






论文链接
BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection
0. Abstract
- 提出了一种新的 3D 物体检测器,具有值得信赖的深度估计,称为 BEVDepth,用于基于相机的鸟瞰 (BEV) 3D 物体检测
- BEVDepth通过利用显式深度监控来解决深度估计不足的问题,还引入了一个具有相机意识的深度估计模块,以促进深度预测能力
- 设计了一个新颖的深度细化模块,以对抗不准确特征反投影所带来的副作用
1. Intro
本文的问题:检测器中学到的深度质量是否真正满足精确的3D物体检测的要求 ?
- LSS 机制中存在三个缺陷
- 深度不准确:由于深度预测模块直接受最终检测损失监督,绝对深度的质量远未令人满意
- 深度模块过拟合: 大多数像素无法预测出合理的深度,这意味着它们在学习阶段没有得到适当的训练
- BEV语义不准确 :LSS 中学到的深度将图像特征投射到三维视体特征中,然后进一步汇总为BEV特征,由于深度不准确,只有部分特征被投射到正确的BEV位置,导致BEV语义不准确
- 提出 BEVDepth
- 一种新的多视角3D检测器,利用来自点云的深度监督来指导深度学习
- 创新地提出将相机内参和外参编码到深度学习模块中,使得检测器对各种相机设置都具有稳健性
- 进一步引入了深度细化模块来改进学习到的深度
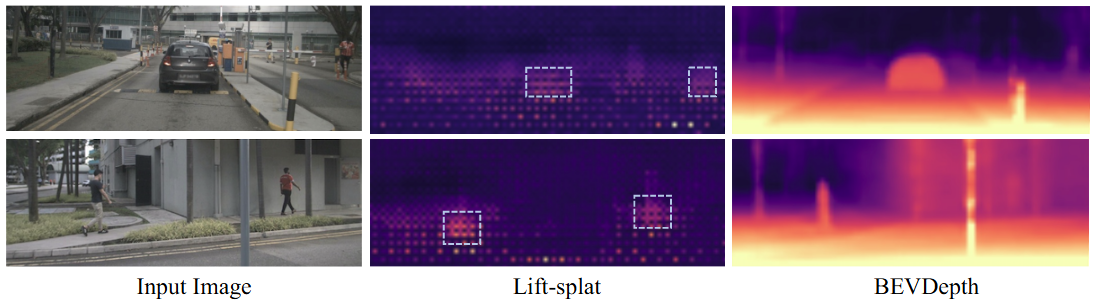
Fig.1 深度估计结果在Lift-splat检测器和BEVDepth中得以实现。虚线框突出显示了Lift-splat检测器在通常情况下能够进行"相对"准确的深度预测的区域,通常是物体和地面之间的连接区域
2. Related Work
基于视觉的三维物体检测
- 基于视觉的3D检测的目标是预测物体的3D边界框
- 从单眼图像中估计物体的深度本质上是不确定的。即使有多视角摄像机,估计没有重叠视图的区域的深度仍然具有挑战性
- 相关工作:
- 直接从2D图像特征预测3D边界框
- 预测三维空间中的物体
基于LiDAR的3D物体检测
- 由于深度估计的准确性,基于激光雷达的三维检测方法经常在自动驾驶感知任务中使用
- VoxelNet 将点云进行体素化,将其从稀疏体素转换为密集体素,然后在密集空间中提出边界框以在卷积过程中辅助索引
- PointPillars 使用柱状结构编码点云,而不是3D卷积过程,使其快速但仍保持良好性能
- CenterPoint 提出了一种无锚点检测器,将CenterNet 扩展到3D空间
深度估计
- 深度预测对于单目图像解释至关重要
- MVSNet 首次将代价体引入深度估计领域
- 使用多尺度融合生成深度预测,并引入自适应模块同时提高性能和减少内存消耗
3. 深入研究 LSS 中的深度预测
- 首先回顾了基准3D检测器的整体结构。
- 然后,对基准检测器进行了一项简单实验,以揭示观察到的先前现象的原因
- 最后讨论了这个检测器存在的三个不足之处,并指出了一个潜在的解决方案
3.1 基本检测器的模型体系结构
-
基于 Lift-splat 的检测器将 LSS 中的分割头替换为 CenterPoint 的3D检测头
其架构由四个部分组成
-
提取 2D 特征的图像编码器: F 2 d = { F i 2 d ∈ R C F × H × W , i = 1 , 2 , . . . , N } F^{2d} = \{F^{2d}_i∈ \mathbb{R}^{C_F ×H×W} , i = 1, 2, ..., N\} F2d={Fi2d∈RCF×H×W,i=1,2,...,N} 来自 N 个视图的输入图像 I = { I i , i = 1 , 2 , . . . , N } I = \{I_i, i = 1, 2, ..., N\} I={Ii,i=1,2,...,N},其中 H H H、 W W W 和 C F C_F CF 分别代表特征的高度、宽度和通道数
-
深度网络:根据图像特征 F 2 d F^{2d} F2d 估计图像深度 D p r e d = { D i p r e d ∈ R C D × H × W , i = 1 , 2 , . . . , N } D^{pred} = \{D^{pred}_i∈ \mathbb{R}^{C_D×H×W} , i = 1, 2, ..., N\} Dpred={Dipred∈RCD×H×W,i=1,2,...,N},其中 C D C_D CD 代表深度箱的数量
-
视图变换器:使用方程式将 F 2 d F^{2d} F2d 投影到 3D 表示 F 3 d F^{3d} F3d 中,然后将它们汇集到一个集成的 BEV 表示 F b e v F^{bev} Fbev 中
F i 3 d = F i 2 d ⊗ D i p r e d , F i 3 d ∈ R C F × C D × H × W (1) F^{3d}_i = F^{2d}_i ⊗ D^{pred}_i\ ,\ \ \ \ F^{3d}_i ∈ \mathbb{R}^{C_F ×C_D×H×W} \tag{1} Fi3d=Fi2d⊗Dipred , Fi3d∈RCF×CD×H×W(1) -
3D 检测头:预测类别、3D 框偏移和其他属性
-
3.2 Making Lift-Splat Work Is Easy
-
学习深度 D p r e d D^{pred} Dpred 被认为是至关重要的,因为它用于为后续任务构建 BEV 表示
-
通过将 D p r e d D^{pred} Dpred 替换为随机初始化的张量,并在训练和测试阶段冻结它,将 D p r e d D^{pred} Dpred 替换为随机化的软值后,LSS 的 mAP 仅下降了3.7%(从28.2%降至24.5%)
-
证明只要正确位置上的深度有激活,检测头就可以工作。解释了 LSS 大多数区域学习到的深度较差,但检测mAP仍然合理

表1 评估在 nuScenes 验证集上的深度预测。 "soft"和"hard"分别表示深度维度上的高斯随机化和 one-hot 随机化
3.3 Making Lift-Splat Work Well Is Hard
- 揭示了 Lift-splat 现有工作机制中存在的三个不足之处,包括深度不准确、深度模块过拟合和BEV语义不精确
- 为了更清晰地展示这种想法比较了两个基准线
- 一个是基于天线射频技术的检测器,命名为基检测器(Base Detector)
- 另一个利用额外的深度监督从点云数据中派生出来的检测器 D p r e d D^{pred} Dpred,将其称为增强检测器(Enhanced Detector)
深度不准确
-
在基检测器中,深度模块的梯度来自检测损失,这是一种间接的方法。使用常用的深度估计度量评估了在 nuScenes val 上学习到的深度 D p r e d D^{pred} Dpred,包括尺度不变的对数误差(SILog)、平均绝对相对误差(Abs Rel)、平均平方相对误差(Sq Rel)和均方根误差(RMSE)
-
评估了两个探测器在两种不同的协议下
-
每个对象的所有像素
-
每个对象的最佳预测像素

表2 评估 nuScenes 验证集上的深度预测结果。DL 代表深度损失。所有前景点均用于评估。
-
深度模块过拟合
-
基检测器只学习在部分区域预测深度。大多数像素没有经过训练来预测合理的深度,这引发了对深度模块的泛化能力的担忧。(即该检测器对于超参数非常敏感)
-
选择“图像尺寸”作为变量,进行以下实验来研究模型的泛化能力
-
首先使用输入尺寸为256×704来训练基础检测器和增强检测器
-
然后分别使用192×640、256×704和320×864这几种尺寸进行测试

Fig.2 检测器对图像大小的鲁棒性测试。我们使用256×704进行训练。在nuScenes上报告mAP
-
BEV语义不精确
-
没有深度监督时,图像特征不能被正确地反投影。因此,池化操作只能聚合部分语义信息

Fig.3 与基准检测器(左侧)相比,改进的检测器(右侧)在特征反投影过程中保留了更多的结构信息,因此能够提供精确的语义信息。每个点表示一个图像特征。
-
假设贫乏的深度对于分类任务是有害的。然后,我们使用两个模型的分类热图,并将它们的TP /(TP + FN)作为比较的指标进行评估,其中TP表示将反投影头正确分类的锚点/特征,被分配为正样本,而FN表示相反的意思

表3 对 nuScenes val 数据集进行分类。我们使用分类热图进行评估,th 表示热图的阈值。 -
意识到在多视图3D检测器中赋予更好的深度的必要性,并提出了解决方案——BEVDepth
4. BEVDepth
BEVDepth是一种带有可靠深度的新型多视角3D检测器。它利用相机感知深度预测模块(DepthNet)上的显式深度监督,结合未投影视锥特征上的新型深度细化模块,实现这一目标。
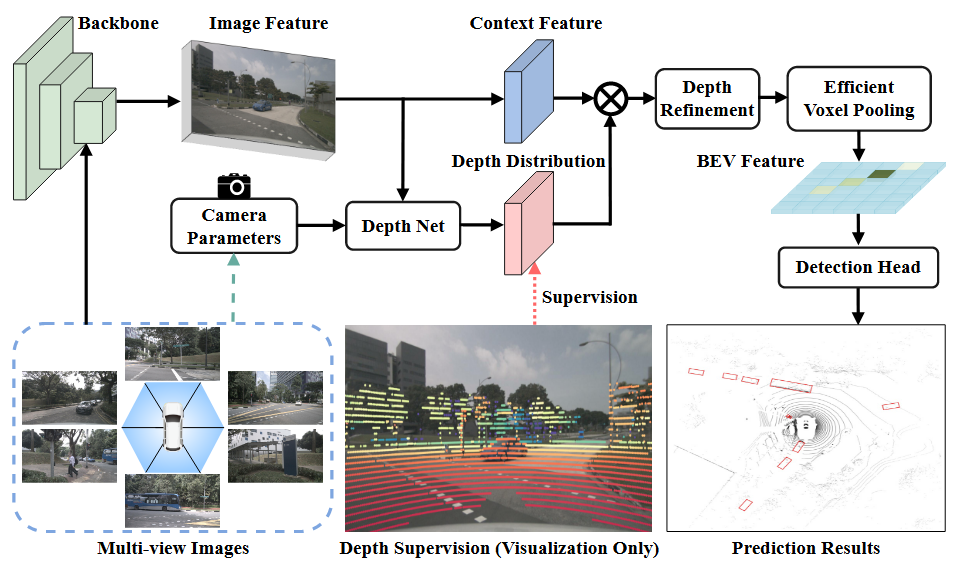
Fig. 4 BEVDepth框架。图像主干从多视图图像中提取图像特征。深度网络以图像特征作为输入,生成上下文和深度,并得到最终的点特征。体素池将所有点特征统一到一个坐标系统中,并将它们池化到BEV特征图上。
明确的深度监督
-
在基检测器中,深度模块的唯一监督来自于检测损失。然而,由于单目深度估计的困难,仅仅使用一个检测损失远远不足以对深度模块进行监督
-
**提出使用由点云数据 P 导出的地面实况 D g t D^{gt} Dgt 来监督中间深度预测 D p r e d D^{pred} Dpred **
P i i m g ^ ( u d , v d , d ) = K i ( R i P + t i ) (2) P^{\hat{img}}_i (ud, vd, d) = K_i(R_iP + t_i) \tag{2} Piimg^(ud,vd,d)=Ki(RiP+ti)(2)
进一步转换为2.5D图像坐标 P i i m g ( u , v , d ) P^{img}_i(u,v,d) Piimg(u,v,d),其中 u 和 v 表示像素坐标,为了对齐投影的点云和预测的深度之间的形状,对 P i i m g P^{img}_i Piimg 采用最小池化和独热编码,将这两个操作一起定义为 ϕ \phi ϕ
D i g t = ϕ ( P i i m g ) (3) D^{gt}_i = \phi(P^{img}_i)\tag{3} Digt=ϕ(Piimg)(3)
相机感知的深度预测
-
将相机内参作为DepthNet的输入之一
- 首先将相机内参的维度通过MLP层进行缩放。
- 然后,使用 Squeeze-and-Excitation 模块对图像特征 F i 2 d F^{2d}_i Fi2d 进行重新加权。
- 最后,将相机外参与其内参连接起来,以帮助 DepthNet 了解 F 2 d F^{2d} F2d 在自身坐标系中的空间位置
设 ψ \psi ψ 为原始 DepthNet,整体的相机感知深度预测可以写成
D i p r e d = ψ ( S E ( F i 2 d ∣ M L P ( ξ ( R i ) ⊕ ξ ( t i ) ⊕ ξ ( K i ) ) ) ) (4) D^{pred}_i = ψ(SE(F^{2d}_i |MLP (ξ(R_i) ⊕ ξ(t_i) ⊕ ξ(K_i)))) \tag{4} Dipred=ψ(SE(Fi2d∣MLP(ξ(Ri)⊕ξ(ti)⊕ξ(Ki))))(4)
其中,ξ 表示 Flatten 操作。在 DepthNet 内部建模相机参数,旨在提高中间深度的质量。由于 LSS 的分离特性的好处,相机感知的深度预测模块与检测头隔离,因此在这种情况下,回归目标不需要改变,从而增加了可扩展性
深度细化模块
- 为了进一步提高深度质量,设计了一个新颖的深度细化模块
- 首先将 F 3 d F^{3d} F3d 从 [ C F , C D , H , W ] [C_F,C_D,H,W] [CF,CD,H,W] 重塑为 [ C F × H , C D , W ] [C_F × H,C_D,W] [CF×H,CD,W],并在 C D × W C_D × W CD×W 平面上堆叠几个3×3的卷积层。最后将其输出重塑回来,并输入到后续的 Voxel/Pillar Pooling 操作中
- 一方面,当深度预测置信度低时,深度细化模块可以沿深度轴聚合特征
- 另一方面,当深度预测不准确时,深度细化模块可以在理论上将其细化到正确的位置,只要接受域足够大即可
- 深度细化模块赋予了 View Transformer 阶段一个校正机制,使其能够修正那些摆放不当的特征
5. Experiment
5.1 实验设置
数据集和指标
- 数据集: nuScenes
- 指标:nuScenes检测分数(NDS)、平均精度(mAP)以及五个真阳性(TP)指标,包括平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)、平均速度误差(mAVE)和平均属性误差(mAAE)
实施细节
- 使用 ResNet-50 作为图像主干,图像大小处理为256×704。采用图像数据增强,包括随机裁剪、随机缩放、随机翻转和随机旋转,还采用BEV数据增强,包括随机缩放、随机翻转和随机旋转
- 使用 AdamW 作为优化器,学习率设置为 2e-4,批量大小设置为64
- 对于消融研究,所有实验都在不使用 CBGS 策略的情况下训练了24个周期。与其他方法相比,BEVDepth 使用 CBGS 训练了20个周期。摄像头感知 DepthNet 位于特征层,步幅为16
5.2 消融实验
组件分析
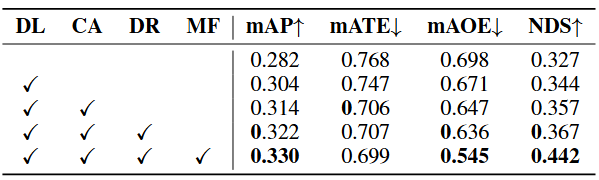
表4 Depth Loss(深度丧失),Camera-awareness(相机感知)和Depth Refinement Module(深度细化模块)对nuScenes验证集进行消融研究。DL,CA,DR和MF分别表示Depth Loss(深度丧失),相机感知,深度细化模块和多帧
- 基准 BEVDepth 获得28.2%的mAP和32.7%的 NDS,添加深度损失将 mAP 提高了2.2%
- mATE 略微降低 0.21,因为原始的BEVDepth已经在检测损失的帮助下部分学习了深度预测。将相机参数建模到 DepthNet 中进一步减小了mATE 0.41,揭示了相机感知的重要性
- 深度细化模块将mAP提高了0.8%
深度损失
-
在深度估计领域中,BCE和L1Loss是两种常见的损失函数。在本部分中,我们剔除了在DepthNet中使用这两种不同损失函数的影响,发现不同的深度损失几乎不会影响最终的检测性能

表5 不同深度损失的消融研究,包括BCELoss和L1Loss。结果在nuScenes val上报告
深度细化模块
-
在效率方面,最初在其中采用了3×3卷积。在这里,消除了包括1×3、3×1和3×3在内的不同卷积核来研究其机制
-
当在 C D × W C_D × W CD×W 维度上使用1×3卷积时,信息不会沿深度轴交换,并且检测性能几乎不受影响。当使用3×1卷积时,特征可以在深度轴上相互交互,对应地提高了 mAP 和 NDS。这类似于使用原始的 3×3 卷积,揭示了该模块的本质

表6 深度细化模块中卷积核的消融研究。结果报告在nuScenes验证集上
5.3 基准测试结果
高效的体素池化
- 现有的Lift-splat中的 Voxel Pooling 利用了涉及“排序”和“累积求和”操作的“累加技巧”。这两个操作在计算上效率低下
- 提议利用GPU的强大并行性,通过为每个视锥特征分配一个CUDA线程,将特征添加到其对应的BEV网格中
多帧融合
- 多帧融合有助于更好地检测物体,并赋予模型估计速度的能力
- 将来自不同帧的视锥体特征的坐标与当前自我坐标系统对齐,以消除自我运动的影响,然后进行 Voxal 池化
- 不同帧的池化的 BEV 特征直接连接并输入到后续任务
nuScenes 验证集
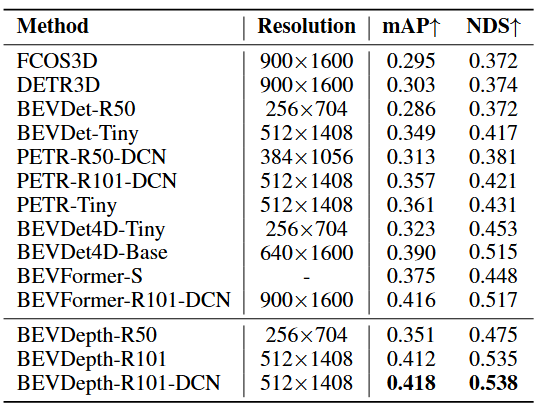
表7 nuScenes验证集的比较
nuScenes 测试集
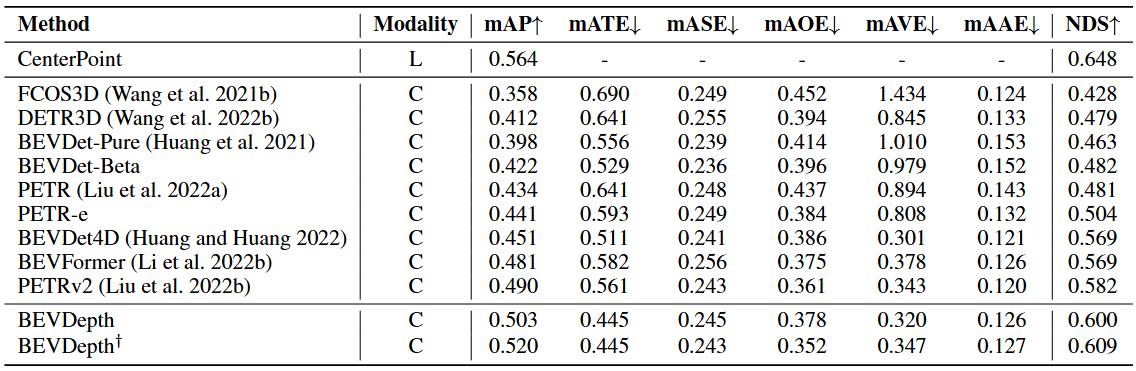
表8 在 nuScenes 测试集上的比较。L表示激光雷达(LiDAR),C表示相机(camera)。BEVDepth 使用预训练的VovNet作为骨干网络。输入图像的分辨率设置为640×1600。BEVDepth † ^{†} † 使用 ConvNeXT 作为骨干网络。
6. 总结
- 提出了一种新的网络架构,名为BEVDepth,用于准确预测3D物体检测的深度
- 首先研究了现有3D物体检测器的工作机制,并揭示了它们中的不可靠深度
- 在BEVDepth中引入了相机感知深度预测和深度细化模块,并使用显式深度监督,使其能够生成稳健的深度预测
- BEVDepth获得了预测可信深度的能力,并获得了显着的改进

















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









