







普通三维模型能够直观地展示物体的三维全貌,但是在一些场合需要将三维模型变为相应的点云模型进行展示,而使用激光雷达等传感器采集到的点云信息往往只能反应模型表面的情况,或是使用PCL库中的可执行文件进行转换,这两种操作较为麻烦。笔者最近就遇到了这样一个情况,找到了一个名叫CloudCompare(CC)的软件,能够支持将多种文件格式的三维模型转变为点云模型。以下将本人在使用过程中所使用到的一些操作简记下来供朋友们和将来的自己参考。
一、下载
CloudCompare是一款免费软件,其可以在CloudCompare - Downloads下载,可选择下载安装版或者便携版,笔者下载了安装版,安装过程简单且快速。
二、基本设置
(1)隐藏坐标原点
坐标原点的标记无论是在三维模型还是点云模型中都显得十分突兀,为了画面更加好看,可以通过设置隐藏掉坐标原点的标记。设置方法如下:
在工具栏中找到Display-->Display Settings-->Other options,将“Show middle screen cross”选项取消勾选。
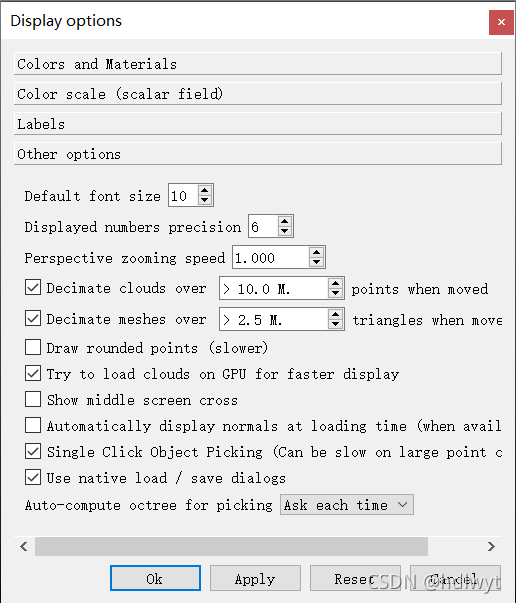
(2)改变背景颜色
为了更好地与点云模型形成对比,需要设置模型界面的背景颜色,设置方法如下:
在工具栏中找到Display-->Display Settings--> Colors and Materials,在右边第三列的Colors选项中点击Background,即可自行更改颜色。
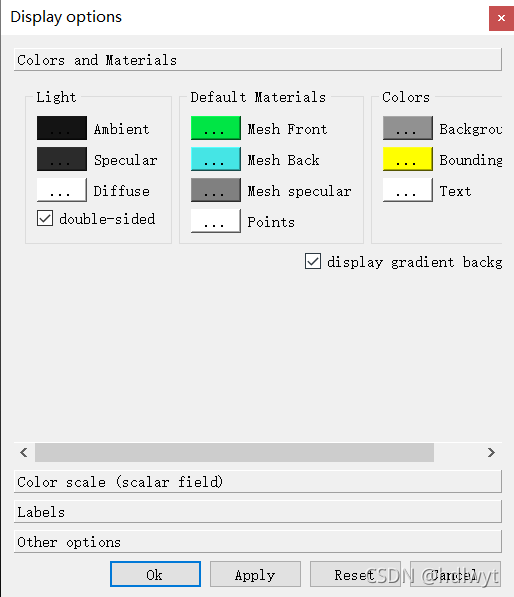
三、三维模型至点云模型转换
(1)导入三维模型
首先准备好三维模型文件,笔者所使用的为.stl文件。在工具栏中找到File-->Open,选择三维模型文件点击打开,即可在CC中看到带转换的三维模型。

(2)导出点云数据
首先在左上角的DB Tree工作区中点击选中Mesh(即我们的模型),接着在工具栏中找到Edit-->Mesh-->Sample points,即可跳出点云采样的相关设置。Points Number表示设置导出点云模型的点总数,Density表示点云模型点的密度,这两项根据需要进行设置,此处我们不改变默认值,其他选项不用设置,点击OK。此时在DB Tree中就出现了一个新的对象,即Mesh.sampled。
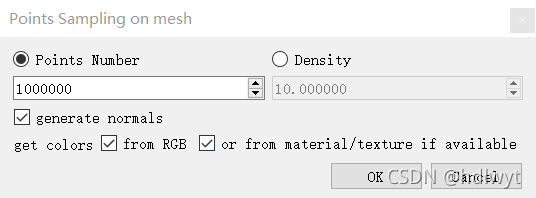
(3)展示点云模型
操作完以上步骤后会发现,点云模型与我们原来的三维模型重合在一起了,使我们很难看清楚我们点云模型的具体效果。因此需要隐藏我们的原始三维模型,此处笔者非常暴力地再DB Tree中选中了三维模型的根目录,点击右键,再点击Delete,此时三维模型就被删除了,仅留下了点云模型,前后效果如下图所示。看到点云模型后我们可能会觉得其点过于密集或过于稀疏,此时就可以重新打开原始的.stl三维模型并重复以上操作,改变(2)中提到的Points Number和Density参数,笔者将Points Number调节为750而Density调节为0.5时达到了我需要的比较好的效果。


(4)保存点云模型
在DB Tree工作区中点击选中我们的点云模型Mesh.sampled,即可进行保存操作,保存类型可以自选,保存成txt文件也可以被重新加载进CC中打开。

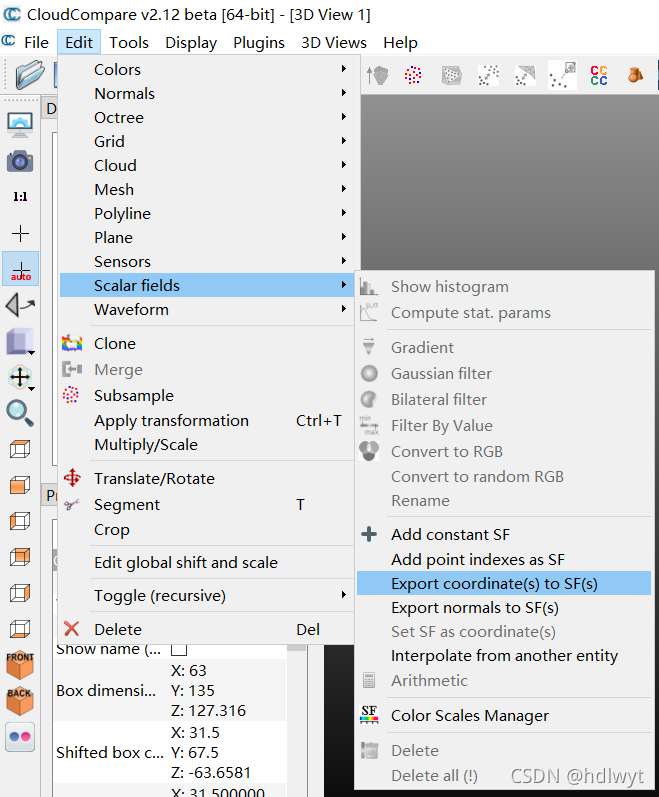
(5)高程颜色渲染
同样在DB Tree工作区中选中点云模型Mesh.sampled,在工具栏中找到Edit-->Scalar fields-->Export coordinate(s) to SF(s),接着选择需要渲染的轴,之后即可显示出渲染后的点云模型。
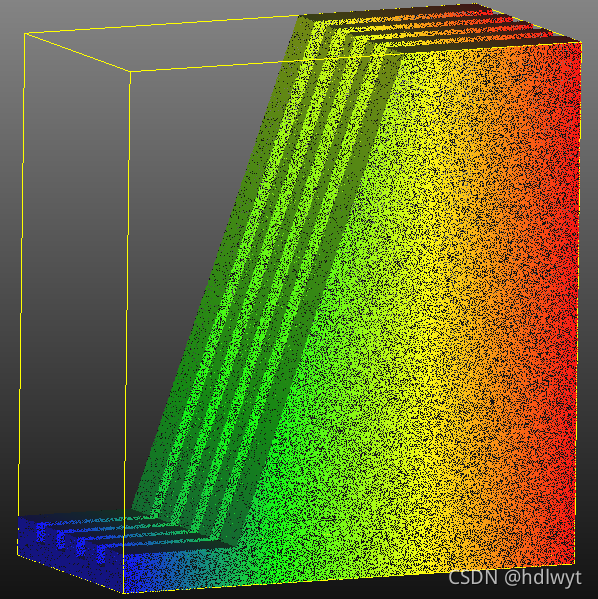
笔者所使用到的功能和操作也仅为上述这些,欢迎朋友们指出错误或提出补充,本人也许在之后写一些文书的时候会使用CC进行一些点云图的绘制。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









