







Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams
abstract
外国口音转换(FAC)的方法旨在生成听起来与给定的非母语人士相似但带有母语人士口音的语音。传统的FAC方法在合成时间期间从参考(即本地)话语借用激励信息(F0和非周期性;由传统声码器产生)。因此,生成的语音保留了母语使用者的语音质量的某些方面。我们提出了一个FAC框架,该框架消除了对传统声码器(例如,STRAIGHT,World)的需求,因此也消除了使用母语者激励的需求。
我们的方法使用在母语语音语料库上训练的声学模型来提取与说话者无关的语音后验图(PPG),然后训练语音合成器将非母语说话者的PPG映射到相应的频谱特征中,然后使用高质量的神经声码器将其转换为音频波形。在运行时,我们使用从本地引用话语中提取的PPG来驱动合成器。听力测试表明,与基线系统相比,所提出的系统产生的语音听起来更清晰、自然,与非母语者相似,同时显著降低了非母语者的外国口音。
introduction
外国口音转换旨在创建一种新的声音,该声音具有给定非母语人士的音质和母语人士的发音模式(例如,韵律、分段)。这可以通过将来自母语话语的重音相关提示与非母语说话者的语音质量相结合来实现。FAC在计算机辅助发音训练中具有潜在的应用,可以作为模仿的模型语音。
FAC中的主要挑战是将语音信号划分为与accent相关的提示和语音质量。已经提出了多种解决方案,包括语音变形、帧配对和发音合成。这些方法可以减少非母语话语的accent,但有各种局限性。语音变形通常会产生听起来像“第三个”speaker的声音,即与任何一个speaker不同的speaker。帧配对方法可以合成类似于非母语者语音的语音,但合成保留了母语者语音质量的某些方面。这是因为来自母语者的激励信息被用于合成语音。最后,发音合成需要专门的设备来收集发音数据,因此它们在现实世界中的应用并不实用。
在这项工作中,我们建议在依赖说话者的语音丰富语音嵌入中执行FAC:语音后验图(PPG)。PPG被定义为每个语音帧属于一组预定义的语音单元(音素或三音/senones)的后验概率,这些语音单元保留了话语的语言和语音信息。我们的方法如下。在第一步中,我们使用在大量母语语音语料库上训练的speaker相关声学模型为非母语speaket生成PPG。然后,我们构建了一个序列到序列的语音合成器,它可以捕捉非母语说话者的语音质量。合成器将来自非母语speaker的PPG序列作为输入,并产生相应的mel频谱图序列作为输出。最后,我们训练一个神经声码器WaveGlow,将融合频谱图转换为原始语音信号。在测试过程中,我们向合成器提供来自本地话语的PPG序列。结果输出包含母语使用者的发音模式和非母语使用者的语音质量。拟议系统的总体工作流程如图1所示。
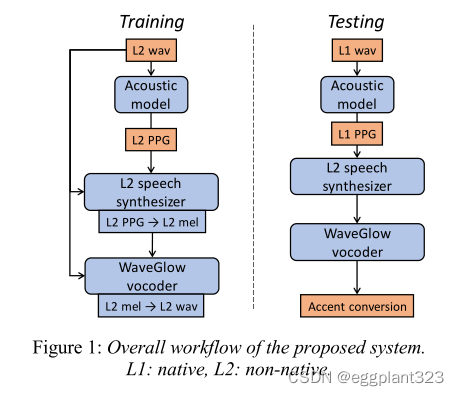
所提出的系统有三个优点。
- 首先,它消除了从本地参考语音借用激励信息的需要,这防止了本地说话者的语音质量方面泄漏到合成语音中。
- 其次,我们的系统不需要来自母语参考说话者的任何训练数据。因此,我们可以灵活地在测试期间使用任何参考声音。
- 第三,我们的系统通过序列到序列模型捕获上下文信息,该模型在多个任务上显示出最先进的性能,有助于产生更好的音频质量。
related work
口音转换的早期尝试使用语音变形,通过混合母语和非母语使用者的频谱成分来控制口音的程度。在中,作者使用PSOLA来修改重音语音的持续时间和音高模式。Aryal和Gutierrez-Osuna采用了语音转换(VC)技术,用一种基于声道长度归一化后的MFCC相似性匹配源帧和目标帧的技术取代了动态时间扭曲(DTW)。后来,赵等人使用PPG相似度代替MFCC相似度对声学帧进行配对。
PPG已应用于许多任务,例如,基于神经网络的语音识别、口语术语检测、发音错误检测和个性化TTS。PPG最近也引起了VC的广泛关注。Xie等人将目标说话者的PPG划分为簇,然后将源说话者的PPGs映射到目标说话者的最近簇。Sun等人使用PPG进行多对一语音转换。Miyoshi等人扩展了基于PPG的VC框架,包括使用LSTM的源和目标PPG之间的映射;他们获得了比不包括PPG映射过程的基线更好的语音个性评级,但音频质量更差。张等人将来自源扬声器的瓶颈特征和融合频谱图连接起来,然后使用序列到序列模型将源融合频谱图转换为目标扬声器的融合频谱图,最后使用WaveNet声码器恢复语音波形。他们的模型需要并行录音,并且需要为每对扬声器训练一个新的模型。然后,他们应用文本监督来解决转换语音中的一些发音错误和伪像。最近,周等人采用双语PPG进行跨语言语音转换。
method
我们的系统由三个主要组成部分组成;提取PPG的扬声器无关声学模型(AM),将PPG转换为mel声谱图的非母语扬声器的语音合成器,以及实时从mel声纹图生成语音波形的WaveGlow声码器。
acoustic modeling and PPG extraction
我们使用具有多个隐藏层的DNN p-范数非线性作为AM。我们通过最小化从预训练的GMM-HMM强制对准器获得的输出和senone标签之间的交叉熵,在本地语音语料库上训练AM。母语语音训练对我们的任务至关重要,因为母语和非母语框架必须在母语语音空间中匹配。有关AM的更多详细信息,请参阅。
PPG-to-Mel-spectrogram conversion
我们使用改进的Tacotron 2模型将非母语使用者的PPG转换为其相应的mel声谱图。原始的Tacotron 2模型采用字符的one shot vector表示,并将其传递给编码器LSTM,后者将其转换为隐藏表示,然后将其传递到具有位置敏感注意力机制的解码器LSTM,该解码器LSTM预测mel声谱图。为了提高模型性能,字符嵌入在被馈送到编码器LSTM之前通过多个卷积层。
解码器在将预测的mel谱图传递给注意力和解码器LSTM之前附加PreNet(两个完全连接的层)以提取结构信息。它还在解码器之后应用PostNet(多个一维卷积层)来预测频谱细节,并将其添加到原始预测中。
在这项工作中,我们用PPG嵌入网络(PPG-PreNet)代替了字符嵌入层,该网络包含两个具有ReLU非线性的完全连接的隐藏层。该PPG嵌入网络类似于Tacotron 2中的PreNet,并将原始高维输入PPG转换为低维BNF。这一步骤对于模型的收敛至关重要。PPG到Mel的转换模型如图2所示。
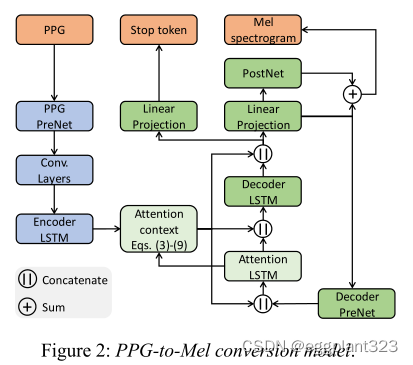
最初的Tacotron 2是为了接受字符序列作为输入而设计的,这些字符序列比我们的PPG序列短得多。例如,我们的语音语料库中的每个句子平均包含41个字符,而PPG序列有几百个帧。因此,如所指出的,原始的Tacotron 2注意力机制会被如此长的输入序列混淆,并导致PPG和声学序列之间的错位。因此,推理将是有错的,并将产生不可理解的语音。这个问题的一个解决方案是用较短的PPG序列训练PPG-to-Mel模型。例如,可以使用分词而不是句子。
然而,这个解决方案有几个问题。
- 首先,为了获得准确的单词边界,我们需要对训练句子进行强制对齐,这需要访问转录。
- 第二,也是更重要的一点,如[33]所述,用短片段进行训练和用较长的输入序列进行推理会导致模型失败。
我们通过在注意力机制中添加局部性约束来解决这个问题。语音信号具有很强的时间连续性和渐进性。为了捕捉语音上下文,我们只需要在一个小的本地窗口中查看PPG。受此启发,在训练期间的每个解码步骤,我们将注意力机制约束为查看隐藏状态序列中的窗口,而不是完整序列。
我们对这个约束条件的正式定义如下。允许di是解码器LSTM在时间步长i的输出, yi 是预测的声学特征(运用linear projection的输出在di上), 和ℎ = [ℎ1,ℎT ] 是来自编码器的隐藏状态的完整序列。应用位置敏感注意机制,
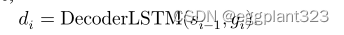
S(i-1)是LSTM在时间(i-1)上的步长,gi是注意力上下文
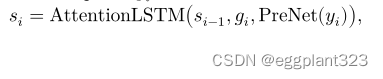

现在,为了实施局部性约束,我们只考虑以当前帧为中心的固定窗口内的隐藏表示,即

mel-spectrogram to speech
我们使用WaveGlow声码器将语音合成器的输出转换回语音波形。WaveGlow是一种基于流的网络,能够从mel声谱图生成高质量语音(与WaveNet相当)。它从零均值球面高斯(带方差휎) 具有与期望输出相同数量的维度,并使这些样本通过将简单分布转换为具有期望分布的层的一系列层。在训练声码器的情况下,我们使用WaveGlow对以mel频谱图为条件的音频样本的分布进行建模。WaveGlow仅使用单个神经网络就可以实现实时推理速度,而WaveNet由于其自回归性质,合成话语需要很长时间。有关WaveGlow声码器的更多详细信息,请读者参阅[14]。
experiments and results
experimental setup
我们使用Librispeech语料库来训练AM。它包含960小时的英语母语,其中大部分来自北美。AM有五个隐藏层和一个带有5816个传感器的输出层。我们在公开的L2-ARCTIC语料库中的两个非母语者YKWK(母语为韩语的男性)和ZHAA(母语为阿拉伯语的女性)上训练了PPG-to-Mel和WaveGlow模型。
我们使用Audacity对原始L2-ARCTIC录音进行降噪处理,以去除环境背景噪声。对于母语参考语,我们使用了来自ARCTIC语料库的两个北美说话者BDL(M)和CLB(F)。L2-ARCTIC和ARCTIC中的每个演讲者都记录了相同的1132句话,即大约一个小时的演讲。对于每个L2-ARCTIC说话者,我们使用前1032个句子进行模型训练,接下来的50个句子进行验证,剩下的50个语句进行测试。所有音频信号都以16KHz采样。我们使用80个滤波器组来提取具有10ms偏移和64ms窗口的mel光谱图。PPG也以10ms的偏移被提取。
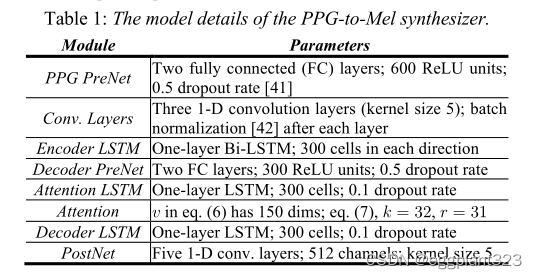
PPG到Mel模型参数总结在表1中。我们使用的批量大小为6,学习率为1×10−4。α,β,γ根据经验分别设置为1.0、1.0和0.005。窗口大小w注意机制的局部约束的值被设置为20。我们训练模型,直到验证损失达到平稳期(~8h)。对于WaveGlow模型,我们设置σ如所建议的,训练期间为0.701,测试期间为0.6。批量大小为3,学习率为1×10−4。对模型进行训练,直到收敛(约一天)。所有模型都是在单个Nvidia GTX 1070 GPU上进行训练的。
AM使用Kaldi进行训练,其他模型在PyTorch中实现,并使用Adam优化器进行训练。有关更多详细信息和音频样本,请参阅https://github.com/guanlongzhao/fac-via-ppg.
我们将我们提出的系统与中的基线进行了比较,其工作原理如下。首先,我们计算了每个native帧和non-native帧的PPG。然后,我们使用PPG空间中的对称KL散度来配对最接近的native帧和non-native帧。在最后一步中,我们从帧对中提取梅尔倒谱系数(MCEP),以训练联合密度GMM(JD-GMM)频谱转换,如[39]所述。然后,我们使用JD-GMM转换本地MCEP,以匹配non-native说话者的语音质量。最后,我们使用STRIGHT声码器从转换后的MCEP中合成语音,并结合母语使用者的非周期性(AP)和F0(标准化为非母语使用者的音高范围)。我们对基线系统使用了相同的1032话语训练集。GMM包含128个混合和全协方差矩阵。我们使用了24dim MCEP(不包括MCEP0)和Δ特征。所有特征都是通过STRAIGHT以10ms的偏移和25ms的窗口提取的。对于每个系统,我们为speaker对BDL-YKWK和CLB-ZHAA生成AC。
results
我们进行了三项听力测试来比较系统的性能:音频质量和自然度的平均意见得分(MOS)测试、语音相似性测试和重音测试。所有实验都是在亚马逊机械土耳其人上进行的,所有参与者都居住在美国。对于每个测试,每个系统的每个扬声器对(总共50个)随机选择25个话语。在所有实验中,样本的呈现顺序是随机的。
MOS测试以五分制对音频样本的音频质量和自然度进行了评级(1分制、2分制、3分制、4分制、5分制)。音频质量和自然度MOS分别描述了演讲的清晰程度和人性化程度。这两项测量是从不重叠的听众群体中获得的,以避免偏见。每个音频样本至少获得17个评级。听众还将同一套ARCTIC和L2-ARCTIC的原始录音作为参考。结果汇总在表2和表3中。应该注意的是,在[9]中,我们确定基线系统的音频质量MOS比使用DTW进行帧配对的传统JD-GMM系统高约0.4。因此,我们的基线是一个比传统的JD-GMM更强的系统。
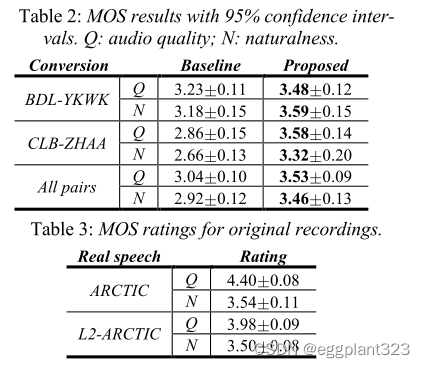
在所有情况下,我们的系统在音频质量和自然度方面都显著优于基线。尽管这两个系统的音频质量MOS低于原始录音,但所提出的系统与ARCTIC之间没有显著差异(p = 0.35)或L2ARCTIC(p = 0.54)自然度MOS上的记录。
在语音相似性测试中,听众被提供了三个话语,即原始的非母语话语和来自这两个系统的合成,并被要求选择这两个合成中哪一个听起来更像非母语者。
参与者还被要求在做出选择时用7分制(1分完全不自信,7分极度自信)对自己的信心水平进行评分。参与者被要求在执行任务时忽略口音。在每次试验中,来自两个系统的样本的呈现顺序是反向平衡的,17名参与者对音频样本进行了评分。结果如表4所示。在72.47%的情况下,听众更喜欢具有3.4置信水平(高于“有点自信”)的拟议系统,而在其余27.53%的情况中,听众选择了置信水平低得多的基线(1.05,或“完全不自信”)

在重音测试中,参与者被要求用发音文献中常用的九分制(1-没有外国口音,9-非常强的外国口音)对外国口音的程度进行评分[43]。每个音频样本由18个人进行评分。结果汇总在表5中。ARCTIC说话者的原始话语被评为“无外国口音”(1.20),而L2-ARCTIC说话者中的原始话语则被评为重重音(7.17)。与L2ARCTIC语音相比,基线(2.94)和提出的(3.93)系统都显著降低了外国口音,但被评为比本地语音更重音。令人惊讶的是,从我们的系统生成的语音被评为比基线系统更重音;有关这一结果的潜在解释,请参阅讨论部分。

discussion and conclusion
所提出的重音转换系统产生的语音质量比基线系统更好,因为它使用最先进的序列到序列模型(改进的Tacotron 2)将PPG转换为mel声谱图,然后使用神经声码器直接从mel声纹图生成音频。该过程利用了语音信号的时间依赖性,避免了使用通常会降低合成质量的基于传统信号处理的声码器。我们还提出了一种易于实现的注意力机制的局部约束,以使PPG-to-Mel模型可在话语级样本上进行训练。请注意,我们的MOS评级低于原始Tacotron 2和WaveGlow论文中的评级,这主要是因为他们的系统是用24倍以上的数据训练的。提高所提出系统的MOS评级的一个未来方向是联合训练PPG到Mel和WaveGlow模型。
与从母语使用者借用激励信息(F0,AP)的基线相比,我们的系统直接从合成的mel声谱图中生成非母语使用者的激励。这防止了母语使用者的语音质量“泄漏”到合成中,使其与非母语使用者的声音质量更相似。
我们的系统从原生PPG序列中提取原生发音模式,因此使合成语音的重音明显低于非原生语音。与基线系统相比,重音评分略有上升可能是两个因素造成的。首先,AM在提取PPG时不可避免地产生识别错误,并且这些错误将在合成中反映为发音错误。其次,所提出的模型没有明确地对重音和语调模式进行建模;因此,我们发现一些合成结果具有出乎意料的语调。因此,在未来的工作中,我们计划将语调信息纳入建模过程;一种可能的解决方案是在训练和测试PPG-to-Mel模型时,在归一化的F0轮廓上调节PPG序列。
目前,PPG到Mel和WaveGlow模型需要非母语人士至少一小时的演讲时间。这一要求可以通过遵循多说话者TTS的迁移学习范式来放宽。重音转换的最终目标是消除在合成时对参考话语的需求,即采用非母语话语并自动减少其重音。这可以通过学习从非母语说话者的PPG序列到母语PPG序列的序列到序列映射,然后用这个重音减少的PPG顺序驱动PPG-to-Mel合成器来实现。















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









