







我们今天的课程主题是动态全局光照和Lumen ,在讲Lumen之前,我们需要首先需要了解GI(Global Illumination),如果不把GI讲清楚,大家将会陷入Lumen复杂深邃的技术细节中。
如果不了解GI的发展演变,大家会感觉Lumen中的某些细节处理是凭空从天上掉下来的。但其实不然,Lumen中的很多算法和思想在之前的一些GI算法中都有出现和实践过,因此Lumen更像一个各种GI算法的集大成者。我们只有理解GI最宏观的体系结构,你才能理解Lumen 是怎么产生的。
一、 Global Illumination

第一步我们是要了解渲染中最著名的Render Equation ,这在之前的课程中也讲到过。我们今天几乎做的所有Rendering 相关的工作都是去满足这个Render Equation 。但是至今为止,没有任何一款游戏引擎能够做到实时的完全按照Render Equation来进行渲染,我们能做到的只是在无限的逼近它。

如果只计算点光(Point Lighting)的直接光照(Direct Lighting)还是比较简单的。但 GI 并不只计算点光,而是需要计算四面八方照的光,这些光和物体表面的 BRDF方程都要进行积分,才能形成我最终的光照。
这里面复杂的积分过程非常麻烦,电脑屏幕上拥有百万甚至千万级别的 pixel 。对于每个pixel,都要去采集四面八方射过来的光线,从而计算出它的积分值。离线情况尚且困难,更何况是实时的情况下,一秒钟还要渲染几十帧甚至上百帧,这里面的计算量简直恐怖如斯。

更糟糕的是,需要计算的光线数量严格意义上是无限多的。就算你在场景里面只摆放了一个光源,但这个光源可以把周围物体无数个小面片照亮,每一个被照亮的小面片依旧可以视为一个新的光源来照亮其他物体。同时被这些小面片照亮的其他地方也会继续反弹光线。我们把只进行一次反弹叫做 SingleBounce,把多次反弹叫做 MultiBounce 。
上图右侧是著名的渲染场景康奈尔盒(Cornell Box),通过比较渲染场景和同一场景的实际照片来确定渲染的准确性。它的左边是红色,右边是绿色,上面放置一个光源,下面放有一个长方块和一个方形块。这里需要注意的是,上方放置的光源并不是点光源,而是一个面光源,因此光源本身就可以分解成无限多个。就算是Cornell Box 这么简单的场景,如果你想把它做到接近真实也是非常困难的,并且如果想要做到实时渲染更是难上加难。
我们如果仔细观察,这个简单场景中的的光学现象其实非常复杂。光源照射到红色墙反弹回来后会出现很多红光,红光会照亮这长方块的左侧面。同样,右边墙上也看到绿色。而这就是 GI 的效果。

我们以游戏为例,如果游戏中只有直接光照,最终的效果就如上图左侧一样。而通常我们在游戏看到的效果并非如此,因为通常我们还会加上环境光。环境光其实是对 GI 的一个 hack,如上图右侧。虽然有了环境光的效果会让场景显得好了一点,但依旧达不到真正GI非常丰富且复杂效果。
阳光投进洞口的岩洞,拉开窗帘的房间,打着手电的傍晚,这些场景如果没有GI 来模拟复杂MultiBounce 的光学现象,整个画面会看上去非常塑料。因此我们需要去实现GI的这种效果。
Monte Carlo Integration
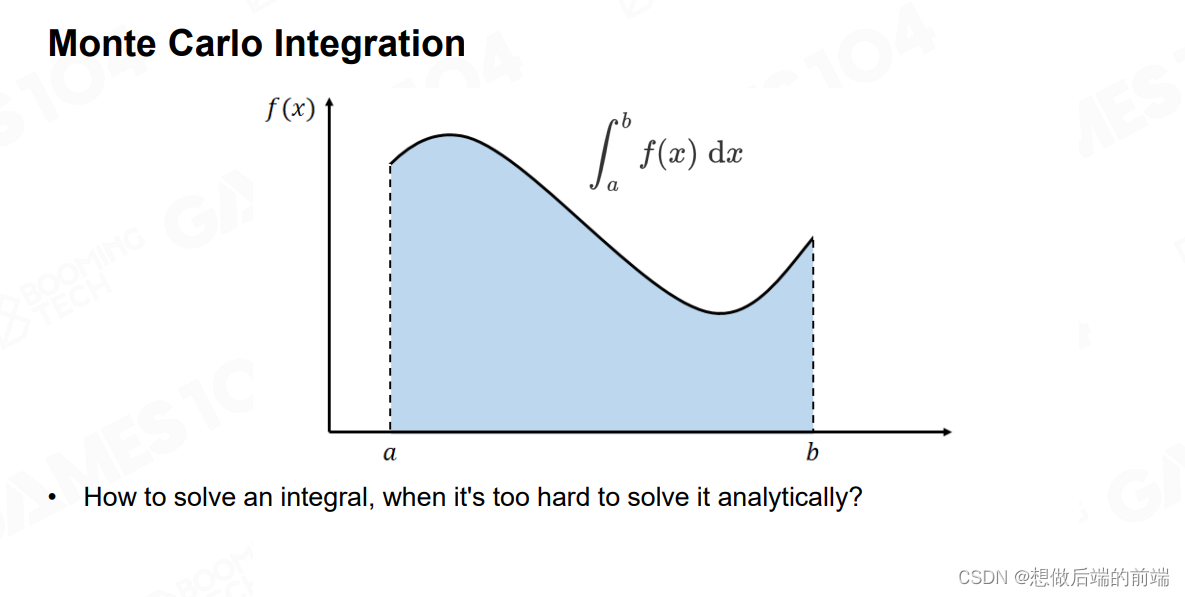 如之前所述,Global Illumination 中最复杂的问题就是积分,通常来讲,我们可以使用蒙特卡罗(Monte Carlo)积分法来解决这个积分。蒙特卡洛是一类统计模拟的积分方法,在求解积分时,如果找不到被积函数的原函数,那么利用经典积分方法是得不到积分结果的,但是蒙特卡洛积分方法告诉我们,利用一个随机变量对被积函数进行采样(Sampling),并将采样值进行一定的处理,那么当拥有一定数量的采样时,最终估算得到的结果可以很好的近似原积分的结果。这样一来,我们就不用去求原函数的形式,就能求得积分的近似结果。
如之前所述,Global Illumination 中最复杂的问题就是积分,通常来讲,我们可以使用蒙特卡罗(Monte Carlo)积分法来解决这个积分。蒙特卡洛是一类统计模拟的积分方法,在求解积分时,如果找不到被积函数的原函数,那么利用经典积分方法是得不到积分结果的,但是蒙特卡洛积分方法告诉我们,利用一个随机变量对被积函数进行采样(Sampling),并将采样值进行一定的处理,那么当拥有一定数量的采样时,最终估算得到的结果可以很好的近似原积分的结果。这样一来,我们就不用去求原函数的形式,就能求得积分的近似结果。
他的想法其实非常简单,假设对于一个函数f(x)区间 A 到 B ,我们在做Render 时的积分区间就是在法线朝向的半球上进行积分。

我们对于区间A到B内的点进行采样,得到每一个点的函数值,然后进行平均,就能知道你的这个积分的估算值是多少。对于 Shading 来讲,就是采样多个方向的光线计算的Radiance,最后把他们加在一起。
二、Monte Carlo Ray Tracing
使用Monte Carlo 求解GI 最直接的应用就是Monte Carlo Ray Tracing。
Monte Carlo Ray Tracing的思想非常简单,首先从我们的眼睛出发,也就是屏幕上的每个像素,发出射线(Ray),这些射线会射中场景中的某个物体。我们从被射中的位置点出发,再往它的四面八方去投射射线(1 Bounce),这些发出的射线会打中其他的物体,它又会在新的点向四周发射射线(2 Bounce),以此类推。在此期间,如果某根Ray射中了光源,那么我们就可以根据这条路径计算出对应的Radiance 。
Monte Carlo Ray Tracing通过多次反弹,每增加一层Bounce的,它的计算复杂度会进行指数级的扩张。SingleBounce如果还能勉强接受,但是MultiBounce计算量会随着迭代的次数急速膨胀。
我们需要注意的是,在我们实际应用的场景中,真正对于结果有贡献,或者说有亮度的地方是非常不均匀的。比如说一个硕大无比的房间,它真正亮的地方可能就是阳光射进窗子里的那一部分。你的整个房间都是被就是被它的MultiBounce照亮。这个时候你在进行采样的时候,你会经常发现,只有极少数的射线有机会打中窗子,绝大多数射线只会采样到了房间内黑暗的部分,根本没采到光。
因此Monte Carlo Ray Tracing 最大的问题实际上就是采样,因为采样是随机的,所以没有办法保证相邻的 pixel A 和 pixel B 能够产生同样的结果,A可能采样到了光,而B则没有,因此你会在屏幕上看到很多的噪点。

如上图所示,最左上角的图中是每次只发射一根射线,可以看到会有很明显的 Noise 。之后它每一张图从左到右从上到下采样数量都是翻倍的。
因此右下角图中的射线数量是2的16次方64,000 条射线。可以看到最后渲染的结果已经非常 Smooth 了。如果我们只需要一次Bounce 的结果 ,如果硬件够狠,几分钟你也许能渲染出来,但是如果是 MultiBounce 的话,依旧需要非常非常久的时间才能得到结果。
综上所述,你会发现基于Monte Carlo的方法,你的 Sampling数量越多效果越好,但是也会越慢。如何 Sampling是所有基于蒙特卡罗的GI 方法的核心。
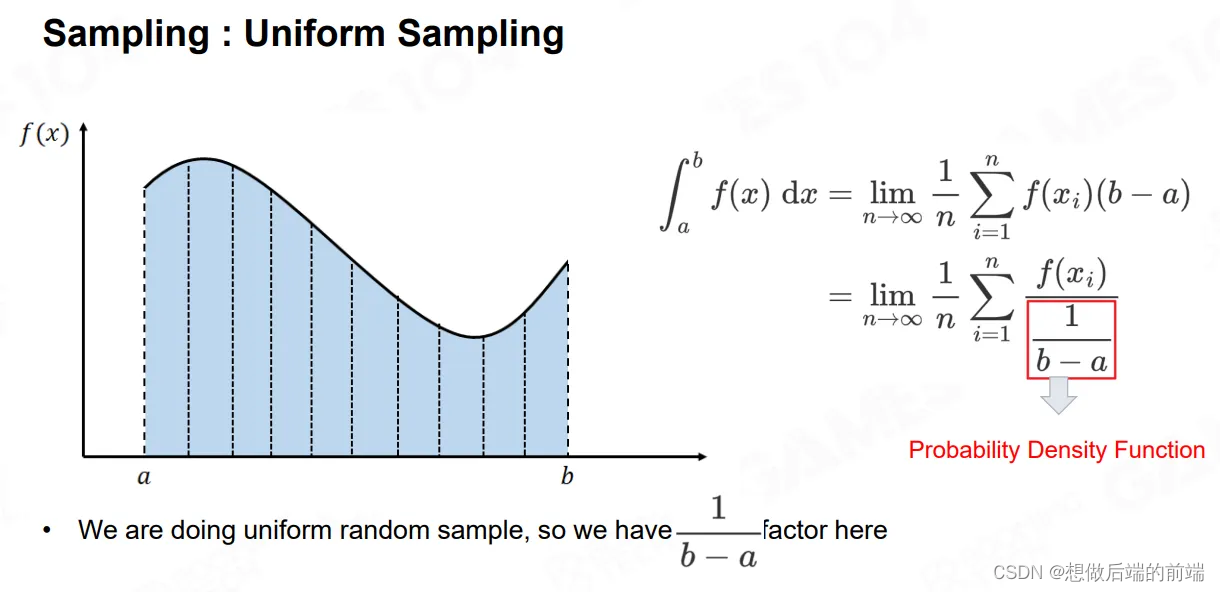
Sampling最简单的方法就是均匀采样 (Uniform Sampling)。但是绝大部分情况下信号的分布是不均匀的。使用Uniform Sampling除非密度很高,否则的话得出的结果其实并不尽如人意。如同上面我们的例子中,在一个房间内只有一个窗子是亮的,渲染的时候你在半球内实施Uniform Sampling,只有很少的射线能够采样到窗户。这就是Uniform Sampling 的一个问题。
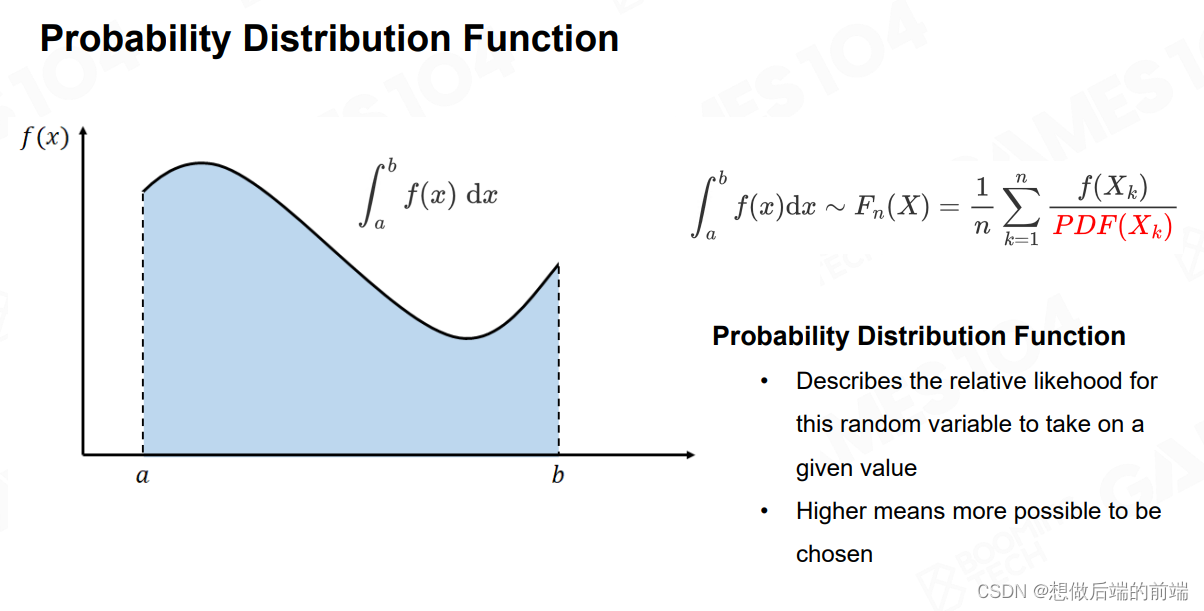
我们要引入一个很有意思的概念叫概率密度函数(probability distribution function )PDF。我们按照PDF的概率去选取我们的采样点,而不是按区间A到B均匀分布。我们只要在积分中除以选取采样点的概率,最后算出的积分是等价的。
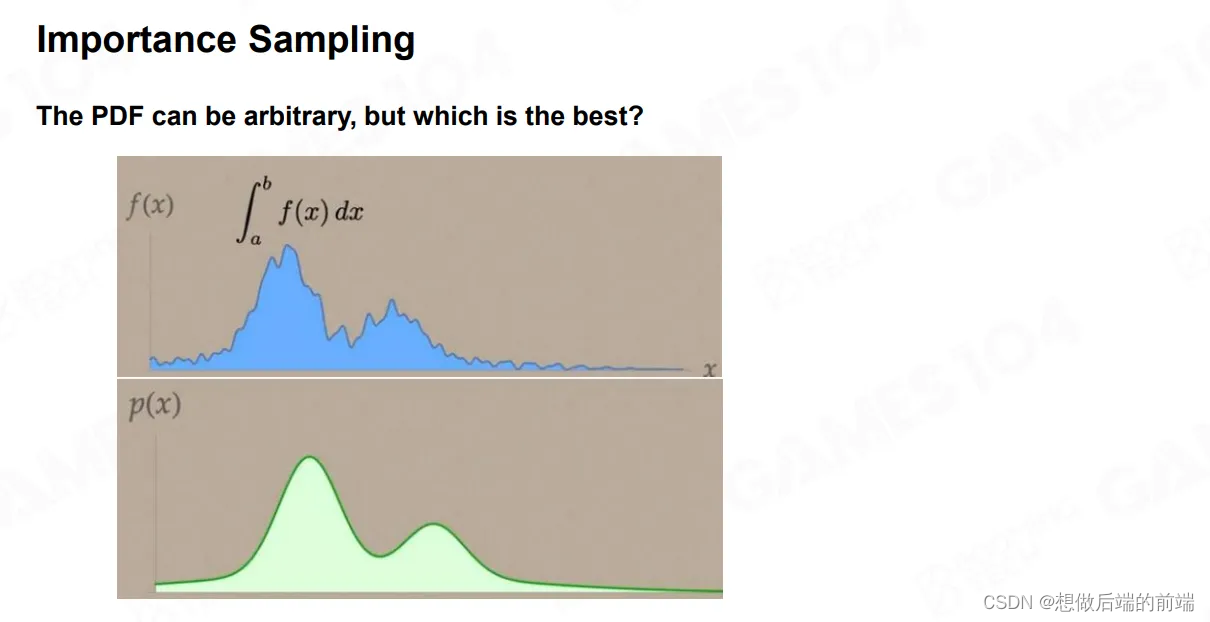
如上图所示,蓝色函数是我们要求解的函数,我们选取与被积函数 f(x) 相似的概率密度函数 p(x) 。根据 p(x) 在f(x) 越大的地方,采样点选取的概率越大,也就是信号强烈的地方,我们的采样点会比其他地方更多,在f(x)值较小的地方,采样点的选取的概率越小。在数学上可以证明,这样的采样方法,可以用尽可能少的采样来获取更为逼近的真实积分值的结果。
这个概念其实也很简单,我们尽可能朝着光比较亮的地方,或者尽可能沿着我的法线正对的地方去多投射一些采样的射线,那这样的话我就可以用更少量的射线来获得我想要的结果。

我们在做 Rendering 的时候,如果假设大部分反射是 diffuse的 ,对光的这个敏感度就是一个Cosine Lobe,靠近法线(Normal)的方向会敏感,然后对其他的角度衰减扩散。就算你的光线很强,但你是从很侧面射来,我对这个光的感应度其实也并不高。
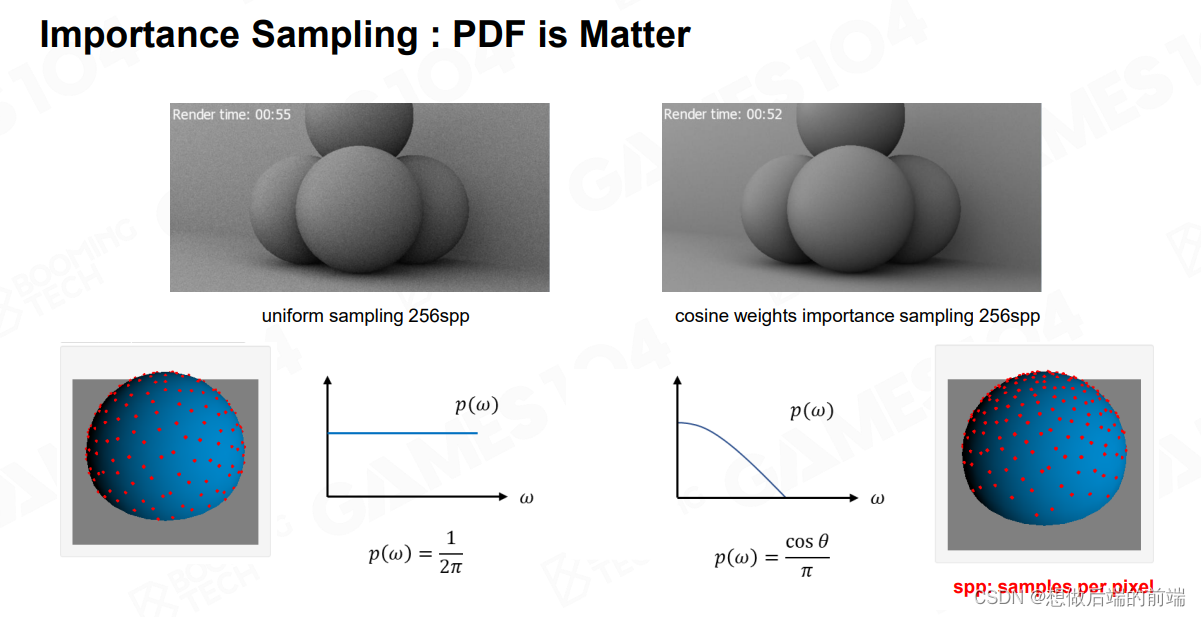
如上图,左边是Uniform Sampling,而右边是Cosine Lobe,也就是采样点的分布会稍微密集的靠近天顶的地方,你可以发现同样是256 spp( Sampling per pixel),使用Uniform Sampling会有很多噪点,而Cosine Lobe噪点会明显下降 。
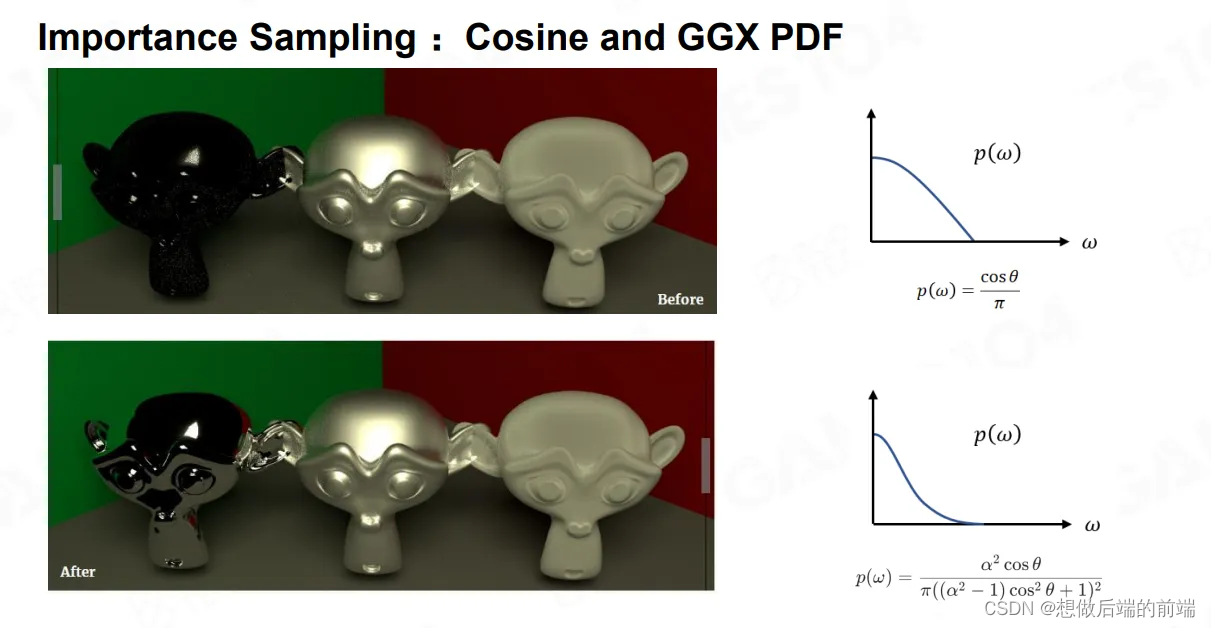 如上图所示,GGX材质高频足够高低频足够宽。这种情况下,我们使用GGX 的PDF会比使用Cosine Lobe更为Sharp,更能表达Glossy的效果。
如上图所示,GGX材质高频足够高低频足够宽。这种情况下,我们使用GGX 的PDF会比使用Cosine Lobe更为Sharp,更能表达Glossy的效果。
总而言之,GI 核心是你需要去找到一个好的 Sampling 方法,用尽可能少的射线去获取一个来自于四面八方的光场提供给你的信息。
三、Reflective Shadow Map(RSM )
前面我讲了Monte Carlo Ray Tracing的GI 算法,但它是一种离线方案,通常是在电影行业中使用,因为这种方案对于实时计算的游戏来说太过昂贵。这一章节们来讲 Reflective Shadow Map(RSM ),它核心解决的问题是我怎么把光注入到场景中去。
在图形学里面,我们大致有两类的GI方法,一类就是之前最经典的Monte Carlo Ray Tracing。另一个著名的方法叫做光子映射(Photon Mapping)。
Photon Mapping 的思想非常有意思,和我们之前的Ray tracing从相机为原点发出射线向整个世界不同,Photon Mapping 是从光源出发。Photon Mapping的思想是:我们之所以能看到世界中的物体,原因是因为从光源射出来的光子打到了物体表面,进而不停地反弹,人眼收集到了这些光子,进而你看到了整个世界。因此Photon Mapping使用光学中最基础的概念,从光的角度去看待整个问题。
关于Photon Mapping具体的实现细节,我们今天就不展开了。简单的讲Photon Mapping就是说我发射出无数的光子,然后这些光子在物体的表面来回 Bounce 。当到达一定条件后,那些光子就会停留在物体表面。我们在做 Shading 时,收集这些Photon然后进行插值,最后得出Shading的结果。 这就是Photon Mapping一个核心思想,大家如果有兴趣的话可以查阅相关的资料。
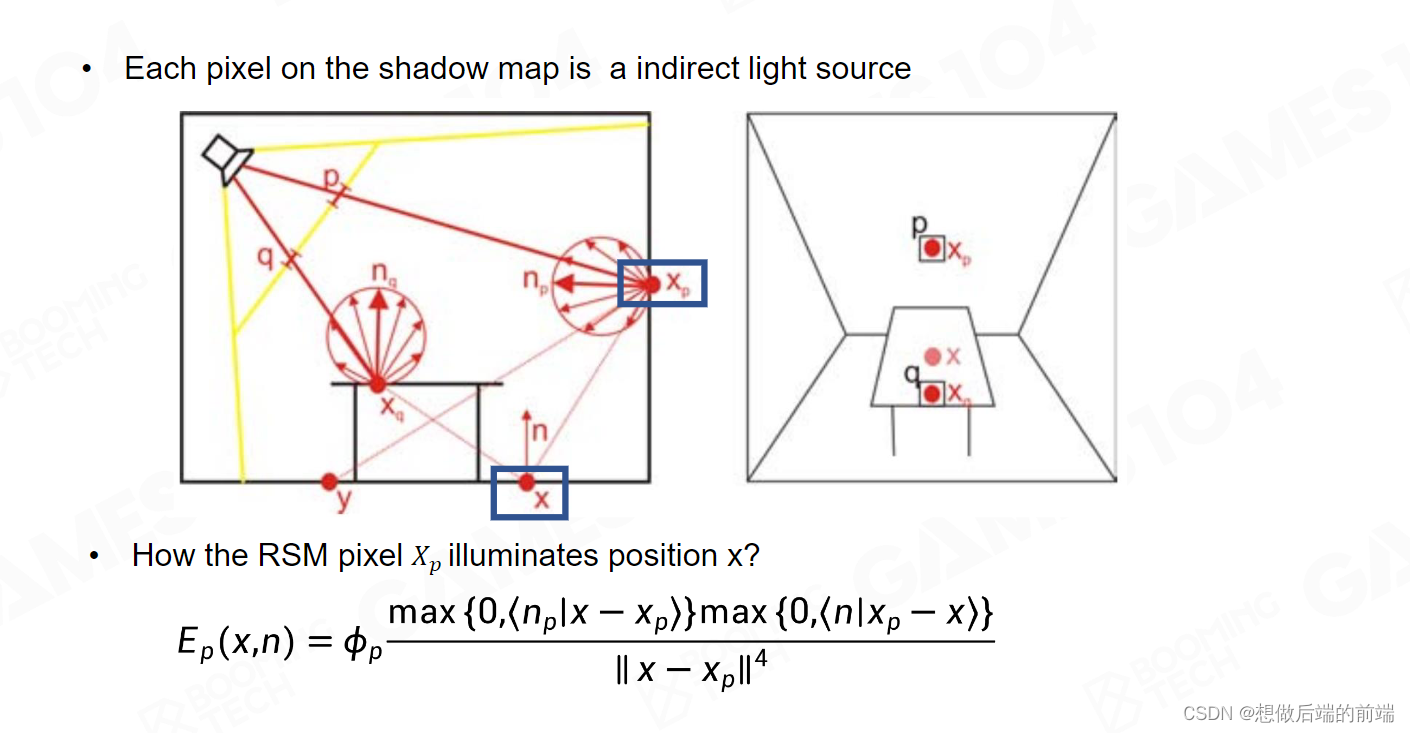
接着我们来讲 RSM ,它的想法基于一个直观的观察。我们在渲染阴影的时候,需要渲染一帧 Shadow Map,Shadow Map的渲染和正常的渲染不同,正常的渲染是从当前相机的视角去渲染。而 Shadow Map 是从光源的位置和视角去渲染。
因此,如果我们从光源的位置和视角,把整个场景正常渲染一遍,当只有直接光照的时候,所有被光源照亮的物体表面都会渲染到我的Map 里面。换句话说,从光的位置,你能看到所有被它直接照亮的表面。所有被第一次被灯光照亮的表面将被我渲染进去,一个像素不会多,一个像素也不会少。
当然这里我们除了存储光照通量之外,还需要存储WorldPos 和Normal,以提供给后续 Shading 读取。那么在做Shading 的时候,就提前拥有了RSM,我们就能知道所有在空间中被光源第一次照亮的点和它对应的亮度信息。
对应上图,假设我们要渲染X点的光照值,X点因为被桌子挡住,光源无法直接照亮这个点,因此X点并没有直接光照。我们根据之前渲染的那张Reflective Shadow Map,得知光源会射到 Xp 点,Xp点会沿着它的法线方向进行散射,我就可以把Xp 点的 Radiance 给接过来进行 Shading 。这就是RSM的一个核心想法。
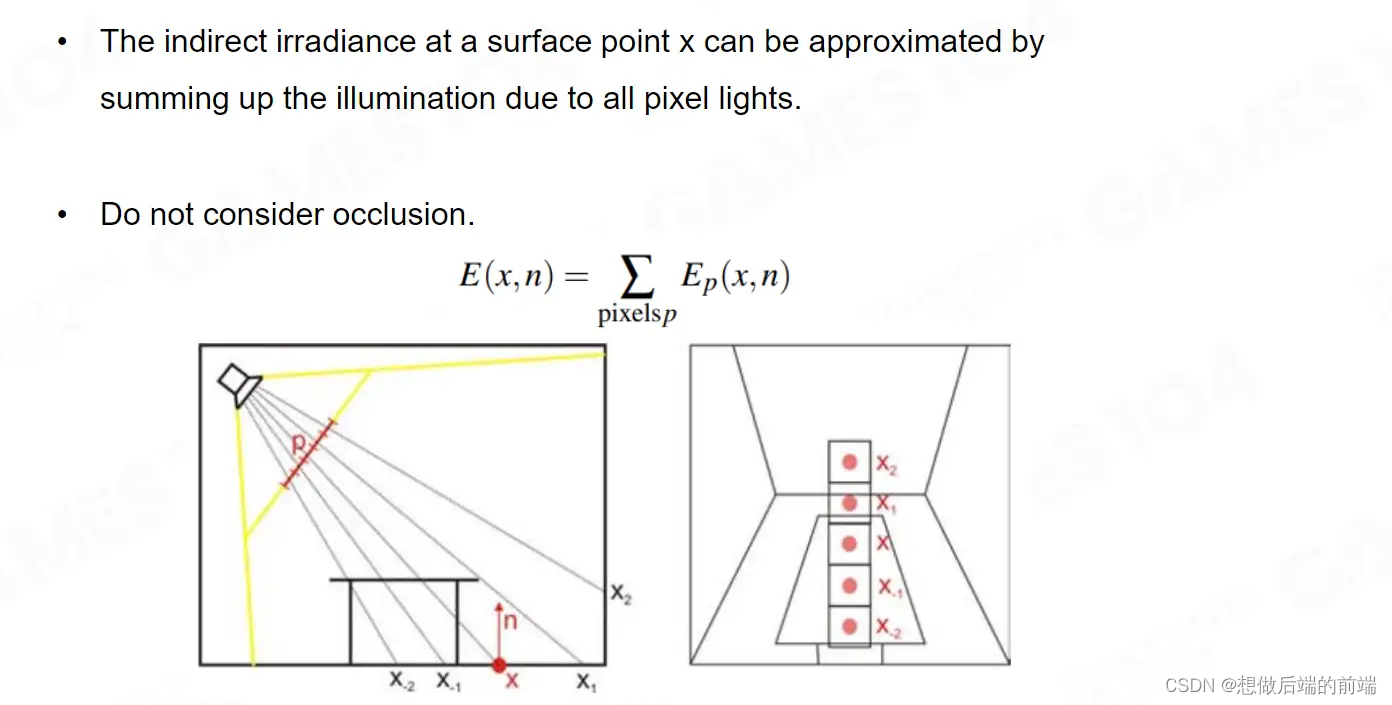
以此类推,最简单直接的方法就是将RSM中的每个像素都当成是一个小光源,把RSM上的每一个点都进行一次渲染,但这个方法有个问题就是过于粗暴,比如RSM分辨率大小是 512x512,那也是将近有几十万个点。把每个像素都当作光源渲染一遍是一个极度缓慢的过程。
 我们的改进的思路也很简单,距离我们比较近的间接光照对我们的影响最大,比较远的那些采样点贡献度则更低,因此我们不去对RSM上每个点都去采样,而是在世界空间中去不同方向发射Cone Tracing ,并且各个方向的方向采样密度不相同。如果某个方向上采样点距离比较远,我们采样的密度低一些,如果比较近,我们采样的密度会高一些。
我们的改进的思路也很简单,距离我们比较近的间接光照对我们的影响最大,比较远的那些采样点贡献度则更低,因此我们不去对RSM上每个点都去采样,而是在世界空间中去不同方向发射Cone Tracing ,并且各个方向的方向采样密度不相同。如果某个方向上采样点距离比较远,我们采样的密度低一些,如果比较近,我们采样的密度会高一些。

RSM只需要 400 次采样就能得到 1 bounce 的 GI 的效果,这也说明间接光照其实是非常低频的数据,它并不像直接光照那么高频。根据这个思想,我们可以用更低分辨率来计算间接光照,也就是每隔两个或者每隔四个pixel来做一次间接光计算,旁边像素可以跟共用周围像素计算的结果。
当然这也会产生一些问题,如果采样点和我当前渲染像素空间位置相差很大,或者法线朝向不共面,会产生很多Artifact 。当然这些渲染错误的 pixel 不会很多,对于整个屏幕来讲可能不到 1% 甚至千分之一。因此对于这种情况,我们就认为这是个无效的差值,重新对它进行一次完整的采样。

很早以前的游戏中其实已经实现了RMS,所以你可以在游戏中看到手电筒照照亮周围物体的效果。
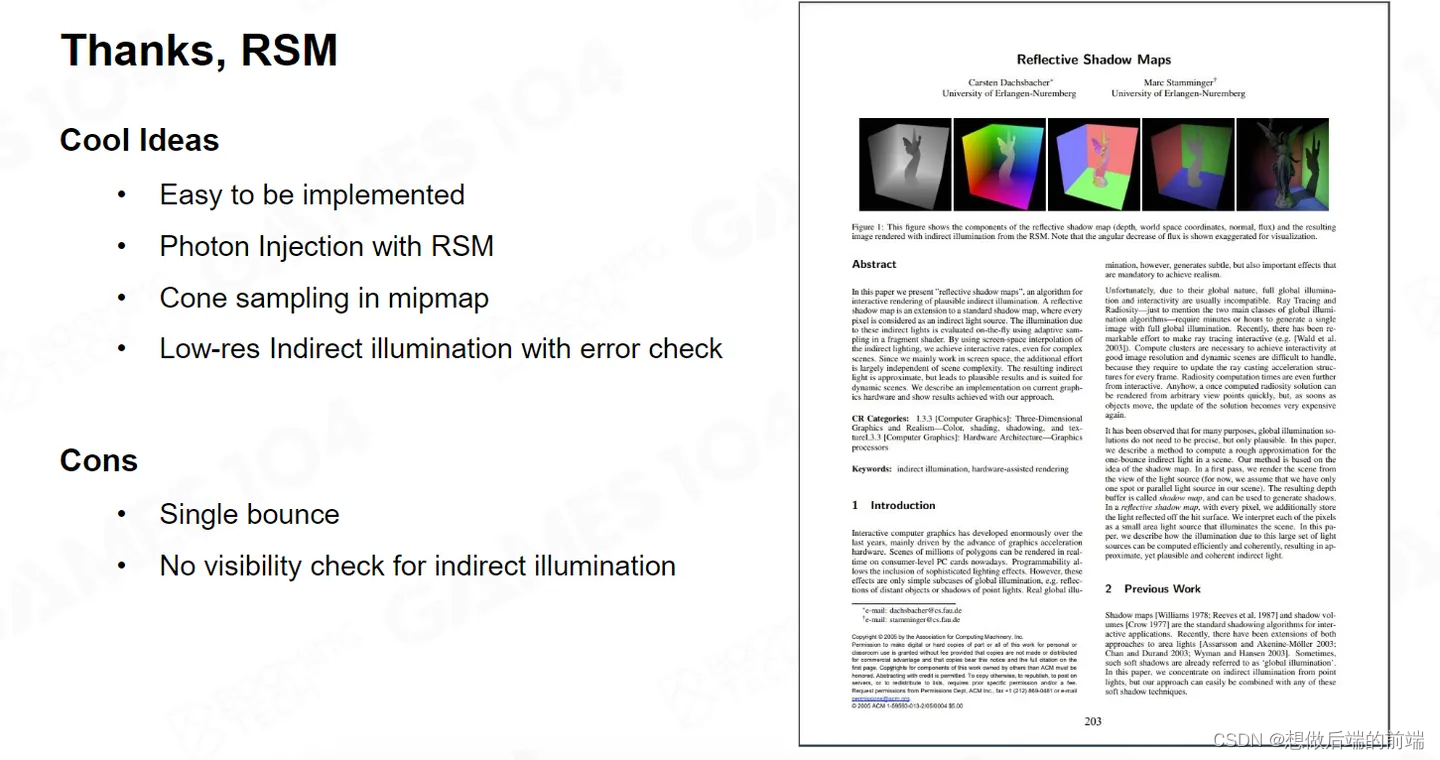
我们非常感谢RSM,首先想到了用把光子注入到世界当中这种方法。并且给我们提供了可以在更低分辨率的屏幕空间里面去采集这些间接光照的思路,还给我们提供了出现了 Error时,处理这些错误像素的方法。Lumen中很多地方都使用了这种思路。
RSM毕竟是个早期算法,有很多的局限性。首先是只能解决 SingleBounce ,而且它也不检测 Visibility ,并且没有考虑间接光照的遮挡。但是毫无疑问RMS 是一个非常具有启发性的一个工作。
四、Light Propagation Volumes(LPV)
既然光子已经注进去了,那我们就要让光在这个世界里面流动起来。这里就要介绍一个也非常具有启发性的算法 Light Propagation Volumes(LPV)。

LPV最早是 Cry Engine 3 提出的一种实时、无需任何预计算的全局光照技术。

在RSM中,我们找到并定义了一系列的虚拟点光源,LPV的第一步仍是如此。它在找到虚拟点光源后,把整个场景分成的一个个小格子叫做Voxel(体素)。
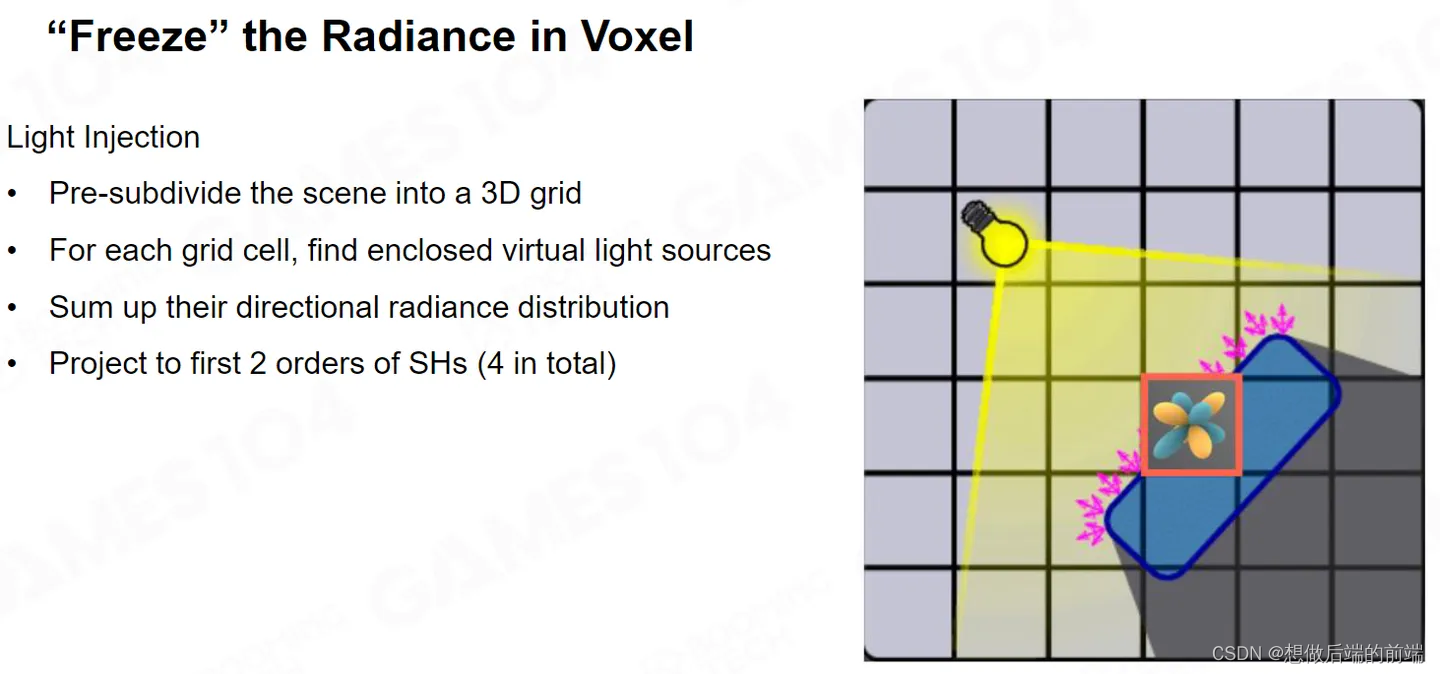
我们需要把在RSM得到的虚拟点光源“注入”到它对应的Voxel中。
由于在Voxel里可能有多个虚拟光源存在,因此存储时可以使用多个Cubemap来暴力存储,但是这会造成巨大的存储开销,通常来讲我们可以用二阶的球谐函数(Spherical Harmonics)SH来拟合这里的光照结果,因为球谐函数SH能够将光照是加权累积在一起。最后我就得到了在小格子里面Radiance 在空间上的分布场。
对于任何一个物体,在Shading 的时候,就可以拿到世界空间中每个Voxel内部光照的 SH 进行光照计算。
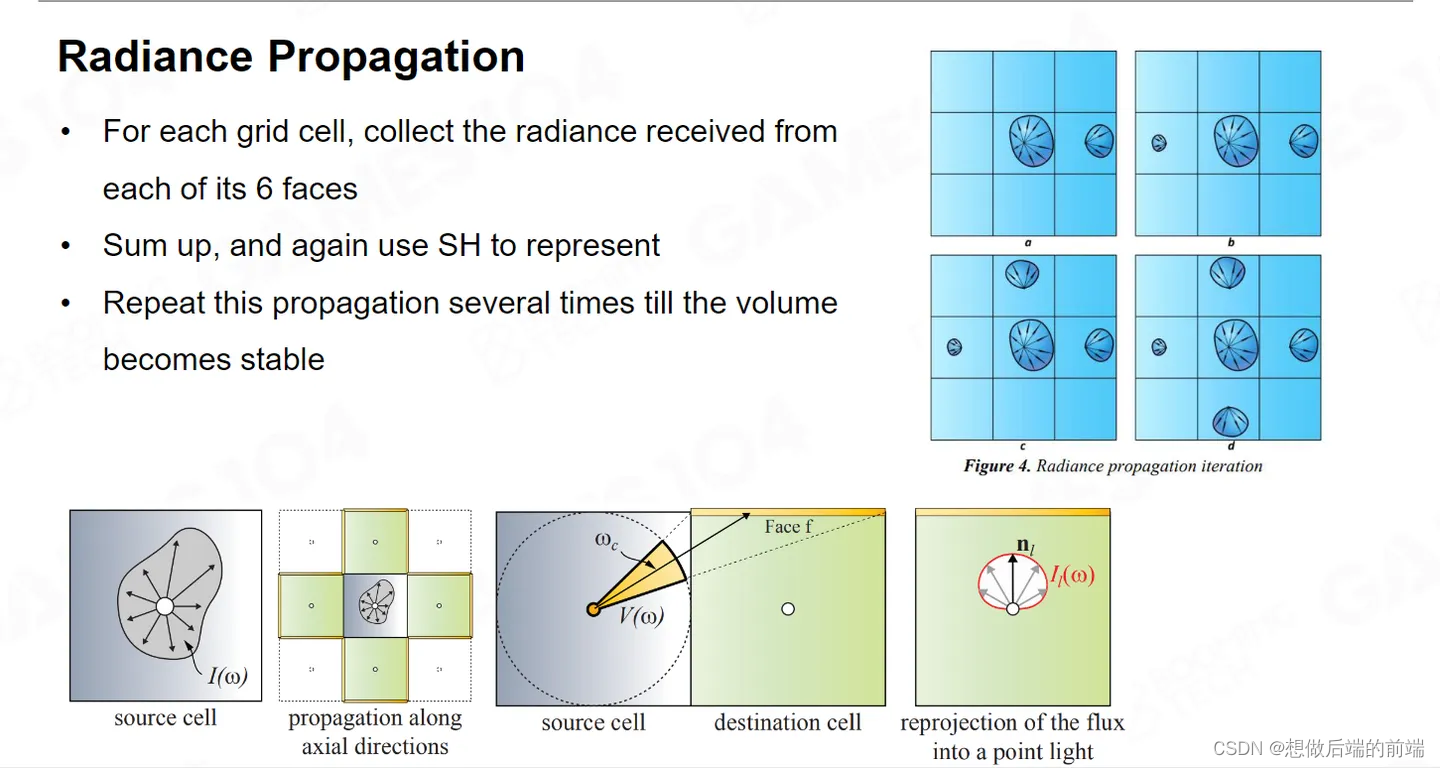
当我们有了Voxel 之后,还需要对场景进行扩散。对于一个Voxel,在传播时可以传播上下左右前后共六个格子。它从每个Voxel发出对应方向的射线,例如穿过了Voxel的右面就传播到右边的相邻格子。

这种扩散叫Propagation,LPV的主要问题是当Radiance 扩散出去之后,你这个Voxel内部还有没有 Radiance ,如果内部还有Radiance ,那么能量是不守恒的;如果 Radiance 不在,那个地方就是黑的,那么周围为什么还能被照亮呢?
我们会发现这个光的扩散的速度扩散的范围跟你做了多少次 Iteration 有关,这种感觉就像是说光是有限速度在各个这个 Radiance 里面去传递的。因此LPV 的方法不太符合物理学原理。
为什么要提起这个算法呢,我觉得最核心的就是他是第一个把空间进行 Voxel 的划分,在每个Voxel 里面去保存Radiance 的分布情况,并且更有意义的是他提出了把Radiance 的分布用SH存储的方案。
五、 Sparse Voxel Octree for Real-time Global Illumination (SVOGI)
接下来我们要介绍 SVOGI ,SVOGI是对之前LPV的空间的升级,之前的LPV虽然对空间进行Voxel 划分,但每个Voxel如果你分得太粗,就不能够准确地表达这个世界里面的光的分布,如果分的太细,那我就将拥有极其多的Voxel。并且物体里面的空间是是中空的,没有Voxel存在的必要,因为Voxel只需要存物体里面的光照信息。 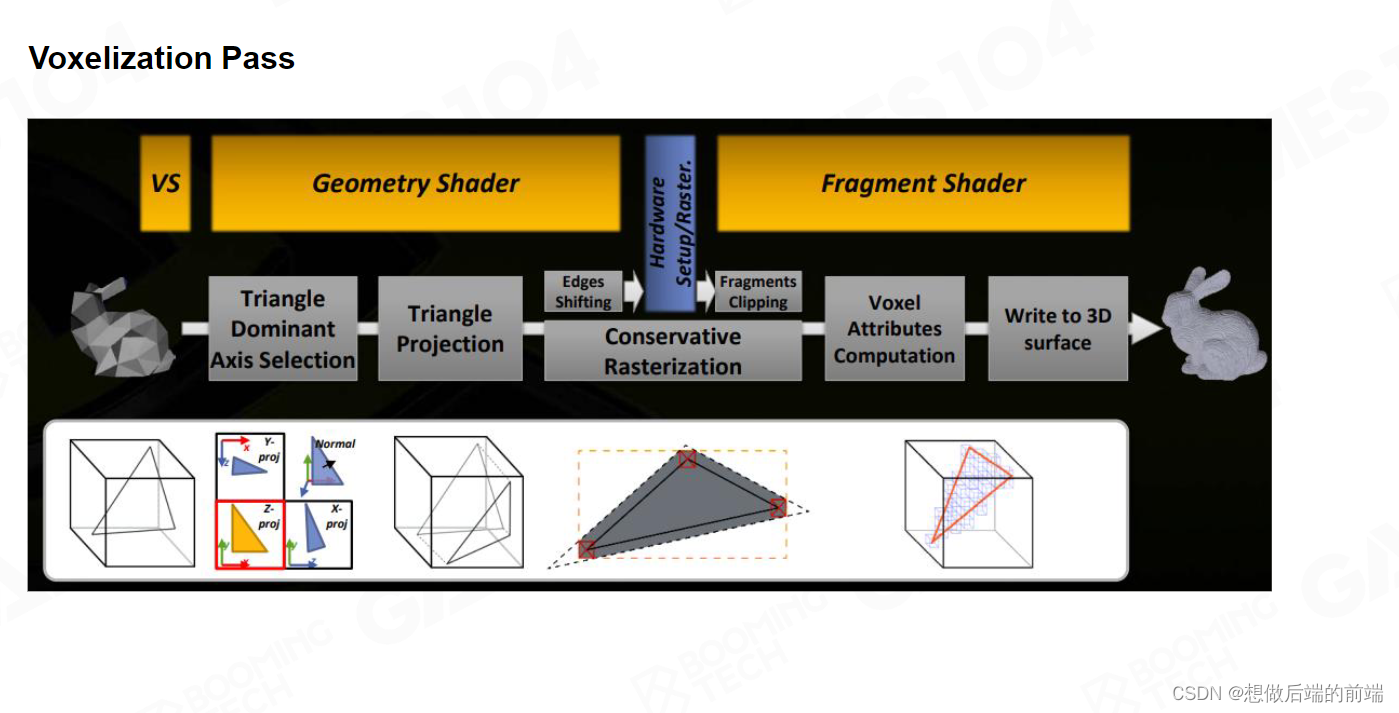
因此SVOGI提出一个叫做保守光栅化的方法。一般来讲,决定一个三角形是否占有一个像素的标准是三角形是否覆盖了像素的中心,保守光栅化则是只要覆盖到像素的任何区域我都会进行Voxel。比如很小很薄的三角形只占有像素的很小部分,依旧会进行Voxel。

如上图所示,我们把表面的 Voxel 全部收集起来。
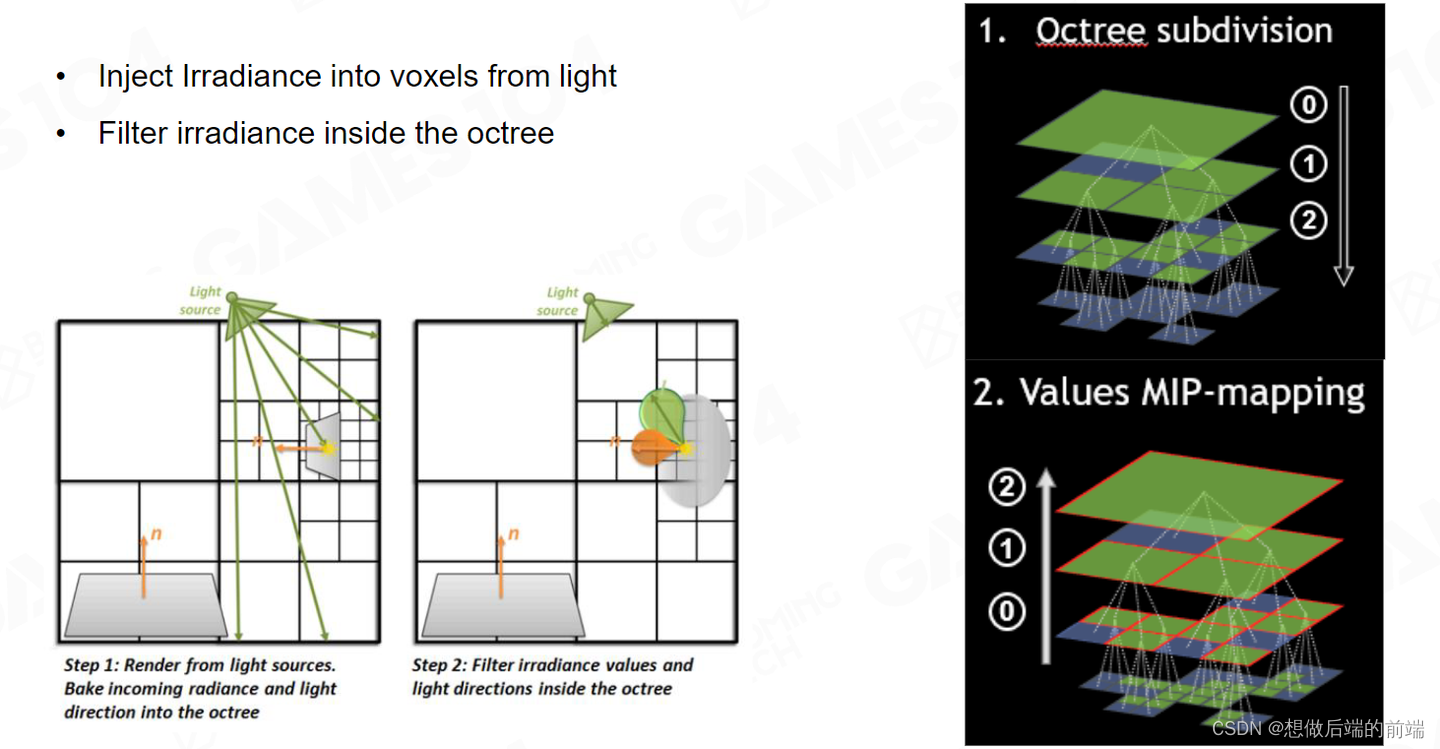
如果我们要表达的空间非常大,自然而然我们可以使用树来存储。大家知道空间上我的每一个维度上都进行二分,三维空间上八次分,因此我们使用八叉树。如果这个区间里没有对应物体,这颗树就会分得特别粗,如果有物体则会继续细分。
实际原文的实现非常复杂的。对于每一个节点,它不仅存自己的数据,还要存了周围的数据。因为它要做 Filtering 的时候需要这些数据来做差值,因此所需要的数据结构惊人的复杂。
我们很努力的想找到它的源代码,但很遗憾由于我们的信息渠道不够充沛,并没有找到源代码。所以有一些他们没有讲到但我们很关注的一些细节无法得知。
但他首先意识到Voxel的空间分布是不均匀的,基本上只要用到空间结构表达,使用这种Octree Tree空间划分的思想就是一个很自然而然的想法。
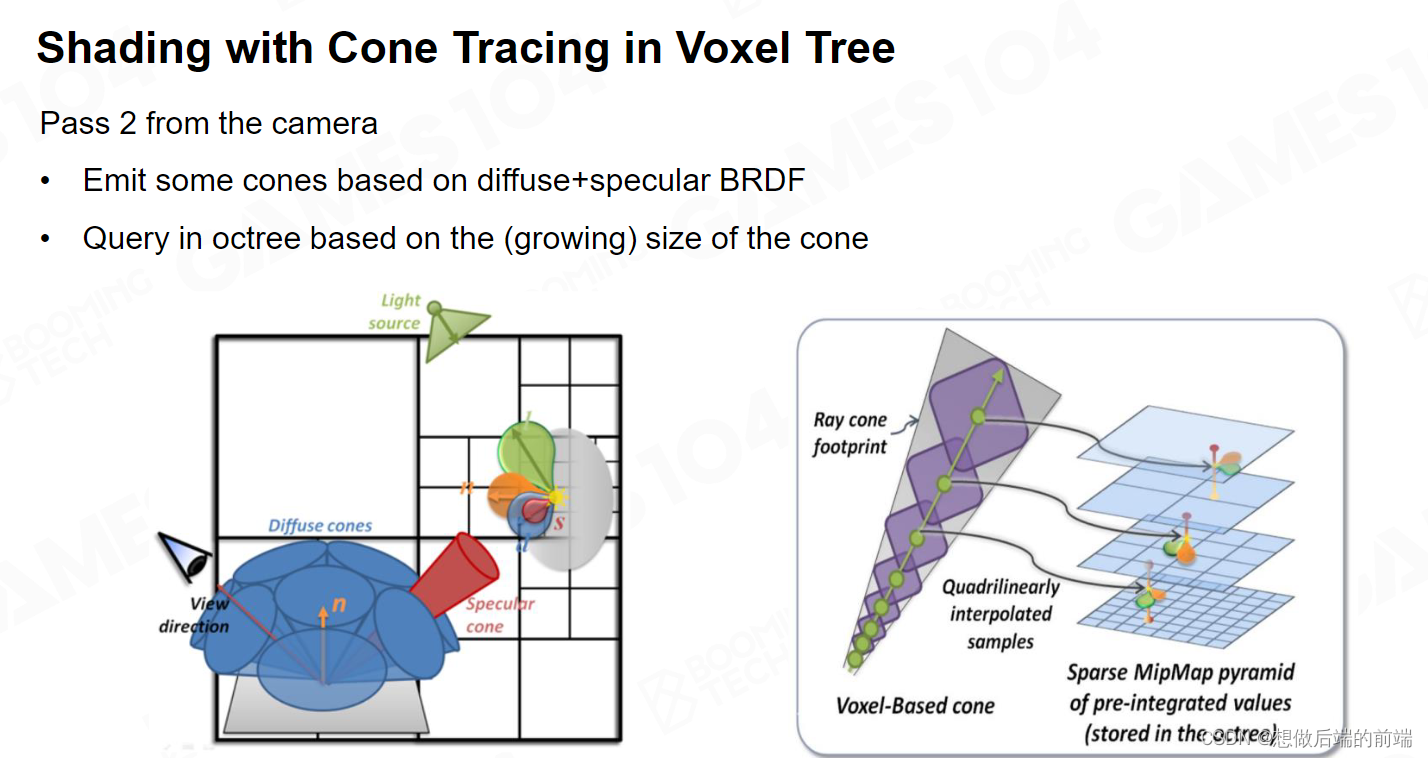
SVOGI 另一个很启发性的思路是,通常采样时你需要采样几百根Ray才能达到你想要的效果。他的想法是我想要重点采样的地方,并不是使用Ray而是Cone,Cone的英文是圆锥,当圆锥体展开的时候,对应的面积就会越来越大,那它在远处就会扫到更大颗粒的Voxel。由于Voxel 对空间的表达是一个树状结构,越靠近树的根部,它Voxel表达的空间区域就越大。所以你远处的颗粒更大的Voxel存储的值,实际上是一个很大面积的Radiance 的集合。
SVOGI提出的这个思想非常的好,因为你只要对空间进行结构性的Voxel 表达,你就会有这样的优势。
六、Voxelization Based Global Illumination (VXGI)

SVOGI的很多细节我们查不到,但是这并不重要,因为实际上没有人再用这个算法。原因很简单,八叉树的数据结构在 GPU 上表达非常的复杂。这在VXGI发明后,一切都被变成了浮云。
VXGI的思路是,我们其实并不需要整个场景的表达,对于 GI 来讲,我们最重要的工作是把我眼睛看到的地方的GI做好,并且离我比较近的区域的GI更为重要,远处区域的 GI虽然也重要,但是我不需要对它进行很高精度的采样。
这个时候我们使用传统的Clip Map 的思想,离我相机近的地方,我用更密的 Voxel 去表达;离我远一点精度就下降一倍,以此类推。
这样就不用极其费劲的去构建一个稀疏的八叉树结构,我依旧还是构建了一个树状结构,并且这个树状结构基于View的密度分布,对 GPU 更加友好,并且实现起来更加的清晰明确。
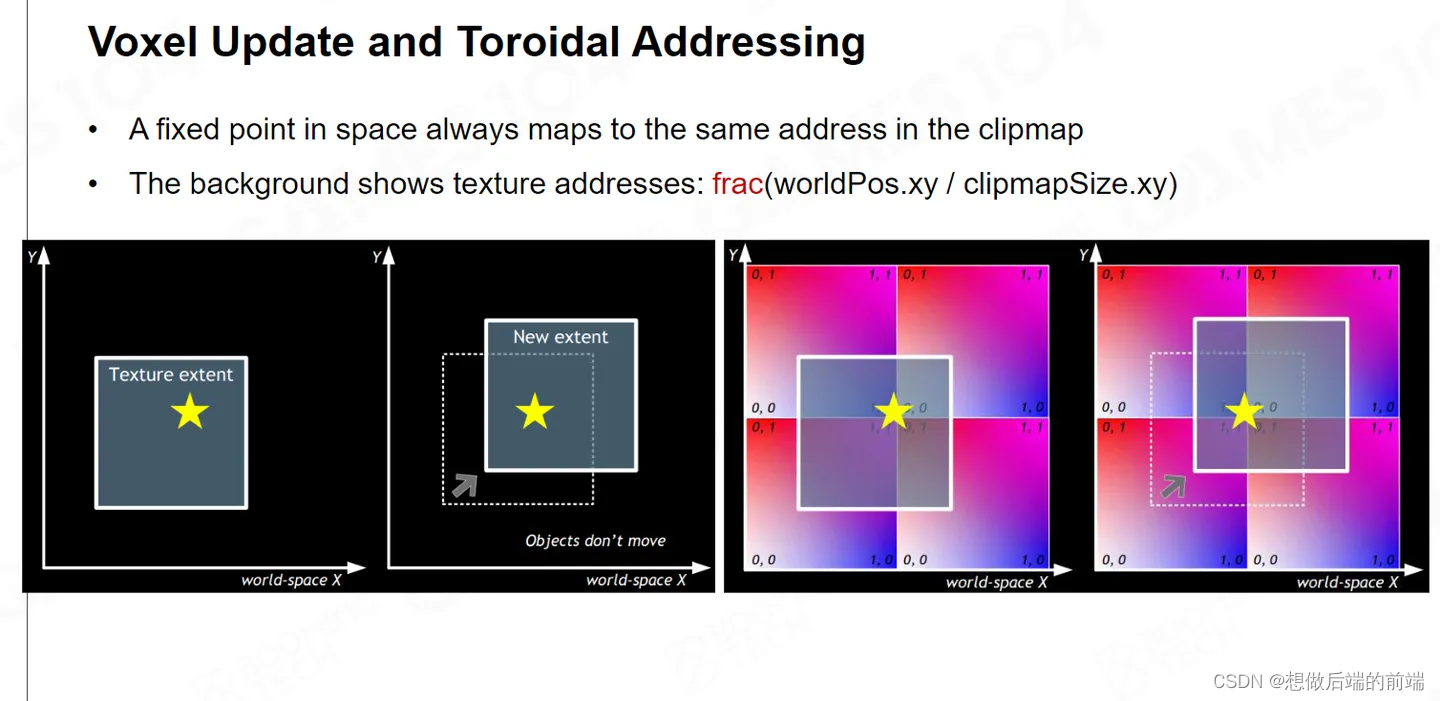
由于场景中你的相机总是在动,那么对应的ClipMap 也要跟随着进行更新。VXGI提出一种可循环的寻址系统。当你的相机移动变化时,我们只需要进行增量更新,也就是在 GPU 中,你每次只需要更新它边上那圈数据,而不需要把中间那些没有必要更新的数据重新生成和赋值。

这样我们对整个空间就有一个近处密、远处稀疏的Voxel 表达。如上图所示,远处的 Voxel 也没有显得特别稀疏,这是因为随让远处的Voxel很大,但是因为透视投影的原因,在屏幕空间中感觉并没有没有特别明显,但实际上它已经离你很远了。
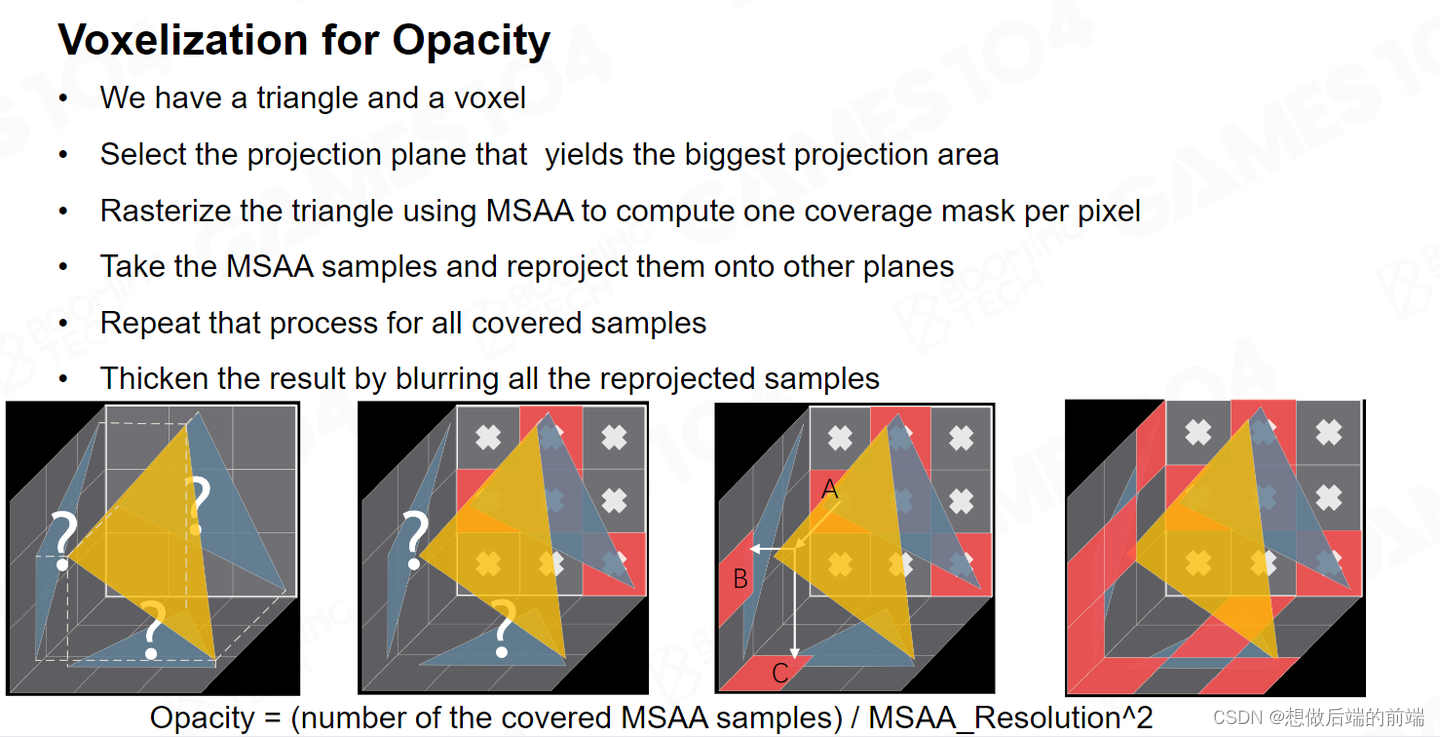
VXGI 还需要考虑透明度的问题。每个Voxel 并不是只有透光和不透光两个状态。实际每个 Voxel 有一个 Opacity 。假设Voxel里面有一个Mesh,这个Mesh把55%的光挡住,而45%的光透过,并且各个方向的透光率不一样,因此我们要沿着它各个方向算出它的不透明度。
我们在采样时,不像大家想的那样 hit 到了一个 Voxel 我就停在那里,而是有一个有半透明效果。
 如上图所示,对于一个场景而言里面的Voxel 会有很多半透(灰色)的区域。
如上图所示,对于一个场景而言里面的Voxel 会有很多半透(灰色)的区域。

对于VXGI,我们同样使用RSM,注入到我们每一个表面的Voxel 上去。
 大家可以看到只有一些 Voxel被照亮 ,因为只有这些Voxel 接受到了直接光照。
大家可以看到只有一些 Voxel被照亮 ,因为只有这些Voxel 接受到了直接光照。
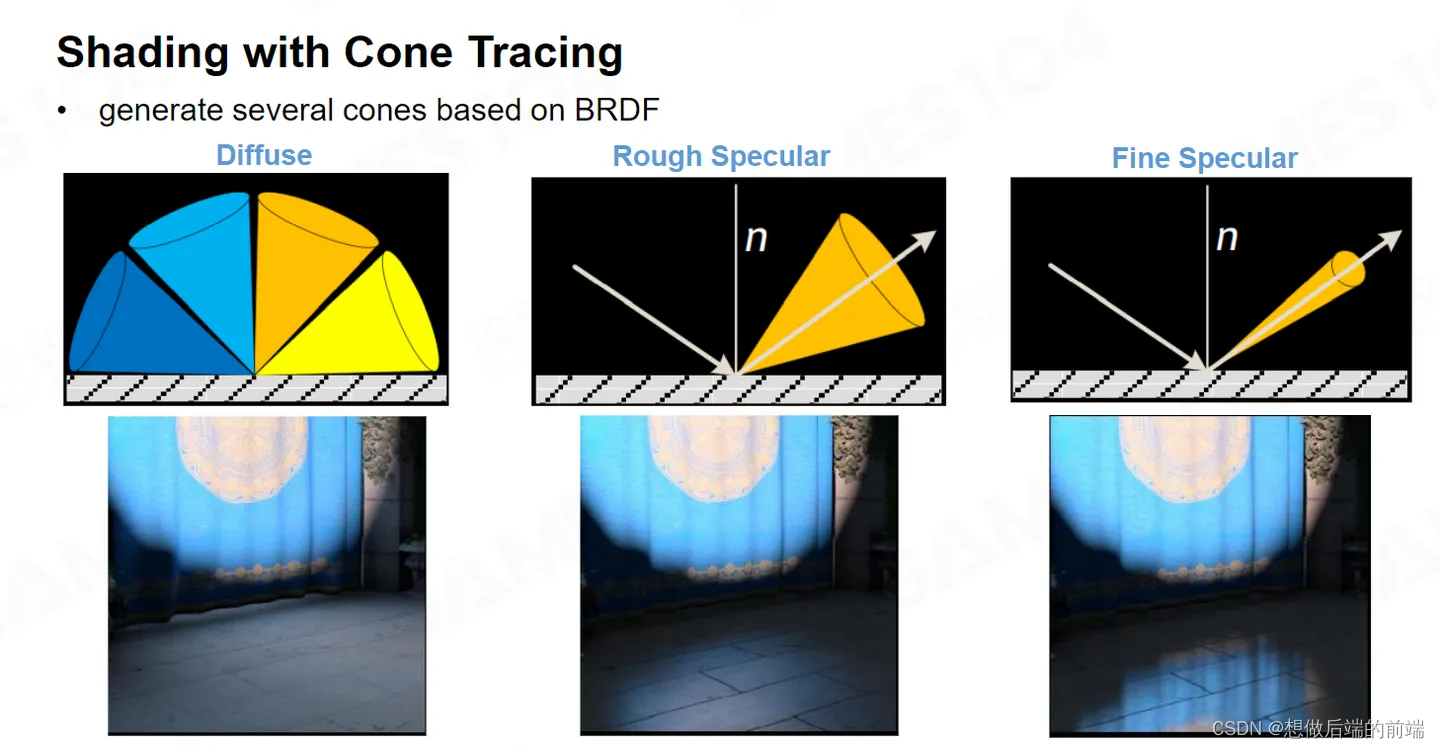
接下来,我们对于每个屏幕上的像素,进行Cone Tracing 。对于非常粗糙的表面,我就以Cosine Lobe四面八方的采样;如果表面是比较光滑我就沿着大致的反射方向采样;如果非常光滑的表面,我不仅只沿着反射方向去取那个间接光照,Cone还会变得非常的细。

根据之前所讲,如果沿着这个方向的 Opacity不是完全遮蔽,那么光能透露过来。这时候我再继续往后走,越往上走,我的采样面积就越大。我就取 Clip map 里面更高的 Mip 的那个Voxel,这样我一次性就能覆盖很大的区域。
我光线的透过的Alpha会随着我不断的透射而变低,当Alpha小于某个阈值,很接近于零的时候,我们就说,就当做不透明算了,我们就不往后再走了,这样能让我们的算法更快一点。

VXGI 实际上是我个人认为非常好的一个算法。虚幻引擎中有一代里面有一个插件就可以实现 VXGI。我对所有能够实装的算法都是比较敬畏的。
因为你真的敢把一个算法放出来,让大家在各种场景里测试的话,说明它本身的效率性能和它的鲁棒性已经达到了一定的程度。
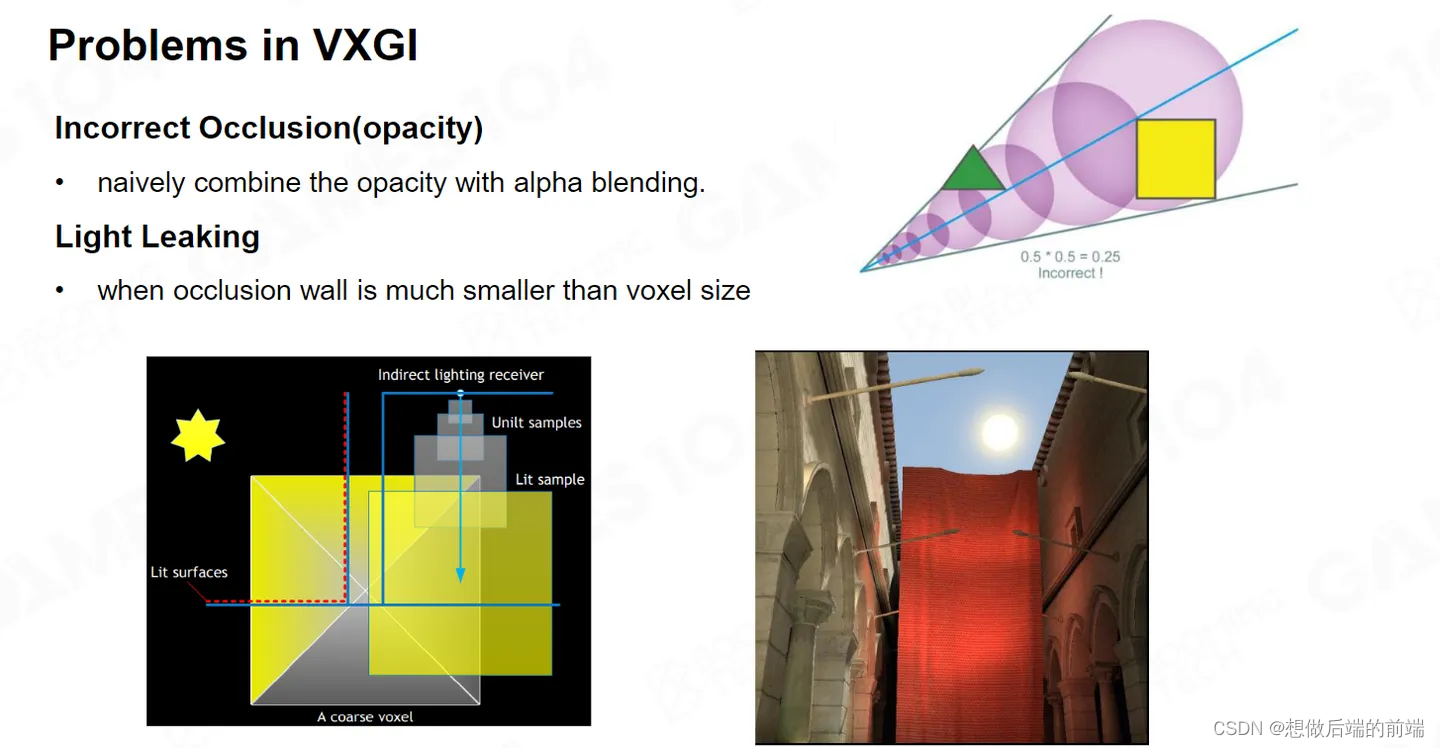
VXGI 其实也有很多的问题了,比如实际的Cone Tracing中opacity 累积是一个估计值。
如上图中右上所示,绿色三角形在Voxel 里面阻挡了一部分光照,黄色的方块也阻挡了部分光。它两个Alpha如果按照乘法累积肯定不为零。但是在实际上光路上其实已经完全阻挡了光照。
实际的渲染中的表现就是 Light Leaking漏光,特别是对于那种一些很薄的物体,或者本身不是很薄但是距离比较远的物体尤其严重。
七、Screen Space Global Illumination (SSGI)

SSGI的工作最早是2015年寒霜在SIGGRAPH 上发表的工作。

SSGI的原始思想很简单,如上图所示,红色框的是我直接渲染出来的东西。下面白色的部分,如果我要我去渲染它的间接光,因为他的表面非常的 Mirror ,所以我只要在屏幕空间里面把红色部分反一下,这些数据我就可以用了。因此SSGI的思路是,我在屏幕空间中把这些渲染好的像素点作为我全局光照的小光源。

如上图,假设整个屏幕中的像素已经渲染好了,当我要Shading图中黄色的点时,我已经知道了Normal和相机方向,我就可以沿着反射方向射一些Ray。这些Ray就在我的屏幕空间里面去找空间上位置正确的点,如果这个点是红色我就获得了一些红色的Radiance ,如果这个点是绿色我就收到了一些绿色的 Radiance ,这样的话我就可以直接用屏幕空间的数据进行 Indirect Lighting 。
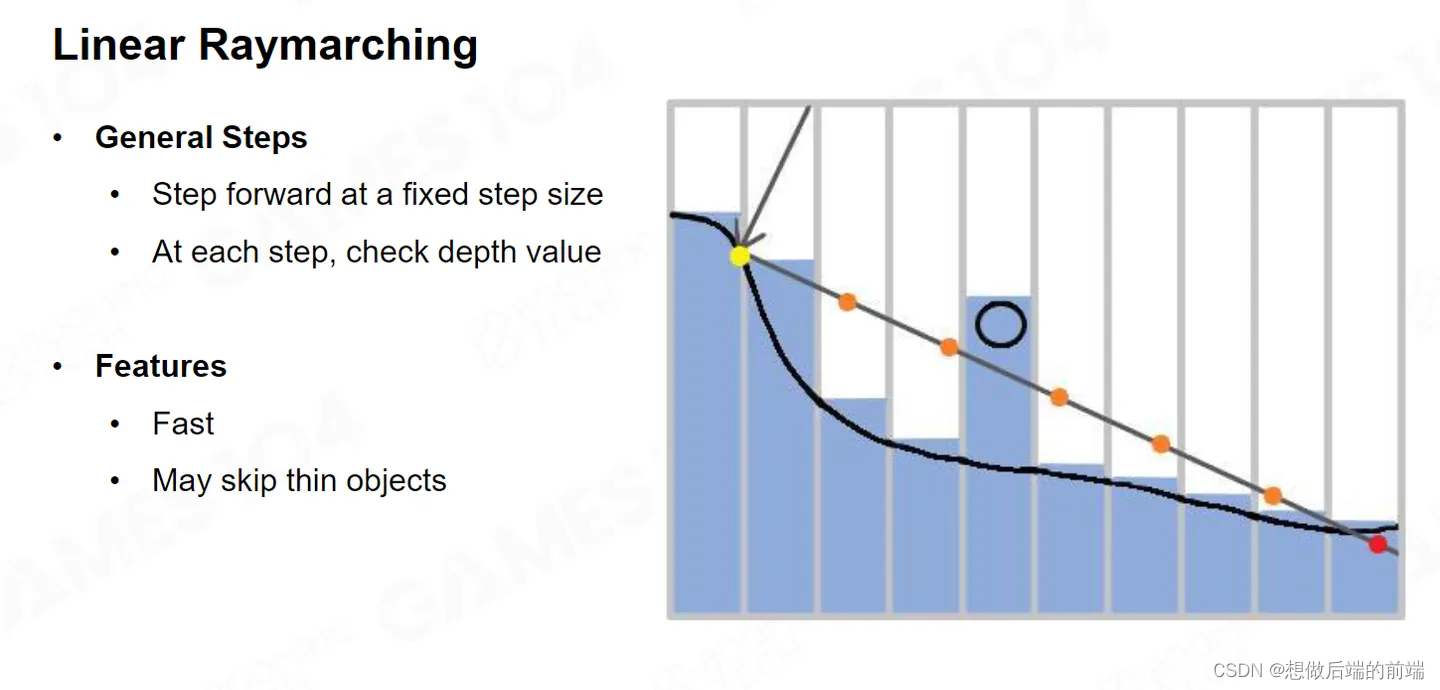
我们在屏幕空间中找到对应采样点的方法叫做Raymarching。假设我们从一个点出发射出一根Ray,这根Ray使用均匀间隔一直往前走,如果它当前位置的深度值比我这跟Ray的深度更靠前,就说明这跟Ray被挡住了,这个时候我就认为找到了一个交点。这就是均匀的 Remarching ,它要求步进间距非常的密,速度也就会很慢。
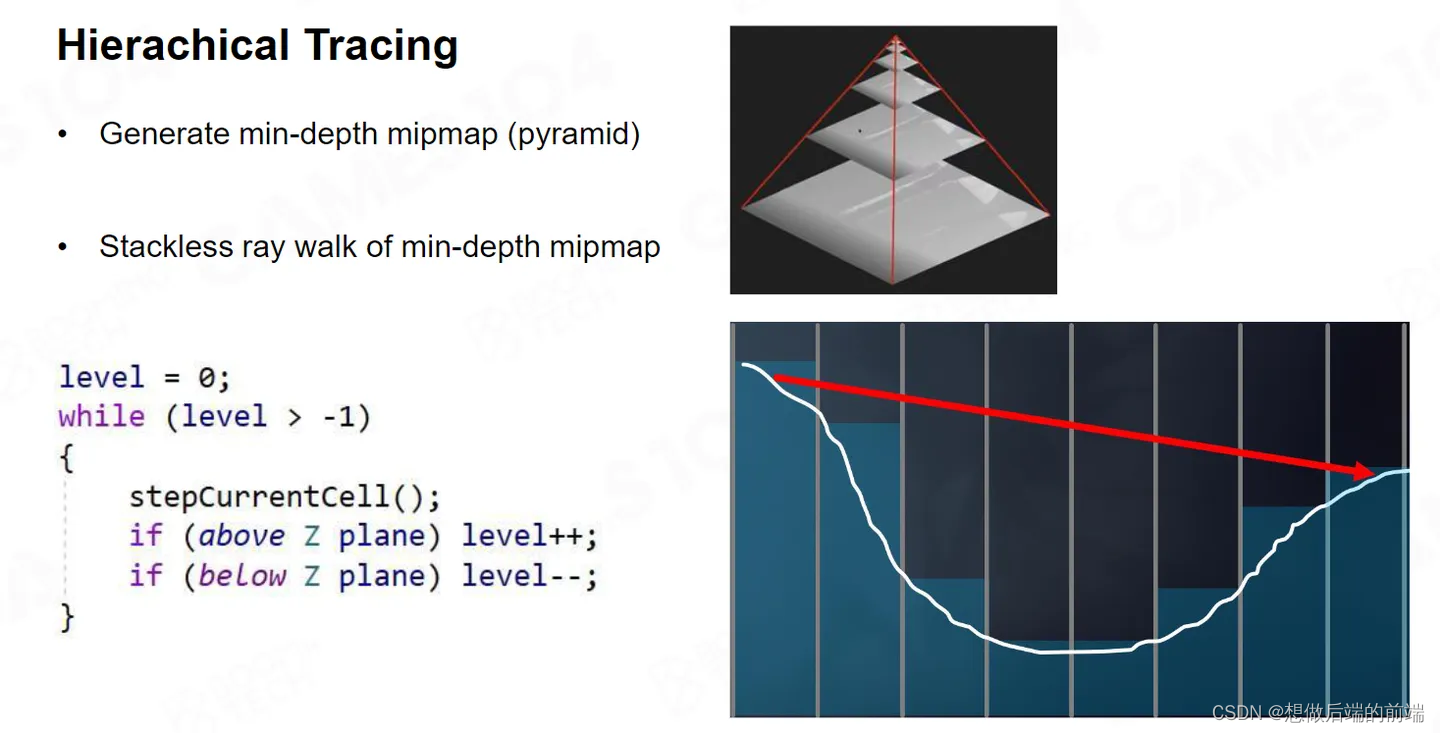
当然我们需要另一种方法加速Remarching 。GPU 硬件提供了生成一个特殊Buffer的方法,当然我们也可以自己实现,叫做HZB,也叫做Hi-Z。它可以把 Z buffer 做成一层层的 Mip,每个上层 Mip里面的一个像素,都对应它下层Mip里面四个点的像素。上层 Mip像素点的值,是下层Mip四个像素点中深度的最小值,也就是离我最近的那个值。
如果我们拥有了Hi-Z,一根Ray如果跟 Hi-Z的某个Mip不相交,那我跟你下层的Mip一定不相交。如果我跟你某个Mip相交,那我一定跟你下层某个Mip的像素相交。所以它实际上把这个Depth Buffer 做成了一个 Hierarchy 的结构。

当我有了Hi-Z,想做Raymarching的时候 就比较简单了。比如初始状态下,我在Mip0层,我先在Mip0层往外走一格。
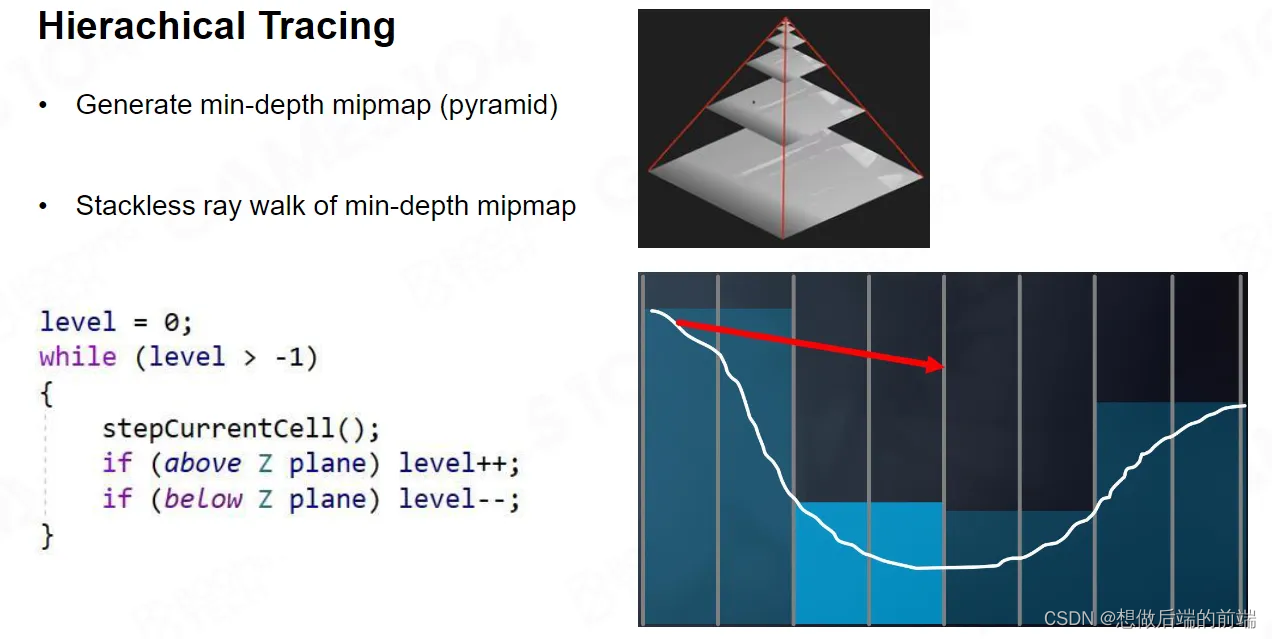
如果发现在Mip0层没有交点,我需要接着走,不过这时我往上跑一层跑到Mip 1走一格,这就相当于走了两格。
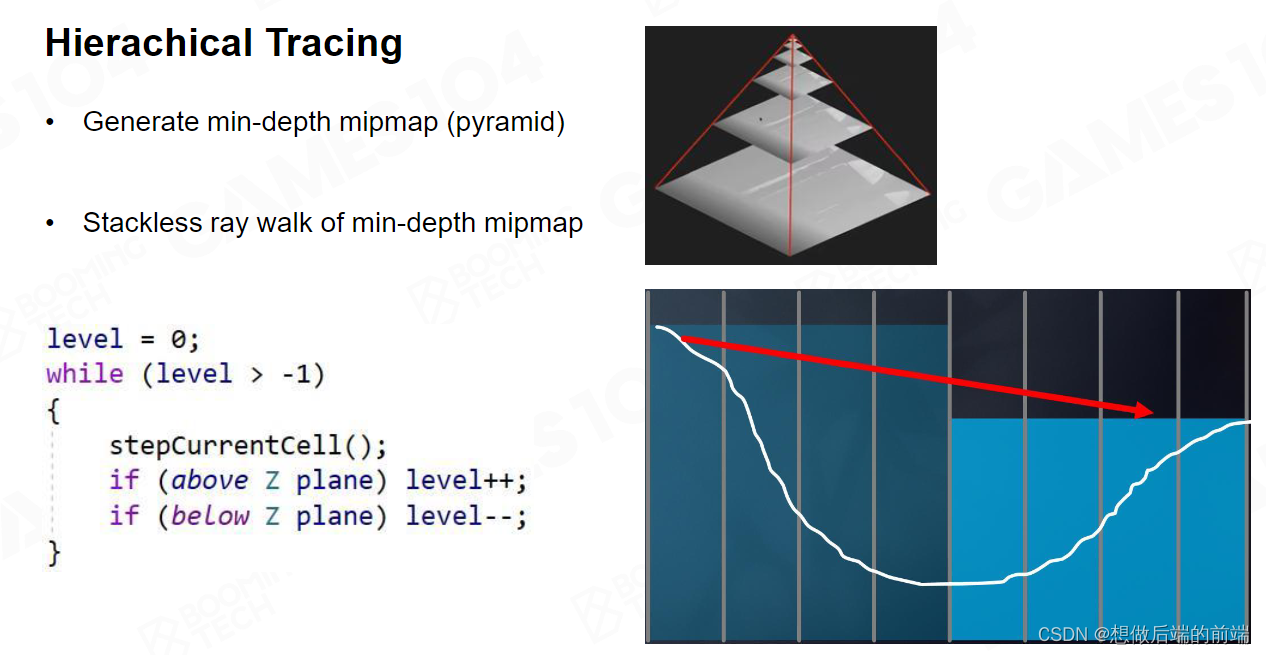
这个时候如果我发现还没有交点,我就开始胆子更大了,我在再往上走一层在Mip2走一格,我再做一次深度测试的话,这一次我相当于做到了四格。
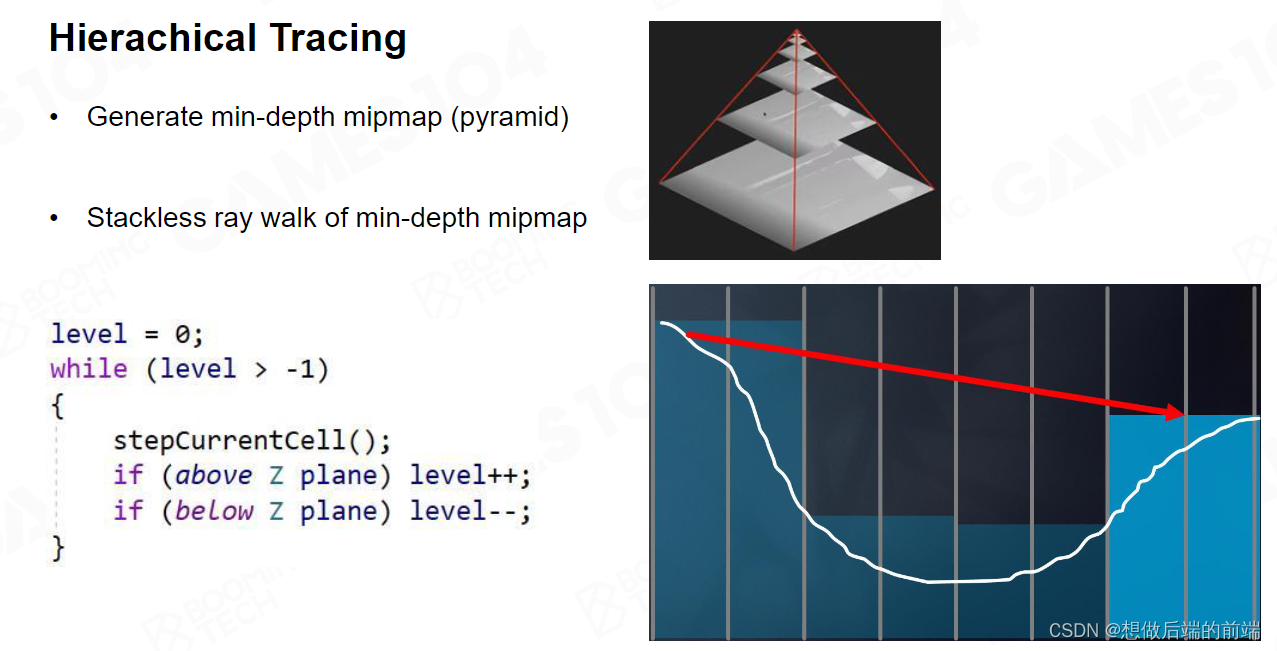
这个时候假设我不小心发现我检测到了物体。如今我是在 Mip2级别,我就知道他可能交到了Mip1 或者Mip0 的某个点,但是具体是哪个点我不知道。这时候,我回退到 Mip 1往前走一格。

我发现好像跟 Mip 1也有个交点。那我再回退到 Mip 0 继续走。
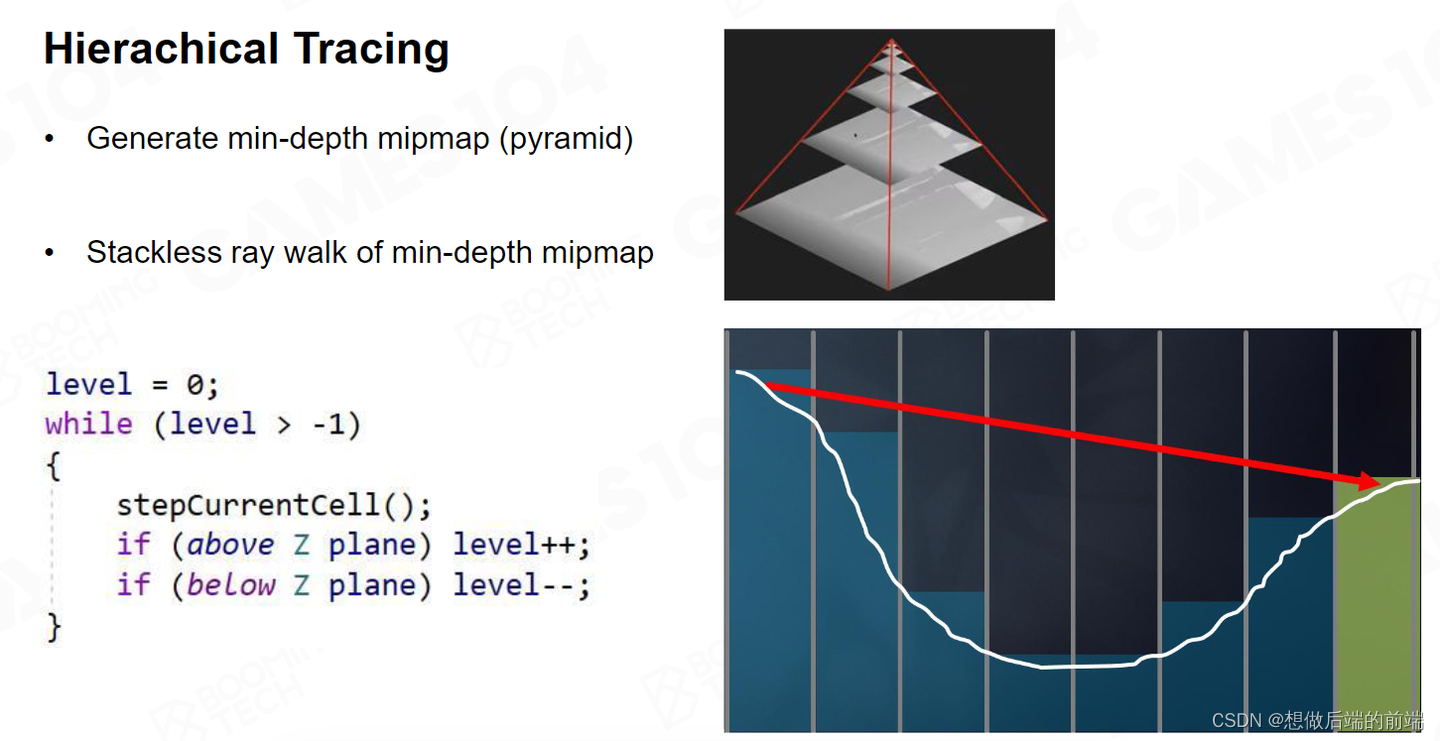
这时我们就能找到交点。虽然听上去Hi-Z比均匀采样更为复杂,但是它的算法复杂度是 log 2 的,也就是说你就算是 1024 或者更高的分辨率,我也最多只需要十几步就走到了。如果你用 Uniform 的 Raymarching 可能要走五六十步才能走到。

SSGI 还有一个很有意思的思想就是复用采样。当我对一个像素求出了采样点,我周围的点在也要进行球面采样的时候,如果不考虑 visibility ,他采样到的那个小灯泡实际上也是你的小灯泡,相当于帮你也做了一次采样。这个思想其实也是非常重要的。因为在我们真正做 GI 的时候,你不可能对每一个采样点的位置射那么多的Ray,不然整个计算就会爆炸。

和之前一样,我们提供采样的Scene Color 也会做Mipmap,对于远处的Cone Tracing 会采样到分辨率更低的贴图,这相当于对整个光照进行了一次 Filtering。

当然SSGI也会有一些问题,如果在屏幕空间没有的东西,我就看不到。比如像上面例子中框出的部分因为反射的数据拿不到,所以下面的整个都变白了。但是这不影响SSGI作为一个非常有用的算法。
SSGI 拥有很多优点:
- 因为Hi-Z的精度非常高,所以两个物体的交接面,非常细腻的几个 pixel 的内容误差,它都能把你算出来,因此SSGI能够处理非常近的Contact Shadow。而以前 Voxel的方法对它的处理很糟糕。
- 对于Hit的计算,因为用了Hi-Z 的方法非常准确,这比Voxel去估计要准得多。
- 无论场景有多复杂,SSGI对场景的 complexity 是无感的
- SSGI能够处理动态的物体。
这几个优势非常重要,这就是为什么在这么复杂的 Lumen 架构里面,还使用到了SSGI 。


















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











