







1.1 YOLO11简介
YOLO11 是 Ultralytics YOLO 系列实时对象检测器的最新版本,最新的YOLOv11模型在之前的YOLO版本引入了新功能和改进,以进一步提高性能和灵活性。YOLO11在快速、准确且易于使用,使其成为各种目标检测和跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
YOLOv11的变化相对于ultralytics公司的上一代作品YOLOv8变化不是很大的,主要改进主要有以下几点:
- C2f变为C3K2
- 在SPPF后面加了一层类似于注意力机制的C2PSA
- 检测头内部替换了两个DWConv
官网YOLOv11在COCO数据集上的性能表现,如下图所示: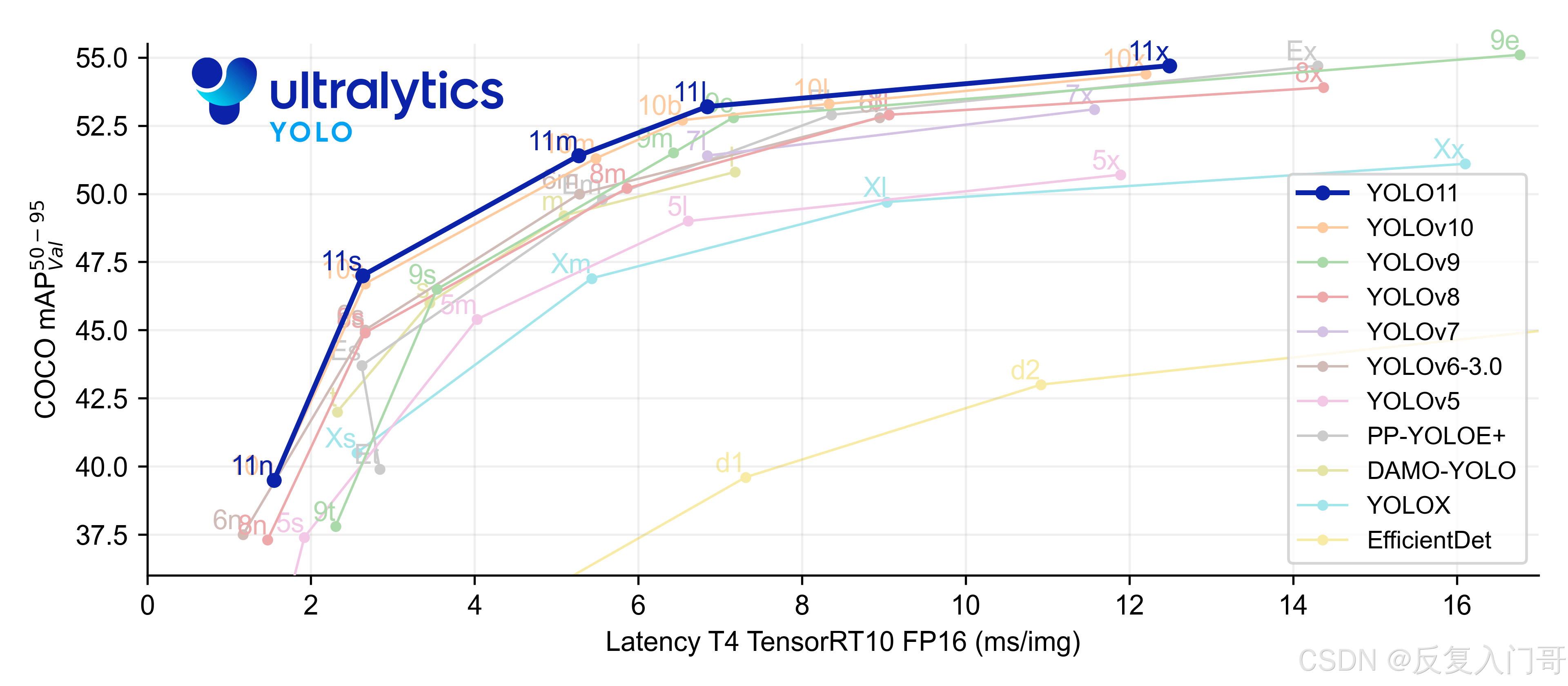
官网源码:yolo11
1.2 与YOLO8的差异体现
下面两张图yolo11.yaml和yolo8.yaml的差异,左边为yolo8的yaml文件,右边为yolo11的yaml文件,从两者对比上主要体现在yolo8的c2f在yolo11替换为C3k2,且在yolo8的backbone的SPPF下一层加入C2PSA
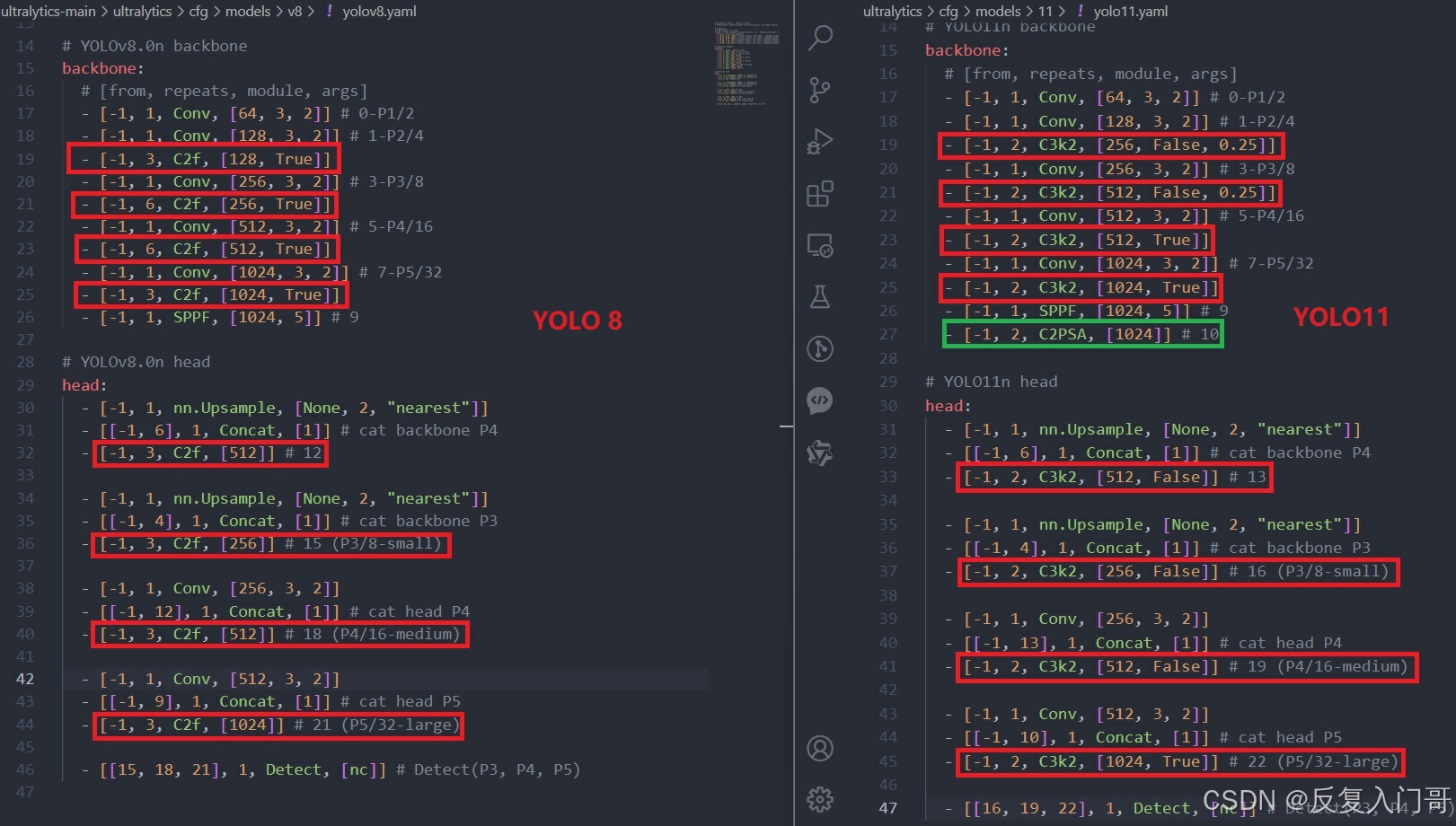
1.3 YOLO11的网络结构
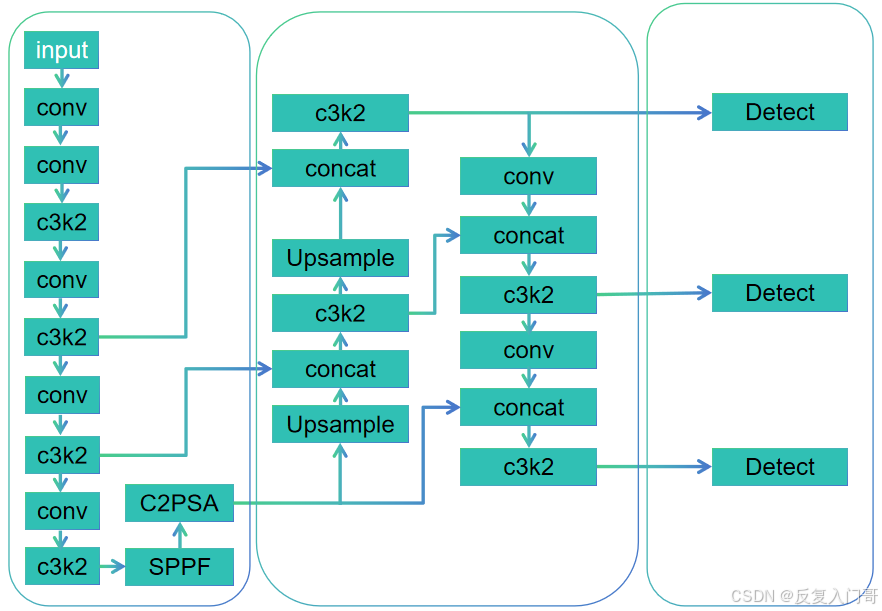
1.4 详解C3k2和C2PSA模块
1.4.1 C3k2模块
C3k2模块是基于C3完成的一个更快速的CSP模块,它是更高效的CSP瓶颈变体。它使用两个卷积代替一个大的卷积,从而加快了特征提取的速度。CSP模块结构如下:
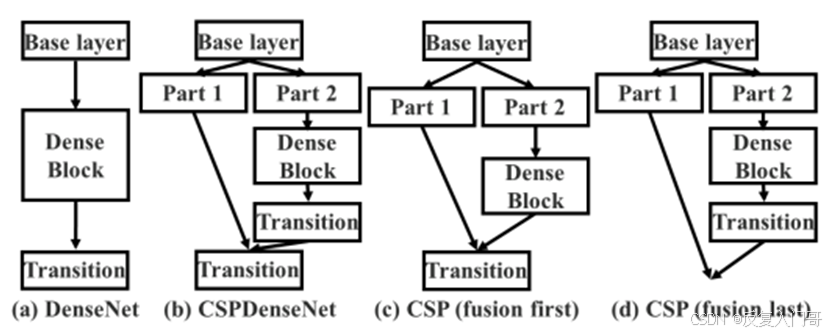
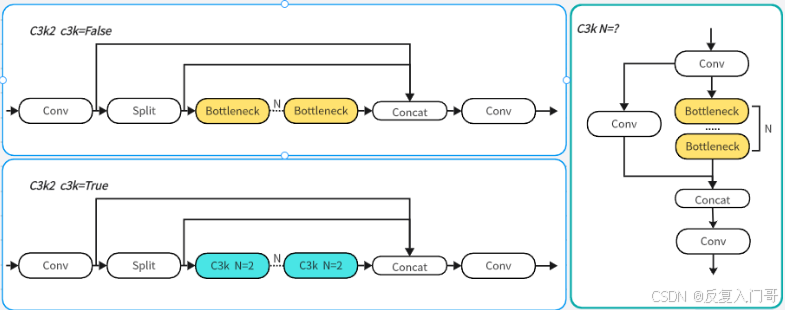
C3K2代码详细解析:
class C3k2(C2f):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
# 调用父类 C2f 的构造函数,初始化基础参数
# c1: 输入通道数
# c2: 输出通道数
# n: 堆叠 Bottleneck 或 C3k 层的数量,默认值为1
# c3k: 如果为 True,则使用 C3k 结构;如果为 False,则使用 Bottleneck 结构
# e: 膨胀系数,默认为 0.5,控制 Bottleneck 内部卷积通道数
# g: 分组卷积的组数,默认为 1
# shortcut: 是否使用残差连接,默认为 True
super().__init__(c1, c2, n, shortcut, g, e)
# self.m: 使用 nn.ModuleList 来存储多层模块的列表
# 根据传入的 c3k 参数决定使用 C3k 模块还是 Bottleneck 模块
# 如果 c3k 为 True,则使用 C3k 模块;否则使用 Bottleneck 模块
# self.c 是从父类 C2f 中继承的计算出的通道数
# 这里会根据 n 的数量创建多个 Bottleneck 或 C3k 模块,组成一个列表
self.m = nn.ModuleList(
# 如果 c3k 为 True,则创建 C3k 模块,输入输出通道都为 self.c,shortcut 和 g 保持一致,卷积核大小为 2
C3k(self.c, self.c, 2, shortcut, g) if c3k else
# 否则,创建 Bottleneck 模块,输入输出通道同样为 self.c,shortcut 和 g 也保持一致
Bottleneck(self.c, self.c, shortcut, g)
for _ in range(n) # 这里根据 n 来创建 n 个模块
)
1.4.1 C2PSA模块
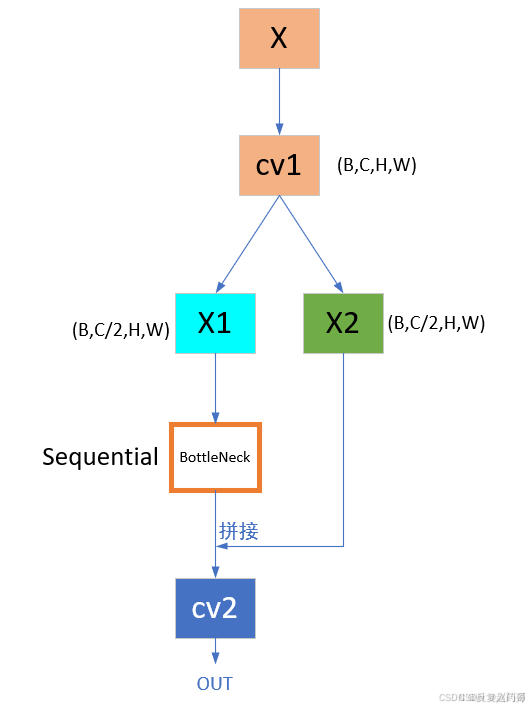
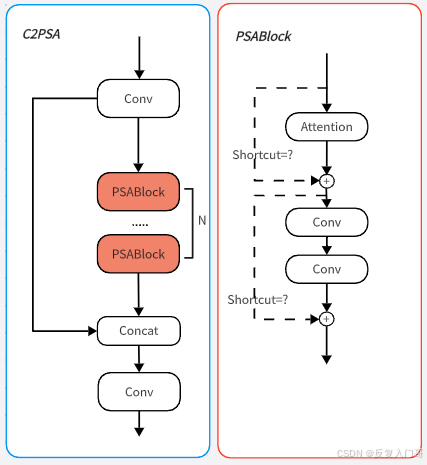
C2PSA机制是一个C2(C2f的前身)机制内部嵌入了一个多头注意力机制,下图为c2模块和C2PSA机制的原理图:
c2模块
C2PSA模块
C2PSA代码详细解析:
class C3k2(C2f):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
# 调用父类 C2f 的构造函数,初始化基础参数
# c1: 输入通道数
# c2: 输出通道数
# n: 堆叠 Bottleneck 或 C3k 层的数量,默认值为1
# c3k: 如果为 True,则使用 C3k 结构;如果为 False,则使用 Bottleneck 结构
# e: 膨胀系数,默认为 0.5,控制 Bottleneck 内部卷积通道数
# g: 分组卷积的组数,默认为 1
# shortcut: 是否使用残差连接,默认为 True
super().__init__(c1, c2, n, shortcut, g, e)
# self.m: 使用 nn.ModuleList 来存储多层模块的列表
# 根据传入的 c3k 参数决定使用 C3k 模块还是 Bottleneck 模块
# 如果 c3k 为 True,则使用 C3k 模块;否则使用 Bottleneck 模块
# self.c 是从父类 C2f 中继承的计算出的通道数
# 这里会根据 n 的数量创建多个 Bottleneck 或 C3k 模块,组成一个列表
self.m = nn.ModuleList(
# 如果 c3k 为 True,则创建 C3k 模块,输入输出通道都为 self.c,shortcut 和 g 保持一致,卷积核大小为 2
C3k(self.c, self.c, 2, shortcut, g) if c3k else
# 否则,创建 Bottleneck 模块,输入输出通道同样为 self.c,shortcut 和 g 也保持一致
Bottleneck(self.c, self.c, shortcut, g)
for _ in range(n) # 这里根据 n 来创建 n 个模块
)
1.5 Detect改进解析
YOLO11解耦头中的分类检测头增加了两个深度可分离卷积DWConv,其目的是为了减少参数量和计算量,具体的对比大家可以看下YOLOv8和YOLOv11的解耦头:
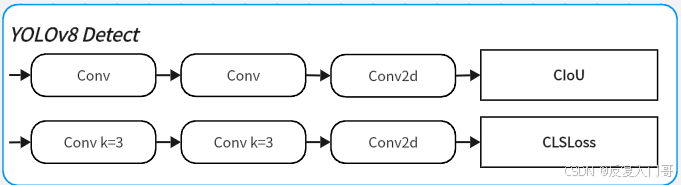

1.6 总结
该博客主要介绍了相较于YOLO8,YOLO11主要创新点,并对YOLO11的创新点做主要剖析,其他的YOLO11细节请读者自行研究!
1.7 其他
YOLO系列算法应用面十分广泛,可以结合一些可落地项目,在项目的基础上进行算法改进完成论文创新撰写,相应的落地应用链接可点击:链接

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









