







文章目录
1 YOLOv1(2015, Joseph Redmon)
Paper:http://arxiv.org/abs/1506.02640/
Github:https://github.com/pjreddie/darknet/
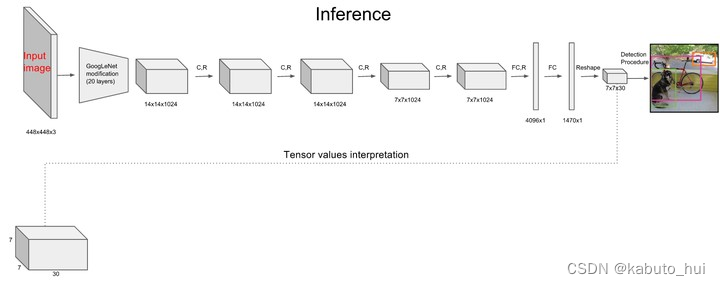
Source: YOLO系列简析
YOLOv1的特点:
- Backbone: 启发于GoogleNet,一路卷积到底,无BN层,Leaky ReLU作为激活函数;
- Head: 划分网络,每个网格能预测2个框,但只能输出一个目标,网络输出组成如下图所示,(x, y, w, h)分别表示目标的中心坐标和宽高;
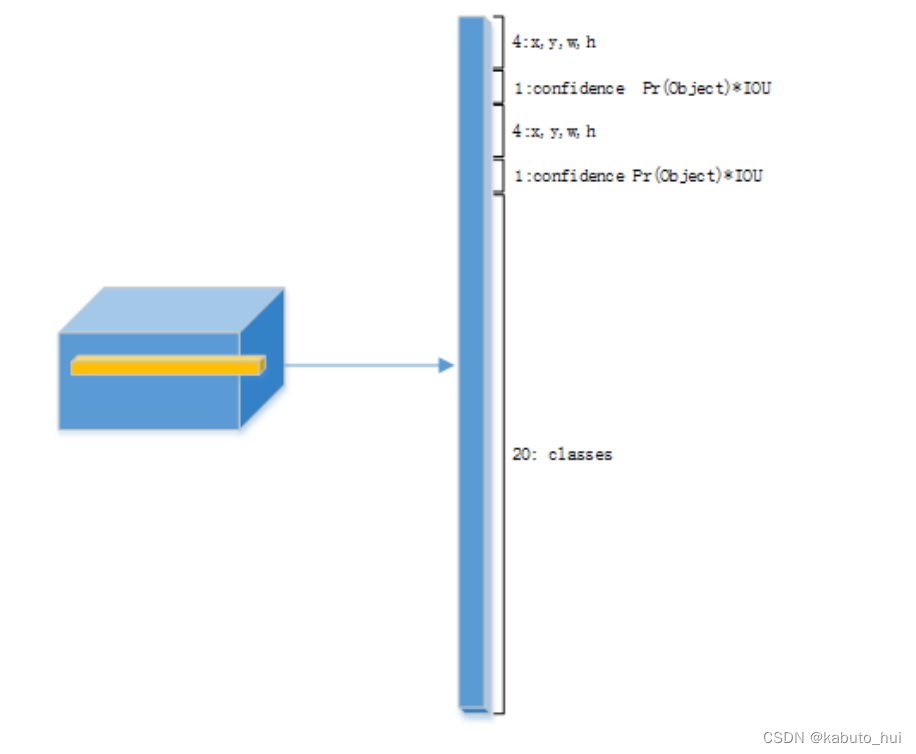
YOLOv1的缺陷: - head部分是全连接层,限制了网络输入必须是固定的;
- 由于YOLOv1每个网格的检测框只有2个,对于密集型目标检测和小物体检测都不能很好适用。
- Inference时,当同一类物体出现的不常见的长宽比时泛化能力偏弱。
2 YOLOv2(2016, Joseph Redmon)
Paper:https://arxiv.org/pdf/1612.08242v1.pdf/
Github:https://github.com/pjreddie/darknet/
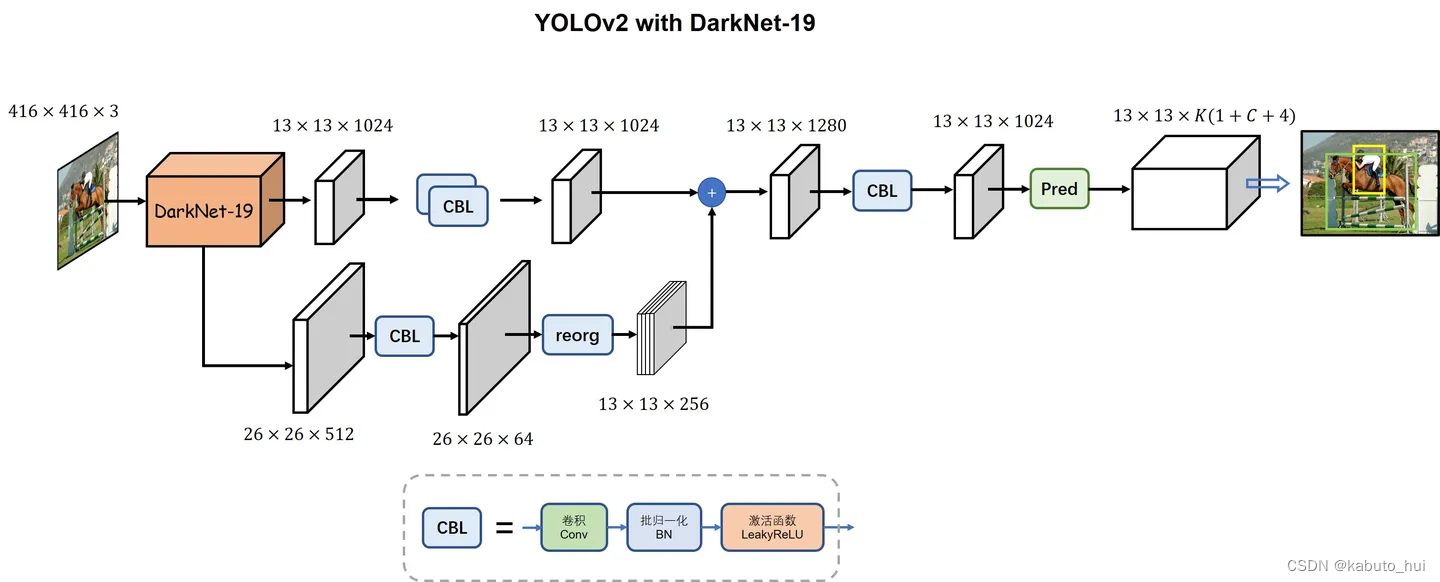
Source: YOLO入门教程(新)
YOLOv2的特点:
- Input:
- 多尺度训练:随机resize输入尺寸320:32:608
- 优化预训练模型:大分辨率输入在imagenet上finetune(4%+)
- Backbone:
- Darknet19,BN层(2%+)
- average pooling代替全连接
- Head:
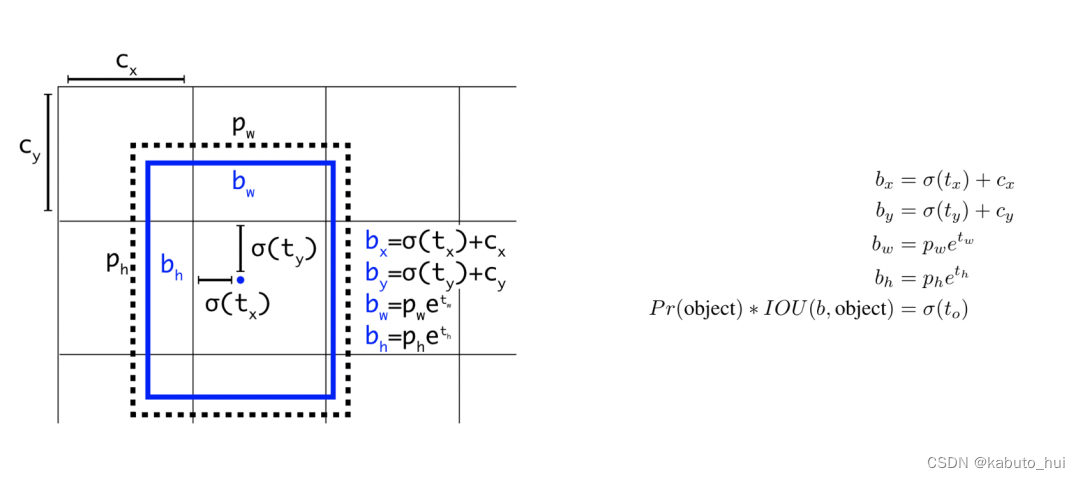
- anchor box,由k-means聚类产生,5个,每个anchor单独预测目标位置、置信度以及类别,输出结构构成如下图所示。
- passthrough:将(h,w,c)的tensor隔点采样重组成(h/2, w/2, c*4)
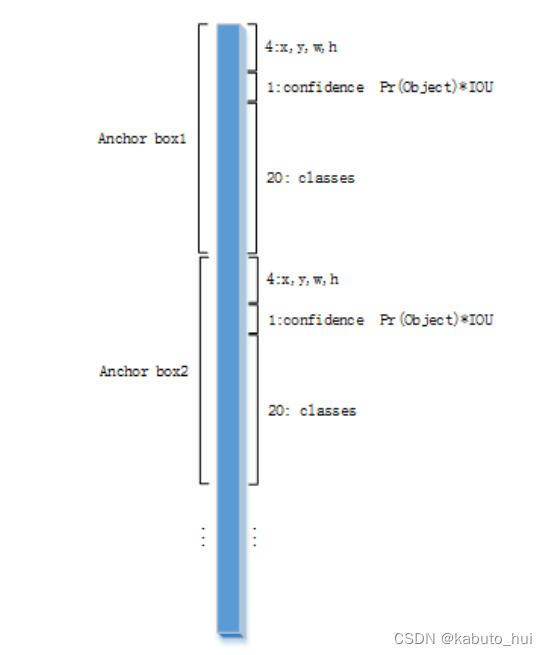
YOLOv2的回归目标变成了anchor点到中心点的偏差,并使用sigmoid和归一化处理:
3 YOLOv3(2018, Joseph Redmon)
Paper:https://arxiv.org/abs/1804.02767/
Github:https://github.com/pjreddie/darknet/
Source:江大白-深入浅出Yolo系列
YOLOV3的特点:
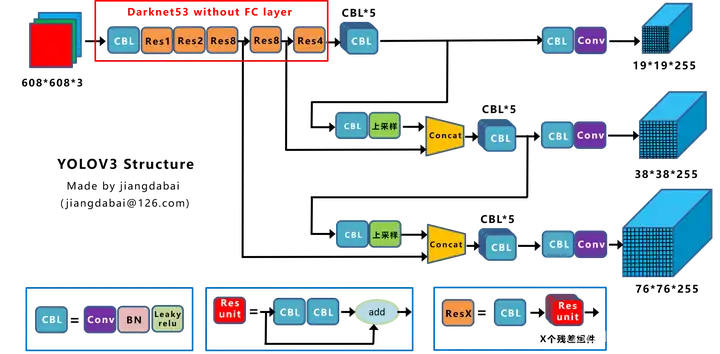
- BackBone:
- Darknet53,残差思想
- 去掉池化层,使用卷积实现下采样
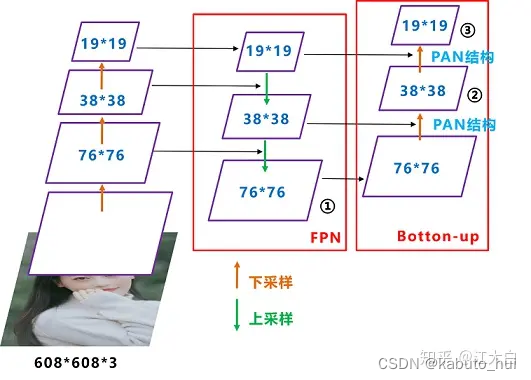
- Neck: 引入FPN(特征金字塔),分成3个检测头,浅层头(76x76)感受小,预测小目标,深层头(19x19)感受野大,用于预测大目标;
- Head:
- 3个尺度,每个尺度3个anchor box,浅层预测头使用小尺度anchor box,深层头使用大尺度anchor box
- 将YOLOv2的单标签分类改进为多标签分类,Head结构将用于单标签分类的Softmax分类器改成多个独立的用于多标签分类的Logistic分类器,取消了类别之间的互斥,可以使网络更加灵活
- Tricks: 引入adam优化器(YOLOv3发布时,Adam开始逐渐流行起来)
4 YOLOv4(2020, Alexey Bochkovskiy, Chien-Yao Wang)
Paper:https://arxiv.org/abs/2004.10934/
Github:https://github.com/AlexeyAB/darknet/
Source:江大白-深入浅出Yolo系列
YOLOV4的特点:
-
Input: Mosaic和CutMix进行数据增强
-
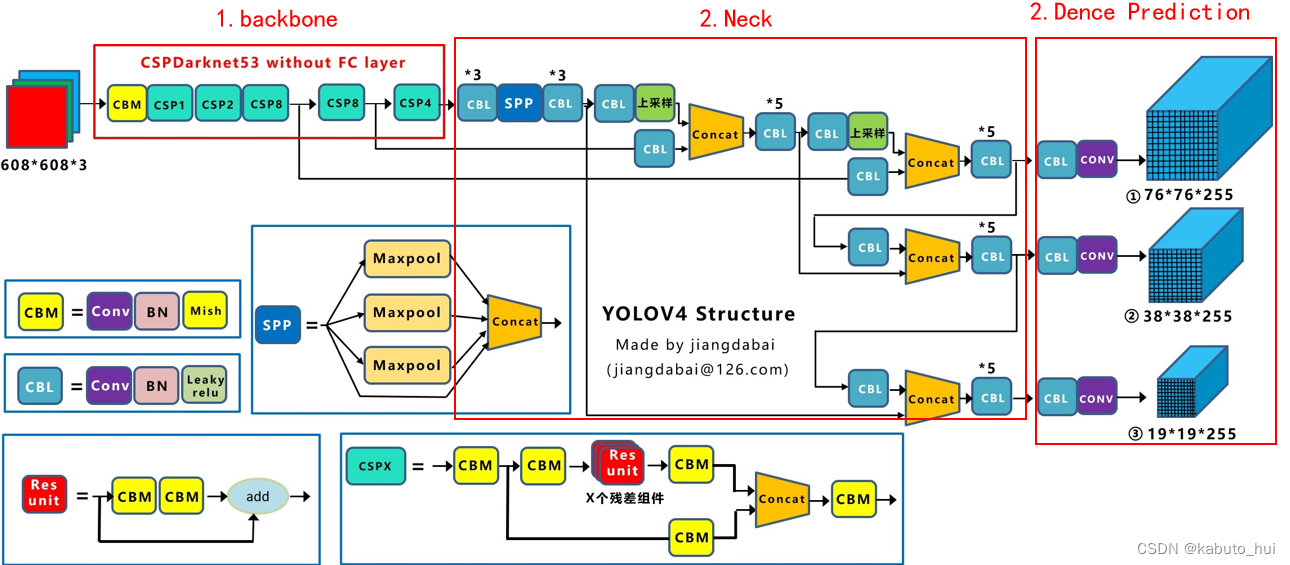
Backbone:
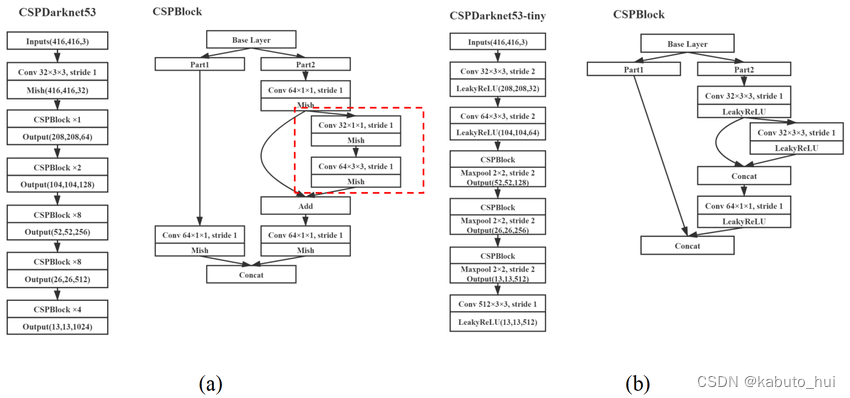
- CSPDarknet53(Cross Stage Partial Network :子模块主要解决了由于梯度信息重复导致的计算量庞大的问题)
- 使用mish激活函数:
M
i
s
h
(
x
)
=
x
∗
t
a
n
h
(
l
n
(
1
+
e
x
p
(
x
)
)
)
Mish(x) = x * tanh(ln(1 + exp(x)))
Mish(x)=x∗tanh(ln(1+exp(x)))
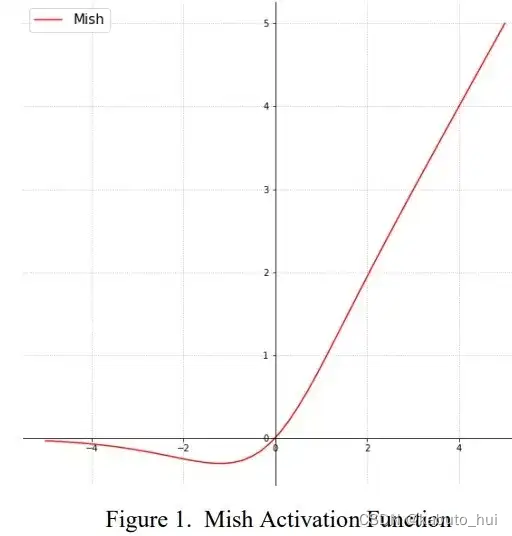
Source: Mish:一个新的state-of-the-art激活函数,ReLU的继任者
- CSPDarknet53(Cross Stage Partial Network :子模块主要解决了由于梯度信息重复导致的计算量庞大的问题)
-
Neck:
- SPP(Spatial Pyramid Pooling)模块, 1×1, 5×5, 9×9, 13×13,最大池化,stride=1
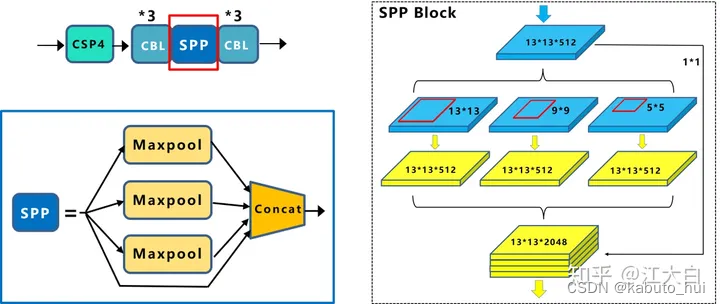
Source:江大白-深入浅出Yolo系列 - PAN(Path Aggregation Network ):在FPN后添加了一个自底向上的特征金字塔
Source:江大白-深入浅出Yolo系列
- SPP(Spatial Pyramid Pooling)模块, 1×1, 5×5, 9×9, 13×13,最大池化,stride=1
-
Head:
- 整体延用v3的Head结构
- 使用CIoU Loss
L C I O U = 1 − C I O U = 1 − IOU ( A , B ) + D 2 2 D 1 2 + v 2 ( 1 − IOU ( A , B ) ) + v v = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 L_{C I O U}=1-C I O U=1-\operatorname{IOU}(A, B)+\frac{D_2^2}{D_1^2}+\frac{v^2}{(1-\operatorname{IOU}(A, B))+v} \\ v=\frac{4}{\pi^2}\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right)^2 LCIOU=1−CIOU=1−IOU(A,B)+D12D22+(1−IOU(A,B))+vv2v=π24(arctanhgtwgt−arctanhw)2
其中:D2表示检测框中心点距离,D1表示2个检测框最小外接矩形对角线的距离。
-
Tricks:
- SAT(self adversarial training)使用基于FGSM原理的梯度攻击技术,生成对抗样本进行对抗训练。
- CmBN(Cross mini-Batch Normalization)CmBN是CBN的修改版:
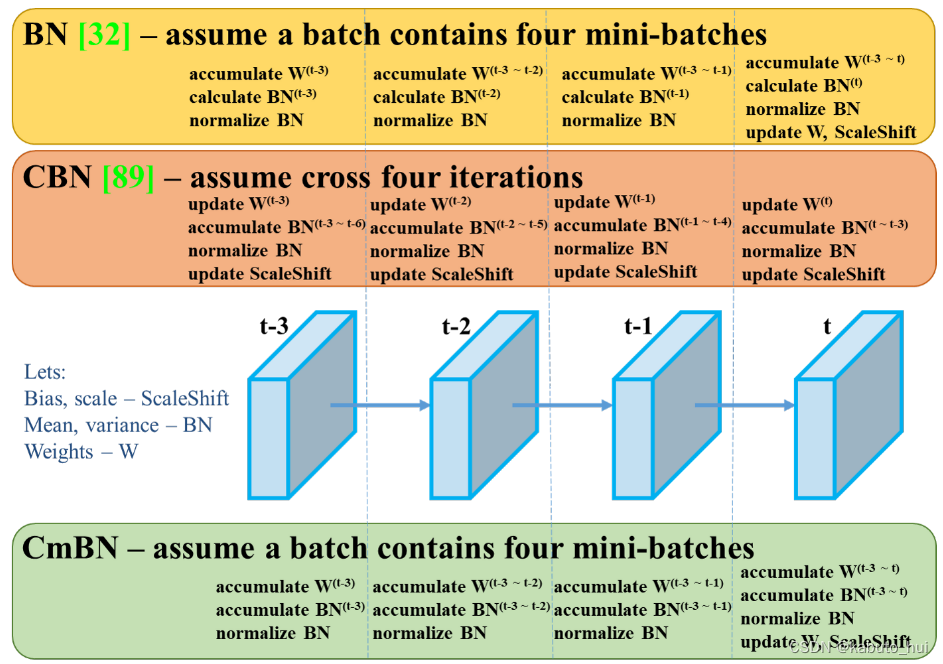
CBN主要用来解决在Batch-Size较小时,BN的效果不佳问题。CBN连续利用多个迭代的数据来变相扩大Batch-Size从而改进模型的效果。(每次迭代时计算包括本次迭代的前四个迭代后统一计算整体BN,计算一次更新一次)而CmBN是独立利用多个mini-batch内的数据进行BN操作。(每四个迭代后统一计算一次整体BN,最后更新)
-
Label Smooth:可以看作是一种防止过拟合的正则化方法,预测目标对应的类别调整为 α < 1 \alpha < 1 α<1,剩余的其他类别均分 1 − α 1 - \alpha 1−α

5 YOLOV5(2021,Ultralytics)
Paper:无
Github:https://github.com/ultralytics/yolov5/
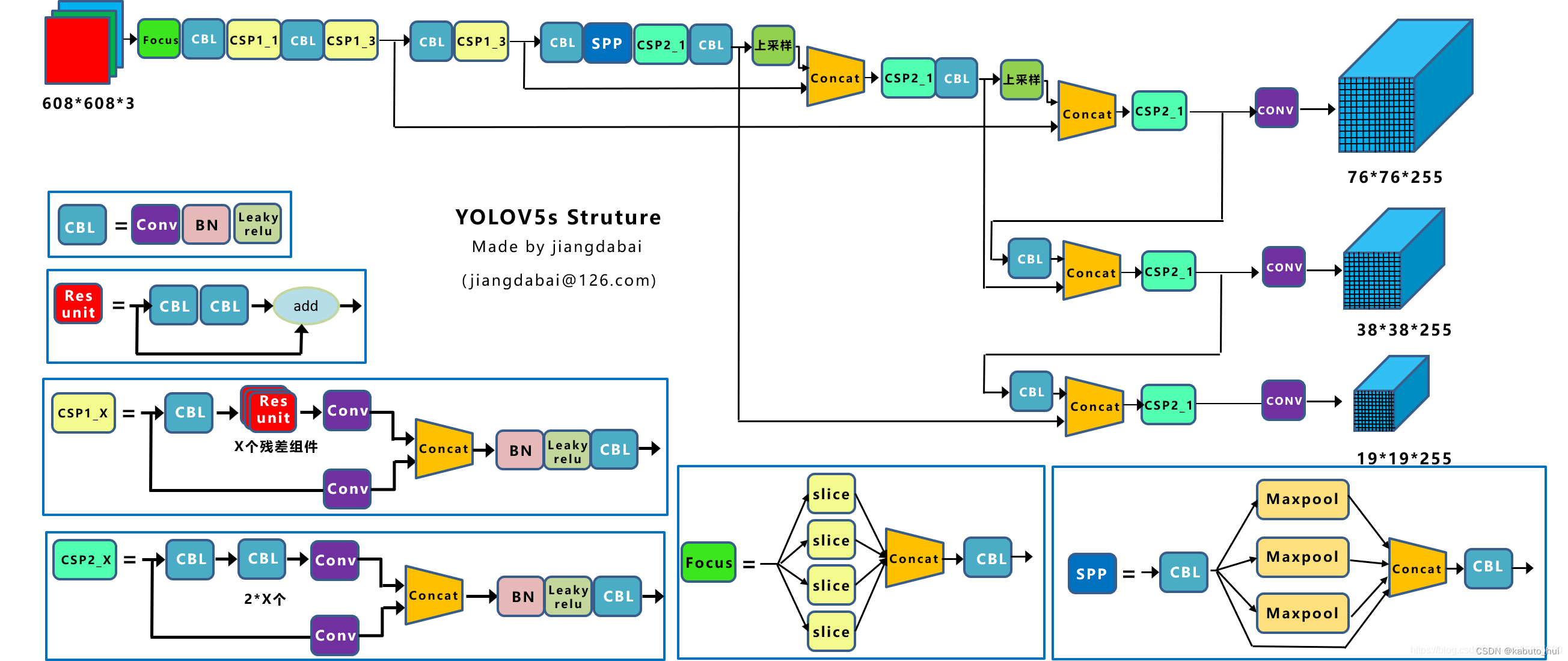
Source:深入浅出Yolo系列之Yolov5核心基础知识完整讲解
-
Input:
- 使用mosaic数据增强(v5与mosaic的作者为同一人)
- 自适应图片缩放:缩放时由原来的固定尺寸变为以添加最少黑边为原则
-
Backbone:
- 整体沿用v4中的CSP思想
- 使用Focus结构,整体操作类似于v2的passthrough,v5第六版之后舍弃了该结构,采用常规卷积,参数更少,效果更好
-
Neck: 类似于v4,使用了SPP和PAN模块
-
Head: 在v4的基础上引入自适应anchor box(Auto Learning Bounding Box Anchors)和领域正负样本分配策略
- 自适应anchor box:训练前,针对不同的训练数据,聚类anchor box
- 增加高质量正样本检测框可以显著加速收敛,v5的领域正负样本分配策略:
- 将ground truth与当前feature map中的anchor box进行比较,如果ground truth与anchor box的宽高比例都处在[1/4, 4]那么这个ground truth就能与当前featuer map相匹配。
- 将当前feature map中的ground truth分配给对应的grid cell。将这个grid cell分为四个象限,针对与当前feature map匹配的ground truth,会计算该ground truth处于四个象限中的哪一个,并将邻近的两个grid cell中的检测框也作为正样本。如下图所示,若ground truth偏向于右上角的象限,就会将ground truth所在grid cell的上面和右边的grid cell中的检测框也作为正样本。
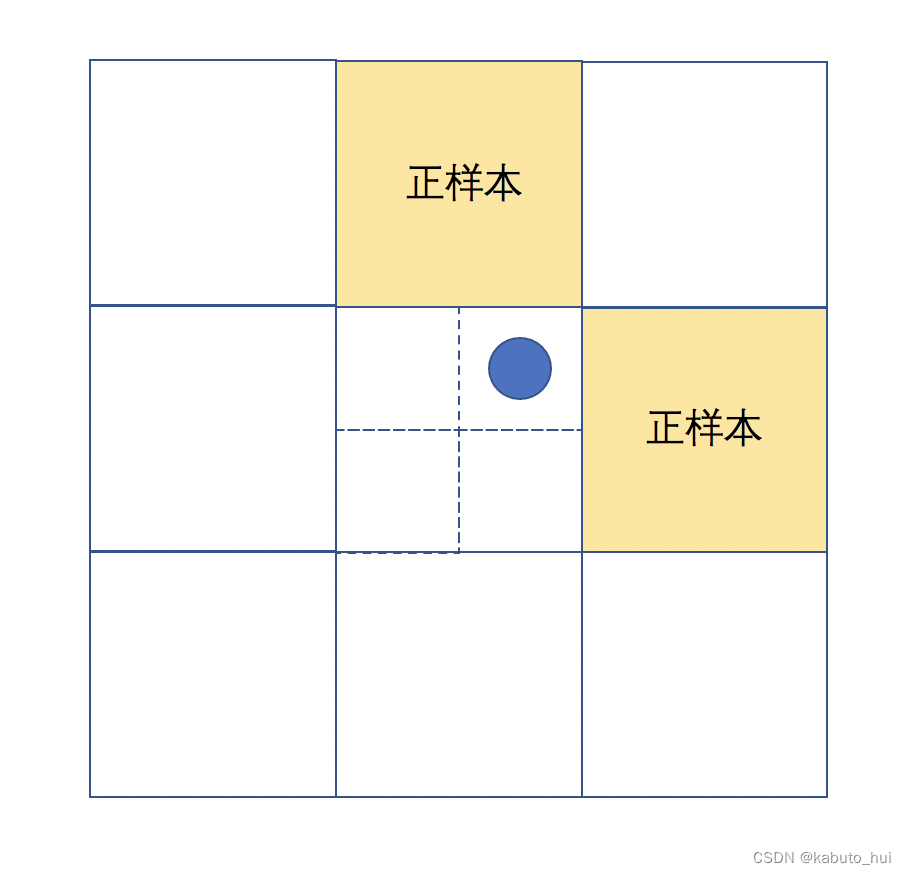
比起yolov4中一个ground truth只能匹配一个正样本,YOLOv5能够在多个grid cell中都分配到正样本,有助于训练加速和正负样本平衡。
-
Tricks:
- 混合精度训练
- 模型EMA(Exponential Moving Average)策略:将模型近期不同epoch的参数做平均,提高模型整体检测性能以及鲁棒性。
6 YOLOX(2021, Megvii旷视)
Paper:https://arxiv.org/pdf/2107.08430.pdf/
Github:https://github.com/Megvii-BaseDetection/YOLOX/
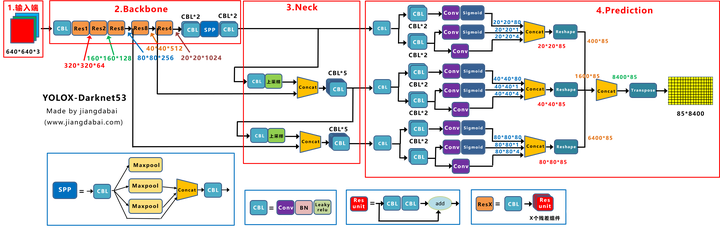
Source:江大白-深入浅出Yolo系列之Yolox核心基础完整讲解
- Input:
- 使用Mosaic和MixUp数据增强
- 不使用预训练模型,从头裸训
- BackBone: v3的backbone darknet53
- Neck: 使用SPP模块
- Head:
- 解耦头(decouple head):分别聚焦cls(分类信息),reg(检测框信息)和IOU(置信度信息)。常规的检测头在特征的表达与学习能力上比起Decoupled Head有所欠缺,并且Decoupled Head模块能加快模型的收敛速度
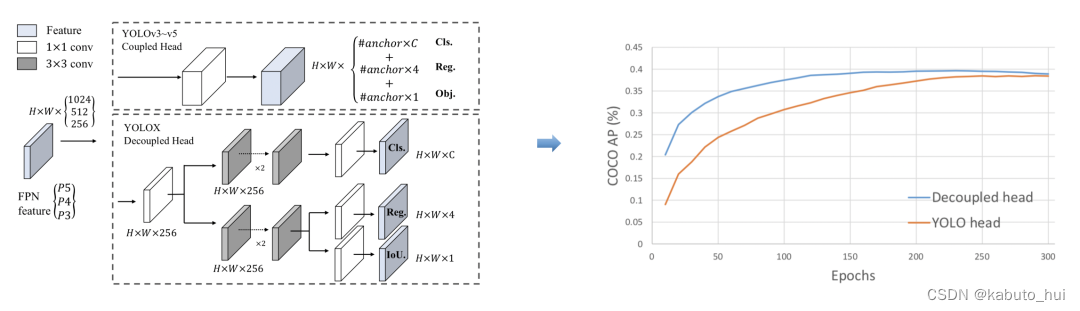
- anchor-free思想:YOLOX作者去掉了anchor box,和FCOS一样,每个grid都只预测一个目标。
- 对于一个给定的gt边界框,首先根据它的size确定所匹配的尺度,然后就和YOLOv3一样了,计算它在这个尺度上的中心点位置,计算中心点偏差 tx、ty,至于宽高 w、h,就直接作为回归目标(注意,这里要把宽高做归一化,这是yolo基操)
- 解耦头(decouple head):分别聚焦cls(分类信息),reg(检测框信息)和IOU(置信度信息)。常规的检测头在特征的表达与学习能力上比起Decoupled Head有所欠缺,并且Decoupled Head模块能加快模型的收敛速度
SimOTA正负样本分配策:
假设网络最后输出的size为hxw:
- 将所有位于gt内的点标记为:in_box
- 以gt为中心,落在5x5区域内的点标记为:in_center
- in_box与in_center取并集,作为前景信息fg_mask
- 计算iou_loss矩阵: 计算gt与fg_mask中预测box的IoU,取log作为iou_loss
- 计算cls_loss矩阵: 先使用置信度矩阵乘以分类矩阵,再与gt计算BCE损失
- in_box与in_center取交集,,在fg_mask中标记,作为in_box_and_center
- 计算simOTA的cost矩阵: c o s t = c l s l o s s + 3.0 ∗ i o u l o s s + 100000 ∗ ( i n b o x a n d c e n t e r ) ,其中 100000 ∗ ( i n b o x a n d c e n t e r ) cost = cls_loss + 3.0 * iou_loss + 100000 * (~in_box_and_center),其中100000 * (~in_box_and_center) cost=clsloss+3.0∗iouloss+100000∗( inboxandcenter),其中100000∗( inboxandcenter),表示给位于center外且在box内的其他点给一个非常大的loss,在最小化cost的过程中就会优先选择center内的样本。cost的大小为N(gt的数量)xM(fg_mask内点的数量)
- dynamic_k_matching:
- 针对每个gt,取iou最大的10个anchor点对应的iou并求和,将其和值向下取整得到dynamic_k;
- 针对每个gt,从cost中挑选dynamic_k个最小的loss,如果一个anchor被多个gt匹配上,则选取cost最小的作为匹配;


Source: YOLOX中的SimOTA正负样本分配策略
YOLOv5的正负样本分配策略是基于邻域匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。YOLOx使用的SimOTA能够算法动态分配正样本,进一步提高检测精度。而且比起OTA由于使用了Sinkhorn-Knopp算法导致训练时间加长,SimOTA算法使用Top-K近似策略来得到样本最佳匹配,大大加快了训练速度。
- Tricks:
- EMA策略
- 余弦退火学习率
7 YOLOv6(2022,美团)
Paper:https://arxiv.org/pdf/2209.02976.pdf/
Github:https://github.com/meituan/YOLOv6/
官方博客:https://blog.csdn.net/MeituanTech/article/details/125437630/
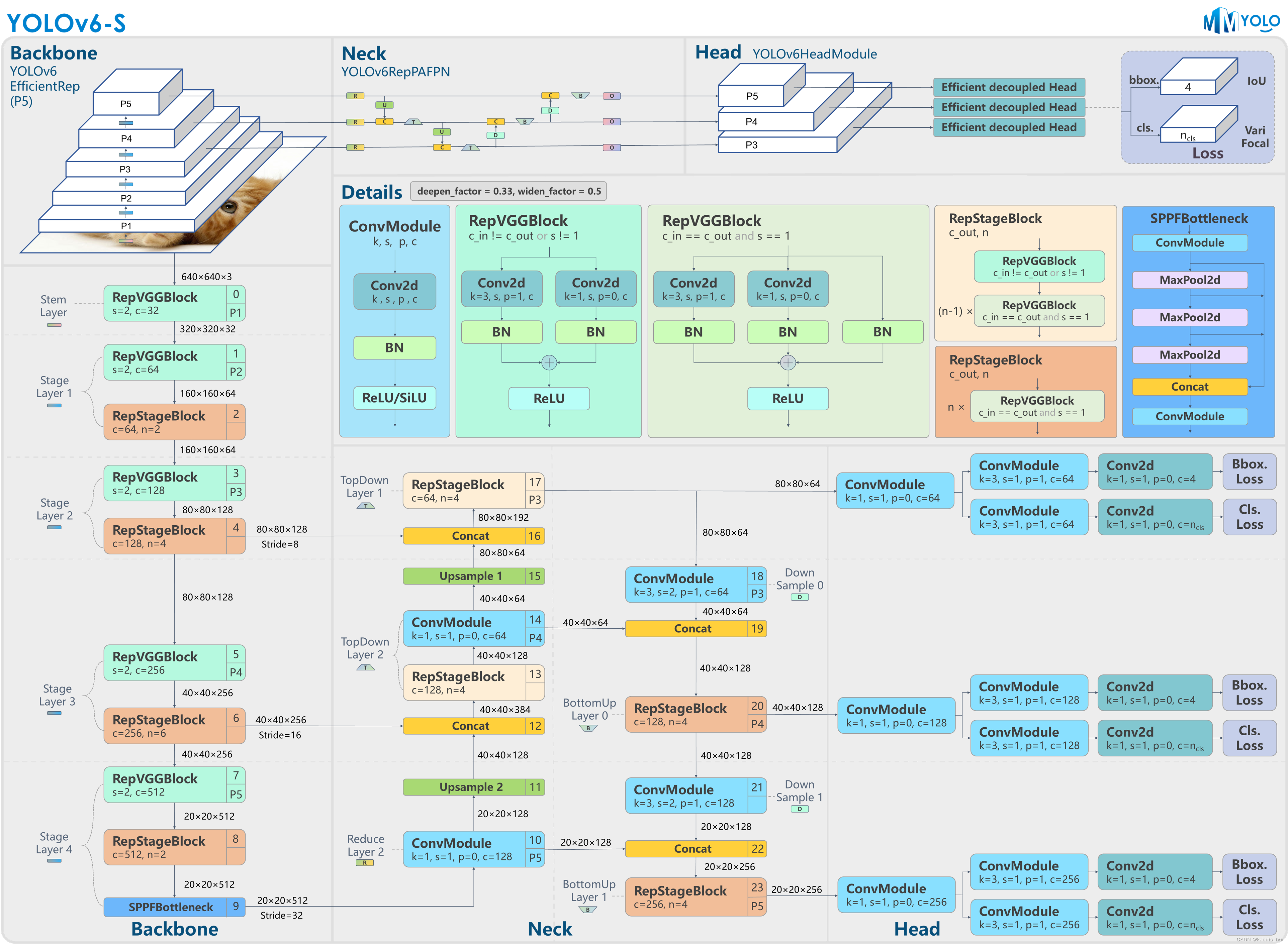
Source: MMYOLO-YOLOV6 原理和实现全解析
-
Input: 沿用yolov5逻辑
-
Backbone:
- 设计了EfficientRep Backbone的结构,将普通卷积替换成RepConv
- 设计SimSPPF结构:
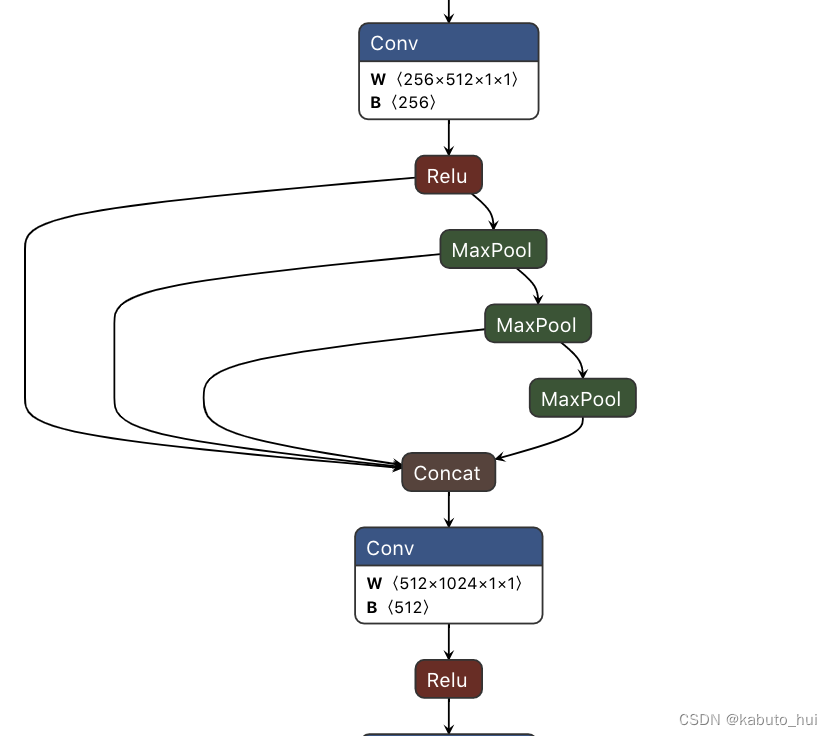
-
Neck: 基于RepVGG style设计了可重参数化、更高效的Rep-PAN
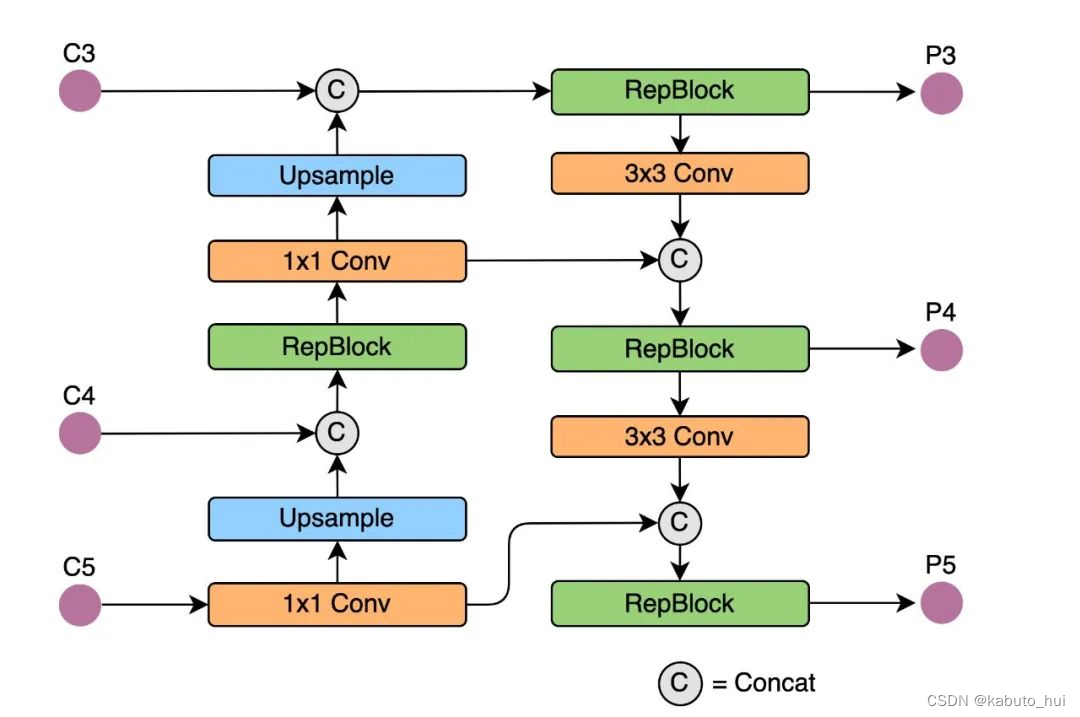
Source: YOLOv6:又快又准的目标检测框架开源啦 -
Head:
-
YOLOv6依然采用了Decoupled Head结构,并对其进行了精简设计。YOLOX的检测头虽然提升了检测精度,但一定程度上增加了网络延时。YOLOv6采用Hybrid Channels策略重新设计了一个更高效的Decoupled Head结构,在维持精度的同时降低了延时,缓解了Decoupled Head中 卷积带来的额外延时开销。
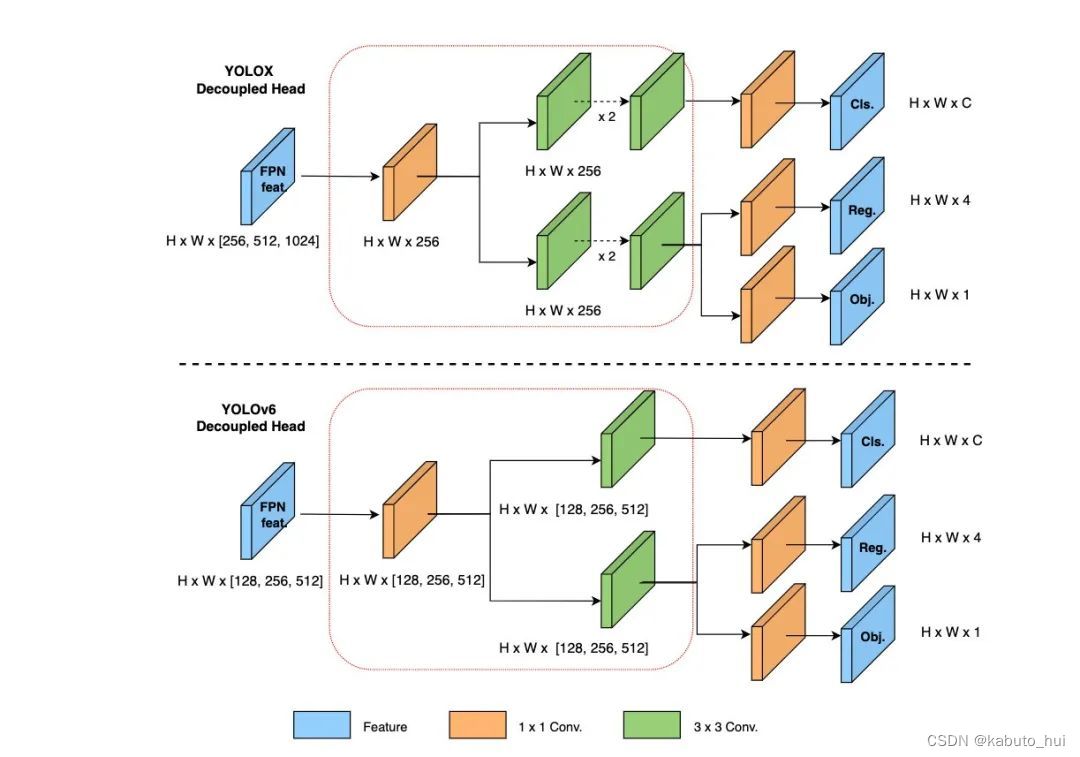
Source: YOLOv6:又快又准的目标检测框架开源啦 -
SIoU检测框回归损失函数: YOLOv4中的CIoU Loss虽然考虑到检测框与ground truth之间的重叠面积、中心点距离,长宽比这三大因素,但是依然缺少了对检测框与ground truth之间方向的匹配性的考虑。SIoU Loss通过引入了所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度。具体包含四个部分:角度损失、距离损失、形状损失和IoU损失,以下内容摘选自:边框回归损失函数SIoU原理详解及代码实现:
(1)角度损失(Angle cost),定义如下:
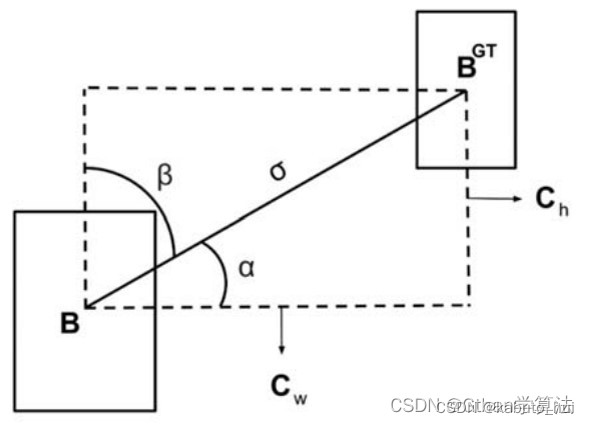
Λ = 1 − 2 ∗ sin 2 ( arcsin ( c h σ ) − π 4 ) = cos ( 2 ∗ ( arcsin ( c h σ ) − π 4 ) ) \Lambda=1-2 * \sin ^2\left(\arcsin \left(\frac{c_{\mathrm{h}}}{\sigma}\right)-\frac{\pi}{4}\right)=\cos \left(2 *\left(\arcsin \left(\frac{c_{\mathrm{h}}}{\sigma}\right)-\frac{\pi}{4}\right)\right) Λ=1−2∗sin2(arcsin(σch)−4π)=cos(2∗(arcsin(σch)−4π))
其中 c h c_h ch为真实框和预测框中心点的高度差, σ \sigma σ为真实框和预测框中心点的距离,事实上 arcsin ( c h σ \arcsin (\frac{c_h}{\sigma} arcsin(σch)等于角度 α \alpha α
c h σ = sin ( α ) σ = ( b c x g t − b c x ) 2 + ( b c y g t − b c y ) 2 c h = max ( b c y g t , b c y ) − min ( b c y g t , b c y ) \begin{gathered} \frac{c_h}{\sigma}=\sin (\alpha) \\ \sigma=\sqrt{\left(b_{c_x}^{g t}-b_{c_x}\right)^2+\left(b_{c_y}^{g t}-b_{c_y}\right)^2} \\ c_h=\max \left(b_{c_y}^{g t}, b_{c_y}\right)-\min \left(b_{c_y}^{g t}, b_{c_y}\right) \end{gathered} σch=sin(α)σ=(bcxgt−bcx)2+(bcygt−bcy)2ch=max(bcygt,bcy)−min(bcygt,bcy)
( b c x g t , b c y g t ) \left(b_{c_x}^{g t}, b_{c_y}^{g t}\right) (bcxgt,bcygt) 为真实框中心坐标 ( b c x , b c y ) \left(b_{c_x}, b_{c_y}\right) (bcx,bcy) 为预测框中心坐标,可以注意到当 α \alpha α 为 π 2 \frac{\pi}{2} 2π 或 0 时,角度损失为 0 ,在训练过程中若 α < π 4 \alpha<\frac{\pi}{4} α<4π ,则最小化 α \alpha α ,否则最小化 β \beta β。
(2)距离损失(Distance cost),定义如下:
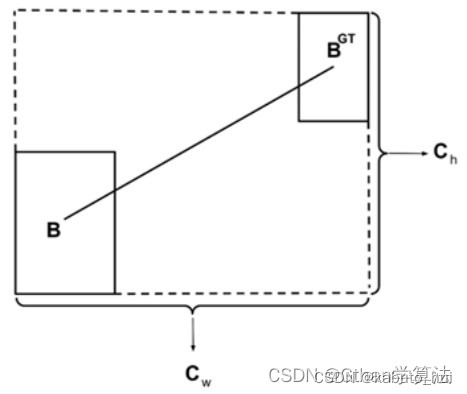
Δ = ∑ t = x , y ( 1 − e − γ ρ t ) = 2 − e − γ ρ x − e − γ ρ y ρ x = ( b c x g t − b c x c w ) 2 , ρ y = ( b c y g t − b c y c h ) 2 γ = 2 − Λ \Delta=\sum_{t=x, y}\left(1-e^{-\gamma \rho_t}\right)=2-e^{-\gamma \rho_{\mathrm{x}}}-e^{-\gamma \rho_y} \\ \rho_x=\left(\frac{b_{c_x}^{g t}-b_{c_x}}{c_w}\right)^2, \quad \rho_y=\left(\frac{b_{c_y}^{g t}-b_{c_y}}{c_h}\right)^2 \quad \gamma=2-\Lambda Δ=t=x,y∑(1−e−γρt)=2−e−γρx−e−γρyρx=(cwbcxgt−bcx)2,ρy=(chbcygt−bcy)2γ=2−Λ
注意: 这里的 ( c w , c h ) \left(c_{\mathrm{w}}, c_h\right) (cw,ch) 为真实框和预测框最小外接矩形的宽和高(3)形状损失(Shape cost),定义如下:
Ω = ∑ t = w , h ( 1 − e − w t ) θ = ( 1 − e − w w ) θ + ( 1 − e − w h ) θ w w = ∣ w − w g t ∣ max ( w , w g t ) , w h = ∣ h − h g t ∣ max ( h , h g t ) \Omega=\sum_{\mathrm{t}=\mathrm{w}, \mathrm{h}}\left(1-\mathrm{e}^{-\mathrm{w}_{\mathrm{t}}}\right)^\theta=\left(1-\mathrm{e}^{-\mathrm{w}_{\mathrm{w}}}\right)^\theta+\left(1-\mathrm{e}^{-\mathrm{w}_{\mathrm{h}}}\right)^\theta \\ \mathrm{w}_{\mathrm{w}}=\frac{\left|\mathrm{w}-\mathrm{w}^{\mathrm{gt}}\right|}{\max \left(\mathrm{w}, \mathrm{w}^{\mathrm{gt}}\right)}, \quad \mathrm{w}_{\mathrm{h}}=\frac{\left|\mathrm{h}-\mathrm{h}^{\mathrm{gt}}\right|}{\max \left(\mathrm{h}, \mathrm{h}^{\mathrm{gt}}\right)} Ω=t=w,h∑(1−e−wt)θ=(1−e−ww)θ+(1−e−wh)θww=max(w,wgt)∣w−wgt∣,wh=max(h,hgt)∣h−hgt∣
( w , h ) (\mathrm{w}, \mathrm{h}) (w,h) 和 ( w g t , h g t ) \left(\mathrm{w}^{\mathrm{gt}}, \mathrm{h}^{\mathrm{gt}}\right) (wgt,hgt) 分别为预测框和真实框的宽和高, θ \theta θ 控制对形状损失的关注程度,为了避免过于关注形状损失而降低对预测框的移动,作者使用遗传算法计算出 θ \theta θ 接近 4 ,因此作者定于 θ \theta θ 参数范围为 [2, 6]。 -
(4)最后SIOU损失函数定义如下:
Loss
S
I
o
U
=
1
−
I
o
U
+
Δ
+
Ω
2
\operatorname{Loss}_{\mathrm{SIoU}}=1-\mathrm{IoU}+\frac{\Delta+\Omega}{2}
LossSIoU=1−IoU+2Δ+Ω
- Tricks: YOLOv6进行了很多蒸馏方向上的尝试。比如Self-distillation,Reparameterizing Optimizer,使用 Channel-wise Distillation进行量化感知训练等方法,进一步加强模型的整体性能。
8 YOLOv7(2022,Chien-Yao Wang)
Paper:https://arxiv.org/pdf/2207.02696.pdf/
Github:https://github.com/WongKinYiu/yolov7/
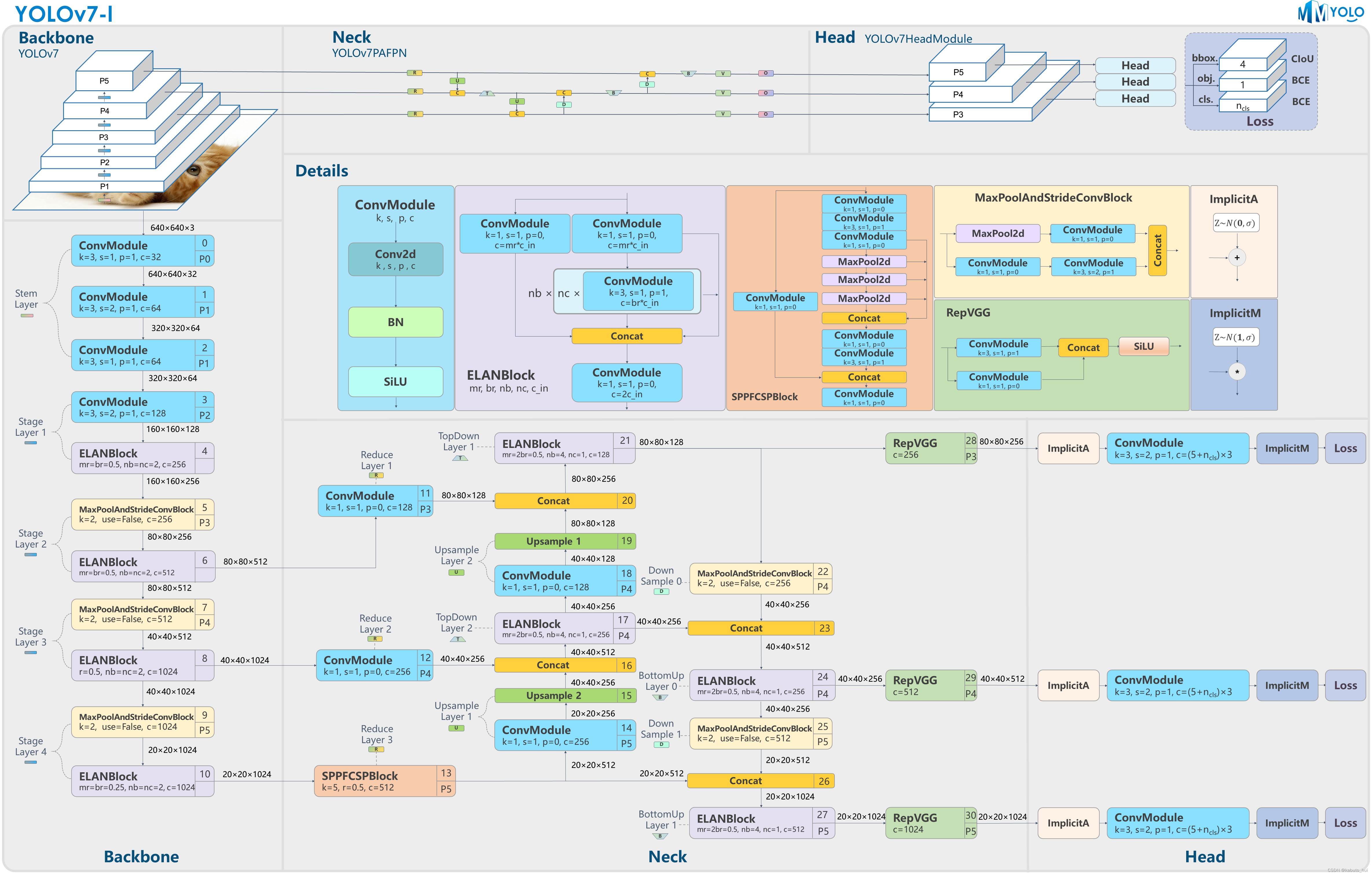
Source: MMYOLO-Github
- Input: 整体上沿用v5的逻辑;
- Backbone: YOLOv7的Backbone结构在YOLOv5的基础上,设计了E-ELAN和MPConv结构。MPConv结构由常规卷积与maxpool双路径组成,增加模型对特征的提取融合能力。

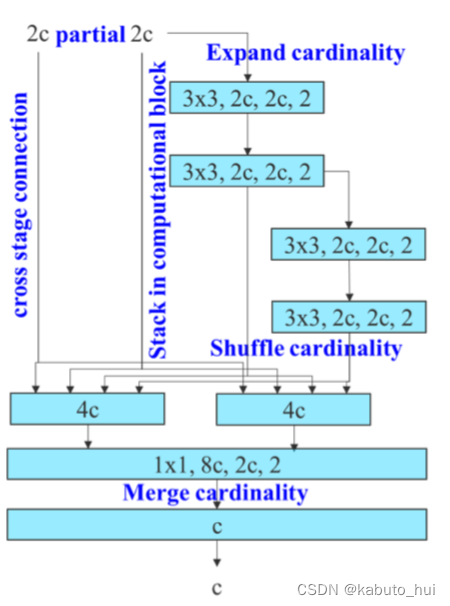
- Neck: YOLOv7的Neck结构主要包含了SPPSCP模块和优化的PAN模块。SPPCSP模块在SPP模块基础上在最后增加concat操作,与SPP模块之前的特征图进行融合,更加丰富了特征信息。PAN模块引入E-ELAN结构,使用expand、shuffle、merge cardinality等策略实现在不破坏原始梯度路径的情况下,提高网络的学习能力。
- Head: YOLOv7的Head结构使用了和YOLOv5一样的损失函数,引入RepVGG style改造了Head网络结构,并使用了辅助头(auxiliary Head)训练以及相应的正负样本匹配策略。
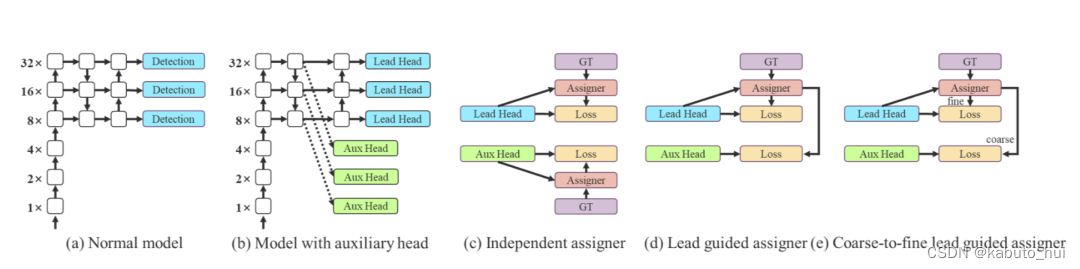
辅助头训练策略以及相应的正负样本匹配策略:
YOLOv7在Head结构引入了辅助头(auxiliary Head)进行训练。正常网络训练如上图(a)所示,而用辅助头参与训练时,将对模型的训练进行深度监督,如上图(b)所示。将辅助头和检测头的损失进行融合,相当于在网络高层进行局部的模型ensemble操作,提升模型的整体性能。
上图(d)中,lead head和auxiliary head使用一样的正负样本匹配策略,通过让浅层的auxiliary head学习到lead head已经获得的特征,让lead head更能专注于学习尚未学习到的剩余特征。
而上图(e)中,在使用lead head和auxiliary head一起优化模型的时候,auxiliary head的正样本是较为“粗糙的“,主要是通过放宽正样本分配过程的约束来获得更多的正样本。lead head中的一个anchor如果匹配上ground truth,则分配3个正样本,而同样的情况下auxiliary head分配5个。lead head中将top10个样本IOU求和取整,而auxiliary head中取top20。auxiliary head的学习能力不如lead head强,为了避免丢失需要学习的信息,将重点优化auxiliary head的召回率。而lead head可以从高recall的结果中筛选出高精度的结果作为最终输出。lead head和auxiliary head的损失函数权重设置为4:1。
9 YOLOv8(2023, Ultralytics)
Paper:无
Github:https://github.com/ultralytics/ultralytics/
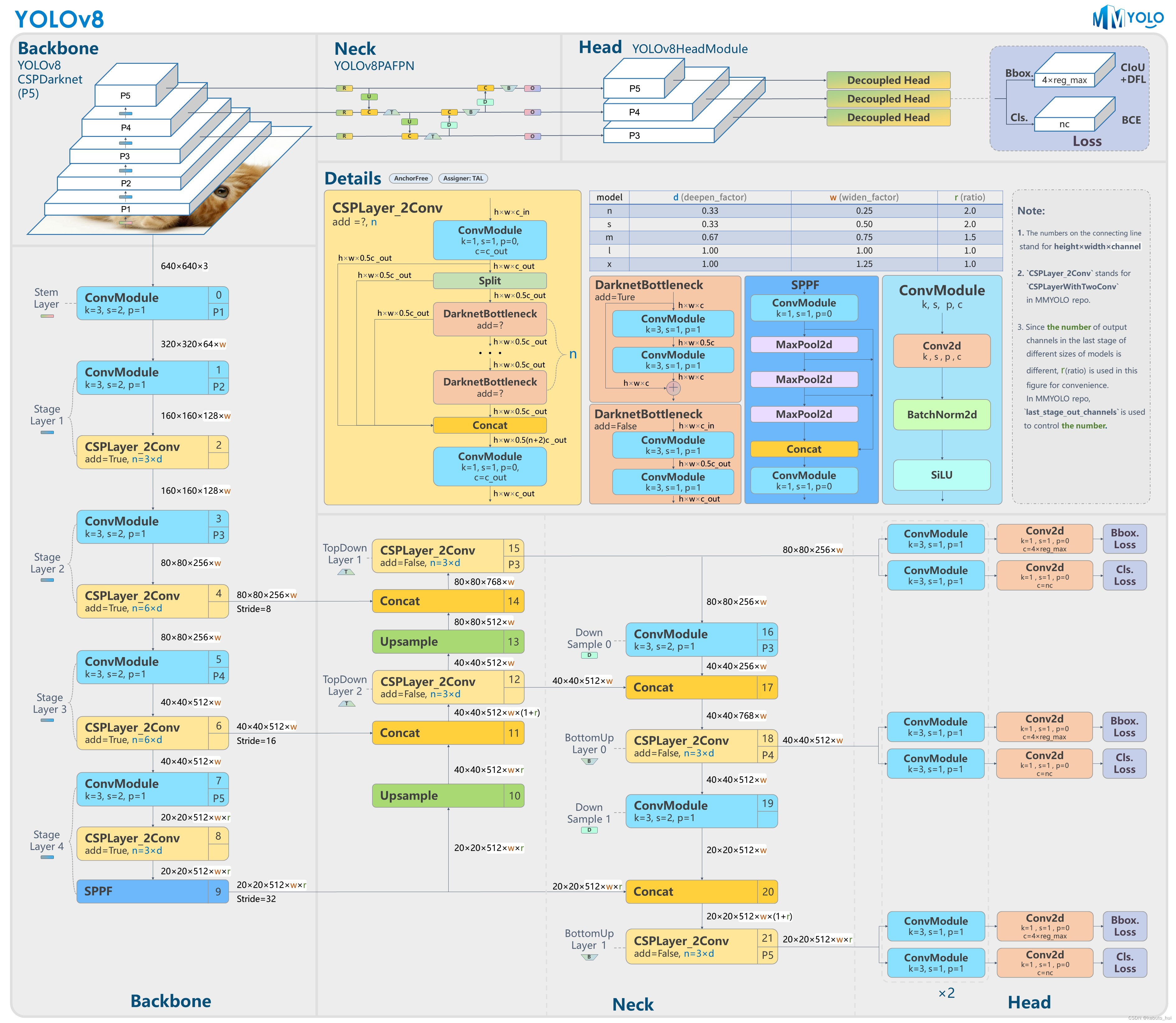
Source: MMYOLO-Github
-
Backbone: 沿用CSPDarknet;
-
Neck: Neck部分参考了v7 ELAN设计思想,将v5中的C3结构换成了梯度流更丰富的C2f结构,不过C2f结构中存在Split操作,对特定硬件就不是很友好了;
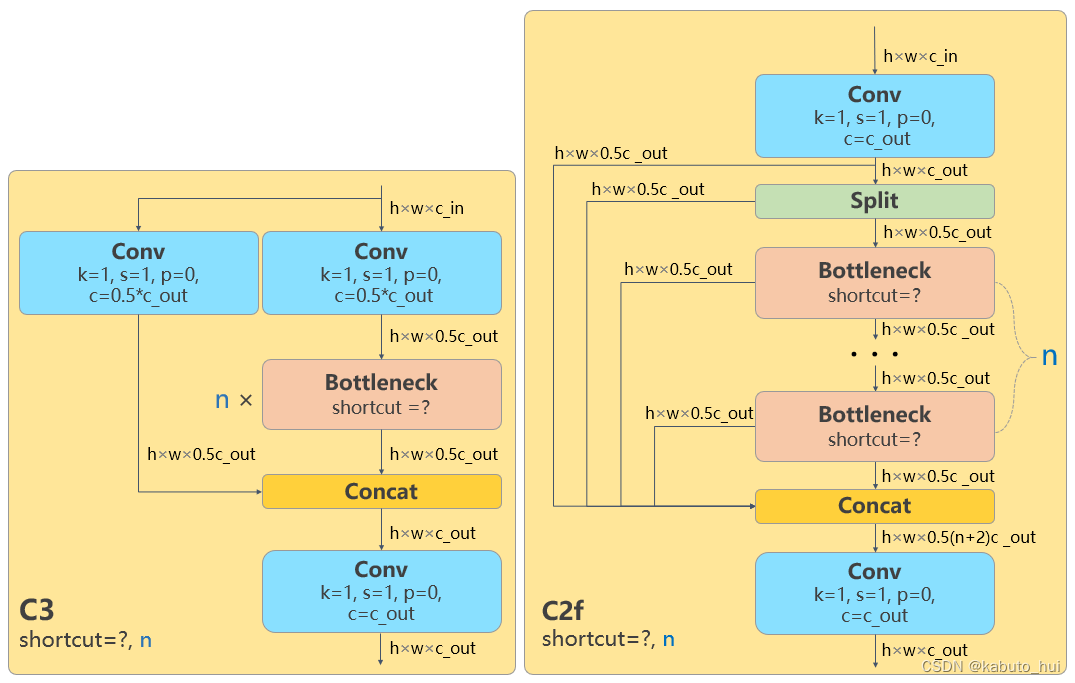
Source: YOLOV8 原理和实现全解析 -
Head: Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free。且不再有objectness分支,只有解耦的分类和回归的分支,并且回归分支使用了distribution focal loss中提出的积分形式表示法。
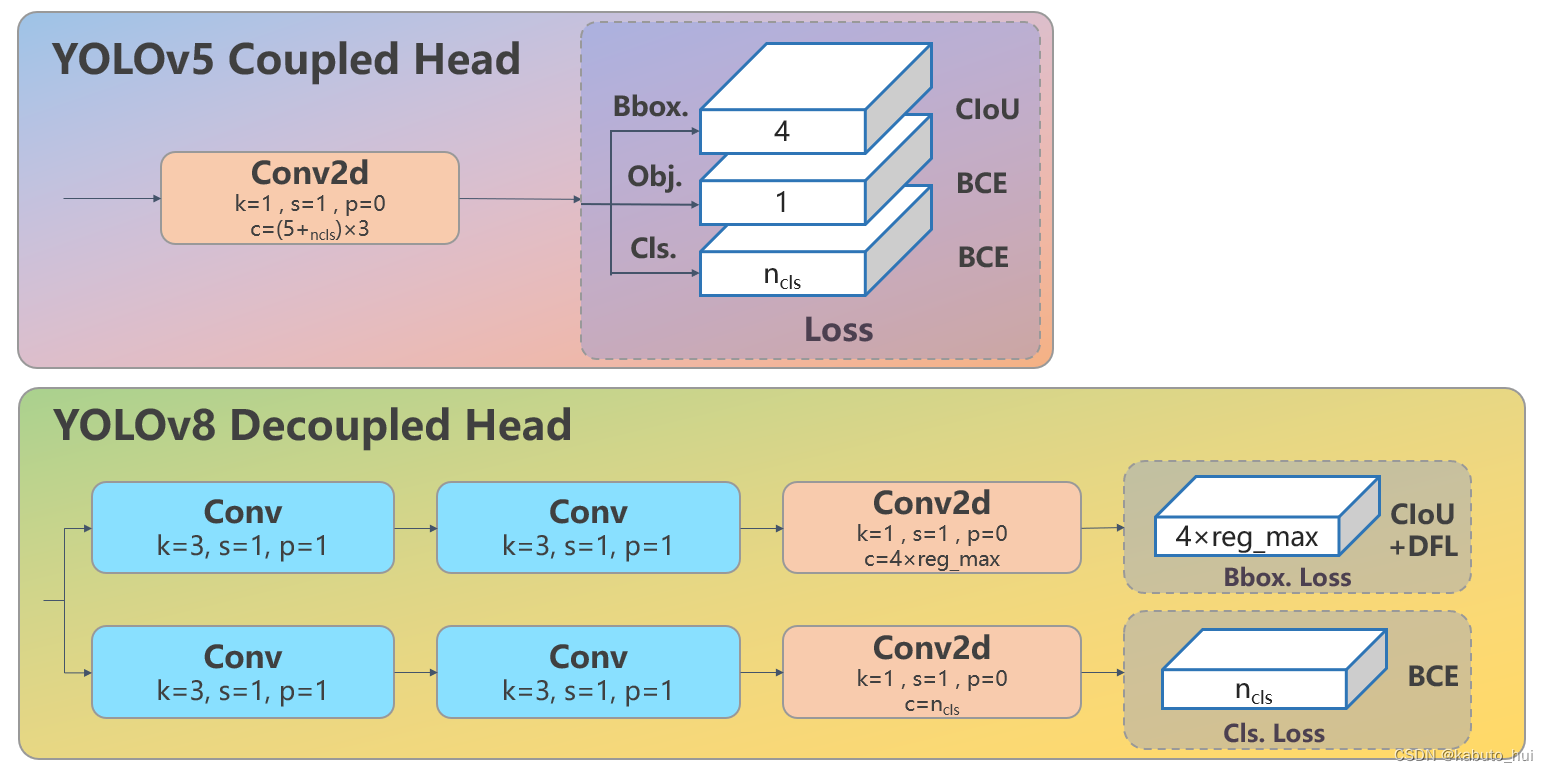
Source: YOLOV8 原理和实现全解析网络回归的目标: 是anchor点到4个边界的l、t、b、r的距离

网络最终的输出为: channel数量是 4 x r e g m a x ( 一般设置为 16 , 16 x 下采样倍数>输入分辨率的一半 ) 4 x reg_max(一般设置为16,16 x 下采样倍数 > 输入分辨率的一半) 4xregmax(一般设置为16,16x下采样倍数>输入分辨率的一半),16表示16个分类,将ltbr的回归任务变成了分类任务,最后通过softmax之后再与(0~15)的正数进行加权得到最后的检测框结果。分类头的channel数量与类别数量一致。最后输出的特征图上的每个位置都代表一个anchor点。

Source: 算法小乔-YOLOv8-训练流程-正负样本分配 -
Tricks: 最后10个epoch关闭Mosiac增强,可以有效提升精度。
Loss 计算: 采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss。其中分类分支依然采用BCE Loss,回归分支使用了Distribution Focal Loss。
-
TaskAlignedAssigner的匹配策略 :根据分类与回归的分数加权的分数去选择正样本。
t = s α + u β t = s^{\alpha} + u^{\beta} t=sα+uβ
针对每一个gt,其中s是每个点对应的gt类别的分类置信度,u是每个点对应预测的回归框与gt的IoU,两者相乘就可以衡量对齐程度alignment metrics。再直接基于对齐程度选取topk作为正样本。 -
Distribution Focal Loss , 参考distribute focal loss 详解。v8中对于检测框的回归任务转化成了分类任务,为了使网络尽快把值集中到label y,增大其最接近的两个label即可: y i ≤ y ≤ y i + 1 y_i \leq y \leq y_{i+1} yi≤y≤yi+1。于是DFL可以表示为:
D F L ( S i , S i + 1 ) = − ( ( y i + 1 − y ) l o g ( S i ) + ( y − y i ) l o g ( S i + 1 ) ) S i = y i + 1 − y y i + 1 − y i , S i + 1 = y − y i y i + 1 − y i DFL(S_i, S_{i+1}) = -((y_{i+1} - y)log(S_i) + (y - y_i)log(S_{i+1})) \\ S_i = \frac{y_{i+1} - y}{y_{i+1} - y_i}, S_{i+1} = \frac{y - y_i}{y_{i+1} - y_i} DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))Si=yi+1−yiyi+1−y,Si+1=yi+1−yiy−yi
具体实施过程如下图,参考算法小乔-YOLOv8-损失函数:
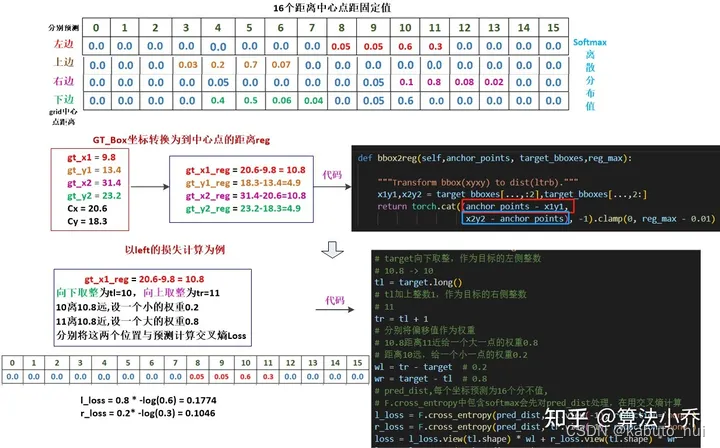
Source: 算法小乔-YOLOv8-损失函数
其实就是将anchor点到gt框四个边界的归一化距离*15,得到其分类的目标,这个值肯定是一个小数,分别向下和向上取整就得到了所谓的 y i y_i yi和 y i + y_{i+} yi+,所以 ( y i + 1 − y i ) (y_{i+1} - y_i) (yi+1−yi)一般就是1了,再根据距离的远近来设置loss的权重。 -
边界框回归: 使用CIoU Loss
从上面可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身。
10 YOLOv9(2024, Wang Chien-Yao)
Paper:https://arxiv.org/pdf/2402.13616.pdf/
HuggingFace Demo:https://hf-mirror.com/spaces/kadirnar/Yolov9/
Github:https://github.com/WongKinYiu/yolov9/
Blog:YOLOv9理性解读 | 网络结构&损失函数&耗时评估
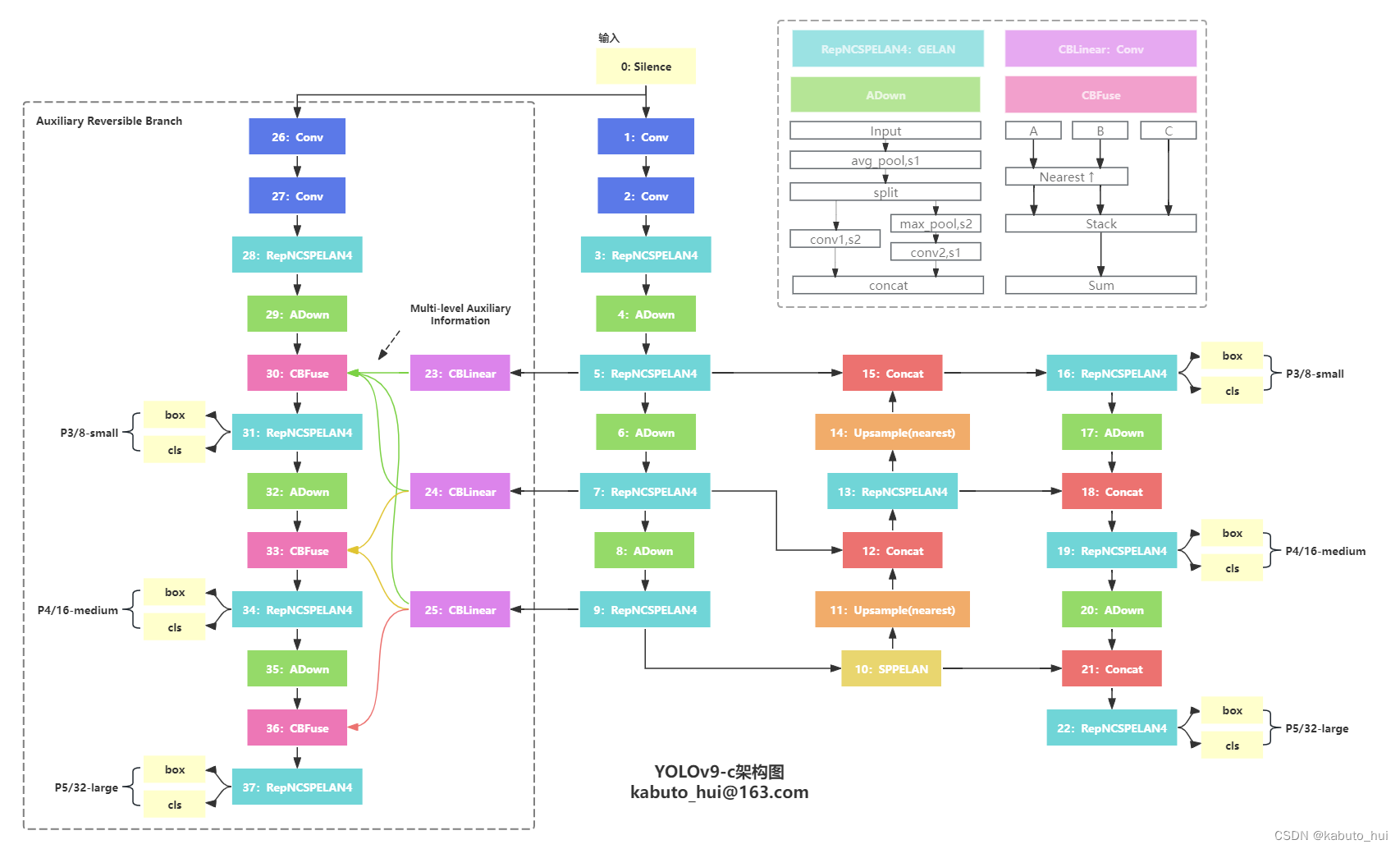
- Backbone:
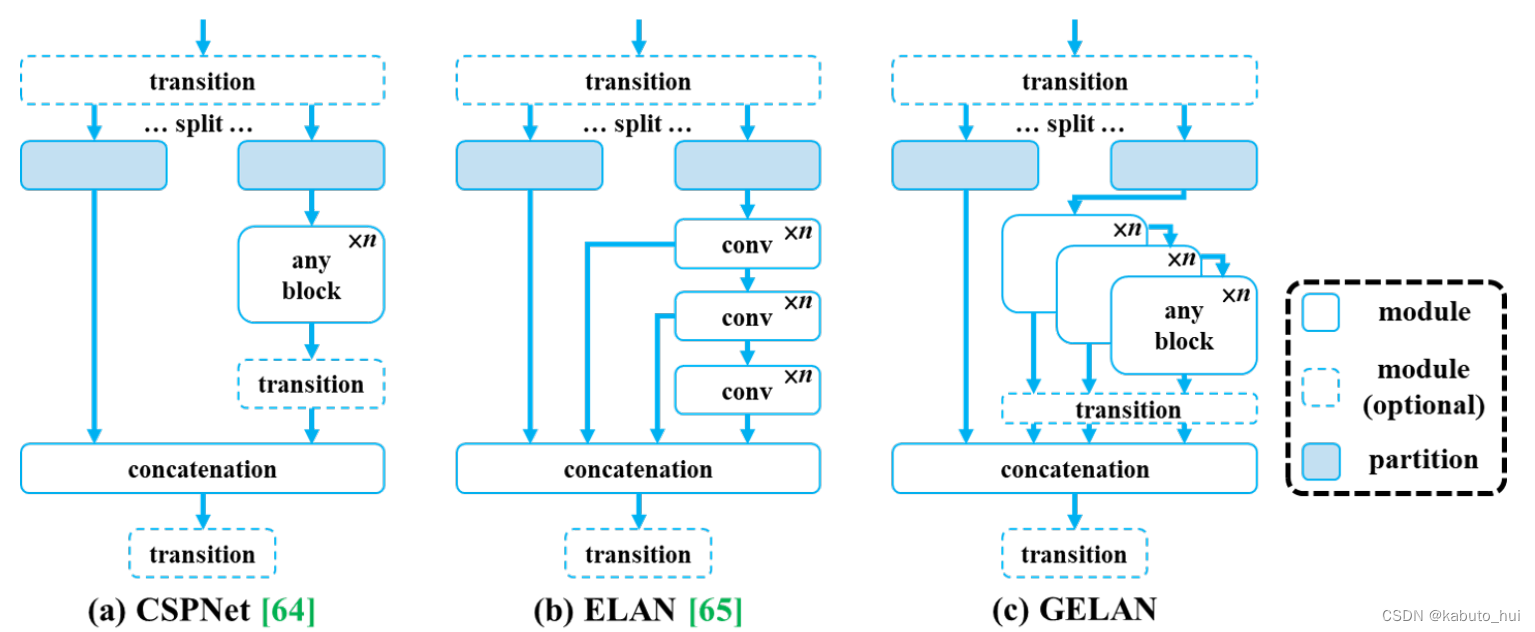
- 将CSPDarknet结构中的CSP block替换成了图中RepNCSPELAN4结构,也就是文章中提到的Generalized Efficient Layer Aggregation Netwwork(GELAN)
- 独立的辅助主干网络,用于计算辅助头
- 将CSPDarknet结构中的CSP block替换成了图中RepNCSPELAN4结构,也就是文章中提到的Generalized Efficient Layer Aggregation Netwwork(GELAN)
- Neck: 沿用PAN的设计
- Head: 沿用v8解耦头的设计
正负样本匹配策略:
样本匹配依旧使用的是TaskAlign样本匹配。和YOLOv8、YOLOv6等算法保持一致;TaskAlignedAssigner的匹配策略就是:根据分类与回归的分数加权的分数去选择正样本。
t
=
s
a
∗
u
b
t = s^{a}*u^{b}
t=sa∗ub
针对每一个gt,其中s是每个anchor点对应的gt类别的分类置信度,u是每个anchor点对应预测的目标框与gt的IoU,a,b表示外部配置的指数,两者相乘就可以衡量对齐程度alignment metrics。再直接基于对齐程度选取topk作为正样本。
损失函数:
- 分类损失:BCE Loss
- 回归损失:DFL Loss + CIoU Loss
总体评价:
- 相较于之前的YOLOv8,YOLOv9指标并没有显著的提升;
- v9以牺牲耗时为代价,换来部分指标提升,整体网络结果对于板端部署并不友好,耗时可能会相较于项目中使用的模型会偏高;
- 在耗时允许范围内,使用YOLOv9,相同量级参数下,指标可能会好一些,需要在实际业务上测试。
参考资料
[1] 江大白-深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
[2] WethinkIn-深入浅出完整解析YOLOv1-v7全系列模型核心基础知识(全方位汇总篇)
[3] YOLOX中的SimOTA正负样本分配策略
[4] MMYOLO-YOLOV6 原理和实现全解析
[5] YOLOv6:又快又准的目标检测框架开源啦
[6] 边框回归损失函数SIoU原理详解及代码实现
[7] YOLOV8 原理和实现全解析
[8] distribute focal loss 详解
[9] 算法小乔-YOLOv8-训练流程-正负样本分配
[10] 算法小乔-YOLOv8-损失函数
[11] YOLOv9理性解读 | 网络结构&损失函数&耗时评估


















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









