







文章目录
随着模型参数规模与数据规模的不断扩展,如何在有限的计算资源下高效地训练模型已经成为制约大语言模型研发的关键技术挑战。
其中,主要面临着两个技术问题:一是如何提高训练效率;二是如何将庞大的模型有效地加载到不同的处理器中。
本文我们将介绍几种常见的高效训练技术,包括 3D 并行训练、激活重计算和混合精度训练。
一、高效训练技术
1. 并行训练
3D 并行策略实际上是三种常用的并行训练技术的组合,即数据并行(Data Parallelism)、管道并行(Pipeline Parallelism)和张量并行(Tensor Parallelism)。有的工作也会使用模型并行一词,它同时包括了张量并行和管道并行。
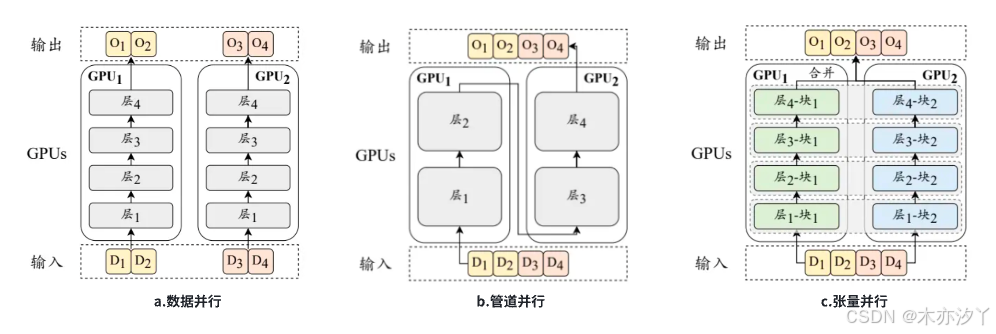
1.1. 数据并行(DP)
数据并行是一种提高训练吞吐量的方法,它将模型参数和优化器状态复制到多个 GPU 上,然后将训练数据平均分配到这些 GPU 上。这样,每个GPU 只需要处理分配给它的数据,然后执行前向传播和反向传播以获取梯度。当所有 GPU 都执行完毕后,该策略会将不同 GPU 的梯度进行平均,以得到整体的梯度来统一更新所有 GPU 上的模型参数。如图a所示,四条数据被分成两份,由两张卡进行分别计算,然后我们会将两张卡的梯度进行平均后再更新模型,这样便等效于执行了批次为 4 的梯度更新。鉴于梯度计算在不同 GPU 上的独立性,数据并行机制展现出高度的可扩展性,可以通过增加 GPU 数量来提高训练效率。数据并行技术的实现相对简便,目前多数深度学习库均已内置了对数据并行策略的支持,例如 TensorFlow 和 PyTorch。
1.2. 管道并行(PP)
也称流水线并行,旨在将大语言模型不同层的参数分配到不同的GPU 上。在实践中,可以将 Transformer 连续的层加载到同一 GPU 上,以减少GPU 之间传输隐藏状态或梯度的成本。例如,在图b中,Transformer 的第 1-2层部署在 1 号 GPU,将 3-4 层部署在 2 号 GPU。然而,朴素的流水线调度并不能达到真正的并行效果。以图b为例,1 号 GPU 在前向传播后需要等待 2 号 GPU反向传播的结果才能进行梯度传播,因此整个流程是“1 号前向-2 号前向-2 号反向-1 号反向”的串行操作,大大降低了 GPU 的利用率。为了解决这一问题,管道并行通常需要配合梯度累积(Gradient Accumulation)技术进行优化。该技术的主要思想是,计算一个批次的梯度后不立刻更新模型参数,而是累积几个批次后再更新,这样便可以在不增加显存消耗的情况下模拟更大的批次。在管道并行中使用了梯度累积后,1 号卡前向传播完第一个批次后,便可以不用等待,继续传播第二个和后续的批次,从而提高了流水线的效率。
1.3. 张量并行(TP)
张量并行与管道并行是两种将大模型参数加载到多个 GPU 上的训练技术。管道并行侧重于将模型的不同层分配到不同的 GPU 上。相较之下,张量并行的分配粒度更细,它进一步分解了模型的参数张量(即参数矩阵),以便更高效地利用多个 GPU 的并行计算能力。具体地,对于大语言模型中的某个矩阵乘法操作 ,参数矩阵 W 可以按列分成两个子矩阵
和
,进而原式可以表示为
。然后,可以将参数矩阵 1 和 2 放置在两张不同的 GPU上,然后并行地执行两个矩阵乘法操作,最后通过跨 GPU 通信将两个 GPU 的输出组合成最终结果。常见的张量并行策略是分解模型注意力层的
,
,
,
和前馈网络层的
,
。目前,张量并行已经在多个开源库中得到支持,例如 Megatron-LM 支持对参数矩阵按行按列分块进行张量并行。
2. 零冗余优化器(ZeRO)
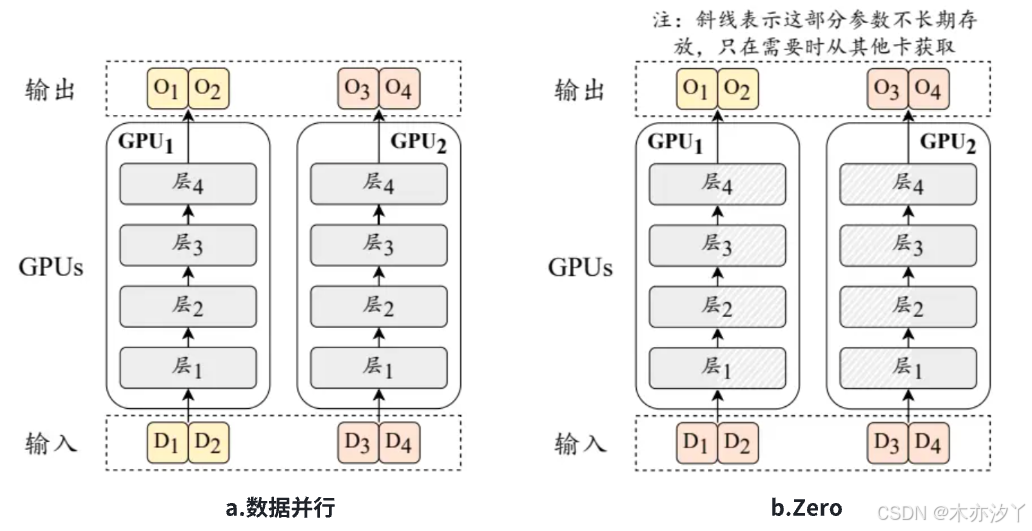
零冗余优化器(Zero Redundancy Optimizer, ZeRO)技术由 DeepSpeed 代码库提出,主要用于解决数据并行中的模型冗余问题,即每张 GPU 均需要复制一份模型参数。在图a中可以看到,数据并行时每个 GPU 都需要存储大语言模型的相同副本,包括模型参数和优化器参数等。对于每个 GPU,在模型传播到某一层时,其他层的模型和优化器参数并不参数计算,这导致了严重的显存冗余现象,同时也限制了每个 GPU 可以支持的前向传播数据量,降低了训练效率。为了解决这个问题,ZeRO 技术仅在每个 GPU 上保留部分模型参数和优化器参数,当需要时再从其它 GPU 中读取。如图b所示,模型被均分在两张 GPU 上,当需要使用第一层计算时,两张卡分别从对方获取相应的模型参数进行计算,使用完之后便可以释放相应显存,从而降低了显存冗余度。ZeRO 有三种划分模型参数和优化器参数的方案:ZeRO 的优化器参数分区方案(ZeRO-1)、ZeRO 的梯度分区方案(ZeRO-2)、ZeRO 的参数分区方案(ZeRO-3)。PyTorch 中也实现了与 ZeRO 相似的技术,称为完全分片数据并行(Fully Sharded Data Parallel, FSDP)。
3. 激活重计算
激活重计算(Activation Recomputation),也称为梯度检查点(Gradient Checkpointing),是一种用于优化反向传播时显存占用的技术。具体来说,给定一个待优化函数 ,在反向传播时需要
的值才能计算
的导数,所以在前向传播时需要保留这些
(通常被称为激活值)。然而,保存每一层所有的激活值需要占用大量的显存资源。因此,激活重计算技术在前向传播期间仅保留部分的激活值,然后在反向传播时重新计算这些激活值,以达到节约显存的目的,但是同时也会引入额外的计算开销。在大语言模型的训练过程中,激活重计算的常见方法是将 Transformer 的每一层的输入保存下来,然后在反向传播时计算对应层内的激活值。
4. 混合精度训练
早期的预训练语言模型(例如 BERT)主要使用单精度浮点数(FP32)表示模型参数并进行优化计算。近年来,为了训练超大规模参数的语言模型,研发人员提出了混合精度训练(Mixed Precision Training)技术,通过同时使用半精度浮点数(2 个字节)和单精度浮点数(4 个字节)进行运算,以实现显存开销减半、训练效率翻倍的效果。具体来说,为了保证表示精度,需要保留原始 32 位模型的参数副本。但在训练过程中,会先将这些 32 位参数转换为 16 位参数,随后以 16 位精度执行前向传播和反向传播等操作,最后在参数更新时再对 32 位模型进行优化。由于在模型训练中前向传播和反向传播占用了绝大部分优化时间,混合精度训练因而能够显著提升模型的训练效率。常见的半精度浮点数表示方式为 FP16,其包含 1 位符号位、5 位指数位和 10 位尾数位,表示范围为 −65504 到 65504。进一步,谷歌的研究人员深度学习场景提出了新的半精度浮点数表示 BF16,其包含 1 位符号位、8 位指数位和 7 位尾数位,表示范围可以达到 1038 数量级。相比于 FP16,BF16 有着更大的数值范围,在大模型训练中被广泛使用。值得一提的是,目前较为主流的 GPU (例如英伟达 A100)都支持 16 位计算单元运算,因此混合精度训练能够被硬件很好地支持。
二、Megatron-Deepspeed框架
接下来我们来聊聊 Megatron-DeepSpeed 框架,它结合了两种主要技术:
-
Megatron-LM 是由 NVIDIA 的应用深度学习研究团队开发并开源的大型、强大的 transformer 模型框架。
-
DeepSpeed 是由Microsoft开源的一个深度学习优化库,让分布式训练变得简单、高效且有效。
DeepSpeed团队通过将DeepSpeed库中的ZeRO分片(ZeRO sharding)、数据并行(Data Parallelism)和管道并行(Pipeline Parallelism)与Megatron-LM中的张量并行(Tensor Parallelism)相结合,开发了一种基于3D并行的实现方案,这就是Megatron-Deepspeed,它使得千亿级参数量以上的大规模语言模型(LLM)的分布式训练变得更简单、高效和有效。
❗️请注意,BLOOM团队BigScience版本的 Megatron-DeepSpeed 是基于原始 Megatron-DeepSpeed 代码库扩展而来。
Megatron-LM 和 DeepSpeed 都有管道并行和 BF16 优化器实现,但我们使用 DeepSpeed 的实现,因为它们集成进了 ZeRO。
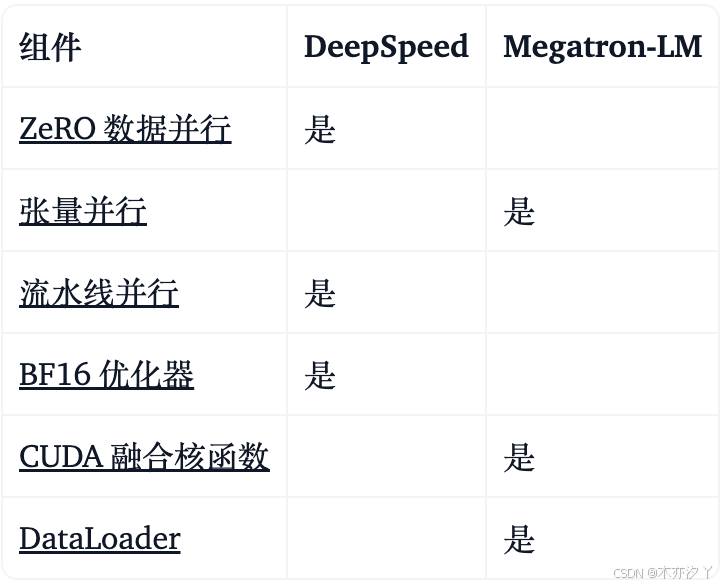
Megatron-DeepSpeed 实现了 3D 并行以允许大模型以非常有效的方式进行训练。包含数据并行 (Data Parallelism,DP)、张量并行 (Tensor Parallelism,TP)、管道并行 (Pipeline Parallelism,PP) 、零冗余优化器 (Zero Redundancy Optimizer,ZeRO)。
- 数据并行 (Data Parallelism,DP) - 相同的设置和模型被复制多份,每份每次都被馈送不同的一份数据。处理是并行完成的,所有份在每个训练步结束时同步。
- 张量并行 (Tensor Parallelism,TP) - 每个张量都被分成多个块,因此张量的每个分片都位于其指定的 GPU 上,而不是让整个张量驻留在单个 GPU 上。在处理过程中,每个分片在不同的 GPU 上分别并行处理,结果在步骤结束时同步。这就是所谓的水平并行,因为是做的水平拆分。
- 管道并行 (Pipeline Parallelism,PP) - 模型在多个 GPU 上垂直 (即按层) 拆分,因此只有一个或多个模型层放置在单个 GPU 上。每个 GPU 并行处理流水线的不同阶段,并处理 batch 的一部分数据。
- 零冗余优化器 (Zero Redundancy Optimizer,ZeRO) - 也执行与 TP 相类似的张量分片,但整个张量会及时重建以进行前向或反向计算,因此不需要修改模型。它还支持各种卸载技术以补偿有限的 GPU 内存。
1. 安装Megatron-Deepspeed框架
拉取pytorch镜像,可以选择常用的镜像源进行下载。
docker pull nvcr.io/nvidia/pytorch:21.10-py3执行以下命令,启动容器。
docker run -d -t --network=host --gpus all --privileged --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --name megatron-deepspeed -v /etc/localtime:/etc/localtime -v /root/.ssh:/root/.ssh nvcr.io/nvidia/pytorch:21.10-py3执行以下命令,进入容器终端。
docker exec -it megatron-deepspeed bash执行以下命令,下载Megatron-DeepSpeed框架。
# 代理加速 git clone https://ghgo.xyz/https://github.com/bigscience-workshop/Megatron-DeepSpeed
git clone https://github.com/bigscience-workshop/Megatron-DeepSpeed执行以下命令,安装Megatron-DeepSpeed框架。
cd Megatron-DeepSpeed
pip install -r requirements.txt2. 使用框架训练GPT-2模型并生成文本
2.1. 处理数据
本指南使用1GB 79K-record的JSON格式的OSCAR数据集。
与用于有监督精调的数据格式不同,用于预训练的OSCAR数据并不以问答对的形式出现。OSCAR的原始文本数据以JSONL格式(每行一个JSON对象)存储,每个JSON对象包含了一个“id”字段和一个“text”字段。其中“id”字段存储一个样本编号,“text”字段存储一段文本,如下表所示。

-
执行以下命令,下载数据集。
# wget https://hf-mirror.com/bigscience/misc-test-data/resolve/main/stas/oscar-1GB.jsonl.xz wget https://huggingface.co/bigscience/misc-test-data/resolve/main/stas/oscar-1GB.jsonl.xz wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt -
执行以下命令,解压数据集。
xz -d oscar-1GB.jsonl.xz -
执行以下命令,预处理数据。
python3 tools/preprocess_data.py \ --input oscar-1GB.jsonl \ --output-prefix meg-gpt2 \ --vocab gpt2-vocab.json \ --dataset-impl mmap \ --tokenizer-type GPT2BPETokenizer \ --merge-file gpt2-merges.txt \ --append-eod \ --workers 8
如果回显信息类似如下所示,表示预处理数据完成。
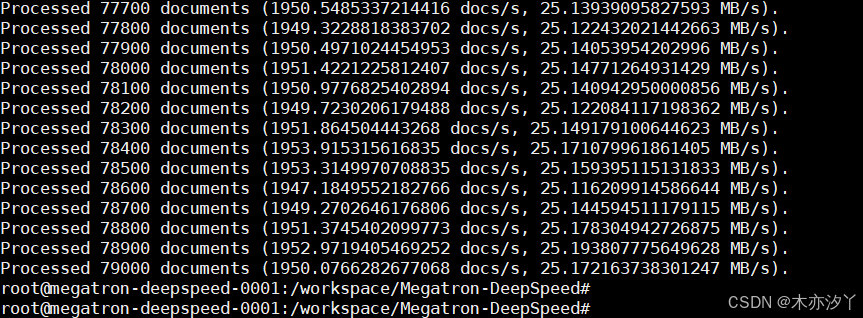
说明:若发生如下“np.float”报错,按照报错提示修改为“float”即可。

-
执行以下命令,新建data目录并将处理好的数据移动到data目录下。
mkdir data mv meg-gpt2* ./data mv gpt2* ./data
data目录下包含:gpt2-merges.txt gpt2-vocab.json meg-gpt2_text_document.bin meg-gpt2_text_document.idx
2.2. 预训练
本示例使用单机单卡的GPU实例完成GPT-2 MEDIUM模型的预训练。

1. 创建预训练脚本文件。
vim pretrain_gpt2.sh#! /bin/bash
# Runs the "345M" parameter model
GPUS_PER_NODE=1
# Change for multinode config
MASTER_ADDR=localhost
MASTER_PORT=6000
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DATA_PATH=data/meg-gpt2_text_document
CHECKPOINT_PATH=checkpoints/gpt2
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
python -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--micro-batch-size 4 \
--global-batch-size 8 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 5000 \
--lr-decay-iters 320000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file data/gpt2-vocab.json \
--merge-file data/gpt2-merges.txt \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 0.00015 \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--checkpoint-activations \
--log-interval 10 \
--save-interval 500 \
--eval-interval 100 \
--eval-iters 10 \
--fp162. 修改测试代码。
Megatron源码有一个断言需要注释掉,以保证代码正常运行。
vim /workspace/Megatron-DeepSpeed/megatron/model/fused_softmax.py +191在assert mask is None, "Mask is silently ignored due to the use of a custom kernel"前加#。

3. 预训练。
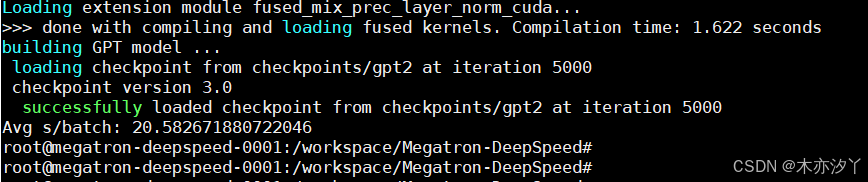
nohup sh ./pretrain_gpt2.sh &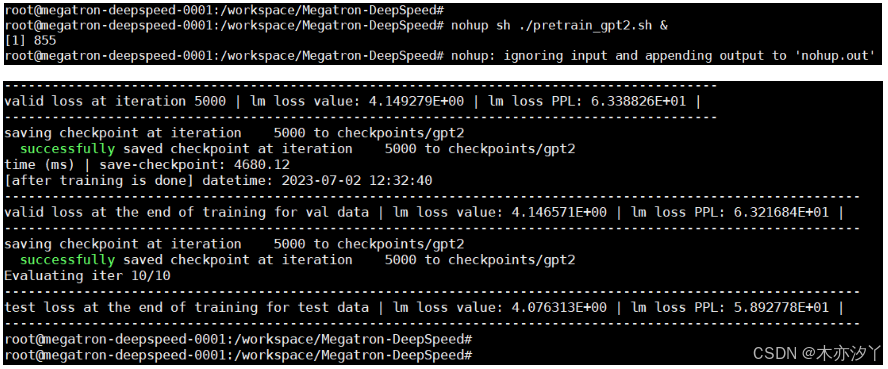
我们使用了一张3090的卡,大概1个小时完成了本次预训练任务。

4.(可选)执行以下命令,查看生成的模型checkpoint路径。 本示例生成的模型checkpoint路径设置在/workspace/Megatron-DeepSpeed/checkpoints/gpt2。
ll ./checkpoints/gpt2
2.3. 使用GPT-2模型生成文本
1. 执行以下命令,安装相关依赖。
# 说明: 由于网络原因,执行命令后可能会失败,建议您多次尝试。
pip install mpi4py如果回显信息类似如下所示,表示依赖安装完成。 
2. 创建文本生成脚本。
vim generate_text.sh#!/bin/bash
CHECKPOINT_PATH=checkpoints/gpt2
VOCAB_FILE=data/gpt2-vocab.json
MERGE_FILE=data/gpt2-merges.txt
python tools/generate_samples_gpt.py \
--tensor-model-parallel-size 1 \
--num-layers 24 \
--hidden-size 1024 \
--load $CHECKPOINT_PATH \
--num-attention-heads 16 \
--max-position-embeddings 1024 \
--tokenizer-type GPT2BPETokenizer \
--fp16 \
--micro-batch-size 2 \
--seq-length 1024 \
--out-seq-length 1024 \
--temperature 1.0 \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--genfile unconditional_samples.json \
--num-samples 2 \
--top_p 0.9 \
--recompute3. 执行以下命令,生成文本。
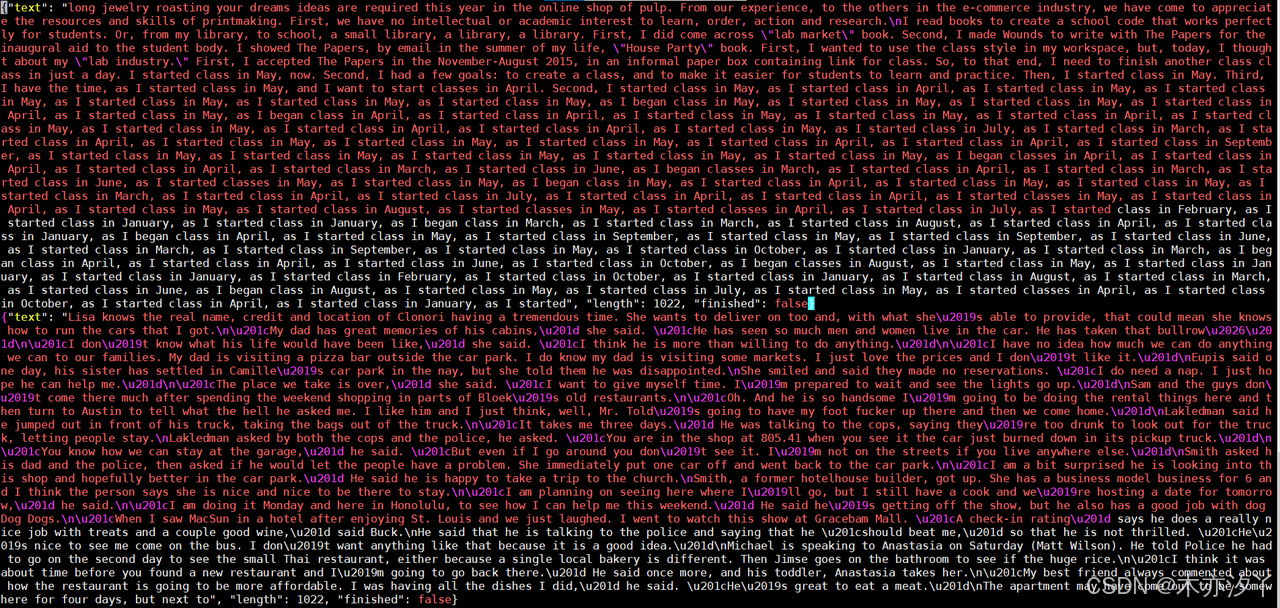
sh ./generate_text.sh
cat unconditional_samples.json回显信息类似如下所示。
3. 单机多卡
如果是单机多卡,可以调整预训练脚本的参数。
GPUS_PER_NODE=2 NNODES=1 WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))world_size=2 model_parallel_size = pipeline_model_parallel_size * tensor_model_parallel_size = 1 data_parallel_size = world_size // model_parallel_size = 2调整全局批处理大小(global-batch-size)、微批处理大小(micro-batch-size)、数据并行大小(data-parallel-size)参数。
三者的关系为:“global-batch-size”可被“micro-batch-size * data-parallel-size”整除。
https://github.com/bigscience-workshop/Megatron-DeepSpeed/blob/main/megatron/arguments.pyglobal-batch-size = 8 micro-batch-size = 4 data-parallel-size = 2

Data Parallel Size
data-parallel-size 指的是数据并行的规模,即有多少个进程负责处理不同的数据批次。在单机多卡的情况下,数据并行是最常见的并行方式之一,它允许每个GPU处理不同的数据子集,从而加速训练过程。对于单机双卡,data-parallel-size 也可以设置为2,这意味着每个GPU都会独立地处理一批数据。
Tensor Model Parallel Size
tensor-model-parallel size 是指张量并行的规模,即将模型的某些层或参数分割到多个GPU上进行计算。这种方式可以有效减少单个GPU的内存占用,适用于非常大的模型。然而,对于较小的模型或普通的单机双卡环境,使用张量并行可能会引入额外的通信开销,反而降低训练效率。因此,在单机双卡的情况下,通常不推荐使用张量并行,除非你确实有一个非常大的模型,且单个GPU无法容纳。
Pipeline Model Parallel Size
pipeline-model-parallel size 是指流水线并行的规模,即将模型的不同层分配到不同的GPU上,形成一个“流水线”式的计算过程。流水线并行适合于深度较大的模型,尤其是当模型层数较多时,可以将不同层的计算分布在不同的GPU上,从而提高并行度。然而,对于单机双卡的情况,流水线并行可能会引入额外的通信开销,尤其是在模型较浅或批次大小较小的情况下。因此,除非你有一个非常深的模型,否则通常不建议在单机双卡环境中使用流水线并行。
🔥🔥🔥 对于单机双卡的环境,最简单的配置是使用数据并行(
data_parallel_size=2),并且不启用张量并行或流水线并行(tensor_model_parallel_size=1和pipeline_model_parallel_size=1)。如果你的模型非常大或非常深,可以根据具体需求选择合适的并行策略。



















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









