









深度变分高斯过程结合了 深度高斯过程(DGP) 的层次非线性建模能力和 变分推断(Variational Inference, VI) 的高效近似推断方法,是一种高效处理高维数据、复杂关系和多层非线性建模的强大工具。
模型构造
1. 层次结构
DVGP 模型由多个高斯过程(GP)层级联构成,每一层 GP 都通过其输出作为下一层的输入。这种层次结构能够捕捉复杂的非线性关系,同时对数据分布进行逐层建模。
-
第一层 GP: 输入原始数据 X,输出隐变量 h(1)。

-
中间层 GP: 每一层隐变量 h(l)作为下一层输入。
-
输出层 GP: 最后一层的隐变量 h(L) 输出最终预测值 y。
2. 变分推断
由于深度结构引入了多个隐变量,直接对后验分布进行精确推断计算复杂度极高。DVGP 使用 稀疏诱导点 和 变分分布 来近似后验:
-
稀疏诱导点:
在每一层 f(l) 中引入 M个诱导点 Z(l),从而降低矩阵运算复杂度:
-
变分下界:
使用变分下界(ELBO)最大化似然,同时优化模型参数和诱导点位置:
3. 核函数选择
DVGP 的每一层 GP 通常使用 RBF 核,可以扩展为更复杂的核以适应任务需求:
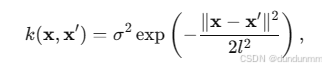
其中 σ2 是输出方差,l 是长度尺度。
实现代码
以下是 DVGP 模型的完整实现代码,并加入了结果可视化功能。
实现代码
import torch
import gpytorch
from matplotlib import pyplot as plt
# 定义单层 GP
class SingleLayerGP(gpytorch.models.ApproximateGP):
def __init__(self, inducing_points):
# 定义变分分布
variational_distribution = gpytorch.variational.CholeskyVariationalDistribution(inducing_points.size(0))
variational_strategy = gpytorch.variational.VariationalStrategy(
self, inducing_points, variational_distribution, learn_inducing_locations=True
)
super().__init__(variational_strategy)
# 定义均值和核函数
self.mean_module = gpytorch.means.ConstantMean()
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
# 构建深度 GP 模型
class DeepGPModel(torch.nn.Module):
def __init__(self, num_inducing):
super().__init__()
inducing_points = torch.linspace(0, 1, num_inducing).unsqueeze(-1)
self.layer1 = SingleLayerGP(inducing_points)
self.layer2 = SingleLayerGP(inducing_points)
self.likelihood = gpytorch.likelihoods.GaussianLikelihood()
def forward(self, x):
x = self.layer1(x).mean
return self.layer2(x)
# 生成数据
torch.manual_seed(42)
x_train = torch.linspace(0, 1, 100).unsqueeze(-1)
y_train = torch.sin(x_train * (2 * 3.14)) + torch.randn(x_train.size()) * 0.2
# 定义模型和优化器
model = DeepGPModel(num_inducing=10)
likelihood = model.likelihood
model.train()
likelihood.train()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
mll = gpytorch.mlls.VariationalELBO(likelihood, model.layer2, num_data=y_train.size(0))
# 训练模型
epochs = 500
for i in range(epochs):
optimizer.zero_grad()
output = model(x_train)
loss = -mll(output, y_train)
loss.backward()
optimizer.step()
if i % 50 == 0:
print(f"Epoch {i}/{epochs} - Loss: {loss.item()}")
print("训练完成!")
# 测试和可视化
model.eval()
likelihood.eval()
x_test = torch.linspace(0, 1, 200).unsqueeze(-1)
with torch.no_grad():
pred = likelihood(model(x_test))
mean = pred.mean
lower, upper = pred.confidence_region()
# 绘图
plt.figure(figsize=(10, 6))
plt.plot(x_train.numpy(), y_train.numpy(), 'k*', label='训练数据')
plt.plot(x_test.numpy(), mean.numpy(), 'b', label='预测均值')
plt.fill_between(x_test.numpy().squeeze(), lower.numpy(), upper.numpy(), alpha=0.3, label='置信区间')
plt.legend()
plt.title("深度变分高斯过程预测结果")
plt.xlabel("输入")
plt.ylabel("输出")
plt.show()
可视化效果
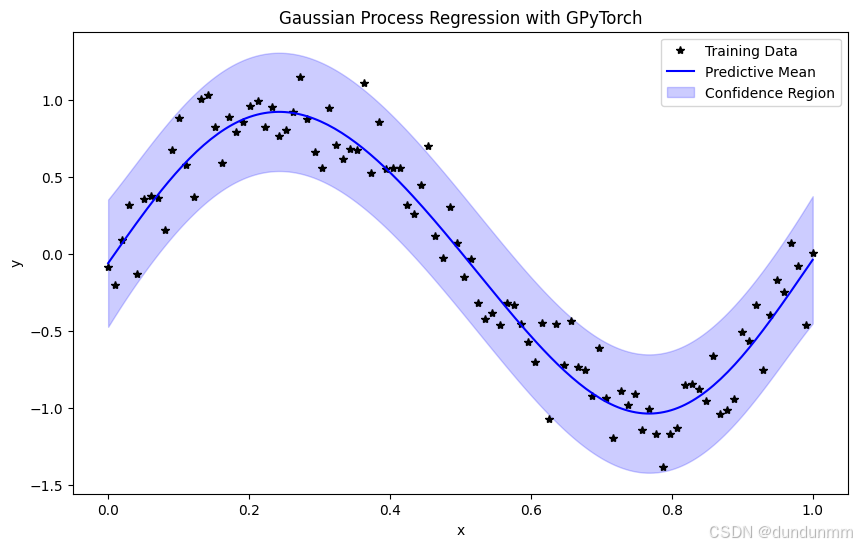
输出图说明:
- 黑色星点: 训练数据点,表示带噪声的观测值。
- 蓝色曲线: DVGP 对输入数据的预测均值。
- 浅蓝区域: DVGP 提供的预测置信区间(通常为 95%)。
通过此可视化可以观察到:
- DVGP 能够很好地捕捉输入与输出之间的非线性关系。
- 置信区间提供了对预测不确定性的量化。

















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









