







Diffusion Policy 项目主页 https://diffusion-policy.cs.columbia.edu/
集成框架 集成矿建https://github.com/huggingface/lerobot
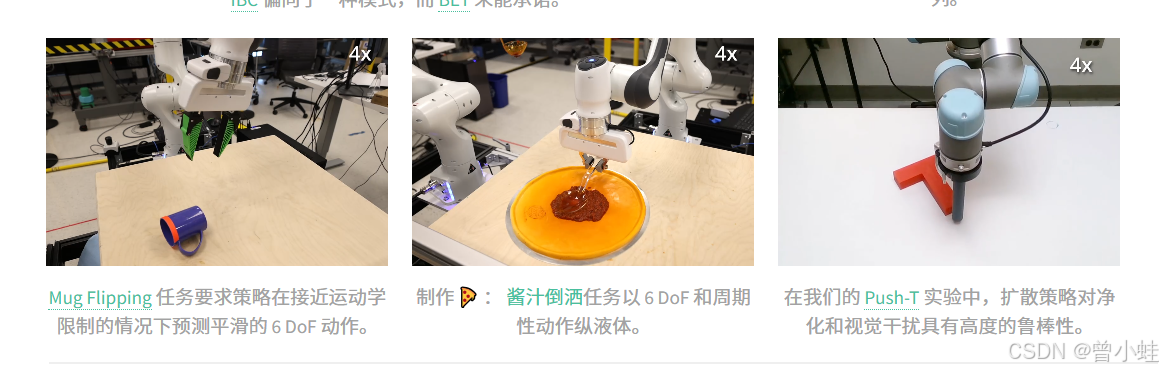
【LeRobot】中文字幕|Diffusion Policy: LeRobot Research Presentation 2 by Cheng Chi
一、 简介——扩散策略
策略的输出是一系列使用扩散模型生成的动作.
关键词:模仿学习(lmitation)、视觉运动策略(visuomotor policy)、操作(visuomotor)
本文介绍了扩散策略,这是一种通过将机器人的视觉运动策略表示为条件去噪扩散过程来生成机器人行为(generating robot behavior)的新方法。我们对来自 4 个不同机器人作基准的 12 个不同任务的 Diffusion Policy 进行了基准测试,发现它始终优于现有的最先进的机器人学习方法,平均提高了 46.9%。Diffusion Policy 学习动作分布评分函数的梯度,并在推理过程中通过一系列随机 Langevin 动力学步骤针对该梯度场进行迭代优化。我们发现,当用于机器人策略时,扩散公式产生了强大的优势,包括优雅地处理多模态动作分布,适用于高维动作空间,并表现出令人印象深刻的训练稳定性。为了充分释放扩散模型在物理机器人上视觉运动策略学习的潜力,本文提出了一系列关键的技术贡献,包括
- 合并后退水平控制、 (incorporation of receding horizon control)
- 视觉调节 (visual conditioning)
- 时间序列扩散转换器。 (time-series diffusion transformer)
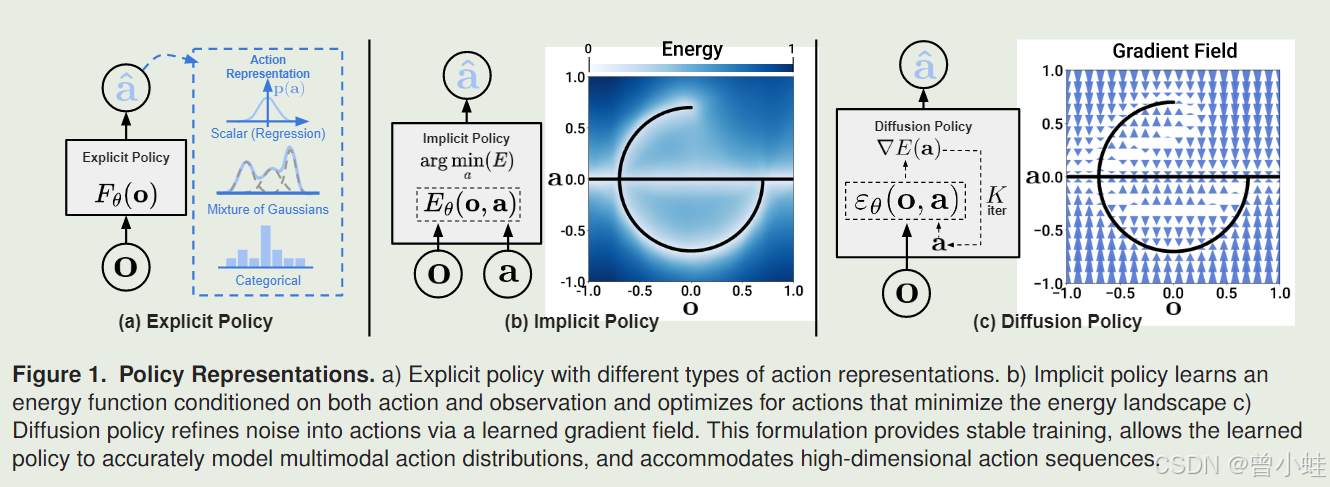
训练完成后的去噪过程,还可以从失败中恢复以及对扰动和遮挡的鲁棒性
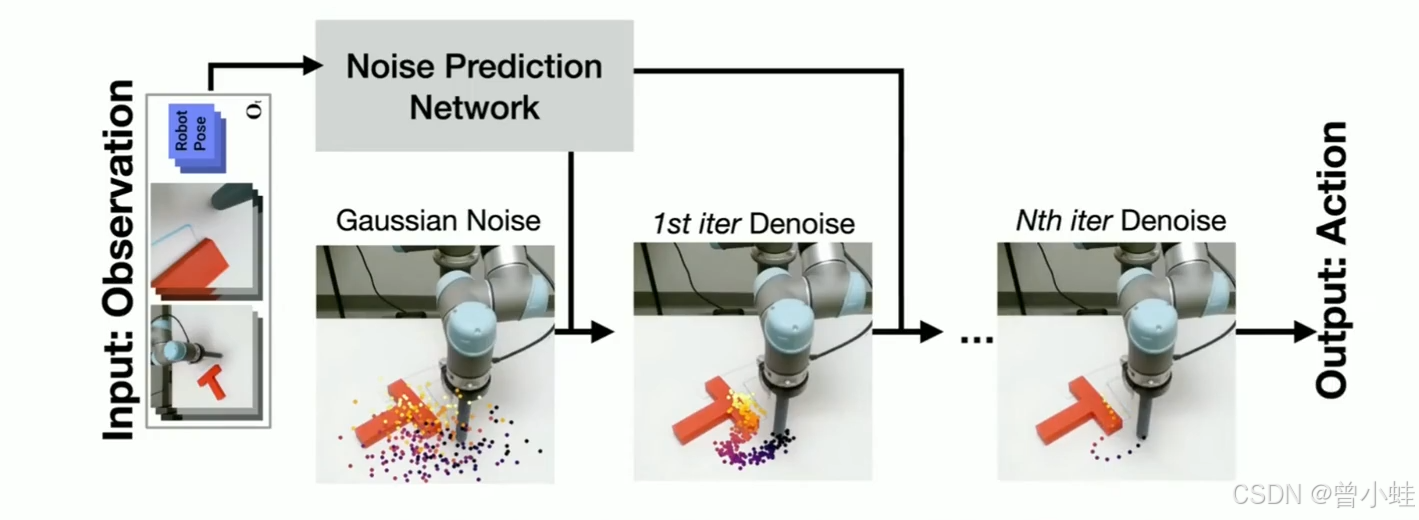

二、方法概述
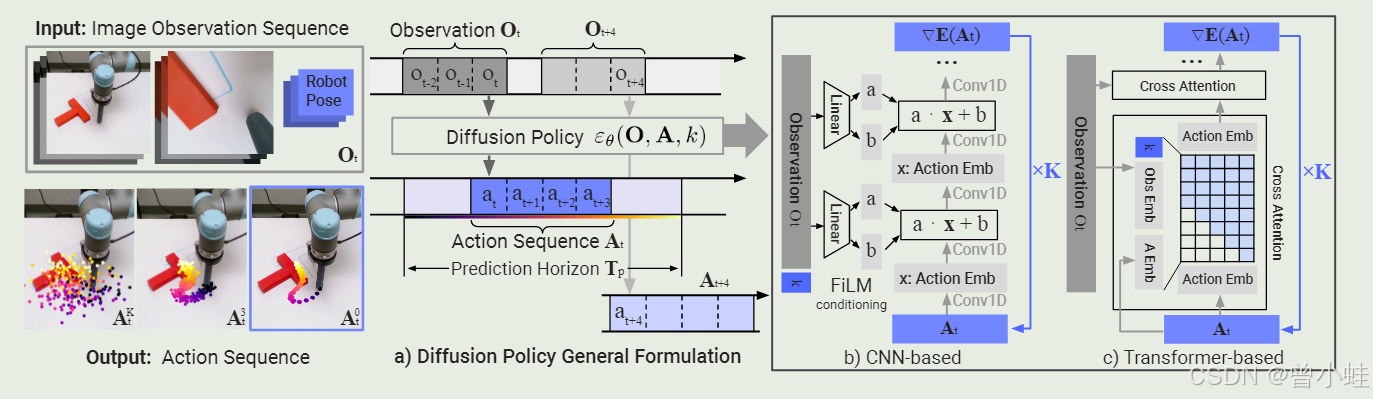
扩散策略概述 a) 一般公式。在时间步 t,该策略将观测数据 Ot 的最新 To 步作为输入并输出动作 At 的 Ta 步。b) 在基于 CNN 的扩散策略中,FiLM(特征线性调制) 对观察特征 Ot 的条件应用于每个卷积层,通道。从高斯噪声中提取的AK t开始,减去噪声预测网络εθ的输出,重复K次得到A0t,去噪动作序列。c) 在基于 Transformer 扩散策略,观察 Ot 的嵌入被传递到每个变压器解码器块的多头交叉注意力层。每个动作嵌入都被限制为仅使用说明的注意力掩码关注自身和先前的动作嵌入(因果注意力)。



















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











