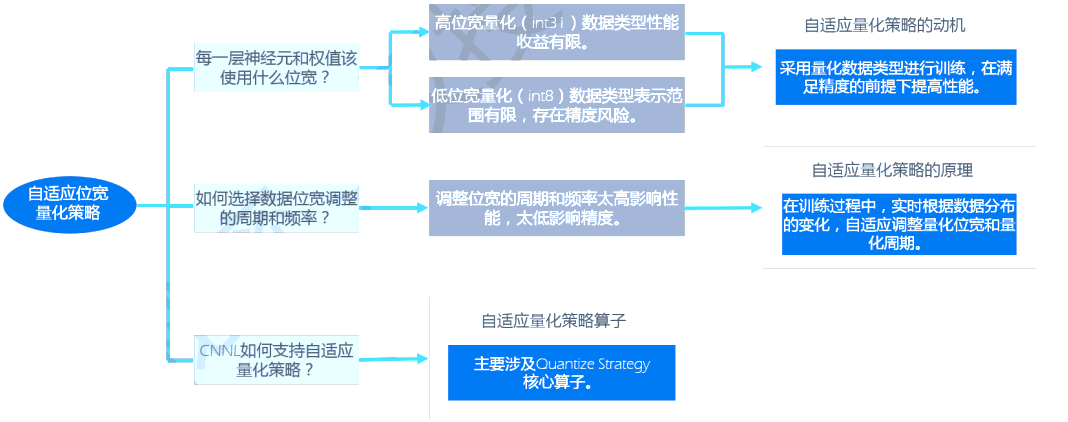
用户无需每一次迭代都计算量化参数,间隔一定迭代后进行量化参数更新,在不更新的迭代中,上一次的参数被用来量化数据。只要更细间隔合适,不会影响训练精度。因为输入数据、卷积核、反向梯度的变化相对稳定、具有一定的连续性和相似性。最简单的是固定更新周期,但是固定周期适应性较差。
定点量化输入的卷积运算
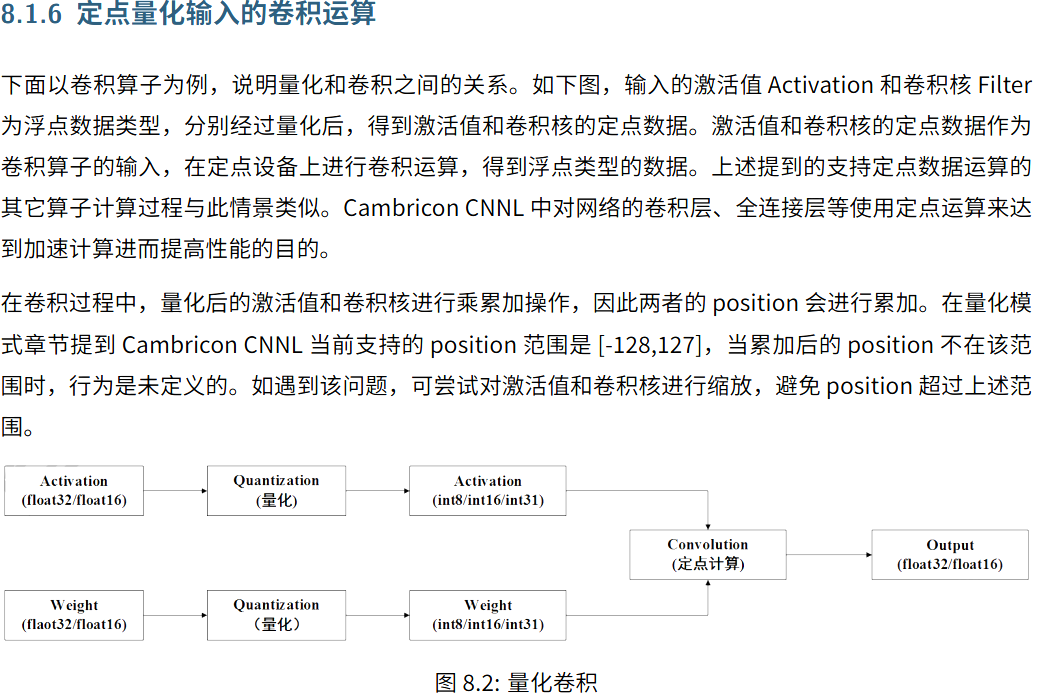
支持定点量化的算子在计算时会涉及到数据类型
- 片上onchip、
- 片下offchip数据类型
- 卷积计算类型
片下数据类型,指定Host端与MLU设备进行张量数据拷入拷出的数据类型
片上数据类型,指定张量在MLU设备上进行定点计算时所需要的数据类型。片上值支持定点型int8 int16 int31
卷积计算类型,配置卷积类算子计算过程中的临时结果的数据类型。
算子计算时,都需要设置片下数据类型,但是,当支持的定点量化算子的片上计算类型和片下数据类型不同时,需要设置片上计算类型。
设置卷积计算类型可以提高卷积计算的精度,但同时会带来一定的性能损失。目的是提升卷积计算精度。片下是half,卷积可以保存中间结果到 float32。
目前量化接口包括
- 通用接口:片上片下计算类型一致。
- 推理接口
- 量化融合接口:适用于(应该也可以支持推理吧?)训练中片下数据类型是浮点型,片上类型是定点型的场景。
通用接口

推理接口

融合接口

我感觉,在推理过程中,也会根据输入数据的不同进行量化模型吗?
根据输入的数据,计算position 、sacle、offset,这个数据不需要每次计算都更新,但是应该可以更新吧?
我们看看友商英伟达的tensrrt的两种量化

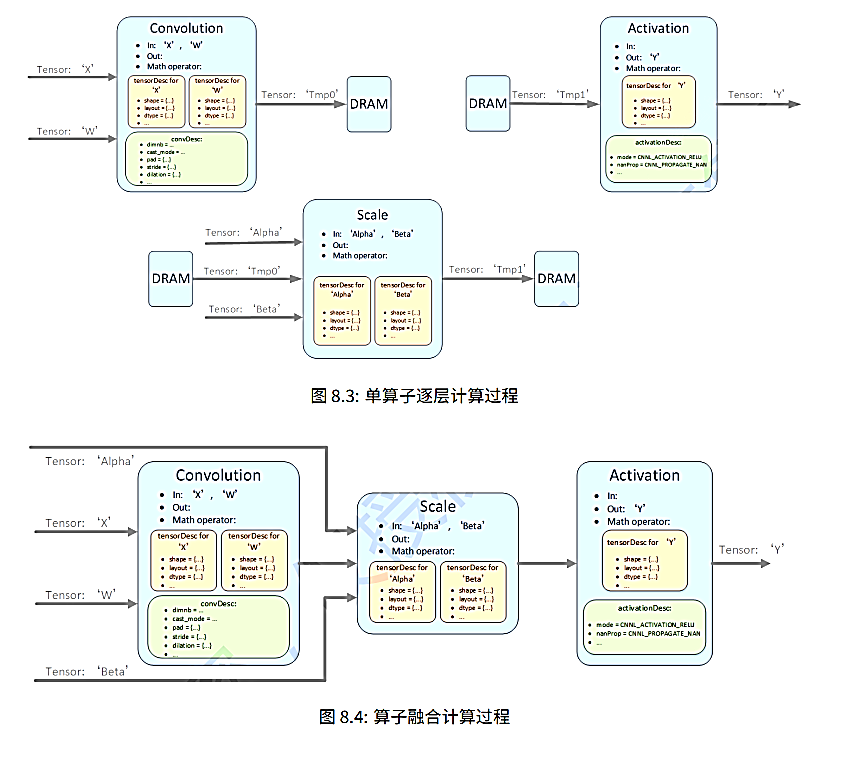
CNNL 特性2 算子融合cnnlFuseOps_t
通过将单个算子融合程复杂算子减少片上和DRAM的交互时间。
网络通常以单算子为执行单位,例如卷积convolution Forward,batchNorm算子。可以分为三个步骤
- Load 从DRAM加载数据到片上
- Computer 计算
- Store 片上存储回DRAM
算子之间的数据复用,中间结果驻留片长,作为下一个的算子的输入。

CNNL 特性3 算子数值的修约模式
CNNL 算子在MLU 执行浮点到定点时,提供了两种修约。
训练场景,两个版本的CNNL都可以用,默认Round
对于推理,用户需要指定CNNL版本。


CNNL 特性4 摆数模块
常用于 推理过程,加速MLU 的卷积类计算。
通过Host端对卷积计算的卷积核或者偏置预处理,满足MLU 计算对数据类型和布局的需要,减少MLU的开销,加速计算。
在几万次的网络循环中,每一次都需预处理就很卷积核和偏置很麻烦,这些都是已知的,可以调用一次摆数模块对卷积核和操作进行预处理,在循环调用卷积类算子时就可以减去这时间,提升效率。
当卷积核的数据类型为浮点数时或数据布局不是最佳的NHWC时,必须调用摆数模块
党偏置需要转数时,必须调用摆数模块
CNNL 特性5 API 日志与调试

打印算子接口的参数信息





MLU 问题定位

CNNL_Extra
基于CNNL,针对DNN应用场景,提供了高度优化的融合算子,同时提供了自定义算子的入口。
头文件 nccl_extra.h
库 libnccl_extra.so

支持算子
1、cnnlDetectionOutput
支持Yolov2,v3,v4,v5,FasterRcnn,ssd,retinanet,refinedet

2、cnnlFuseLayerNorm
输入的数据在计算layernorm之前,根据参数是否进行bias和residual

3、cnnlFuseNorm
对input 进行归一化

4、cnnlProposal
根据anchor 和bbox_pred 计算候选坐标,并NMS

5\cnnlRelPositionMultiHeadAttention
Conformer是Google在2020年提出的语音识别模型,基于Transformer改进而来,主要的改进点在于Transformer在提取长序列依赖的时候更有效,而卷积则擅长提取局部特征,因此将卷积应用于Transformer的Encoder层,同时提升模型在长期序列和局部特征上的效果,实际证明,该方法确实有效,在当时的LibriSpeech测试集上取得了最好的效果
多头注意力模块融合算子

6、cnnlRoialign
twostage检测网络的roialign算子,支持单一尺度和多尺度的特征图输入。
接着通过这图解释RoiAlign的工作原理
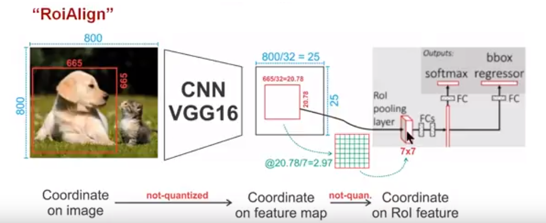
知道了RoiPooling和RoiAlign实现原理,在以后的项目中可以根据实际情况进行方案的选择;对于检测图片中大目标物体时,两种方案的差别不大,而如果是图片中有较多小目标物体需要检测,则优先选择RoiAlign,更精准些…

7、cnnlRoiPool
对RoI区域进行池化。
这个可以在Faster RCNN中使用以便使生成的候选框region proposal映射产生固定大小的feature map
先贴出一张图,接着通过这图解释RoiPooling的工作原理
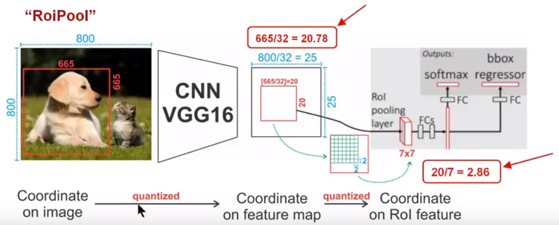
通过上面可以看出,经过两次量化,即将浮点数取整,原本在特征图上映射的20 * 20大小的region proposal,偏差成大小为7 * 7的,这样的像素偏差势必会对后层的回归定位产生影响
所以,产生了替代方案,RoiAlign
8、cnnlSiamRPNPost
Siamese的RPN网络的proposal selection 部分。根据前面的输出确定bbox的位置和分数。

9、cnnlTransformerAttention
Transformer网络的Multi-Head Attention算子。
公式如下:



11、cnnlTransformerAttnProj
Transformer 计算 attention fc 算子


12、cnnlTransformerBeamRearange
Transformer 中 对缓存Key和Value进行重排的算子

13、cnnlTransformerBeamSearch
集束搜索算法
Beam Search(集束搜索):是一种启发式图搜索算法,在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。 好处:减少了空间消耗,并提高了时间效率。 启发式搜索是利用问题拥有的启发信息来引导搜索,达到减少搜索范围、降低问题复杂度的目的
14、cnnlTransformerEmbedding
词嵌入模块算子

15、cnnlTransformerEncDecAttn算子
解码阶段注意力融合算子,
输入子注意力Self-attention以及编码后处理encoder-output算子,返回当前解码器结果。

16、cnnlTransformerEncoderOutput

17、cnnlTransformerFcTopk

18、cnnlTransformerFeedForward/FFN

19、cnnlTransformerPositionEncoding

20、cnnlTransformerSelfAttention

21、cnnlMaskedSoftmax
多头注意力的masked sofxmax计算融合算子

22、cnnlWIndowAttention

寒武纪的cnnl_extra 算子很丰富!
(正文完)
参考文件
Cambricon-CNCV-User-Guide-CN-v2.0.0.pdf
Cambricon-CNNL-User-Guide-CN-v1.19.1.pdf
Cambricon-CNNL-EXTRA-User-Guide-CN-v1.3.0.pdf


















 2893
2893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











