







是啊,poison disk能生成低差异分布的样本。但不属于低差异序列。主要区别还是定义上不是deterministic的,所以之前提到的那些性质也都不满足了,而且生成的时候需要把所有生成过的样本储存起来。实现上也没法做到和这些序列一样那么高效,通常都要rejection sampling啥的。。
低差异序列(一)- 常见序列的定义及性质
https://zhuanlan.zhihu.com/p/20197323?columnSlug=graphics
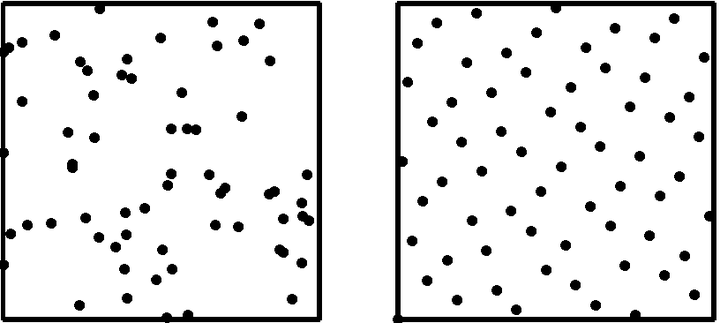
高效的生成在高维空间分布均匀的随机数是在计算机程序中非常常见的组成部分。对于一切需要采样的算法来说,分布均匀的随机数就意味着更加优秀的样本分布。光线传递的模拟(渲染)基于蒙特卡洛积分(Monte Carlo Integration),这个过程中采样无处不在,所以好的样本分布直接影响积分过程的收敛速度。与常见的伪随机数对比,低差异序列(Low Discrepancy Sequence)非常广泛的被用在图形,甚至于金融领域。它们除了在高维空间中的分布更加均匀以外还有许多其他的性质更利于渲染程序的执行。本文标题图片的左右两边分别用32个Sobol序列和伪随机数作为样本分布渲染,可以看出左边的噪点比右边少许多。这篇专栏会介绍几种常见的低差异序列的定义(Van der Corput, Halton,Hammersley,Sobol,Rank-1 lattice),下一篇专栏(低差异序列(二)- 高效实现以及应用 )则会专注于它们高效的实现,以及在渲染程序应用时候的一些问题。
什么是Discrepancy
首先说说这里均匀分布里的“均匀”指的是什么。一个直观的理解可以看下面的图片,左边为伪随机数组成的二维点集,右边则是由低差异序列点集的对整个空间的覆盖更加完整。
更加严谨的定义则要引入Discrepancy(Definition of Discrepancy)的概念

公式看的眼花缭乱,用普通话描述一下就是,对于一个在![[0,1]^n](https://i-blog.csdnimg.cn/blog_migrate/9d32264b7dc605674ae8cef5d3d18268.png) 空间中的点集,任意选取一个空间中的区域
空间中的点集,任意选取一个空间中的区域 ,此区域内点的数量
,此区域内点的数量 和点集个数的总量
和点集个数的总量 的比值和此区域的体积
的比值和此区域的体积 的差的绝对值的最大值,就是这个点集的Discrepancy。分布越均匀的点集,任意区域内的点集数量占点总数量的比例也会越接近于这个区域的体积。
的差的绝对值的最大值,就是这个点集的Discrepancy。分布越均匀的点集,任意区域内的点集数量占点总数量的比例也会越接近于这个区域的体积。
Radical Inversion与Van der Corput序列
接下来在介绍这些序列定义之前,先介绍一个基本的运算,Radical Inversion。这篇专栏将会介绍的所有序列都会用到这个运算过程。

![\Phi_{b, C}(i)=(b^{-1}...b^{-M})\left[ C \left( a_0(i)...a_{M-1}(i) \right)^T \right]](https://i-blog.csdnimg.cn/blog_migrate/0f23b9a0112ae0f138f5bd2e3d003731.png)
这个操作非常直观, 是一个正整数,则任何一个整数
是一个正整数,则任何一个整数 如果先将表示成进制的数,然后把得到的数中的每一个位上的数字
如果先将表示成进制的数,然后把得到的数中的每一个位上的数字 排成一个向量,和一个生成矩阵(generator matrix)
排成一个向量,和一个生成矩阵(generator matrix) 相乘得到一个新的向量,最后再把这个新向量中镜像到小数点右边去就能得到这个数以为底数,以为生成矩阵的radical inversion
相乘得到一个新的向量,最后再把这个新向量中镜像到小数点右边去就能得到这个数以为底数,以为生成矩阵的radical inversion 。
。
上面的描述可能略微有些复杂,但如果矩阵是单位矩阵(Identity Matrix)的时候,这个过程会简化很多,既是直接把这个进制的数镜像到小数点右边去即可。同时这也是Van der Corput序列的定义。

举个例子,正整数8以2为底数的radical inverse的计算过程如下。首先算出8的2进制表示,1000。此处假设为单位矩阵,所以直接将1000镜像到小数点右边,0.0001。这个二进制数的值就是最终结果,把它转换回10进制就得到1/16, 既 。下面的表给出了更多的以2为底数的Van der Corput序列的例子。
。下面的表给出了更多的以2为底数的Van der Corput序列的例子。
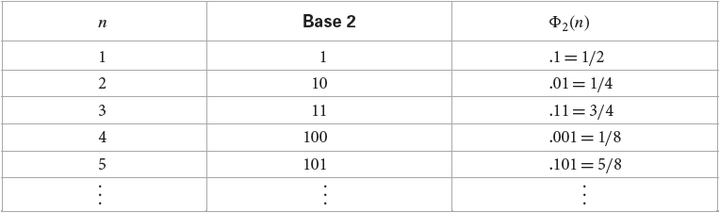
Van der Corput序列有几个属性:1)每一个样本点都会落在当前已经有的点里“最没有被覆盖”的区域。例如 是刚好落在了
是刚好落在了 区间中被覆盖最少的区域(
区间中被覆盖最少的区域( )。2)样本个数到达
)。2)样本个数到达 个点时对 会形成uniform的划分。例如
个点时对 会形成uniform的划分。例如 。3)很多时候并不能够代替伪随机数,因为点的位置和索引有很强的关系,例如在以2为底的Van der Corput序列中,索引为基数时候序列的值大于等于0.5,偶数时则小于0.5
。3)很多时候并不能够代替伪随机数,因为点的位置和索引有很强的关系,例如在以2为底的Van der Corput序列中,索引为基数时候序列的值大于等于0.5,偶数时则小于0.5
Halton序列与Hammersley点集
介绍完Van der Corput之后,Halton和Hammersley就非常简单了。Halton和Hammersley可以生成在无穷维度上分布均匀的点集。它们都基于Van der Corput序列。
Halton序列的定义很简单:

既是每一个维度都是一个基于不同底数的Van der Corput序列,其中
互为质数(例如第
 到第
到第 个质数)。
个质数)。
Hammersley点集的定义和Halton非常类似。

唯一不同的就是将第一个维度变成 ,其中为样本点的索引,为样本点集中点的个数。根据定义,Hammersley点集只能生成固定数目个样本,而Halton序列则可以生成无穷个样本(当然在计算机里我们只有有限的bit去表示有限个样本点)。
,其中为样本点的索引,为样本点集中点的个数。根据定义,Hammersley点集只能生成固定数目个样本,而Halton序列则可以生成无穷个样本(当然在计算机里我们只有有限的bit去表示有限个样本点)。

上面左边的图为第1-100个Halton序列中的二维的样本点, ,右边则为数量为100的二维Hammersley样本点集,
,右边则为数量为100的二维Hammersley样本点集, 。可以看出来他们的分布都远比一般的伪随机数更加均匀。Hammersley的Discrepancy比Halton更稍低一些,但是代价是必须预先知道点的数量,并且一旦固定没法更改。虚幻引擎4中对环境贴图的Filter采样就是用的点集大小固定为1024的Hammersley点集。Halton虽然Discrepancy稍高但可以不受限制的生成无穷多个点,更适合于没有固定样本个数的应用,例如任何progressive或者adaptive的过程。
。可以看出来他们的分布都远比一般的伪随机数更加均匀。Hammersley的Discrepancy比Halton更稍低一些,但是代价是必须预先知道点的数量,并且一旦固定没法更改。虚幻引擎4中对环境贴图的Filter采样就是用的点集大小固定为1024的Hammersley点集。Halton虽然Discrepancy稍高但可以不受限制的生成无穷多个点,更适合于没有固定样本个数的应用,例如任何progressive或者adaptive的过程。
基于radical inversion的序列还都具有Stratified样本的性质。因为每一个维度都是一个radical inversion,所以每一维度都具有所有之前提到的radical inversion的性质。其中之一就是点集个数到达个点时对 会形成uniform的划分。下图是第1-12个Halton序列的二维点集,可以看出点0-7在X轴的投影和0-8在Y轴的投影都是均匀覆盖。这也意味着在样本数量等于每个维度底数的公倍数的时候,样本会自然在每个维度上底数的倍数的strata中自然的形成stratified采样。例如下图中的第0-5个点,刚好在图中落在2x3的strata中。

Halton序列的一个缺点是,在用一些比较大的质数作为底数时,序列的分布在点的数量不那么多的时候并不会均匀的分布,只有当点的数量接近底数的幂的时候分布才会逐渐均匀。例如下图中以29和31为底的序列,一开始的点会分别是1/29,2/29,3/29...所以造成了点都集中落在了一条直线上面。解决这个问题的方法也很简单,Scrambling。Scrambling的方法有许多种,例如最简单的XOR Scrambling适用于以2为底数的序列。对于Halton来说,一个比较常用的方法是Faure Scrambling。

如上面的公式所写,Faure Scrambling的做法就是在做radical inverse的时候不直接将数字镜像到小数点右边,而在镜像前先把每个数字通过一个permutation 转换成另一个数字。不同的底数有不同的permutation
转换成另一个数字。不同的底数有不同的permutation 。例如
。例如。至于
如何具体计算这里不再展开,下一篇专栏在讲实现时会给出参考链接。这里值得一提的是Scrambling完全不会影响radical inversion序列分布的随机性,因为radical inversion会自然的将空间均等划分成底数的整数次幂个部分,scrambling本质上就是在交换这些均等划分的部分,所以Scrambled后的序列依然具有radical inversion的性质。

Sobol序列
与Halton和Hammersley不同,Sobol序列的每一个维度都是由底数为2的radical inversion组成,但每一个维度的radical inversion都有各自不同的矩阵。
因为完全以2为底数,所以Sobol序列的生成可以直接使用bit位操作实现radical inversion,非常高效。Sobol序列的分布具有不仅均匀,而且当样本的个数为2的整数次幂时,在 区间中以2为底的每个Elementary Interval中都有且只会有一个点,这意味着它可以生成和Stratified Sampling和Latin Hypercube同样高质量分布的样本(见下图),同时又不需要预先确定样本的数量或者将样本储存起来,并可以根据需要生成无限个样本,非常适合progressive的采样。这些性质也使得Sobol在需要一切对高维空间采样的应用中,例如图形,渲染以及金融领域,都非常流行,
区间中以2为底的每个Elementary Interval中都有且只会有一个点,这意味着它可以生成和Stratified Sampling和Latin Hypercube同样高质量分布的样本(见下图),同时又不需要预先确定样本的数量或者将样本储存起来,并可以根据需要生成无限个样本,非常适合progressive的采样。这些性质也使得Sobol在需要一切对高维空间采样的应用中,例如图形,渲染以及金融领域,都非常流行,

因为Sobol序列需要一个生成矩阵,而且所有维度都以2为底,所以没有Halton那样在以比较大的数为底时需要用Scrambling来消除分布间的correlation这个问题。那么如何计算出能生成如此高质量分布的矩阵呢?Quasi Monte Carlo的学者们已经花了数10年的时间搜索这种矩阵,现在我们可以在这个网页(Sobol sequence generator )找到可以生成21201维度的Sobol序列的矩阵。
Rank-1 Lattices
最后再简单提一下Rank-1 Lattices。类似于Sobol序列,Rank-1 Lattices依赖于一个生成向量(Generator Vector) 。生成向量的质量直接影响到最终样本的分布。给定一个生产向量后,产生一个点集的做法非常简单:
。生成向量的质量直接影响到最终样本的分布。给定一个生产向量后,产生一个点集的做法非常简单:

既每个样本都是用 乘以生成向量,为样本的索引,为样本总数,得到的乘积如果大于1,则对1求余数(modulate)映射回范围。
乘以生成向量,为样本的索引,为样本总数,得到的乘积如果大于1,则对1求余数(modulate)映射回范围。
这种做法类似Hammersley也只能用于预先知道样本数量并且样本数量固定的应用,如果需要可持续的生成无线个样本,也很简单,只需将换成一个radical inverse的序列即可:

Next...
这篇专栏文章介绍了几个常见低差异序列的定义以及性质,下一篇文章(低差异序列(二)- 高效实现以及应用 )会抛开理论着重谈它如何高效的实现它们,以及在图形程序中使用它们时会遇到的一些实际问题。例如如何将有限的序列用于所有的像素,如何多线程并行,如何利用这些性质并结合到一些光线传递的算法中去。
文章被以下专栏收录
![]()
图形学爱好者的专栏。涉及内容包括用于电影特效的离线渲染技术,用于游戏的实时渲染技术,图形学相关的软件系统如游戏引擎、渲染器的开发以及优化,物理模拟,GPU开发技术等。
推荐阅读

低差异序列(二)- 高效实现以及应用
手把手教你深度学习强大算法进行序列学习(附Python代码)
本文共3200字,建议阅读10分钟。 本文将教你使用做紧致预测树的算法来进行序列学习。 概述 序列学习是近年来深度学习的热点之一。从推荐系统到语音识别再到自然语言处理,它的潜力似乎无穷…

序列的算法(一·a)隐马尔可夫模型

天天算法 | Hard | 1.最长连续序列
12 条评论
写下你的评论...
![]()
葛亮昇2 年前
最近正好对pbrt和Mitsuba里面的低差异采样有点疑惑,大神的文章来的太及时了。希望下一篇能多讲一些Scrambling的内容。感谢大神~
![]()
HackerKO2 年前
大神
![]()
空明流转2 年前
POISON DISK 也算是低差异吧。
![]()
是啊,poison disk能生成低差异分布的样本。但不属于低差异序列。主要区别还是定义上不是deterministic的,所以之前提到的那些性质也都不满足了,而且生成的时候需要把所有生成过的样本储存起来。实现上也没法做到和这些序列一样那么高效,通常都要rejection sampling啥的。。
![]()
liyonghelpme2 年前
good
![]()
中二少年喔美嘎2 年前
我也是看了PBRT中的LDS看不懂,才发现楼主的好文章啊。
![]() 知乎用户2 年前
知乎用户2 年前
直接用数学方法生成分布均匀的采样点,比最佳候选,泊松环碉堡了,溜溜溜。真的是深度好文啊。
![]()
张建龙1 年前
mark
![]()
青春燃烧啊1 年前
你好,请问一下判断 sobol 生成矩阵是否优质的条件是什么?
![]()
赵伟1 年前
无意冒犯 :请问“这位同学,请把那个paper拿过来我look一下”,意义何在?
![]()
走心的生活家8 个月前
看论文看到了,很及时
![]()
方杰锋4 个月前
Discrepancy 的定义,B是任意一个“区间”,不是区域,有一点偏差....















 6982
6982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









