







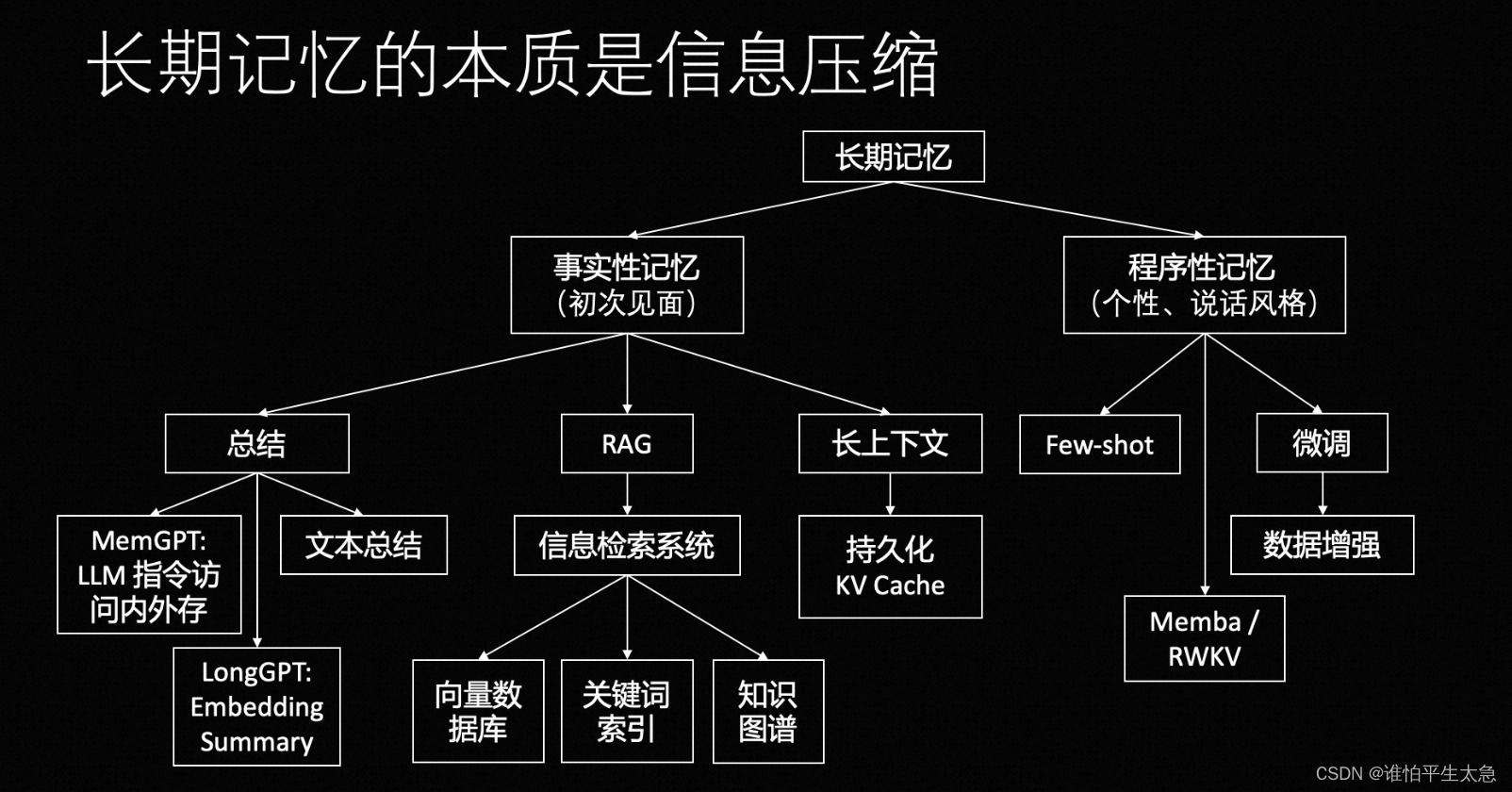
长期记忆:事实性记忆和程序性记忆
(1)事实性记忆的解决方案:总结、RAG和上下文。
总结:
文本总结:把聊天记录用一小段话总结一下。
指令的方式去访问外部存储:模型把对话中的要点记录到一个叫做bio的本上。
在模型层面用Embedding做总结,比如LongGPT,目前主要是学术界在研究。
RAG:一整套信息检索系统
长上下文:+持久化KV Cache、压缩技术、attention的优化技术。
(2)程序化记忆:prompt、few-shot、微调、Memba和RWKV
(3)一个简单有效的长期记忆解决方案:文本总结+RAG
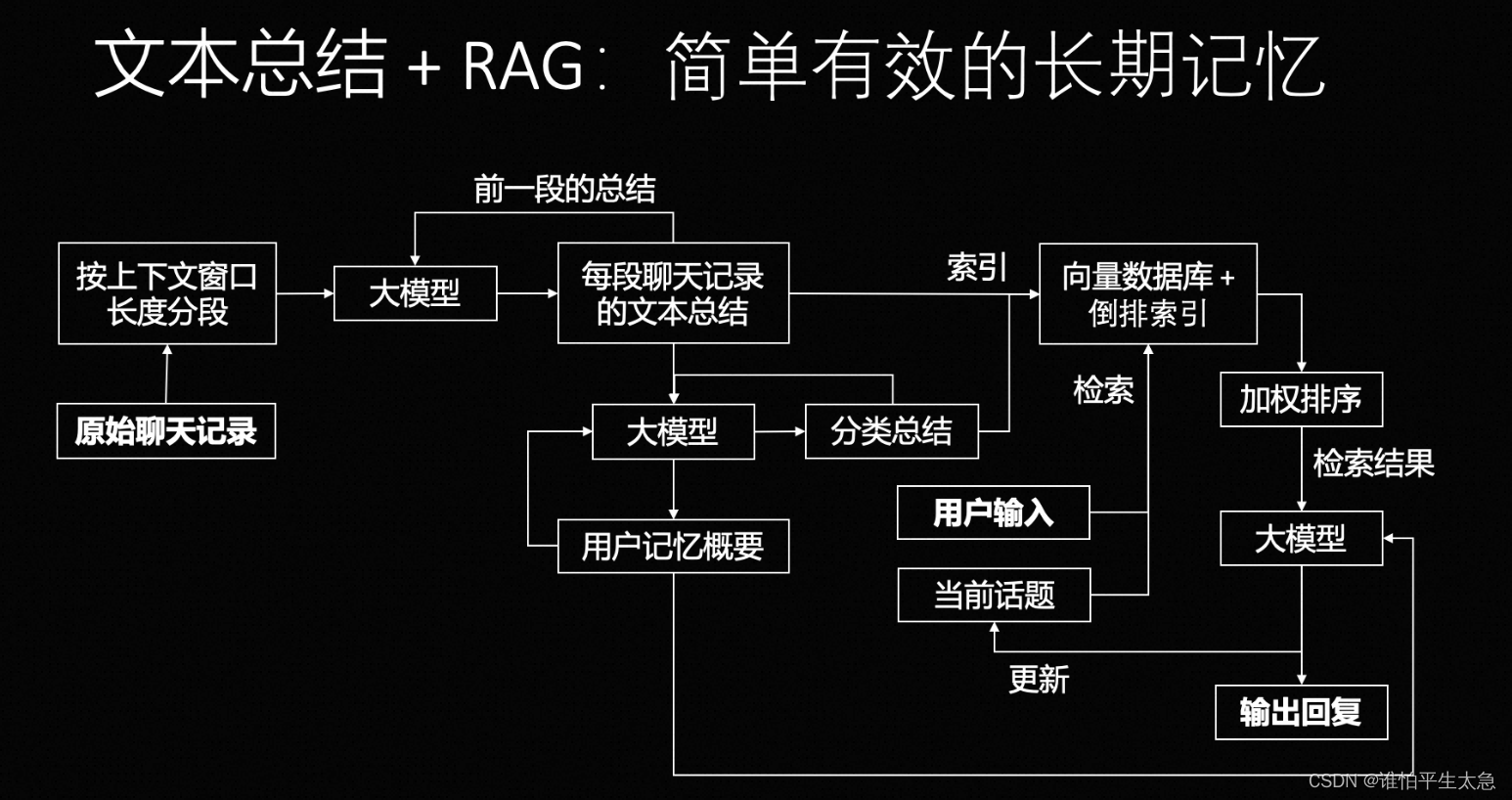
a.按照一定的窗口分段,然后对每一段聊天记录(+前一段的总结)生成文本总结,放进RAG
b.在分段总结的基础上,再让大模型分别生成分话题的分类总结(放进RAG,这部分搜索排序权重要高于a.)和全局的用户记忆概要(不断更新的全局总结:包括用户基本信息、兴趣爱好和性格特征等)
最终带有长期记忆的大模型的输入:包括角色设定(system prompt)、最近对话、全局记忆概要(即角色对用户的核心记忆 b.2)、经过RAG的聊天记录分段总结(a.)和分类总结(b.1)。
(4)Agent对多人记忆的共享
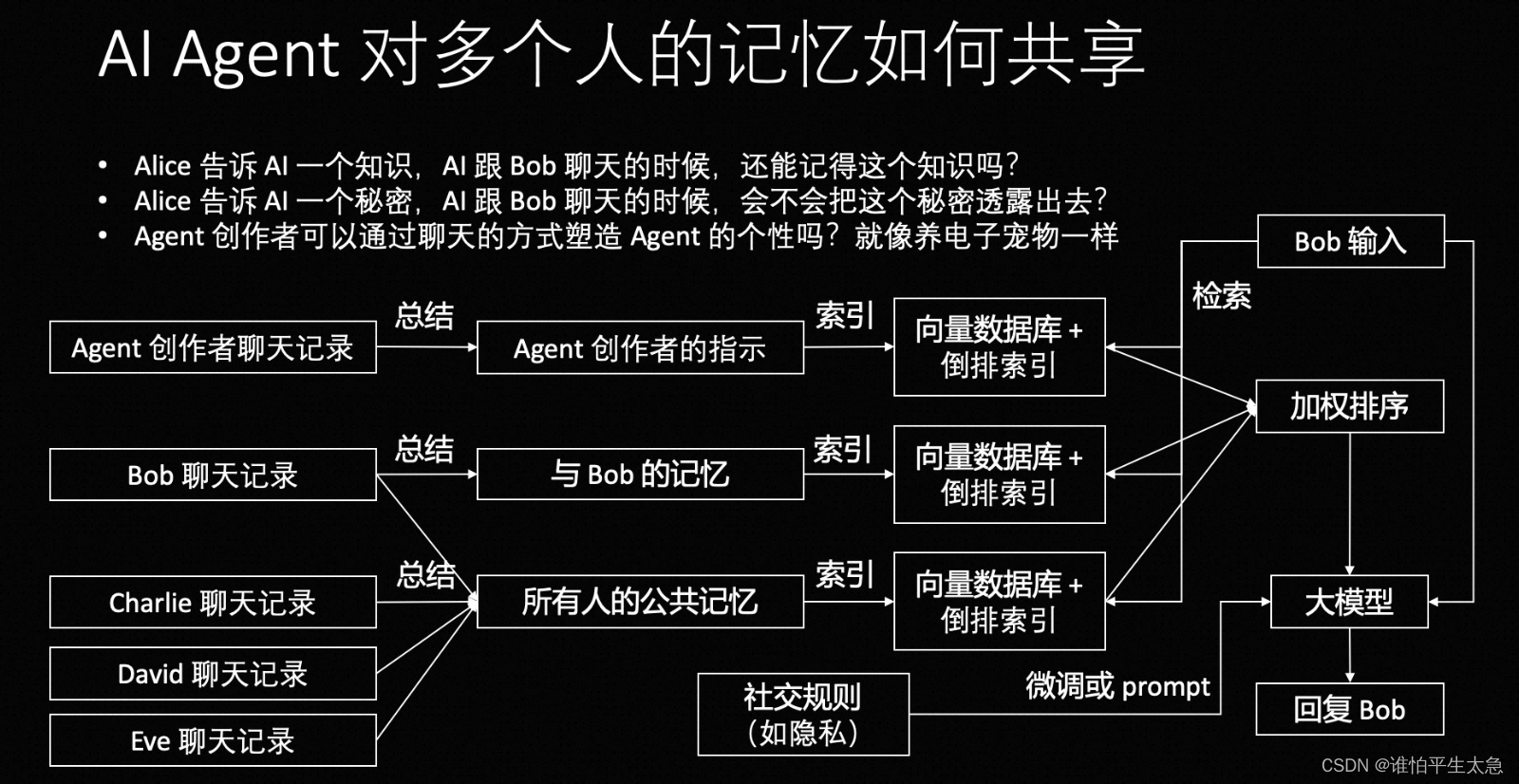
社交问题:一个人在讨论一件事情的时候,会回忆起很多不同人的记忆片段。其中和其他人的记忆也会被检索出来,在生成的时候参考社交规则(A告诉Agent一个秘密,Agent不应该把秘密告诉B)决定用不用,怎么用。
一种简单的实现方法就是类似 MemGPT 这样,当创作者给指示的时候,就把这些指示记录到小本本上,然后通过 RAG 的方式提取出来。
所以 总结和RAG的细节对于实际的应用很重要。
(5)AI Agent的工作记忆 ==> 自我意识
而目前AI Agent在工程上没有做好优化。比如prompt未系统化,比如没有做记忆系统。
prompt的技巧:「要让模型有自己的思考,最关键的就是要把思考的片段和外界输入输出的片段在 自回归模型输入 token的层面就分隔开」比如system、user、assistant这些特殊token,可以增加一个Thought,json等等
另外,目前OpenAI API交互方式本质上还是批处理式,每次API调用还是无状态的,需要带上前面所有的聊天记录,重复计算所有的KV Cache。
如果什么时候,可以不断流式的接受外界的输入token,KV Cache一直在GPU内存或者临时换出到CPU内存,这样KV Cache就是AI Agent的工作记忆,或者说AI Agent的状态,这是的Agent或许就是不断进行的“半神”存在。
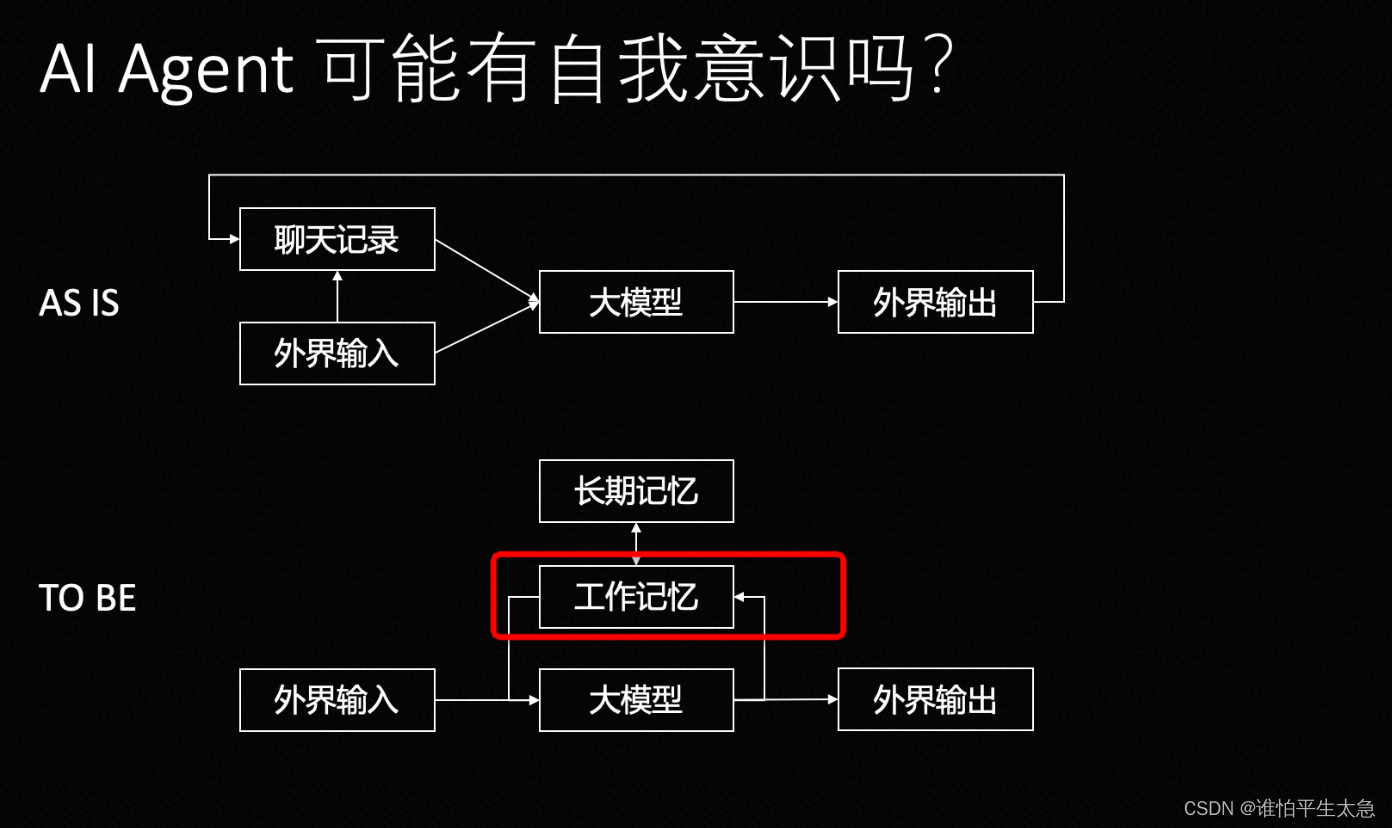
关键在于:AI得有一个内部的思考状态,每小时唤醒一次的工作记忆(AI对自己的感知 + 对用户的感知)。
相当于 内部状态 + 执行逻辑 + 定制唤醒 + 不断更新


















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









