






《InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation》
论文:https://arxiv.org/abs/2404.02733
代码:https://github.com/InstantStyle/InstantStyle
InstantStyle是InstanX提出的,算法能够生成新的图像,这些图像在感知质量上很高,并且能够将任意照片的内容与众多知名艺术作品的外观结合起来。

MOTIVATION
- 首先,风格的概念本质上是不确定的,它包含色彩、材质、氛围、设计、结构等多种元素。
- 其次,Adapter-free方法在处理自然图像时需要将图像反转回潜在噪声,这可能导致细节的丢失,降低生成图像中的风格信息。此外,这个额外步骤耗时,这在实际应用中可能是一个重要的缺点。综上,基于反演的方法(inversion- based methods)很容易出现风格退化(style degradation),通常会导致细粒度细节的丢失。
- 最后,基于适配器(adapter-based)的方法经常需要对每个参考图像进行细致的权重调整,以实现风格强度和文本可控性之间的平衡,但是可能出现的内容泄漏会导致生成的输出中出现来自参考图像的非风格元素,
- 如何有效地将参考图像中的风格与内容分开是一个挑战,一些方法旨在通过构建配对数据集来解决这个问题,其中同一对象以多种样式表示,从而促进提取解开的样式和内容表示。 然而,由于风格本身的不确定性,大规模配对数据集的创建既需要大量资源,又限制了它可以捕获的风格多样性,反过来又。限制了这些方法的泛化能力
METHODS
contributions
- 特征空间内的风格与内容解耦机制:
这一机制旨在将风格和内容从参考图像中解耦(decouple),以便在生成图像时能够保留文本描述的内容,同时应用参考图像的风格。(其假设是同一空间内的特征可以相互添加或减去)
[A straightforward mechanism that decouples style and con-tent from reference images within the feature space, predicated on the assumption that features within the same space can be either added to or subtracted from one another.] - 仅向风格特定块注入参考图像特征:
将参考图像特征仅注入到特定风格块中,防止风格泄露,避免繁琐的权重调整。这通常是参数较多的设计的特征。
[The injection of reference image features exclusively into style-specific blocks, thereby preventing style leaks and eschewing the need for cumbersome weight tuning, which often charac-terizes more parameter-heavy designs.]
cross-attention layers
(写这段的目的为了加深对attention的印象,可以自行跳过~)
在Transformer的编码器-解码器架构中,编码器负责将输入序列编码为一系列特征向量,而解码器则根据这些特征向量逐步生成输出序列。为了使解码器能够对当前生成位置的上下文进行有效的建模,CrossAttention层被引入其中。
- 输入:两个序列,这两个序列必须具有相同的维度。
- 一个序列作为输入的Q(query),定义了输出的序列长度;另一个序列提供输入的K(key)和V(value)
- 注意:Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列
- 输出:输出是经过注意力权重加权求和后得到的交叉注意力输出。输出向量包含了来自不同输入序列或模态的信息的整合结果,反映了它们之间的关联关系
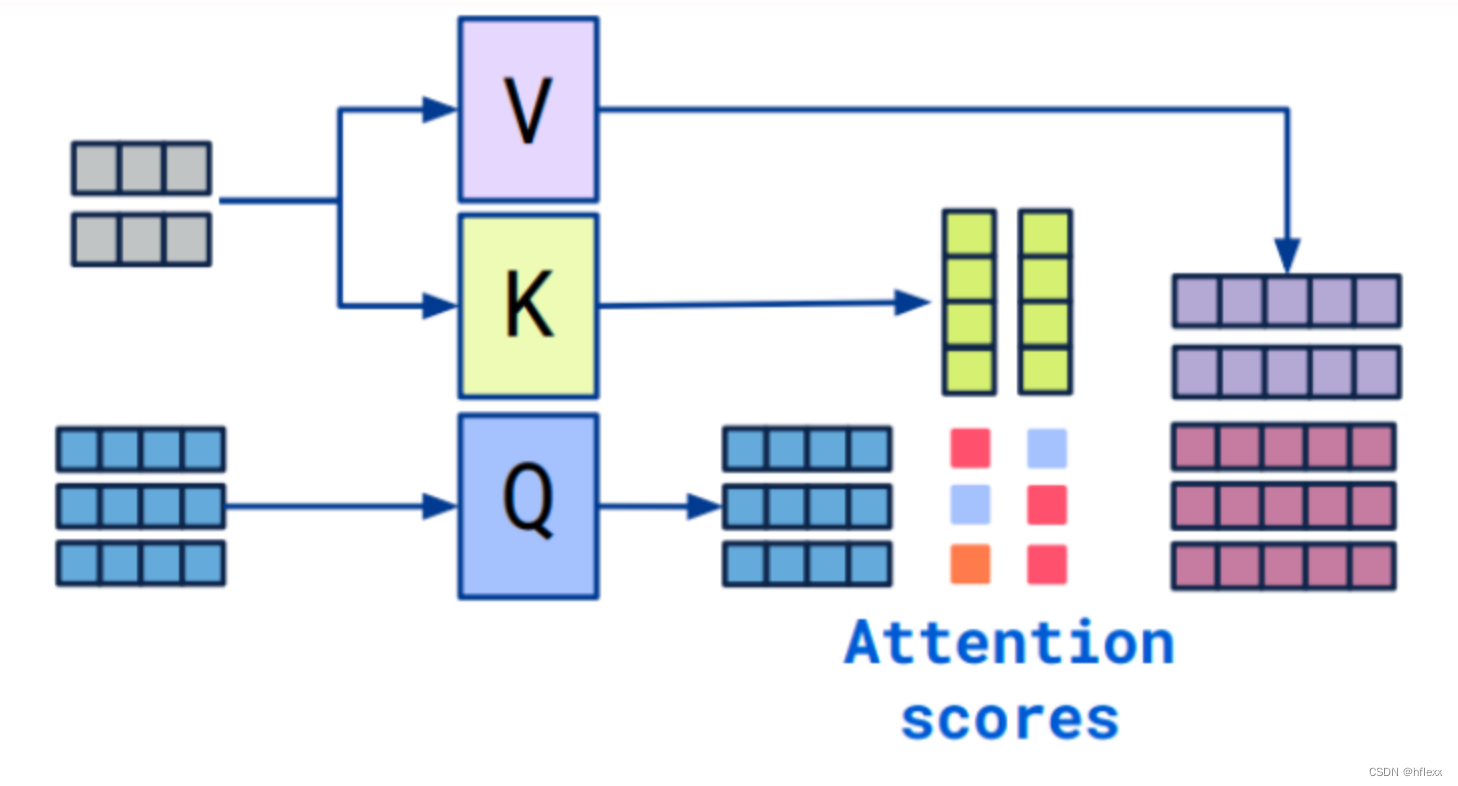
- Cross-attention算法
softmax ( ( W Q S 2 ) ( W K S 1 ) T ) W V S 1 \operatorname{softmax}\left(\left(W_{Q} S_{2}\right)\left(W_{K} S_{1}\right)^{T}\right) W_{V} S_{1} softmax((WQS2)(WKS1)T)WVS1- S1,S2:两个具有相同维度的序列,输出的序列长度与S2一致
- 计算S2的K和V;计算S1的Q
- 使用Q,K计算注意力矩阵,得到二者之间的相关性
- 将V应用于注意力矩阵:将注意力分数与值向量 V 相乘并求和,得到最终的输出序列
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, query_dim, context_dim):
super(CrossAttention, self).__init__()
self.query_dim = query_dim
self.context_dim = context_dim
# 定义线性层,用于将查询向量和上下文向量进行线性变换
self.linear_q = nn.Linear(query_dim, query_dim)
self.linear_c = nn.Linear(context_dim, query_dim)
def forward(self, query, context):
# 将查询向量通过线性变换得到查询投影
query_proj = self.linear_q(query) # [batch_size, query_len, query_dim]
# 将上下文向量通过线性变换得到上下文投影
context_proj = self.linear_c(context) # [batch_size, context_len, query_dim]
# 计算注意力权重,使用点积操作得到注意力分数
attention_weights = torch.bmm(query_proj, context_proj.transpose(1, 2)) # [batch_size, query_len, context_len]
# 对注意力分数进行softmax操作,得到注意力权重
attention_weights = F.softmax(attention_weights, dim=-1)
# 将注意力权重与上下文向量进行加权求和,得到经过注意力调整后的上下文向量
attended_context = torch.bmm(attention_weights, context) # [batch_size, query_len, context_dim]
# 返回经过注意力调整后的上下文向量和注意力权重
return attended_context, attention_weights
IP-adapter
IP-Adapter是文本兼容图像提示适配器,用于实现预训练文本到图像扩散模型的图像提示功能。IP-Adapter通过引入图像提示,使得模型能够直接理解图像内容,从而更有效地生成与用户意图相符的图像。
具体而言,IP-Adapter对文本特征和图像特征采用解耦的交叉注意力机制,将文本特征和图像特征的交叉注意力层分开。对于扩散模型的UNet中的每个交叉注意力层,仅为图像特征添加一个额外的交叉注意力层。在训练阶段,只训练新的交叉注意力层的参数,而原来的UNet模型保持冻结状态。 IP-adapter是轻量级的,非常高效:只有22M参数的IP适配器的生成性能可与文本到图像扩散模型中完全微调的图像提示模型相媲美。
IP-adapter论文: https://arxiv.org/pdf/2308.06721.pdf
IP-adapter代码:https://github.com/tencent-ailab/IP-Adapter
Separating Content from Image
与风格的不确定属性相比,内容通常可以用自然文本来表示,因此我们使用CLIP的文本编码器来提取内容文本的特征作为内容(content)表示。 同时,我们使用 CLIP 的图像编码器来提取参考图像(reference image)的特征。 CLIP对于全局特征拥有良好的表示,故从图像特征中减去内容文本特征后,可以显式地解耦风格和内容。
CLIP的讲解可以跳转到这篇博客: AIGC-《Learning Transferable Visual Models From
Natural Language Supervision》
CLIP论文概述
Injecting into Style Blocks Only
通过实验发现blocks.0,attentions.1和down blocks.2,.attentions.1捕捉风格(颜色、材质、氛围)和空间布局(结构、构图),由于因为已经找到了样式块,我们可以将图像特征注入到这些块中,以实现无缝的样式迁移。
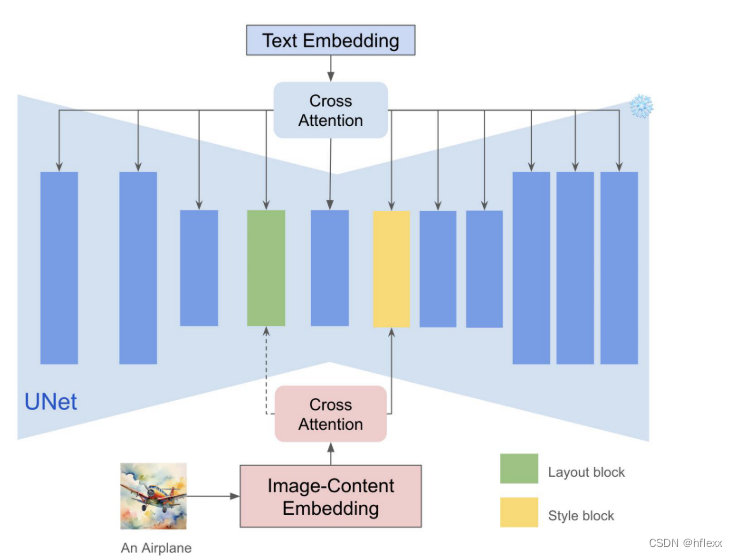
- 11 transformer blocks with SDXL
- 4 for downsample blocks
- 1 for middle block
- 6 for upsample blocks
- 发现第四块和第六块分别对应于布局(layout)和风格(style)。只有当layout是style的一部分时,布局才重要。
实验效果
instantx团队已经在稳定扩散 XL (SDXL) 上实现了他们的方法方法。instantx团队使用常用的预训练 IP 适配器作为示例来验证他们的方法,对于图像特征,他们静音(mute out)除样式块之外的所有块。 他们还按照其官方训练设置在 4M 大规模文本图像配对数据集上从头开始训练 IP-Adapter (SDXL 1.0),而不是训练所有块,在他们的情况下,仅更新样式块。 发现这两种设置达到了非常相似的风格化结果,因此为了方便起见,我们接下来的实验都是基于预训练的 IP-Adapter 的,无需进一步微调。
基于文本的图像风格化:对不同内容的各种样式进行了大量的样式迁移实验。 图像结果显示了风格迁移结果。 由于图像信息仅注入到样式块中,因此大大减轻了内容泄漏,并且不需要仔细调整权重。 这些结果并不是经过精心挑选的。

基于图像的图像风格化:采用 ControlNet (Canny) 来实现基于图像的空间控制风格化来进行对比

方法对比:对于基线,instantx团队将他们的方法与最近最先进的风格化方法进行比较,包括 StyleAlign、Swapping Self-Attention、B-LoRA 和具有权重调整的原始 IP-Adapter。 对于 B-LoRA,他们使用官方训练设置对单一参考风格图像进行训练。
从不同的角度来看,每种方法的风格定义是不同的



















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









