







 本文探讨了大语言模型(LLMs)在表格理解任务中的应用,包括文本推理、符号推理和融合方法。研究显示,GPT4Table和Rethinking Tabular Data Understanding with LLMs等方法在表格数据理解上取得了进展。符号推理通过单轮和多轮推理策略,如ReAct、PandasAI和TaskWeaver,提高了处理复杂表格问题的能力。融合方法通过投票和大模型整合提升了解答的准确性。未来的研究挑战包括解决复杂问题、多表联合分析以及效率和成本的平衡。
本文探讨了大语言模型(LLMs)在表格理解任务中的应用,包括文本推理、符号推理和融合方法。研究显示,GPT4Table和Rethinking Tabular Data Understanding with LLMs等方法在表格数据理解上取得了进展。符号推理通过单轮和多轮推理策略,如ReAct、PandasAI和TaskWeaver,提高了处理复杂表格问题的能力。融合方法通过投票和大模型整合提升了解答的准确性。未来的研究挑战包括解决复杂问题、多表联合分析以及效率和成本的平衡。
大语言模型(LLMs)的发展日新月异,为表格理解任务带来了新的可能性。表格理解任务,如基于表格的问答和表格事实验证,要求从自由形式的文本和半结构化的表格数据中提取深层次的语义信息。与泛化的文本推理任务不同,表格数据的复杂性对推理任务提出了更高的要求。
目前,研究者们主要探索了两种技术路线来应用LLMs于表格理解任务。
- 针对表格数据类型对LLMs进行领域适配,以更好地支持表格数据的理解。
- 直接使用预训练的通用LLMs,并借助一些额外手段(如Prompt技巧、工具使用等)来完成表格理解任务。
1、方法概览
直接使用预训练LLMs进行表格数据理解的技术路线主要有两种主流做法。第一种是基于文本推理的直接方式,将全量表格数据以一定分隔符的方式标记,作为Prompt的一部分输入LLMs,并结合Prompt技巧,直接对问题进行文本推理。第二种是基于符号推理的间接方式,将表格的结构信息(如表头、数据样例等)输入Prompt,根据任务需求指导LLMs编写一定的代码(如SQL、Python等),并调用对应的工具执行代码,得到想要的结果。
1.1、文本推理的方式
1.1.1、GPT4Table
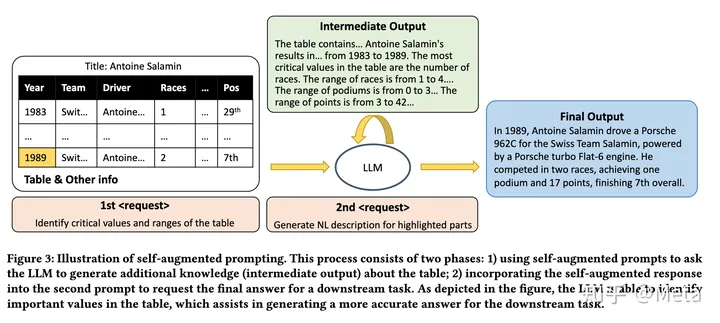
GPT4Table提出了一种全新的benchmark,并在此基础上验证了ChatGPT在各个子任务上的效果。研究团队提出了self-augmentation的Prompt技巧,进一步提升了理解效果:
- 首先让LLM输出一些对表格数据的理解作为额外的知识
- 将这些额外的知识加入到之前的问题prompt里,用于生成最终的答案
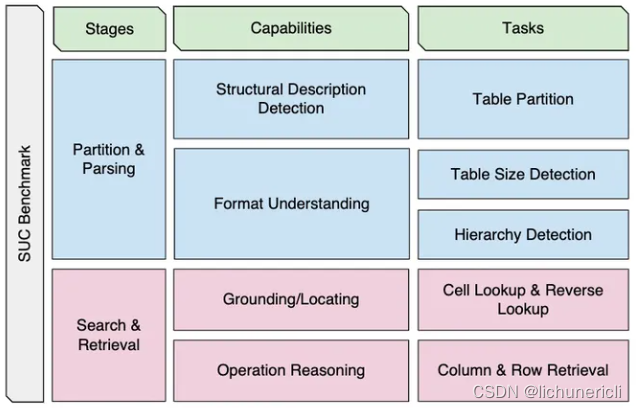
他们将表格数据的结构理解能力分为两大类:
- 区分出表格数据(从文本中定位出哪些内容表示的是表格数据)及解析表格数据(从各种类型,包括XML、CSV、XLSX等,中解析出表格数据的能力)
- 搜索(根据值进行位置搜索/根据位置定位到单元格值)和检索(根据行列信息找到对应的值)
他们设计并对比了一系列Prompt方式进行文本推理进行表格数据理解任务的能力,得出了一些结论和技巧。
- 不同分隔符的差异:在prompt中使用HTML语言表示数据,能普遍取得比简单分隔符表示数据更好的效果。
- one-shot相比zero-shot效果提升明显:尤其是对于一些高度依赖结构解析能力的任务。
- Prompt顺序的影响:添加的外部信息的prompt放在表格数据之前比放在之后会更好。
- 有关Partition mark和format explanation的prompt可能损失搜索/检索相关的能力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









