






Transformers without Normalization
今天给大家分享一篇来自Meta FAIR实验室的作品,作者中包含了何恺明(Kaiming He)和杨立坤(Yann Lecun)两位深度学习领域大佬!项目地址为:https://jiachenzhu.github.io/DyT/

1. 创新点(contribution)
本文提出Dynamic Tanh(DyT)技术,实现无需归一化层训练Transformer,挑战了传统认知,为神经网络研究带来新方向,具体创新点如下:
(1)提出DyT替代归一化层:引入DyT(Dynamic Tanh)作为归一化层的直接替代方案,其定义为 D y T ( x ) = γ ∗ t a n h ( α x ) + β DyT(x)=\gamma * tanh (\alpha x)+\beta DyT(x)=γ∗tanh(αx)+β。通过可学习参数 α \alpha α缩放输入,利用 t a n h tanh tanh函数压缩极端值,模仿归一化层行为,且无需计算激活统计量。实验表明,使用 D y T DyT DyT的Transformer在多种任务和领域中,能达到甚至超越使用归一化层的模型性能,且大多无需调整超参数。
(2)揭示归一化层行为机制:研究发现归一化层(如LN)的输入输出映射类似 t a n h tanh tanh函数的S形曲线。在深层LN层,这种非线性映射明显,会压缩极端值,使大部分值处于近似线性范围。同时,LN按token进行归一化,不同token的线性变换在整体上呈现出非线性的 t a n h tanh tanh形曲线。这一发现为提出 D y T DyT DyT提供了灵感,也深化了对归一化层在神经网络中作用的理解。
(3)验证DyT在多领域有效性:在多个领域的多种任务中对DyT进行验证。在视觉领域,涵盖监督学习(如ViT和ConvNeXt在ImageNet-1K分类任务)、自监督学习(如MAE和DINO)以及扩散模型(如DiT);在语言模型领域,对LLaMA不同规模模型进行预训练;在语音领域,对wav2vec 2.0模型进行预训练;在DNA序列建模领域,对HyenaDNA和Caduceus模型进行预训练。结果表明,DyT在这些任务中均能保持与使用归一化层相当的性能。
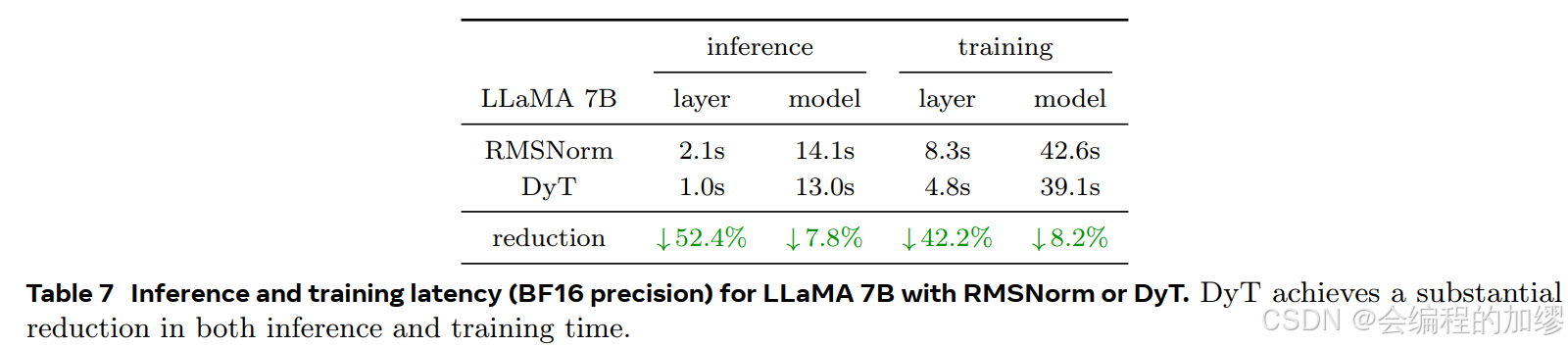
(4)分析DyT特性与优势:对DyT的计算效率、组成部分( t a n h tanh tanh函数和 a l p h a alpha alpha)进行分析。计算效率方面,以LLaMA 7B模型为例,DyT层相比RMSNorm层显著减少推理和训练时间。消融实验表明, t a n h tanh tanh函数对稳定训练至关重要, a l p h a alpha alpha对提升模型性能不可或缺,且 a l p h a alpha alpha在训练中跟踪激活的 1 / s t d 1/std 1/std,与输入激活的 1 / s t d 1/std 1/std强相关。
(5)对比其他去归一化方法优势:将DyT与其他训练无需归一化层的方法(如基于初始化的Fixup、SkipInit和基于权重归一化的 s i g m a R e p a r a m sigma Reparam sigmaReparam)对比。在不同ViT - 基任务中,DyT始终优于这些方法,证明其在去除归一化层的情况下,能更有效地实现稳定训练和良好性能。
2. DyT为何能取代Layer-Norm层
2.1 Transformer中原来的Nomalization层用的什么?
Transformer架构1如下,作者在每个子层中都采用了残差连接和进行层归一化,即每个子层的输出都是
L
a
y
e
r
N
o
r
m
(
x
+
S
u
b
l
a
y
e
r
(
x
)
)
LayerNorm(x + Sublayer(x))
LayerNorm(x+Sublayer(x)):
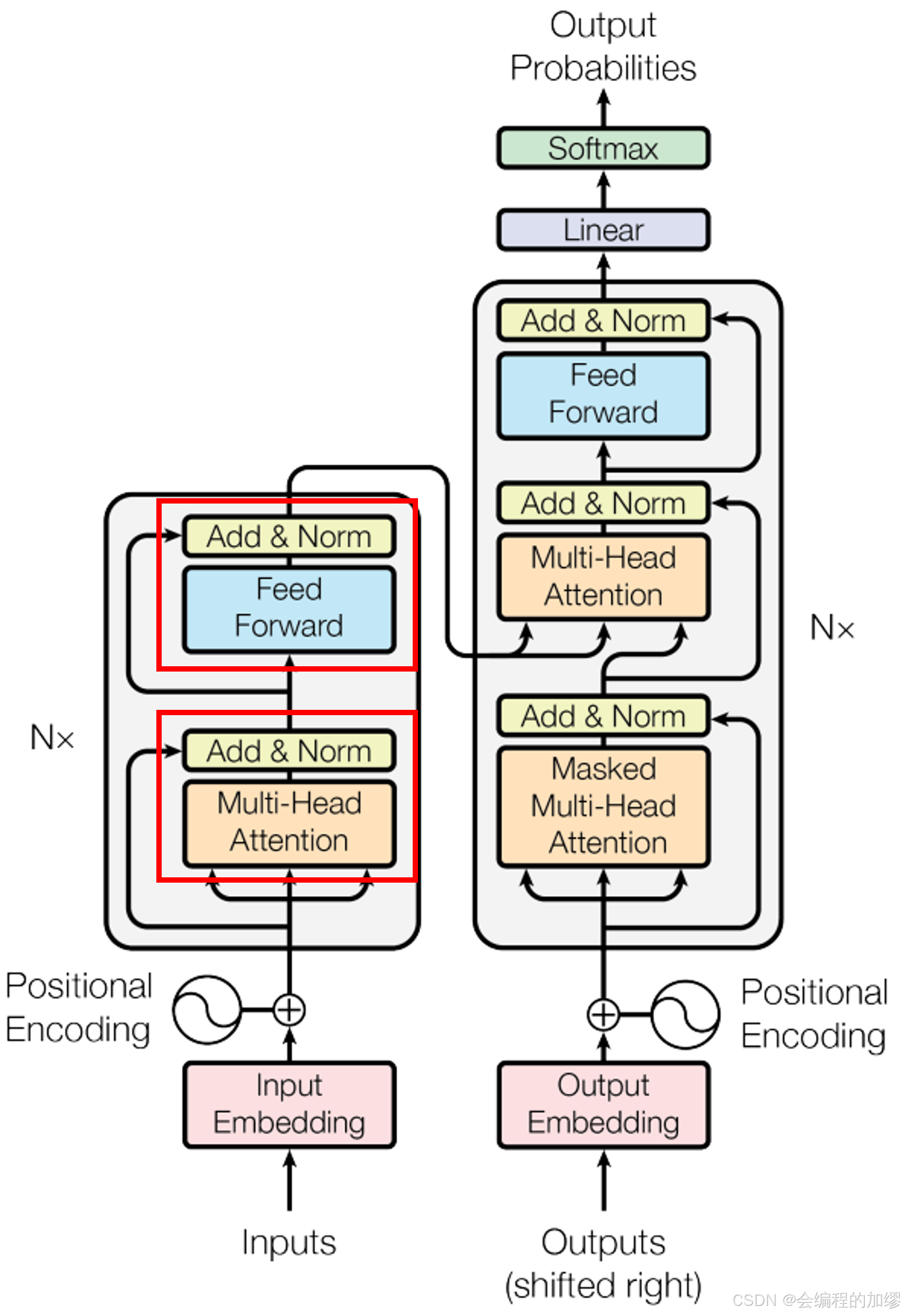
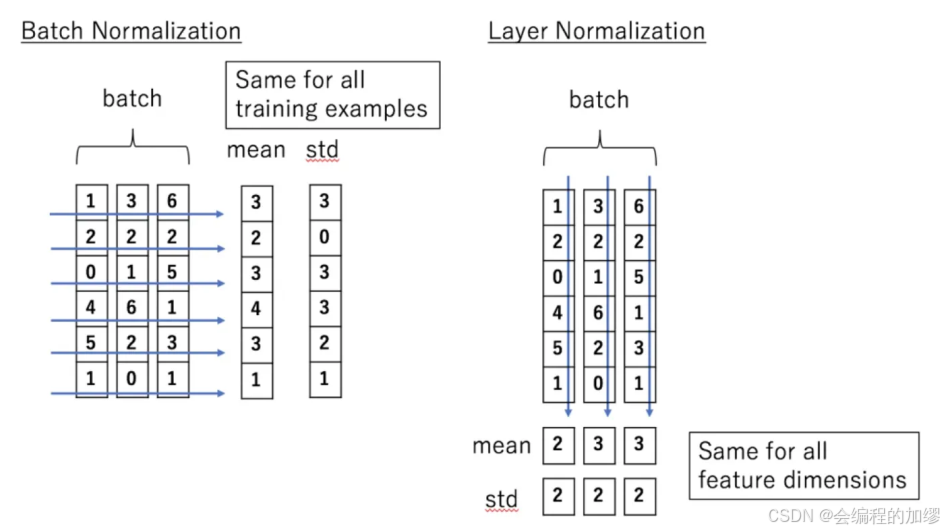
Transformer中,使用了Layer Nomalization(LN)作为归一化层,采用的Layer Nomalization的对比如下所示,具体分析可以见其他作者的博客2。同时,作者对比了Transformer为什么要使用Layer Normalization,而不使用Batch Normalization,两者区别可以从图中可以看出来:
- Batch Normalization(BN): 是对于每个维度上统计所有样本的值,计算均值和方差,BN在每个维度上分布是稳定的。卷积神经网络中使用的是BN。
- Layer Normalization(LN): 是在每个样本上统计所有维度的值,计算均值和方差,LN在每个样本上分布是稳定的。Transformer中主要使用的是LN与root mean square normalization(RMSNorm)。
2.2 Layer-Norm 输入输出映射形状
作者在不同数据集上,训练了计算机视觉领域经典模型vision transformer model(ViT), 语言领域经典模型wav2vec 2.0 Large Transformer model 和 生成领域经典模型diffusion transformer(DiT),并输出了在归一化操作之前与归一化操作之后的数据。结果如下图所示,横轴是归一化层的输入,纵轴是其输出。
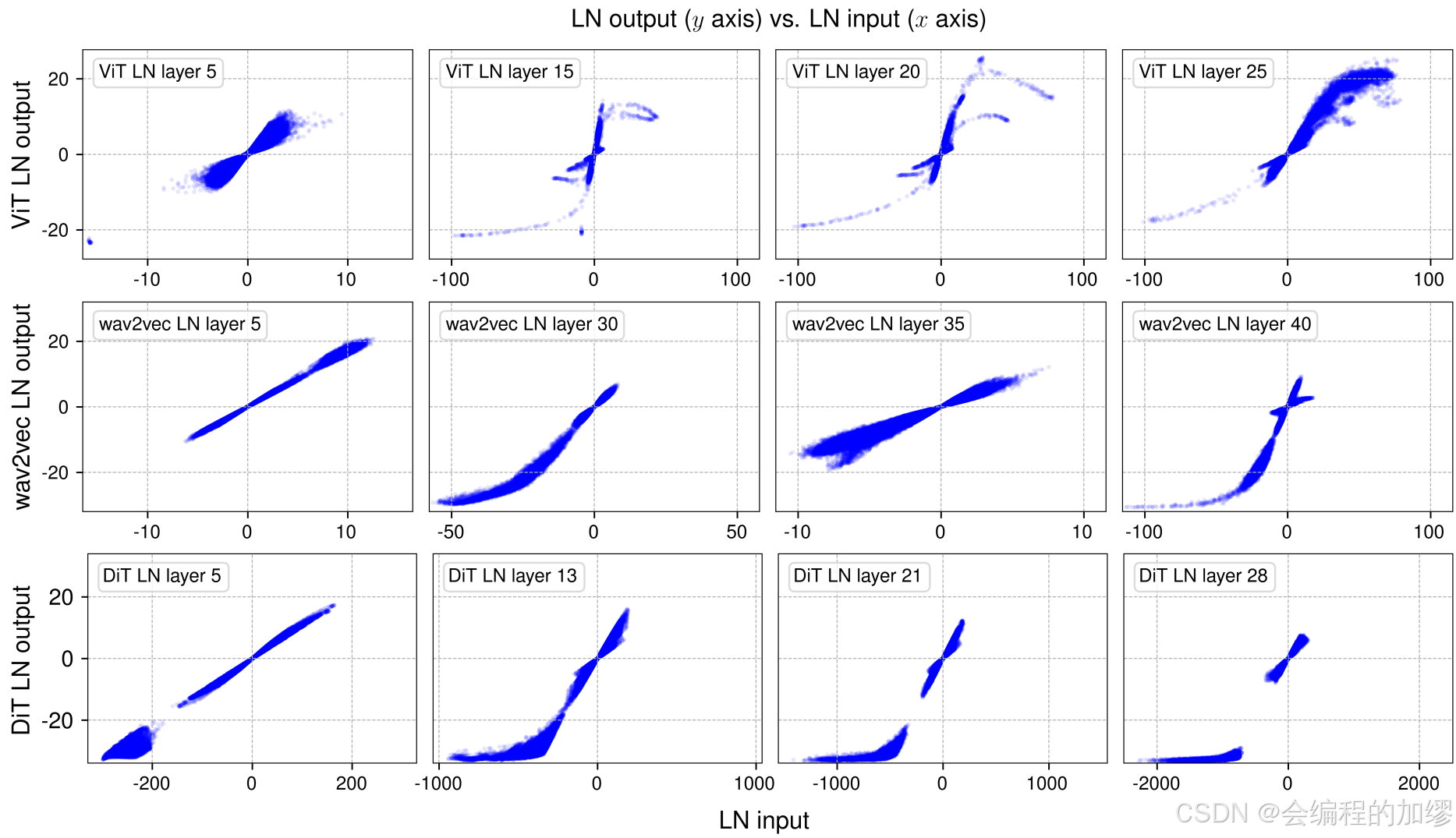
作者发现,归一化层前数据的输入到输出的映射随着归一化层深度的不同,有所变化,层数较浅时,输入输出映射是线性的,层数较深时有点像
t
a
n
h
tanh
tanh函数的S型曲线。由于标记具有不同的均值和标准差数值,这种线性关系并非在输入张量的所有激活值上都整体成立。尽管如此,让作者感到惊讶的是,实际的非线性变换与一个经过缩放的双曲正切函数高度相似。
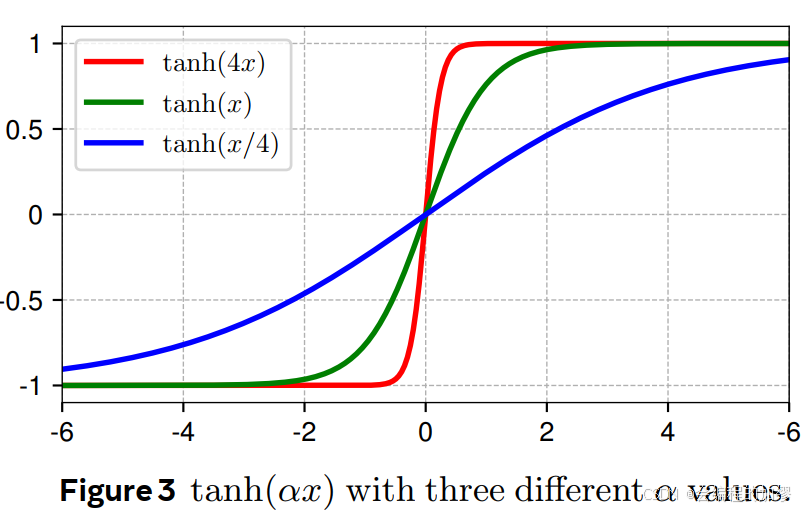
3. 如何用Tanh完成LN层的取代?
为了取代LN层,作者提出了一个动态
t
a
n
h
tanh
tanh函数,即DyT(Dynamic tanh):
D
y
t
(
x
)
=
γ
∗
t
a
n
h
(
α
x
)
+
β
Dyt(x)=\gamma * tanh(\alpha x)+\beta
Dyt(x)=γ∗tanh(αx)+β
作者通过设计一个可学习的缩放函数
α
\alpha
α来使
D
y
T
DyT
DyT学习不同输入函数的缩放,
γ
\gamma
γ和
β
\beta
β也是可学习的,用来帮助函数输出回到任意的尺度。
算法伪代码如下:
# input x has the shape of [B, T, C]
# B: batch size
# T: tokens
# C: dimension
class DyT(Module):
def __init__(self, C, init_alpha):
super().__init()
self.alpha = Parameter(ones(1) * init_alpha)
self.gamma = Parameter(ones(C))
self.beta = Parameter(zeros(C))
def forward(self, x):
x = tanh(self.alpha * x)
return self.gamma * x + self.beta
4. 取代之后效果如何?
作者做了大量的实验来证明
D
y
T
DyT
DyT效果,涉及从监督学习到自监督学习,从视觉任务,到自然语言处理,再到生成任务,效果表明,取代后
D
y
T
DyT
DyT与
L
N
LN
LN效果差不多,一些任务上略好
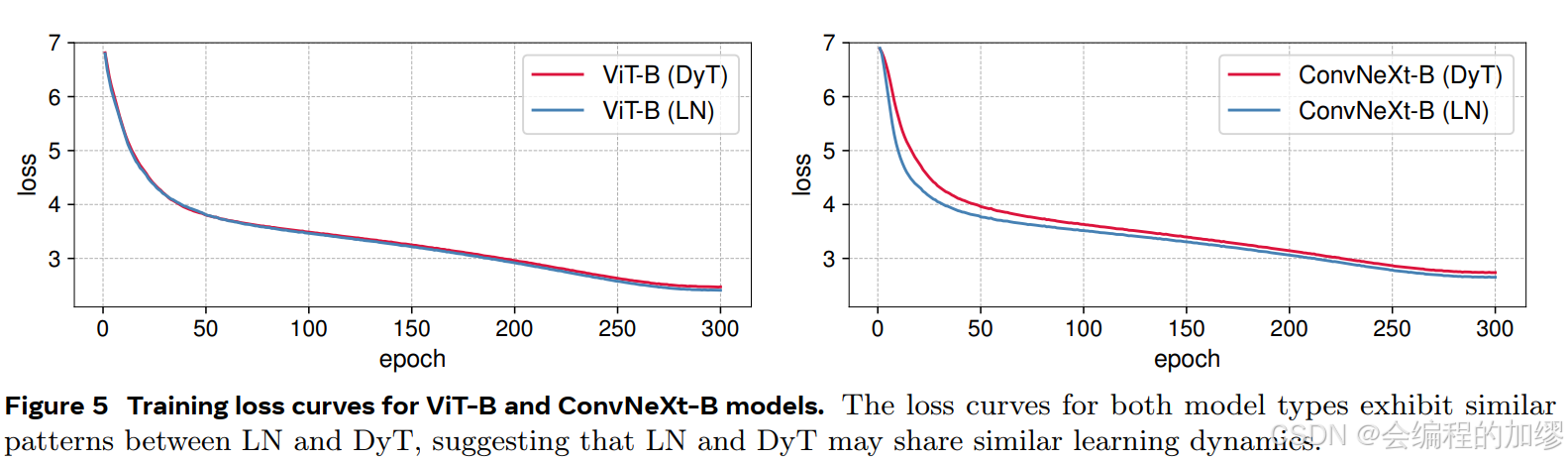
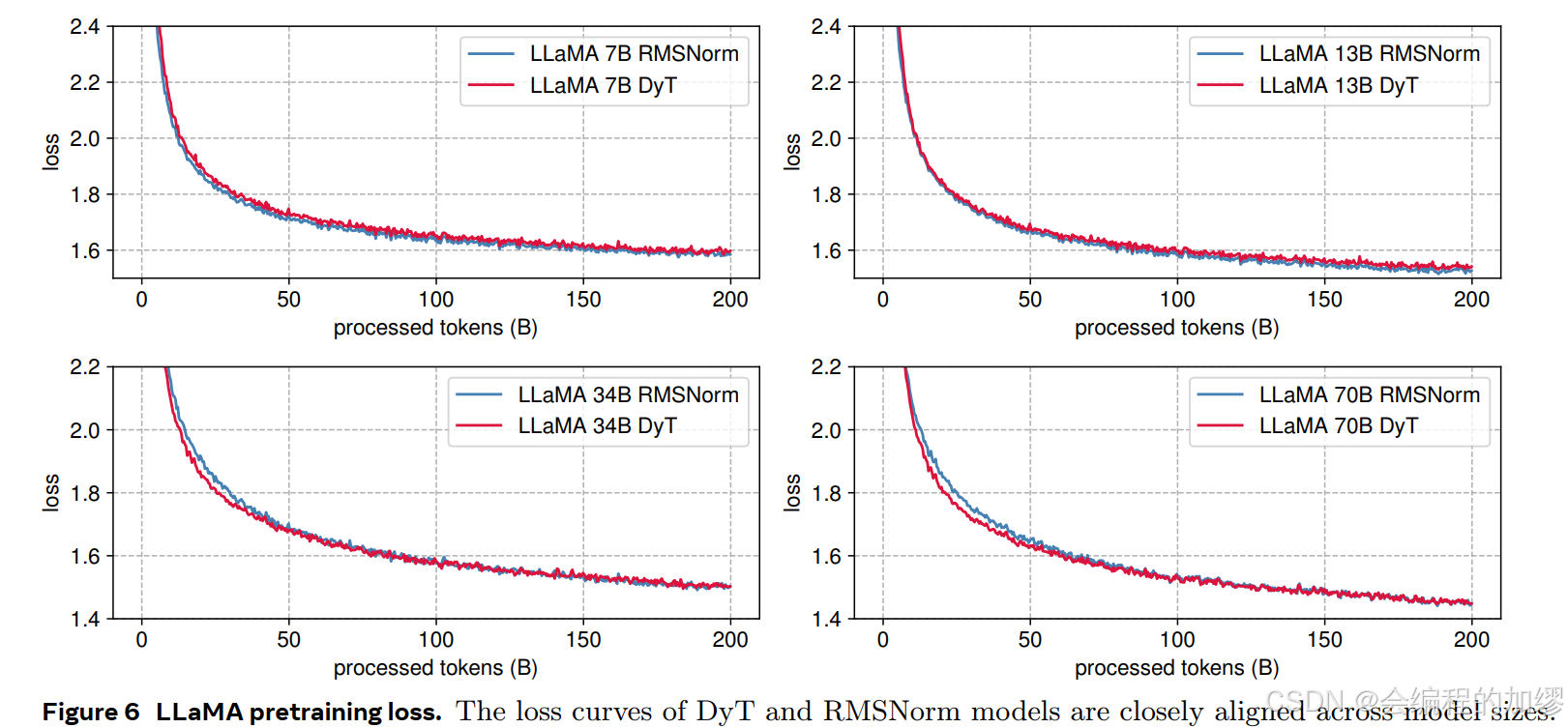
但是
D
y
T
DyT
DyT大大提升了训练和推理的效率:
通过与其他取代归一化层的方法比较,证明了该方法优越性能:

5. 本文的局限性
尽管本文在使用 D y T DyT DyT直接取代 L N LN LN层中表现较好,但是通过 D y T DyT DyT直接取代 B N BN BN层时,在Resnet网络中的效果却远远落后于 B N BN BN层。说明该方法的普适性还有待证明,需要大量地去应用探索和实践:

以上是今天的分享内容,感谢观看,欢迎讨论交流!


















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











