







本文站在巨人的肩膀上,进行翻译、整理、融合,仅供学习,如有不妥,联系删除。
感谢 Vikas Kookna 大佬的总结,感谢Shiledarbaxi, N.大佬的学术贡献。
一、直观感受
图像中的内容一般可以分为两类:things和stuff。things是可计数的实例目标,有很多个, 例如,人和车,每个实例都有一个唯一的id来区分; stuff指的是无定形的区域,一般最多只有一个,如天空、草地和雪,没有实例id。
这些图像分割技术之间的区别在于它们如何处理图像中的"things"和"stuff"。
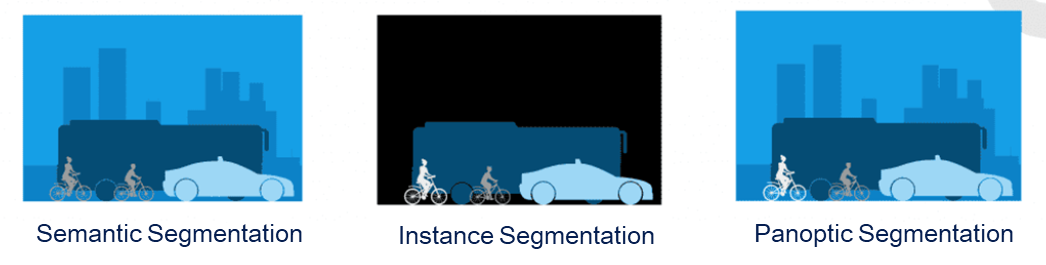 图1-1 三种图像处理技术的直观对比
图1-1 三种图像处理技术的直观对比
1、语义分割是一种将图像中的每个像素分配给特定类别标签的技术,它关注的是图像中的 "stuff" 部分。它通过将相似的纹理区域分配给唯一的类别标签来识别图像中的不同材质或纹理。因此,语义分割可以将图像中的区域分为不同的类别,比如道路、天空、草地等。语义分割的目标是将图像中的每个像素归类到相应的类别中,但它不能区分不同的物体实例。
2、实例分割是在图像中检测并区分不同的物体实例。它通过为每个物体实例分配不同的标识符或掩膜来实现。实例分割的目标是对每个物体实例进行独立的分割,从而可以识别和跟踪图像中的每个物体。实例分割技术通常与目标检测技术相结合,以定位和分割图像中的物体实例。
3、全景分割是一种结合了语义分割和实例分割的综合方法。它既关注图像中的"stuff"部分,也能区分不同的物体实例。全景分割为图像中的每个像素分配一个语义标签和一个唯一的实例标识符。全景分割的目标是同时提供对图像中物体和背景的语义理解以及物体实例的定位和分割。
表1-1 三种技术路线对比
| 图像处理技术 | 方法简介 | 备注 |
| 语义分割 | 为图像中的每个像素分配特定类别标签 | 关注的是图像中的"stuff"部分 |
| 实例分割 | 在图像中检测并区分不同的物体实例 | 关注的是图像中的"stuff"部分 |
| 全景分割 | 结合了语义分割和实例分割的综合方法 | 同时关注"things"和"stuff"两部分 |
综上所述,这三种图像分割技术在处理图像中的"things"和"stuff"方面有所不同。语义分割关注图像中的"stuff",实例分割关注图像中的不同物体实例,而全景分割则综合了这两个方面,同时考虑 "stuff"和物体实例的分割和定位。
二、三者区别
语义分割、实例分割和全景分割之间的区别在于它们如何处理图像中的物体和背景。
1、Semantic segmentation
语义分割研究图像中的无法计数的物体。它分析每个图像像素,并根据它所代表的纹理分配一个唯一的类别标签。例如,在上图中,一张图像包含1辆小汽车、1辆估公交车、2个骑自行车的行人、一条道路和天空。这2个骑自行车的行人代表相同的纹理。
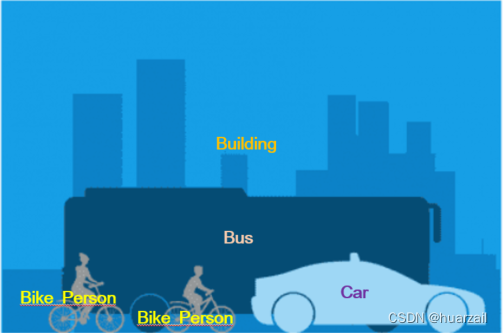
图2-1 语义分割的结果表示
相同的物体具有相同的类别标签
语义分割会为每个纹理或类别分配唯一的类别标签。然而,语义分割的输出不能将这两辆汽车或两个行人分开区分或计数。
常用的语义分割技术包括SegNet(Figure 2-2)、U-Net、DeconvNet和FCNs。

Figure 2-2: Semantic segmentation examples (source: SegNet).
2、Instance segmentation
实例分割通常处理与可计数的物体相关的任务。它可以检测图像中每个物体或类别的实例,并为其分配一个带有唯一标识符的不同掩模或边界框。
例如,在图1-1中,实例分割将分别识别出一辆小汽车、一辆公交车、两个骑自行车的行人(Bike_Person_1和Bike_Person_2)。
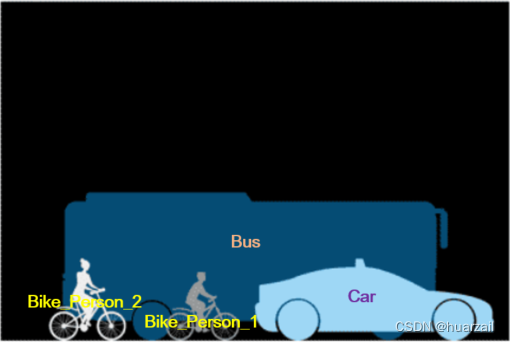
图2-3 实例分割的结果表示
实例分割重点关心前景,相同的类别中不同的物体具有不同的实例ID
常用的实例分割技术包括Mask R-CNN(Figure 2-4)、Faster R-CNN、PANet和YOLACT。图2展示了不同的实例分割检测结果。

Figure 2-4: Instance segmentation examples (source: Mask R-CNN).
3、Panoptic segmentation
语义分割和实例分割技术的目标都是对场景进行连贯处理。自然而然,我们希望在场景中同时识别出物体和背景,以构建更实用的现实世界应用程序。研究人员提出了一种解决方案来统一处理场景中的物体和背景,即全景分割(panoptic segmentation)。
全景分割是两者兼具的最佳方案。它提供了一种统一的图像分割方法,其中场景中的每个像素都被分配了一个语义标签(通过语义分割)和一个唯一的实例标识符(通过实例分割)。
全景分割为每个像素分配了一个语义标签和一个实例标识符的配对。然而,物体之间的像素可能会重叠。在这种情况下,全景分割通过优先考虑物体实例来解决冲突,因为首要目标是识别每个物体而不是背景。
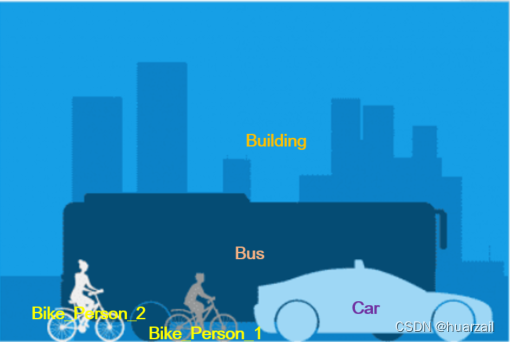
图2-5 全景分割的结果表示
大多数全景分割模型都基于Mask R-CNN方法。其主干架构包括UPSNet、FPSNet(Figure 2-6)、EPSNet和VPSNet。

Figure 2-6: Panoptic segmentation examples (source: FPSNet).
三、评价指标
每种分割技术使用不同的评估指标来评估场景中预测的掩膜或标识符,这是因为stuff和things的处理方式不同。
表3-1 评估指标对比
| 技术 | 方法 | 备注 |
| 语义分割 | 交并比(IoU) | 预测掩膜与真值掩膜之间的相似度 |
| 实例分割 | 平均精确度(AP) | 使用像素级别的IoU来评估每个对象实例 |
| 全景分割 | 全景质量(PQ) | 评估预测的掩膜和实例标识符对于things和stuff的效果 |
1、语义分割通常使用交并比(IoU,也称为Jaccard指数)作为评估指标,它检查预测掩膜与真值掩膜之间的相似度。它确定两个掩膜之间的重叠面积有多少。除了IoU,我们还可以使用Dice系数、像素准确度和平均准确度等指标进行更全面的评估。这些指标不考虑对象级别的标签。
2、实例分割使用平均精确度(AP)作为标准评估指标。AP指标使用像素级别的IoU来评估每个对象实例。
3、全景分割使用全景质量(PQ)指标,评估预测的掩膜和实例标识符对于things和stuff的效果。PQ通过将分割质量(SQ)和识别质量(RQ)两个方面相乘来统一对所有类别的评估。SQ表示匹配段的平均IoU分数,而RQ是使用预测掩膜的精确度和召回率计算的F1分数。
四、实际应用
这三种图像分割技术在计算机视觉和图像处理领域具有重叠的应用。它们共同提供了许多实际应用,帮助人类增加认知的维度。
一些语义分割和实例分割的实际应用包括:
1、自动驾驶车辆:3D语义分割使车辆能够通过识别道路上的不同物体更好地理解环境。同时,实例分割可以识别每个物体实例,提供更深入的计算速度和距离所需的信息。
2、医学扫描分析:这两种技术可以在MRI、CT和X光扫描中识别肿瘤和其他异常。
3、卫星或航空图像:这两种技术提供了一种从太空或高空绘制地图的方法。它们可以描绘出河流、海洋、道路、农田、建筑物等世界上的物体。这类似于它们在场景理解中的应用。
全景分割将自动驾驶车辆的视觉感知提升到了一个新的水平。它产生了像素级准确性的细粒度掩膜,使自动驾驶汽车能够做出更准确的驾驶决策。此外,全景分割在医学图像分析、数据注释、数据增强、无人机遥感、视频监控和人群计数等领域也越来越多地应用。在所有领域中,全景分割在预测掩膜和边界框时提供了更深入和准确的信息。
参考文献:
[2] https://pyimagesearch.com/2022/06/29/semantic-vs-instance-vs-panoptic-segmentation/#TOC

















 3712
3712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









