








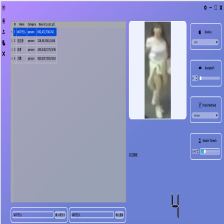
基于ViT finetune车辆重识别demo展示
Vehicle Reid(车辆重识别)
前言
随着transformer在多模态上强有力的对齐能力,以前都很难想象5B组图像-文本pair预训练的参数有多强。
现在告诉你,把vit大模型的参数迁移到纯视觉的下游任务,基本上都是指标猛增。
veri-776 mAP随随便便上85,以前那么多前辈辛辛苦苦设计的network不如大量数据来的直接。backbone强大才是真强大,装上v12发动机, 奥拓变法拉利。
任务目的: 使用一张车的照片,在视频or图像中找到这辆出现的时刻。

问题拆分:
For image: 车辆检测-> vehicle reid -> vector search -> matching.
For video: 车辆检测 -> 多目标跟踪(MOT) -> vehicle reid -> vector search -> matching
- 车辆检测: YOLO检测器 or 其他的detection模型(技术成熟).
- MOT: 使用滤波/位置等信息跟踪, 来减少调用reid 模型的次数,从而来加速(reid相对track耗时很多,技术成熟)。
- Search engine: Faiss 向量检索库支持物理加速和算法加速(有损)。
- Person Reid: 将目标图像映射到特征空间上, 即输入图像输出vector。这一类属于metric learning, 核心思想是类内相近,类间相远。
Vehicle Reid (复现详情见:reid复现)

一句话讲清做了什么:
挑战: 几乎所有的ReID方法都需要在ImageNet上训练的初始模型,该数据集包含了手动给定的图像和预定义集合中的一组标签。完全忽略了描述丰富语义的视觉内容。
作者方案: 想把多模态大模型上视觉和文本描述两个对齐模态的能力迁移到纯视觉下游任务上.
作者分了两步.
- 1.训练不动clip的参数,构建类似person_num个可学习token,每个token代表一个人。(本质:Textual Inversion)
- 2.训练只动visual encoder参数,让它和文本模态对齐。
公开数据集
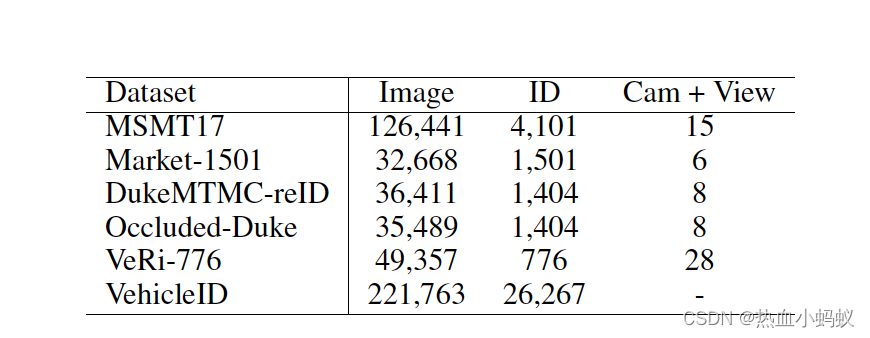
- VehicleID 数据集由许多不重叠的监控摄像头拍摄。总共有221763张图像,来自26267辆车, 没有跨镜头和view信息。
- VeRi-776 数据集利用了大约28个交通监控摄像头在各种条件下的图像,如不同方向、照度和遮挡。它包含了49357张图像,涉及776辆车。
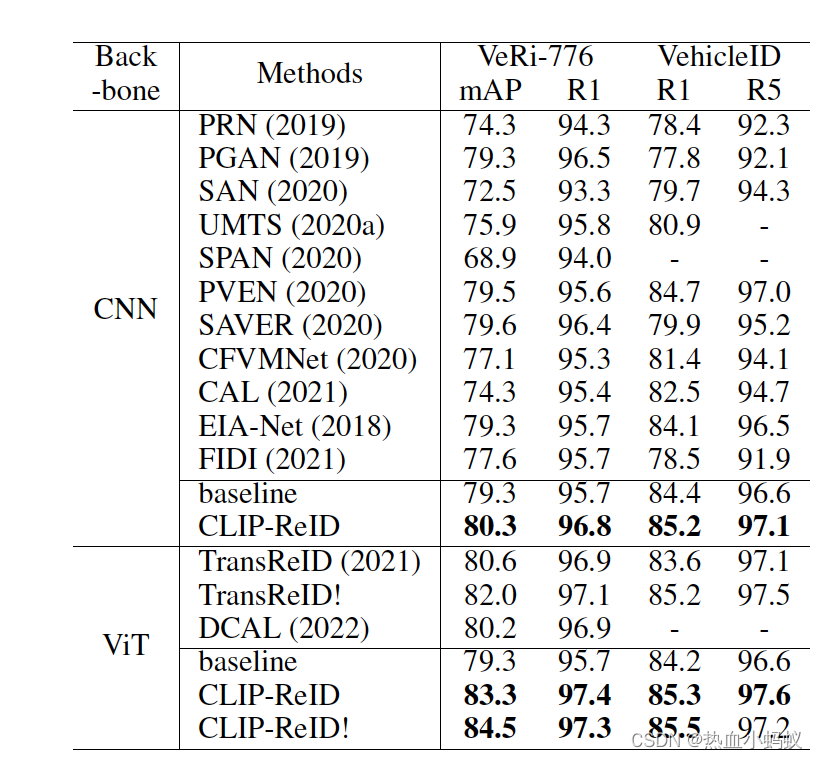
指标
Note: clip_reid在VeRi-776上的指标上mAP达到84.5,Rank-1达到97.3.(同时该指标并未加re-rank), 其指标在2024年也是非常有竞争力的。
Demo Show
-
设计GUI,画交互图和UI.



-
trainning的checkpoint删除梯度等信息转化为跨平台的inference模型(onnx,加速一倍)
-
串联pipeline,参考设计模式,多线程/异步/同步/数据库同步等
-
设计测试用例,测试debug
模型选择:
A. reid_vehicle_id.onnx 模型是在 VehicleID 数据集上训练的,但由于缺少跨镜头的训练数据,其在具有不同视角的车辆检索任务中表现不佳。通常,其检索阈值在约0.2左右。
B.reid_vehicle_veri.onnx 模型则是在 VeRi-776 数据集上训练的,在我们的 demo 测试中表现最佳。一般情况下,其检索阈值在约0.1左右。
结束语
对于创意项目,我会倾向于选择那些具有较大工作量、相对较难且有未来前景的项目进行实现。这也导致完成一个课题项目可能需要2到3个月甚至更长的时间,因此更新的频率会相对较慢。
同时,欢迎大家在评论区留言,分享任何新颖有趣的课题,我将考虑并予以实现。
项目代码和更新地址见我的面包多平台。
要理解我的重识别(ReID)相关代码的解释,需要具备以下基础能力:
- Python基础能力:
- 熟悉Python语法、数据结构、函数和面向对象编程。
- 能够使用Python进行数据处理和简单的算法实现。
- 深度学习的基础知识:
- 理解深度学习的基本概念和原理,如神经网络、反向传播、激活函数等。
- 熟悉深度学习模型的训练和推理过程,包括数据准备、模型定义、训练循环和评估。
- 模型构建的三大要素:
- Dataloader:负责数据加载和预处理,确保数据能够以合适的形式输入到模型中。
- Network:定义神经网络的结构,包括各层的设置、前向传播过程等。
- Loss:定义损失函数,用于衡量模型的预测结果与真实标签之间的差距,并指导模型的参数更新。
如果你正在选择reid这个课题。
我的建议这个课题目前能够继续做的东西不多(能发顶会的东西),大约只有大模型这条路了。目前工业界该方向相对前三年也少了很多人。所以,如果你不得不选择该课题,最好延续大模型这条路做下去。这样你对大模型的知识了解会对后续发展有用。
代码结构总纲领:
- 分为Algorithm和GUI两个文件。Algorithm中的子文件每个都是单独功能的,充分解藕了的。比如,reid就包含detect/extract/search等子文件。GUI则是前端展示的交互和调度逻辑,也被充分解藕,比如,需要修改注册页面的交互在UiPageRegister.py中。
- Algorithm 和 GUI之间也是充分解藕的。什么意思呢?Algorithm下面有个outer_api.py是整个算法所有的对外接口,GUI只能调动outer_api里的结构。如果你只想看算法流程不看GUI的话,只需要看看outer_api就行。
功能解释:
1. 注册界面

选择图片路径->确认按键->车辆检测-> 目标选择->输入注册标签->确认注册->调用reid提特征->注册的sql中(包括图像/特征/ID)
涉及代码: UiPageRegister.py
2. 管理数据界面

选择list行->调取sql->展示信息,支持修改ID和删除某个注册车辆
涉及代码: UiPageManager.py
3. 处理界面

- 选择图像或者视频某个文件: 只处理选择的文件
- 选择文件夹:文件夹下的所有图像或者视频都会被处理
- 三角播放按键:开始去处理选择的文件媒体,再点击就是暂停
- 四角重置按键: 点击重置流程
- 右上角工具按键: device[GPU只支持N卡需要直接配置好驱动和环境], sampleFt[处理视频时抽帧],Match Thresh[匹配时的阈值,两个特征之间的距离小于该阈值时为命中]
Note: 处理视频时, 并开启跟踪时, sampleFt最好设置为1, 因为track跟踪算法会参考位移变化, 抽帧多时,目标位移很大, 会跟踪不上。
自己简单DIY:
1. 前端界面换皮肤
第一种是直接修改GUI.ui下home.py中
self.Main_QF.setStyleSheet(u"QFrame#Main_QF{\n"
"background-color: rgb(129, 129, 129);\n"
"border:0px solid red;\n"
"border-radius:0px\n"
"}")
2. 前端界面模块组件修改
使用QT designer打开GUI.ui.home.ui,使用designer去修改,再 pyside6-uic home.ui > home.py
组件修改完,再修改对应的UiPagexxx.py中的交互流程。
3. 算法想上自己的模型
比如自己的Reid模型(建议把如pth等checkpoint这种模型转换成onnx或者tensorrt, 推理和训练是不一样的,训练时模型会保留梯度等信息且速度不如onnx这种推理架构)
修改reid_extract.py下的class ReIdExtract(object)就行,输入图像输出归一化的特征。
并且在Algorithm.libs.configs.model_cfgs配置文件把模型路径修改一下。


















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











