







0. 前言
- 相关资料
- 官方资料:论文,官网,竞赛链接(2021.9.1)
- 发布时间:ICCV 2021
- 发布机构:南京大学
- 一句话总结:基于篮球、足球、体操、排球赛事的大型时空行为检测数据集。
- 本数据集是 DeeperAction Workshop 三个赛道之一。
- 数据集获取方式就是到竞赛链接下载(要先注册+申请)。
- 下在下来的数据类似于 UCF101-24 和 JHMDB,包括一个pkl文件和一系列视频
- pkl文件的格式如下
Data Format
Here we assume that the ground thruth file multisports_GT.pkl exists as a cache. The cache is a dictionary with the following keys:
labels: list of labels
train_videos: a list with n splits elements, each one containing the list of training videos
test_videos: item for the validation videos
nframes: dictionary that gives the number of frames for each video
resolution: dictionary that output a tuple (h,w) of the resolution for each video
gttubes: dictionary that contains the gt tubes for each video. Gttubes are dictionary that associates from each index of label, a list of tubes. A tube is a numpy array with nframes rows and 5 columns, <frame number> <x1> <y1> <x2> <y2>.
- 其实,这个数据集的论文可以看做是当前时空行为检测的综述。
1. 时空行为检测数据集现状
- 当前的时空行为检测数据集可以分为两类:
- Densely annotated,即每一帧都标注
- Sparsely annotated,隔一段时间(例如1秒)标注一帧
- 标注内容都是类似的,包括人物bbox、以及对应的人物id与行为
- Densely annotated dataset
- 常见的就是 J-HMDB 和 UCF101-24,之前有写过笔记
- 一般来说,相关模型都带有人物跟踪的功能。
- 上述两个数据集的主要问题在于:
- 标签质量低:我写过可视化脚本,可以看到bbox的质量一般般
- 数据集不够复杂:行为类别过于粗糙,很多时候看背景就能知道行为类别
- Sparsely annotated
- 总结来说,一个理想的时空行为检测数据集应该:
- 第一,应该弱化背景信息以及人物姿态(或者说,静态动作)对判断人类动态行为的影响。
- 换句话说,最好不是看静态图片就能判断动作,比如"骑自行车"、“打篮球”这种粗糙的标签。
- 最好就是一张图中有多个人做不同的动作(细粒度动作也行)。
- 第二,行为应该有良好的时间边界
- 第三,行为类别需要好好考虑,应尽量满足 modeling subtle human pose motions, long-term semantics, possible interactions between humans, objects and scenes, and reasoning
- 第一,应该弱化背景信息以及人物姿态(或者说,静态动作)对判断人类动态行为的影响。
2 MultiSports 介绍
- MultiSprots,是 Multi-person Sports Actions 的缩写
- 大型、高质量时空行为检测数据集
- 有25fps的逐帧标签,每个行为有清晰的时间边界
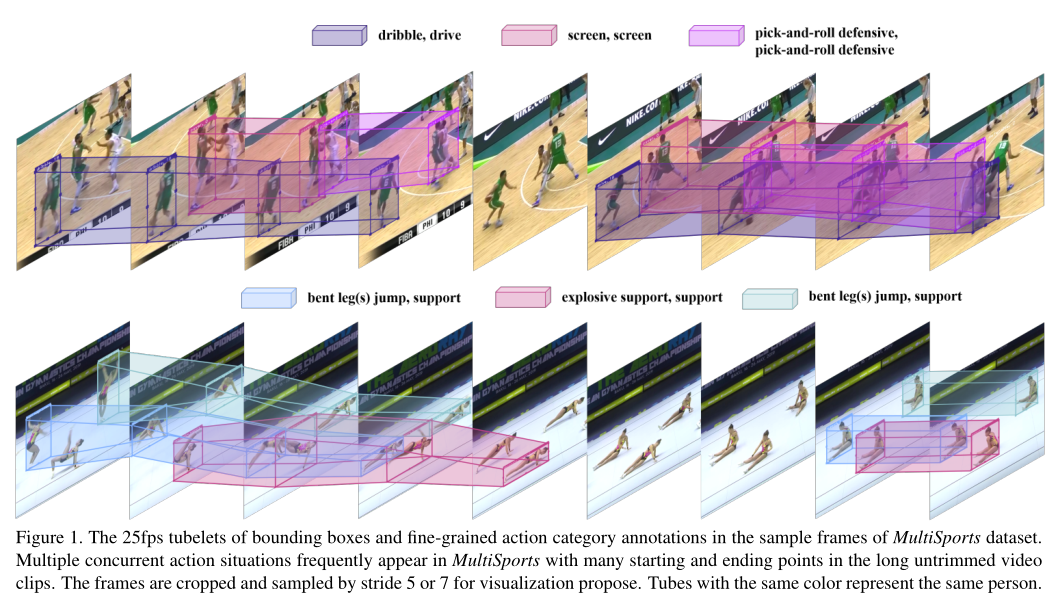
- 为什么选择体育赛事视频
- 第一,动作有明确的定义
- 第二,有大量不同动作同时进行(使得数据集的复杂度提高)
- 第三,背景信息并没有太大作用,使得模型可以更加关注行为本身
- 第四,人-物-场景之间的关系非常重要(比如要判断人在球场中的位置,才能判断一次投篮是2分还是3分)
- 数据集构建过程
- 第一步,Action Vocabulary Generation,选择合适的行为类别
- 由于需要多人场景,所以选择了篮球、足球、排球、体操(aerobic gymnastics)。
- 对于三大球:先让专业运动员文字说明各类动作的边界定义,然后让少量普通人尝试标注,明确各类动作的定义与边界
- 没有标注一些日常行为(comman actions,如站、坐等),就是为了行为边界明确
- 不考虑犯规动作,因为犯规动作一般是看裁判的动作,而跟球员关系不太大
- 只选择difficulty elements,忽略 movement patterns。这一句其实不是特别懂。作者回复如下
- 第一步,Action Vocabulary Generation,选择合适的行为类别
“只选择difficulty elements,忽略 movement patterns”主要针对体操运动,体操我们使用了官方的得分手册来制定类别体系,在体操的得分手册中主要定义了两种动作:难度动作(例如explosive support)和普通的过度动作(例如跑,跳),一般来说作为human actions来说这两种都应该算作动作类别当中,但是为了动作边界清晰,我们只选择了一些难度动作(difficulty elements)算作multisports数据集的动作类别中进行标注,这些动作在评分手册里面有非常详细的定义,因此边界没有歧义。
- 第二步,数据准备(寻找合适的视频)
- 在油管上选择最近相关赛事的高清视频
- 将视频分为若干小段,去掉镜头转换的部分
- 第三步,标注行为
- 首先,请专业运动员标注每个动作的起始帧与结尾帧,并标注起始帧中的对应人物的bbox。
- 之后,通过众包实现tube中其他bbox的标注。
- 第四步,标注人物跟踪标签,即person id
- 使用 FCOT 自动标注,再人工调整
- 第五步,质量管理
- 标注第一步,至少有一个专业运动员进行质检
- 标注第二步,通过5fps视频来检查
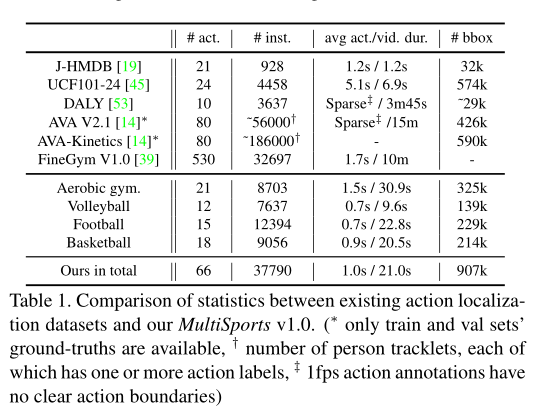
3 现有时空行为检测数据集统计与对比
- 下图从行为类别数量(#act.)、样本数量(# inst.应该指的是tube的数量,AVA没有tube,指的是一张图片中bbox的数量、平均单个tube持续时间(avg act. dur,AVA不存在该样本)、视频平均长度(avg vid. dur)、bbox 数量
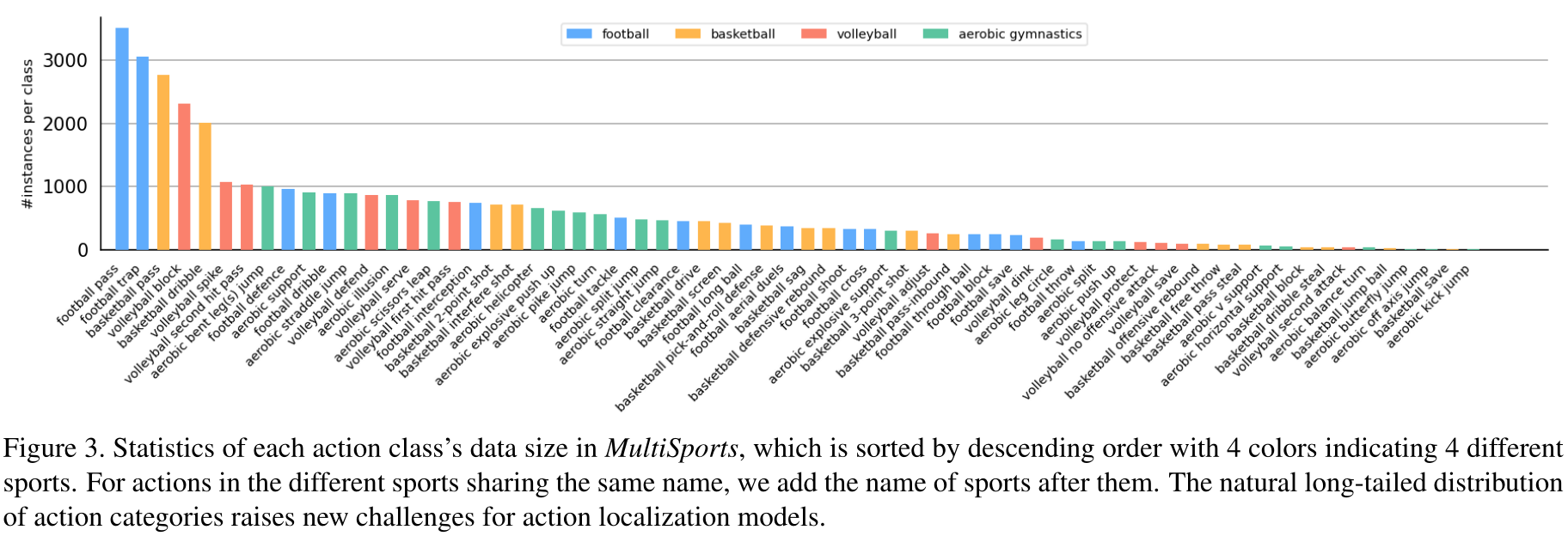
- MultiSports 类别分布是长尾的
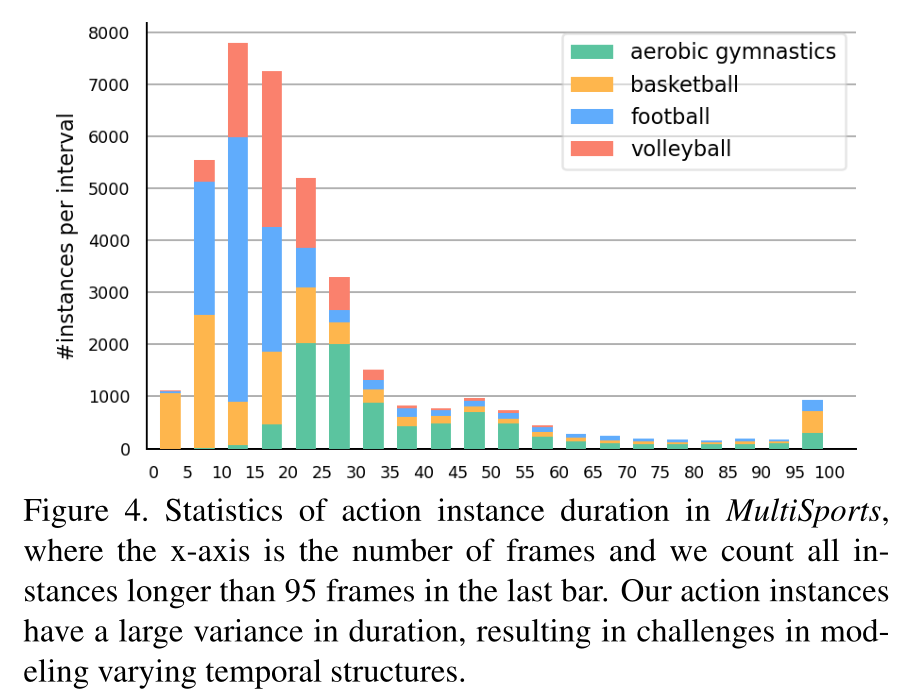
- MultiSports 中每个样本的长度分布,可以看到,短视频还是多数
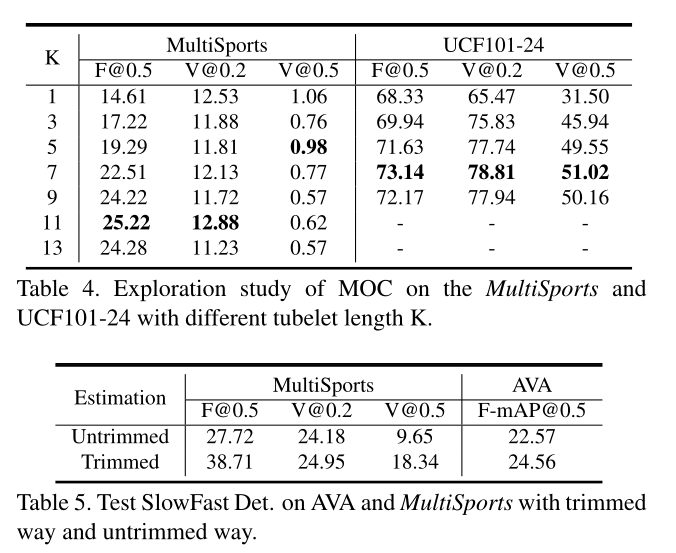
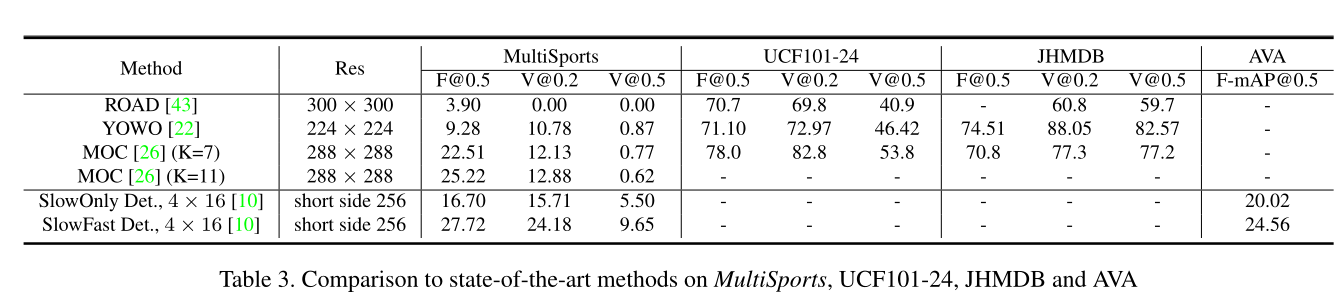
4 实验结果
-
MultiSports 数据集预处理
- 选择 val set 中样本数量大于25的类别,共60类,进行测试。
- 视频720P
- 数据集统计: 训练集 18422 个样本,1574 个视频;验证集 6577 个样本,555个视频。
-
性能指标
- frame-mAP:IoU阈值选择0.5
- video-mAP:使用3D IoU,即 the temporal domain IoU of two tracks, multiplied by the average of the IoU between the overlapping frames
- 时间维度 IoU(1维)* 重叠帧平均IoU
- IoU阈值分别是 0.2 和 0.5
-
结果如下图
- 所谓 trimmed 就是只在有标签的frames中进行测试,untrimmed 就是在没有标签的frame中也进行测试
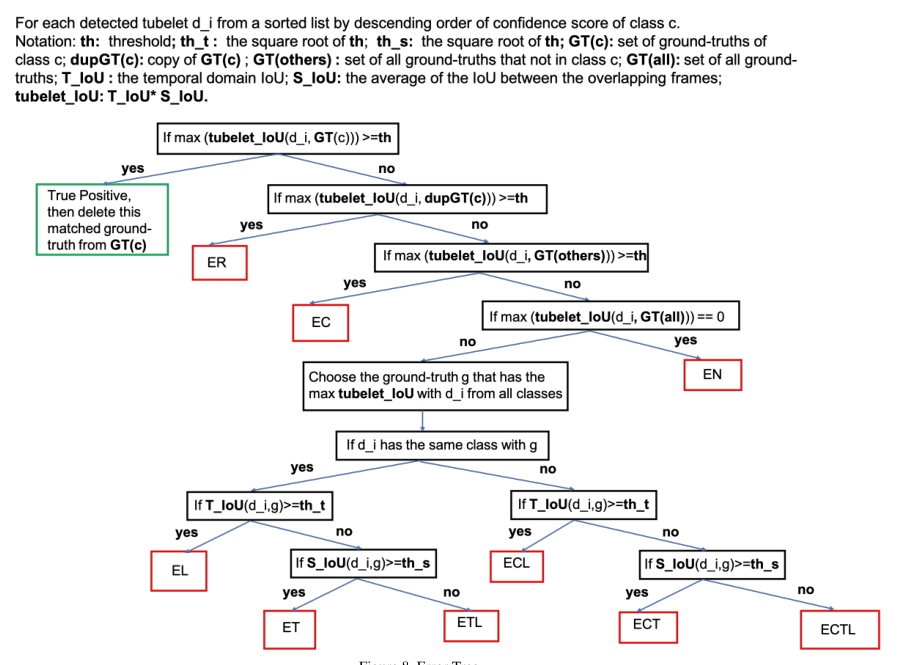
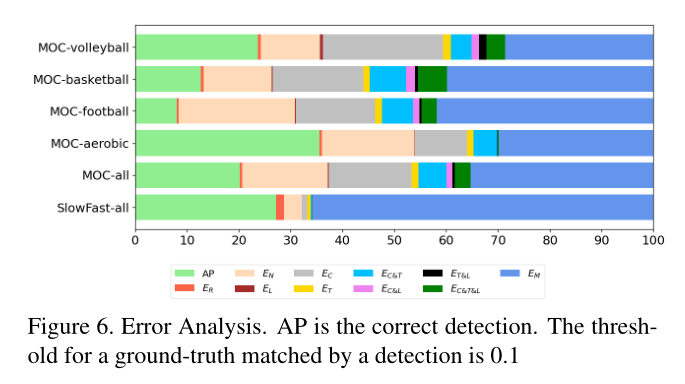
- 错误分析:首先定义有哪些错误类型,再查看每类错误的占比
- E R E_R ER 已经有匹配结果了
- E N E_N EN 预测结果与任何GT都不匹配
- E L E_L EL 行为、空间预测都准,但spatial localization不准
- E C E_C EC 行为class不准,时空都准
- E T E_T ET 行为、空间都准,时间不准
- 上面三类错误的各种排列组合, 如 E L C / L T / C T / L C T E_{LC/LT/CT/LCT} ELC/LT/CT/LCT
- E M E_M EM 就是没有匹配的结果
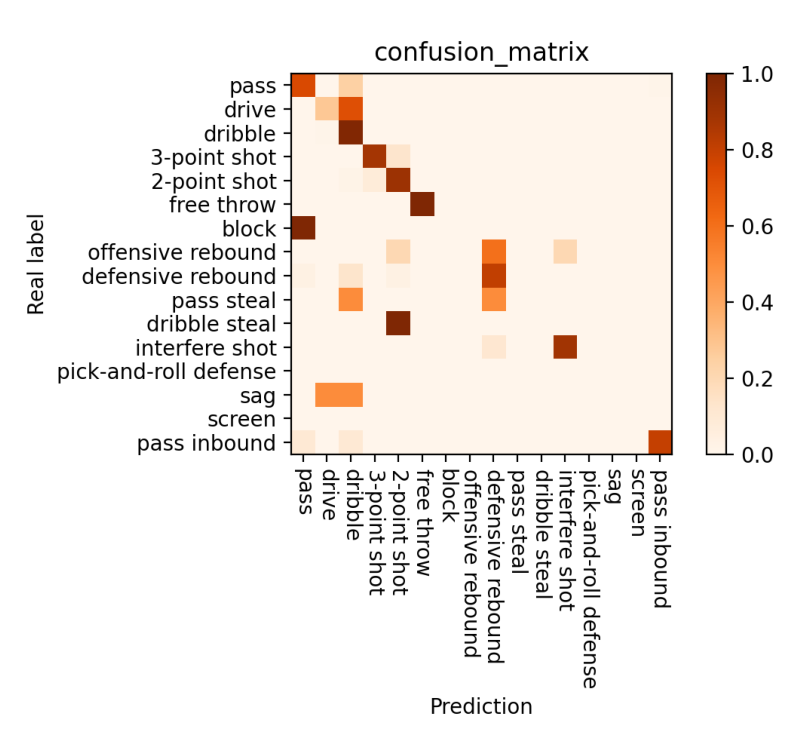
- 混淆矩阵更清晰,比如下图中可以看出,block都被预测为pass了

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









