







 本文介绍了一种名为TabLLM的方法,它通过自然语言处理和大模型的先验知识,有效解决医疗等领域标记数据稀缺的问题。在零样本和少样本条件下,TabLLM在表格数据分类中表现出色,优于深度学习和传统机器学习方法。研究还探讨了不同序列化技术对性能的影响。
本文介绍了一种名为TabLLM的方法,它通过自然语言处理和大模型的先验知识,有效解决医疗等领域标记数据稀缺的问题。在零样本和少样本条件下,TabLLM在表格数据分类中表现出色,优于深度学习和传统机器学习方法。研究还探讨了不同序列化技术对性能的影响。
现实世界中存在大量未利用的先验知识和未标记数据。而在医疗等高价值领域,获取足够标记数据训练机器学习模型尤其困难,这限制了传统监督学习算法的应用。尽管深度学习方法在其他领域取得了显著进展,但在表格数据分类上仍未能超越传统的机器学习方法,如梯度提升树。TabLLM 旨在利用大模型(LLMs)的丰富知识库,通过自然语言处理能力,将表格数据转换为文本表示,从而在零样本或少样本的条件下进行有效分类。这种方法能够在数据标记受限的情况下,利用模型的先验知识提高分类性能,尤其是在面对罕见或特殊情形时。
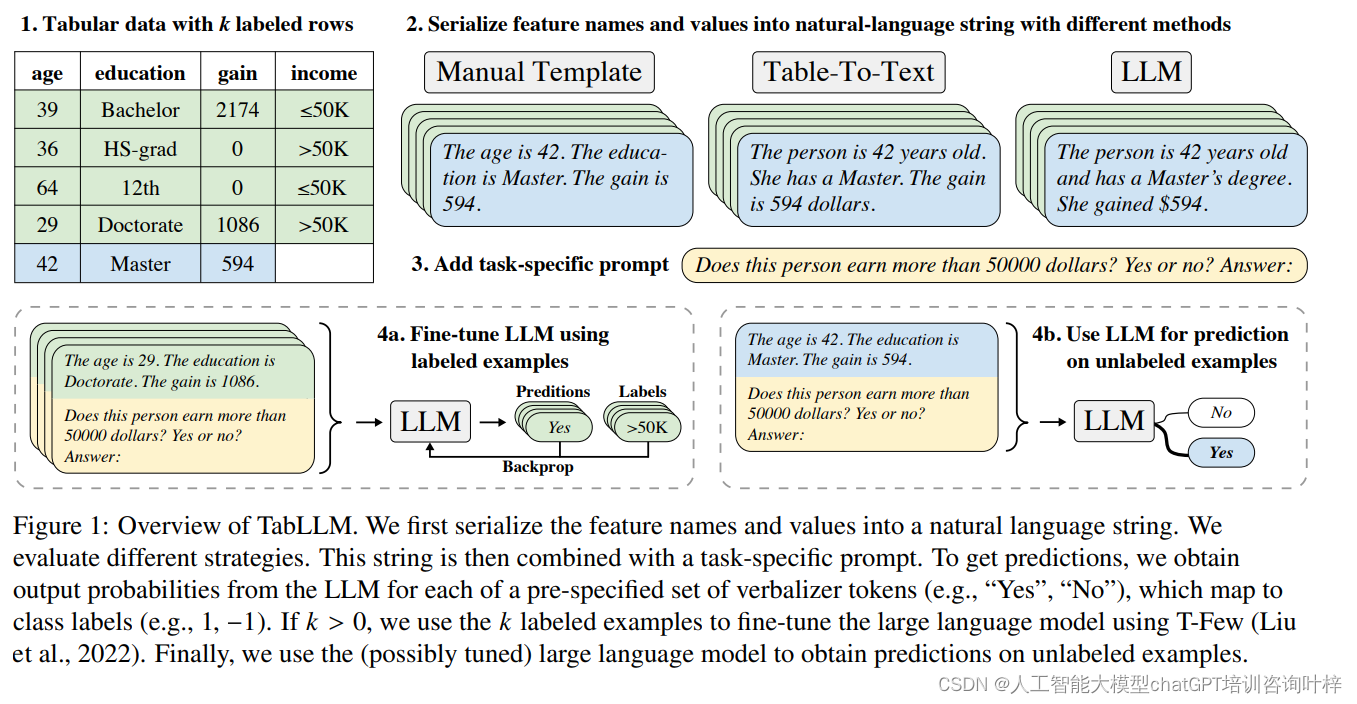
研究者们探索了不同的序列化技术,包括列表模板、文本模板、表格到文本模型,以及使用大型语言模型(如T0和GPT-3)进行序列化。
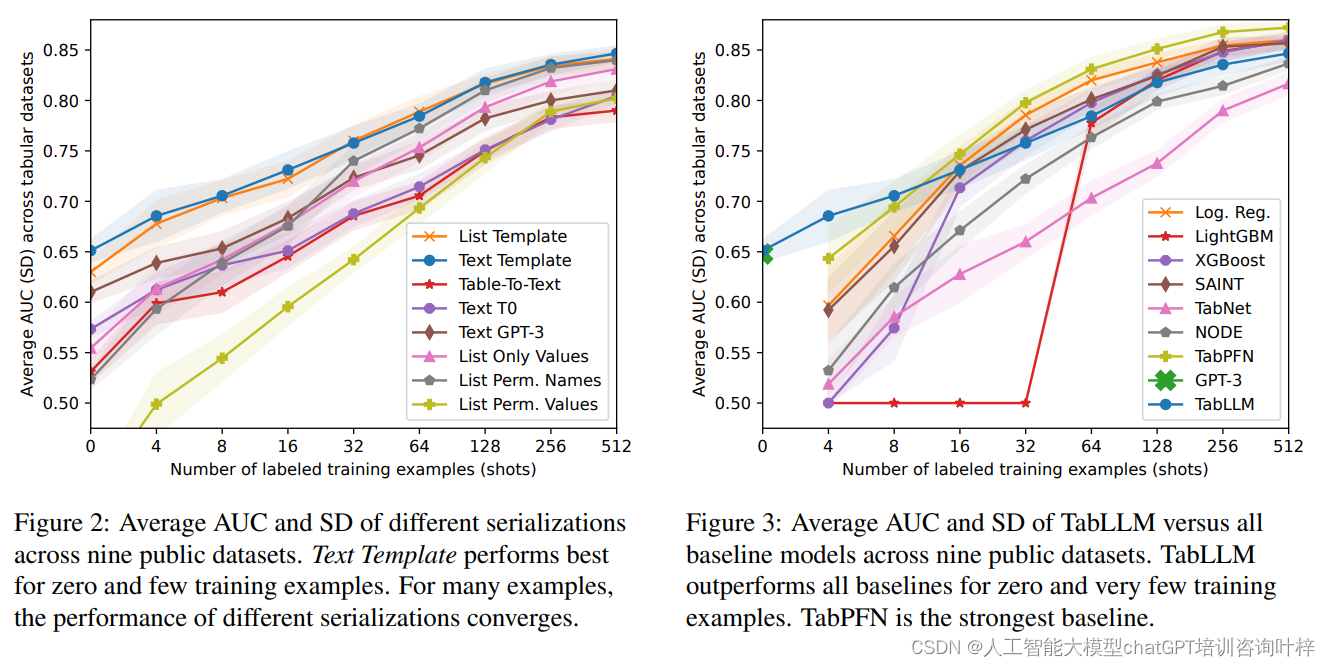
TabLLM框架的性能评估是在多个基准数据集上进行的,旨在展示TabLLM在表格数据分类任务上的表现,并与其他现有的深度学习方法以及传统的机器学习方法进行比较。
评估过程中,TabLLM在不同的数据集上接受了测试,包括在零样本(zero-shot)和少样本(few-shot)的设置下。这些测试允许研究者们评估模型在没有或只有很少训练数据时的性能。结果表明,TabLLM在多个数据集上都取得了有竞争力的结果,特别是在标记数据非常有限的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











