







文章目录
- 前言
- 基本思想
- 一 姿态估计
- 二 姿态估算与滤波的关系
- 三 贝叶斯滤波-核心内容(by忠厚老实的老王)
-
- 3.0 贝叶斯公式:核心思想是通过先验概率和似然概率计算得到的后验概率的方差比前两者更小(方差小意味着误差小)
- 3.1 条件概率
- 3.2 全概率公式与贝叶斯公式
- 3.3 贝叶斯公式的简单运用例子
- 3.4 贝叶斯滤波的三大概率
- 3.5 离散随机变量的贝叶斯滤波
- 3.6 连续随机变量的贝叶斯公式
- 3.7 似然概率与狄拉克函数
- 3.8 随机过程的贝叶斯滤波-重要
-
- 3.8.1 随机过程存在的难点
- 3.8.2 多次迭代中,变量的先验概率的给定
- 3.8.3 贝叶斯滤波使用[状态方程-观测方程]这样的方式来做递推
- 3.8.4 贝叶斯滤波的递推
- 3.8.4.1 错误的递推示例:无观测情况下的递推
- 3.8.4.2 正确的递推讲解
- 3.8.5 贝叶斯滤波的递推的具体做法
- 3.8.5.1 问题的建模
- 3.8.5.2 预测步推导(求先验):求概率密度函数
- 3.8.5.3 更新步推导(求后验): 概率密度函数
- 3.8.5.4 根据后验概率计算状态: ^ \hat{} ^xk
- 3.8.5.5 贝叶斯滤波算法流程
- 3.8.5.6 推导的三条核心结果公式---记起来
- 3.8.5.7 贝叶斯滤波算法优缺点
- 3.8.5.8一些注解
- 四 贝叶斯滤波和其他滤波的关系
- 五 卡尔曼滤波
- 六 扩展卡尔曼滤波
- 七 无痕卡尔曼滤波
- 八 粒子滤波
- madgick的姿态估算分析
- 流形上的卡尔曼滤波
- 不变卡尔曼滤波
- 自动驾驶方面的滤波建议-by忠厚老实的老王
前言
本文章将汇总我这么长时间来,使用IMU进行姿态估计的总结,所以会很多内容,并且不能够一次性完成。我会分成很多次,一步步介绍下去。
目前的计划是,从零开始介绍姿态估算,然后进一步介绍姿态估算与滤波的关系,然后介绍各个我知道的进阶算法。
本文将采用状态估计,而不是姿态估计。因为姿态估计的范围比较狭小,是状态估计中的一部分,后续可能会介绍状态估计中的位置,速度等估计。
基本思想
状态估计=计算公式+数据
- 首先,我们需要知道的是,给你一些传感器的数据,我们怎么根据这些数据来计算得到姿态?这个就是计算公式的作用。
- 有了公式以后,我们需要更好的数据来进行更精准的估计,所以,我们需要滤波。
一 姿态估计
几乎所有姿态估计的资料都是大篇幅的介绍滤波什么的,不讲姿态估计和滤波有什么鬼关系。
原因是因为,对于各种姿态估计的计算方法来说,一旦原理确定了,姿态估计的计算公式是比较固定的,所以重心就变成了怎么去获取更精切的数据。
在实际运用中的开发也是如此,可能姿态估计计算一行代码就完了,剩下的代码都是进行滤波的。
这部分主要是记录一些姿态估计的计算方法的。
1.1 通过6轴IMU来进行姿态估计的入门级方法
下面的方法只需要简单的三角函数以及反三角函数就可以进行姿态估计:
看本文尾部参考资料[1]。
我在geek-workshop看到Malc发了翻译过的文章,见[2]
1.1.1 通过加速度计计算姿态
该公式的原理是通过计算重力在各个方向上的分量,通过反三角函数就可以计算得到姿态:Racc=[Axr,Ayr,Azr]
Axr = arccos(Rx/R)
Ayr = arccos(Ry/R)
Azr = arccos(Rz/R)
1.1.2 引入陀螺仪来得到更好的姿态估计
加速度计已经告诉我们Axr,Ayr,Azr的倾角,为什么还要费事去得到陀螺仪的数据?答案很简单:加速度计的数据不是100%准确的。有几个原因,还记加速度计测量的是惯性力,这个力可以由重力引起(理想情况只受重力影响),当也可能由设备的加速度(运动)引起。因此,就算加速度计处于一个相对比较平稳的状态,它对一般的震动和机械噪声很敏感。这就是为什么大部分的IMU系统都需要陀螺仪来使加速度计的输出更平滑。但是怎么办到这点呢?陀螺仪不受噪声影响吗?
陀螺仪也会有噪声,但由于它检测的是旋转,因此对线性机械运动没那么敏感,不过陀螺仪有另外一种问题,比如漂移(当选择停止的时候电压不会回到零速率电压)。然而,通过计算加速度计和陀螺仪的平均值我们能得到一个相对更准确的当前设备的倾角值,这比单独使用加速度计更好。
You might be asking yourself by this point, if accelerometer model already gave us inclination angles of Axr,Ayr,Azr why would we want to bother with the gyroscope data ? The answer is simple: accelerometer data can’t always be trusted 100%. There are several reason, remember that accelerometer measures inertial force, such a force can be caused by gravitation (and ideally only by gravitation), but it might also be caused by acceleration (movement) of the device. As a result even if accelerometer is in a relatively stable state, it is still very sensitive to vibration and mechanical noise in general. This is the main reason why most IMU systems use a gyroscope to smooth out any accelerometer errors. But how is this done ? And is the gyroscope free from noise ?
The gyroscope is not free from noise however because it measures rotation it is less sensitive to linear mechanical movements, the type of noise that accelerometer suffers from, however gyroscopes have other types of problems like for example drift (not coming back to zero-rate value when rotation stops). Nevertheless by averaging data that comes from accelerometer and gyroscope we can obtain a relatively better estimate of current device inclination than we would obtain by using the accelerometer data alone.
使用陀螺仪的方法:陀螺仪估计姿态=使用估计姿态+陀螺仪测得的角速度*dt
对于陀螺仪来说,它衡量的是角速度,理论上如果我们将角速度进行积分,可以得到姿态,但因为精度,误差以及计算的问题,实际上这样子做得到的结果是十分差的。
但是,我们认为,陀螺仪长时间累积下来的结果,是跟我们估计的姿态接近的,与其进行积分计算,我们用估计的姿态作为陀螺仪累积的结果更好。
因此,我们在预测的姿态基础上,加上角速度乘以时间的变化,从陀螺仪中得到了一个新的姿态:Rgyro=[RxGyro ,RzGyro,RzGyro]
RxGyro = RxEst(n-1)+Rotx*T
RyGyro = RyEst(n-1)+Roty*T
RzGyro = RyEst(n-1)+Rotz*T
这样,我们引入了陀螺仪的测量数据,如果加速度计的数据有巨大误差,通过陀螺仪的数据,可以将估计的误差降低。
上面的公式只是演示,具体的实现涉及从估计的姿态中反算出RxEst等,看[1],[2]
现在我们有了两个姿态,怎么做呢?加权组合得到新姿态
Rest(n) = (Racc * w1 + Rgyro * w2 ) / (w1 + w2)
1.2 四元数解算姿态角解析
可以参考著名的《An efficient orientation filter for inertial and inertial/magnetic sensor arrays》
二 姿态估算与滤波的关系
2.1 状态方程和观测方程

2.2 数据和滤波的关系
我们计算姿态的公式是理想的,只要数据足够准确,计算出来的结果就很好。
但是现实是,只要有测量,就会有误差。
误差包括仪器本身自带的偏差,外部环境的影响,计算的精度损失等等。
怎么获取更精确的数据,是个十分难的问题。
获取更精确的数据,这是滤波的目的,滤波的作用是让数据遵循的分布的误差变小
记 x是我们感兴趣的数据,x遵循某种分布f(N,delta),delta是指分布的方差
通过滤波来获得更精准的数据的步骤:
- 使用滤波算法对数据的分布f(N,delta)(记住,是数据的分布,不是数据),使其方差越来越小(方差变小,则误差变小)
- 方差变小之后,我们就可以根据分布来计算数据的值,比如说像下面的求均值方法:
如果是高斯分布,则可以从分布中获取。
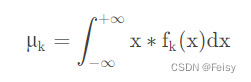
滤波和状态数据的关系:真实的数据的分布是隐藏的,状态方程和观测方程都只是状态数据的来源,我们根据这两种类型的数据,通过滤波,可以计算得到数据的分布,然后通过迭代,让这个分布的方差(即误差)越来越小,从而越来越精准。

记住,将状态方程和观测方程都看成只是带了信息的数据来源,两者都不是最佳的数据。
三 贝叶斯滤波-核心内容(by忠厚老实的老王)
3.0 贝叶斯公式:核心思想是通过先验概率和似然概率计算得到的后验概率的方差比前两者更小(方差小意味着误差小)
https://www.bilibili.com/video/BV1Yq4y1E7BU/?spm_id_from=333.788.recommend_more_video.6
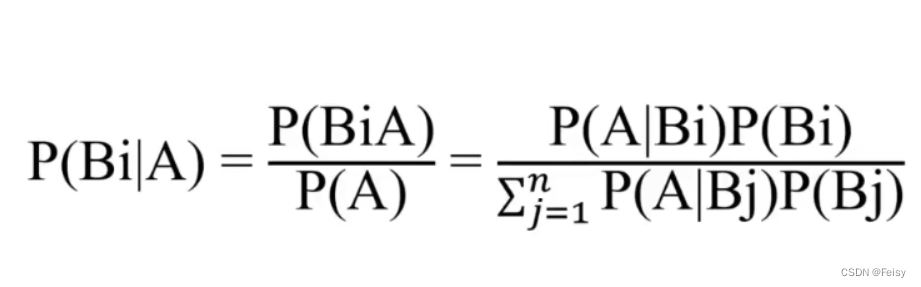
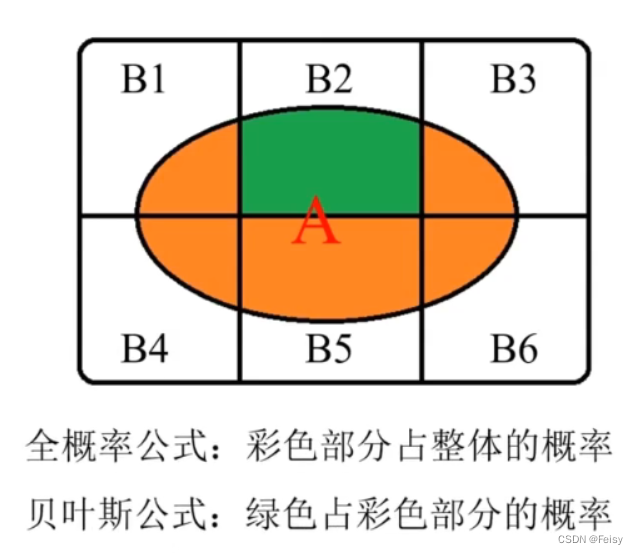
贝叶斯率滤波的思想:新信息出现后的B的概率=B概率 * 新信息带来的调整
至于为什么 A 事件发生后导致的调整为P(A|B)/P(A),这就需要代数了,推导也不复杂.(没有找到推导过程,暂且默认它是对的)
3.1 条件概率
3.1.1 条件概率的定义

这里跟我们理解的有点不一样,我们一般认为,条件的意思是加上了限制,概率会变得更小。
但经常条件概率下反而经常增大。
原因是,样本空间发生了变化。没有条件时总样本空间是S,有条件时样本空间是A。很好
帮助理解的例子是后面的例子1。
3.1.2 条件概率的图示讲解
图示一
S是样本空间
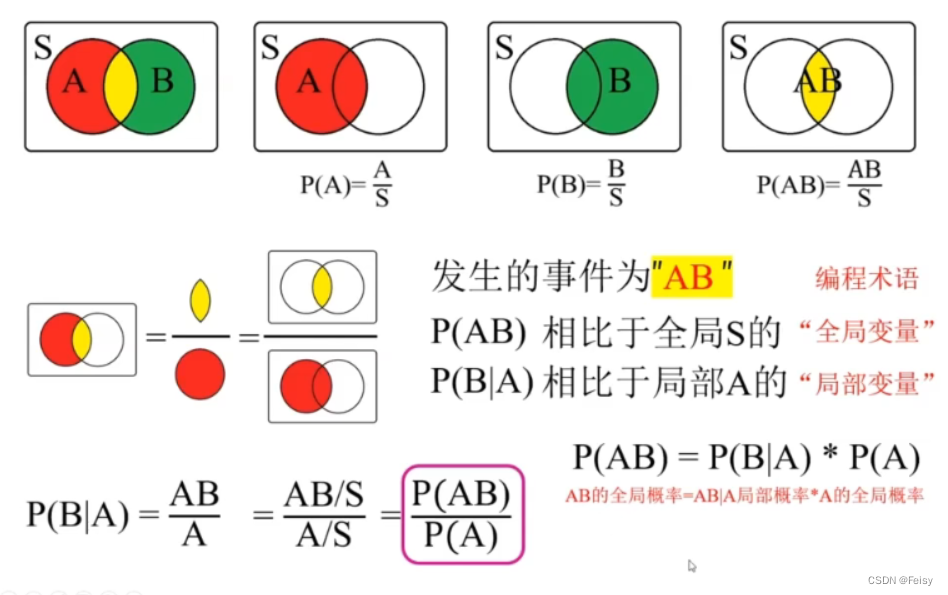
在条件概率下,样本空间发生变化了,不能在原来的S上讨论,要在A的基础上进行讨论
3.1.3 条件概率的例子
例子一
1 背景
一个女孩子去参加相亲,有100个男嘉宾供她选择。你也是其中一个。假设每个人被选中的
概率是相同的。而女孩没有任何条件,则你被选中的概率为1/100
2 条件概率的情况
如果女孩加上身高180,有房有车,工作在北上广,则只有5个人符合条件,你是其中之一。
则你被选中的概率是1/5.
加上条件概率以后,需要关注的范围从100,减到5,大大缩小了范围,更有助于做判断.
3.2 全概率公式与贝叶斯公式
3.2.1 全概率公式
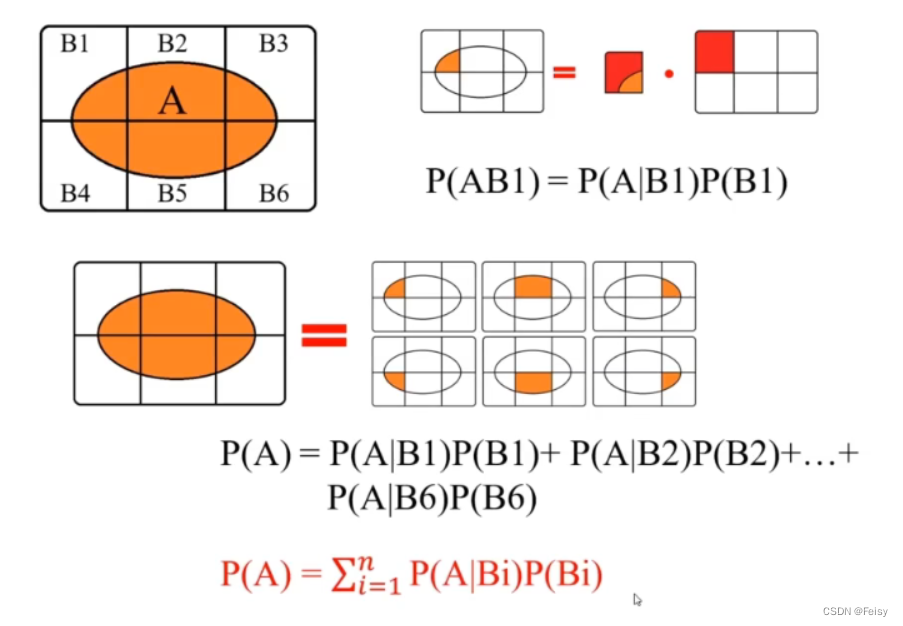
3.2.2 贝叶斯公式
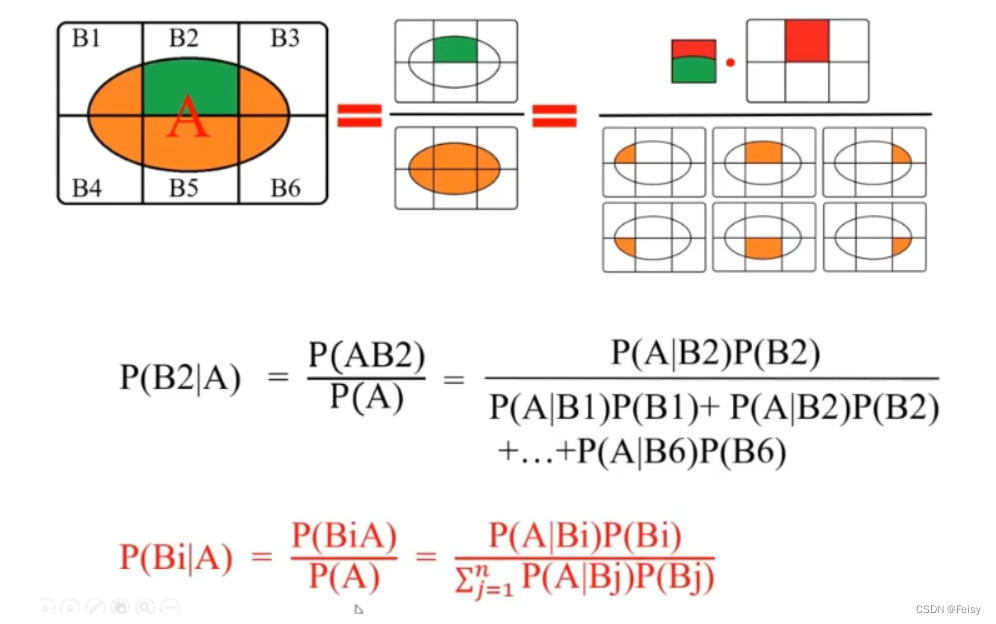
3.3 贝叶斯公式的简单运用例子
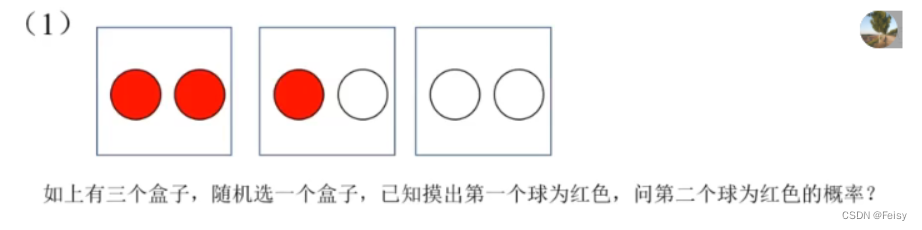
tips:我做的答案不一定准
因为第一个球是红球,所以条件A限定在第一,二个盒子了。
抽了一个红球出来,,还剩下2红1白,从这三个中抽取一个红球的概率是2/3
P(A) = 1/2
P(AB)=1/5(白红,红白,红红,白白)
P(B|A)=P(AB)/P(A) = (1/5)/(1/2) = 2/5
3.4 贝叶斯滤波的三大概率
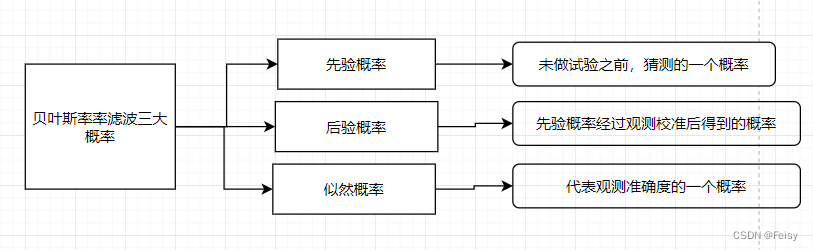
1 主观概率(先验概率):试验之前的概率,可以猜一个概率,并认为它是对的。特点就是没有做试验,就定了一个概率
2 后验概率:猜测了一个值后,然后观测,在观测值的条件下,猜测的值为真实值的概率 P(B|A),A猜测的值,B是观测的的值
3似然概率:源自最大似然估计,表示哪个原因最有可能导致了结果,一般用来表示测量的准确度(传感器)
似然举例:
A班99男1女,B班99女1男
我们随机抽一个班,再随机抽一个人进行观测,结果是女。
此女最像是从B班抽取出来。
我的观测结果是女的,那么是什么原因导致了这个结果?
最大似然的意思就是这个女孩是最有可能从B班抽取的,因为B班的女的太多了。
3.5 离散随机变量的贝叶斯滤波
3.5.1 定义以及公式
A 事件发生后,B发生的概率 P(B|A)=P(BA)/P(A)
A,B用x,y表示,那就变成了如下的形式:
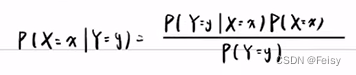
3.5.2 例子 温度的预测
温度的先验概率:也就是我们主动给的一个概率

测量温度

后验概率
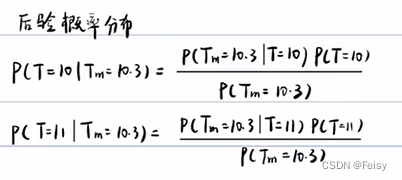
看看公式里面的成分:
先验概率:

后验概率(测量在后):
似然概率(测量在前):
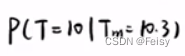

一个常量值:P(Tm=10.3)表示测量值为10.3的概率。
这里会有个疑问,这个值已经是测量出来的了,已经发生了的,那它的概率是1? 答案是:不是的。
随机变量的取值和它的概率不是一个概念。比如说抛硬币,正面朝上,它的概率是0.5,而
不是1.
P(Tm=10.3)是随机试验的一个结果而已,
随机变量的取值是一次随机试验可能的结果。
随机变量的分布律代表对随机变量的不确定的刻画。
即:随机变量的取值和随机变量的分布律没有任何关系
P(Tm=10.3)的计算方法:
用

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3229
3229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









