






CUDA中的线程与线程束
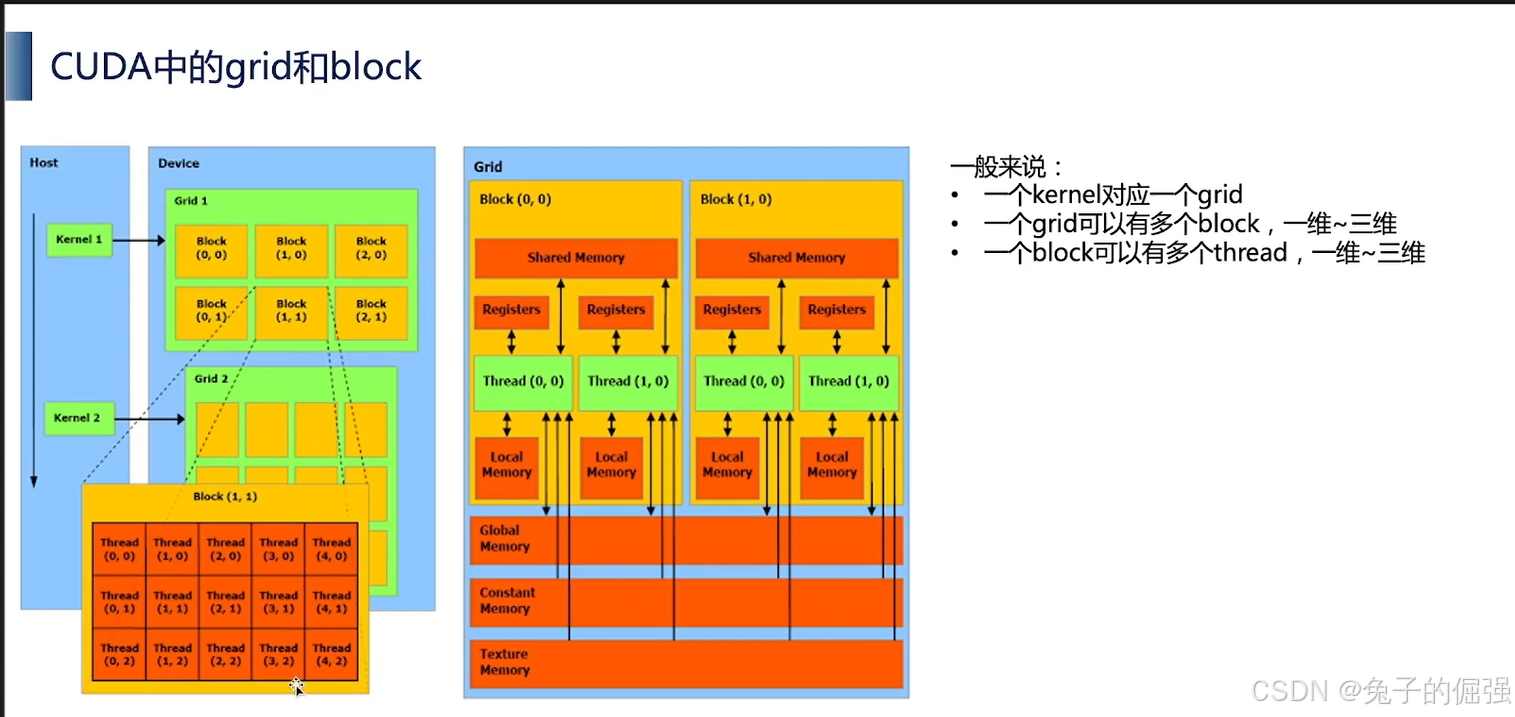
- kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid_size, block_size>>>来指定kernel要执行的线程数量。在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
- synchronize是同步的意思,有几种synchronize
cudaDeviceSynchronize: CPU与GPU端完成同步,CPU不执行之后的语句,直到这个语句以前的所有cuda操作结束
cudaStreamSynchronize: 跟cudaDeviceSynchronize很像,但是这个是针对某一个stream的。只同步指定的stream中的cpu/gpu操作,其他的不管
cudaThreadSynchronize: 现在已经不被推荐使用的方法
__syncthreads: 线程块内同步 - 核函数编写和调用举例
#include <cuda_runtime.h>
#include <stdio.h>
// 核函数
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
void print_one_dim(){
int inputSize = 8;
int blockDim = 4;
int gridDim = inputSize / blockDim;
dim3 block(blockDim);
dim3 grid(gridDim);
// 核函数调用
print_idx_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
.cu与.cpp的相互引用及Makefile
编译器:gcc g++ nvcc
举个例子:
nvcc print_index.cu -o app -I /usr/local/cuda/include
获取编译器选项:
g++ --help
nvcc --help
Makefile编写(是否可以使用CMakeLists.txt?)
.cpp中不能直接调用核函数,需要在.cu中提供调用接口
使用CUDA进行MATMUL计算
host端与device端数据传输
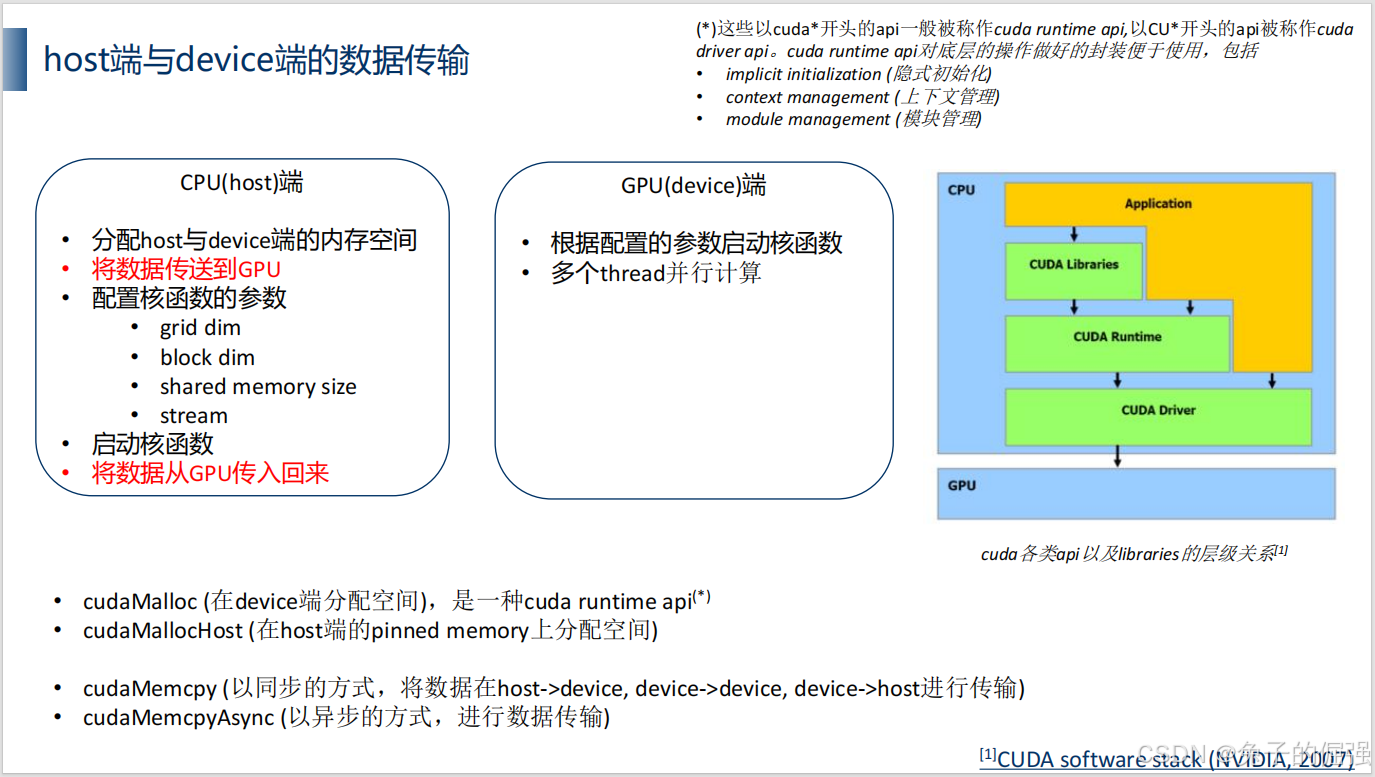
host端与device端数据传输代码实现:
void MatmulOnDevice(float *M_host, float *N_host, float* P_host, int width, int blockSize){
/* 设置矩阵大小 */
int size = width * width * sizeof(float);
/* 分配M, N在GPU上的空间*/
float *M_device;
float *N_device;
cudaMalloc(&M_device, size);
cudaMalloc(&N_device, size);
/* 分配M, N拷贝到GPU上*/
cudaMemcpy(M_device, M_host, size, cudaMemcpyHostToDevice);
cudaMemcpy(N_device, N_host, size, cudaMemcpyHostToDevice);
/* 分配P在GPU上的空间*/
float *P_device;
cudaMalloc(&P_device, size);
/* 调用kernel来进行matmul计算, 在这个例子中我们用的方案是:将一个矩阵切分成多个blockSize * blockSize的大小 */
dim3 dimBlock(blockSize, blockSize);
dim3 dimGrid(width / blockSize, width / blockSize);
MatmulKernel <<<dimGrid, dimBlock>>> (M_device, N_device, P_device, width);
/* 将结果从device拷贝回host*/
cudaMemcpy(P_host, P_device, size, cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
/* Free */
// free与malloc的顺序是反着的
cudaFree(P_device);
cudaFree(N_device);
cudaFree(M_device);
}
cuda core矩阵乘法核函数编写
/* matmul的函数实现*/
__global__ void MatmulKernel(float *M_device, float *N_device, float *P_device, int width){
/*
我们设定每一个thread负责P中的一个坐标的matmul
所以一共有width * width个thread并行处理P的计算
*/
// 确定负责计算的结果元素的索引
int y = blockIdx.y * blockDim.y + threadIdx.y;
int x = blockIdx.x * blockDim.x + threadIdx.x;
float P_element = 0;
/* 对于每一个P的元素,我们只需要循环遍历width次M和N中的元素就可以了*/
for (int k = 0; k < width; k ++){
float M_element = M_device[y * width + k];
float N_element = N_device[k * width + x];
P_element += M_element * N_element;
}
P_device[y * width + x] = P_element;
}
cuda core 每个线程执行核函数计算一个结果元素
GPU刚开始执行核函数的时候,会存在一个warmup阶段,耗时会比较长
CPU与GPU的浮点运算会存在误差,误差控制在e-4以内是ok的
CUDA中规定,一个block中可以分配的thread的数量最大是1024个线程,如果大于1024会显示配置错误
为什么block size = 1的时候比等于16的时候慢很多?
cuda中的error handler

获取GPU的硬件信息
利用cuda runtime api打印硬件信息 & LOG
#include <stdio.h>
#include <cuda_runtime.h>
#include <string>
#include "utils.hpp"
int main(){
int count;
int index = 0;
cudaGetDeviceCount(&count);
while (index < count) {
cudaSetDevice(index);
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, index);
LOG("%-40s", "*********************Architecture related**********************");
LOG("%-40s%d%s", "Device id: ", index, "");
LOG("%-40s%s%s", "Device name: ", prop.name, "");
LOG("%-40s%.1f%s", "Device compute capability: ", prop.major + (float)prop.minor / 10, "");
LOG("%-40s%.2f%s", "GPU global meory size: ", (float)prop.totalGlobalMem / (1<<30), "GB");
LOG("%-40s%.2f%s", "L2 cache size: ", (float)prop.l2CacheSize / (1<<20), "MB");
LOG("%-40s%.2f%s", "Shared memory per block: ", (float)prop.sharedMemPerBlock / (1<<10), "KB");
LOG("%-40s%.2f%s", "Shared memory per SM: ", (float)prop.sharedMemPerMultiprocessor / (1<<10), "KB");
LOG("%-40s%.2f%s", "Device clock rate: ", prop.clockRate*1E-6, "GHz");
LOG("%-40s%.2f%s", "Device memory clock rate: ", prop.memoryClockRate*1E-6, "Ghz");
LOG("%-40s%d%s", "Number of SM: ", prop.multiProcessorCount, "");
LOG("%-40s%d%s", "Warp size: ", prop.warpSize, "");
LOG("%-40s", "*********************Parameter related************************");
LOG("%-40s%d%s", "Max block numbers: ", prop.maxBlocksPerMultiProcessor, "");
LOG("%-40s%d%s", "Max threads per block: ", prop.maxThreadsPerBlock, "");
LOG("%-40s%d:%d:%d%s", "Max block dimension size:", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2], "");
LOG("%-40s%d:%d:%d%s", "Max grid dimension size: ", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2], "");
index ++;
printf("\n");
}
return 0;
}
Roofline model(待补充)
Nsight system and Nsight compute
谷歌搜索下载:官网链接
Nsight system
安装目录:
ls /usr/local/bin |grep nsys
nsys
nsys-ui
启动GUI界面
sudo ./nsys-ui(不加sudo会存在权限问题)
举个例子:
配置可执行文件以及感兴趣内容:
 可视化分析:
可视化分析:
 详细使用手册:官网文档
详细使用手册:官网文档
Nsight compute
查看可安装版本:
sudo apt policy nsight-compute-2022.2.1
安装:
sudo apt install nsight-compute-2022.2.1
查看安装位置:
dpkg -L nsight-compute-2022.2.1
路径:/opt/nvidia/nsight-compute/2022.2.1/
文件:ncu ncu-ui等
启动:
sudo ./ncu-ui
举个例子:
基本配置:replay mode: application
 选择感兴趣内容:
选择感兴趣内容:
 launch即可,第一次运行会比较慢,会重复运行很多次。
launch即可,第一次运行会比较慢,会重复运行很多次。
结果:
 不知道为什么roofline model没有正常显示出来,需要查一查?
不知道为什么roofline model没有正常显示出来,需要查一查?
扩展知识
共享内存以及BANK CONFLICT
shared memory
硬件结构
SM(Streaming Multiprocessor)
在CUDA编程模型中,线程被组织成线程块(block),多个线程块组成一个网格(grid)。每个线程块被分配到一个SM中执行,而SM内部的warp调度器会将线程块中的线程分成多个warp进行执行。
当一个warp中的线程需要等待某些操作(例如内存访问)完成时,SM可以切换到另一个warp继续执行,从而提高计算效率。

核函数编写
#include "cuda_runtime_api.h"
#include "utils.hpp"
#define BLOCKSIZE 16
/*
使用shared memory把计算一个tile所需要的数据分块存储到访问速度快的memory中
*/
__global__ void MatmulSharedStaticKernel(float *M_device, float *N_device, float *P_device, int width){
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/
for (int m = 0; m < width / BLOCKSIZE; m ++) {
M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];
N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];
__syncthreads(); // 上述两句所有thread都会执行,等待所有thread执行完成
for (int k = 0; k < BLOCKSIZE; k ++) {
P_element += M_deviceShared[ty][k] * N_deviceShared[k][tx];
}
__syncthreads();
}
P_device[y * width + x] = P_element;
}
__global__ void MatmulSharedDynamicKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){
/*
声明动态共享变量的时候需要加extern,同时需要是一维的
注意这里有个坑, 不能够像这样定义:
__shared__ float M_deviceShared[];
__shared__ float N_deviceShared[];
因为在cuda中定义动态共享变量的话,无论定义多少个他们的地址都是一样的。
所以如果想要像上面这样使用的话,需要用两个指针分别指向shared memory的不同位置才行
*/
extern __shared__ float deviceShared[];
int stride = blockSize * blockSize;
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * blockSize + threadIdx.x;
int y = blockIdx.y * blockSize + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了 */
for (int m = 0; m < width / blockSize; m ++) {
deviceShared[ty * blockSize + tx] = M_device[y * width + (m * blockSize + tx)];
deviceShared[stride + (ty * blockSize + tx)] = N_device[(m * blockSize + ty)* width + x];
__syncthreads();
for (int k = 0; k < blockSize; k ++) {
P_element += deviceShared[ty * blockSize + k] * deviceShared[stride + (k * blockSize + tx)];
}
__syncthreads();
}
if (y < width && x < width) {
P_device[y * width + x] = P_element;
}
}
动态共享内存比静态共享内存速度慢,没有特殊情况下,使用静态共享内存。
cuda event进行时间测算

BANK CONFLICT(存储体冲突)
在shared memory中什么是bank?

什么时候会发生bank conflict

按行存储,按列访问的时候,会发生bank conflict:
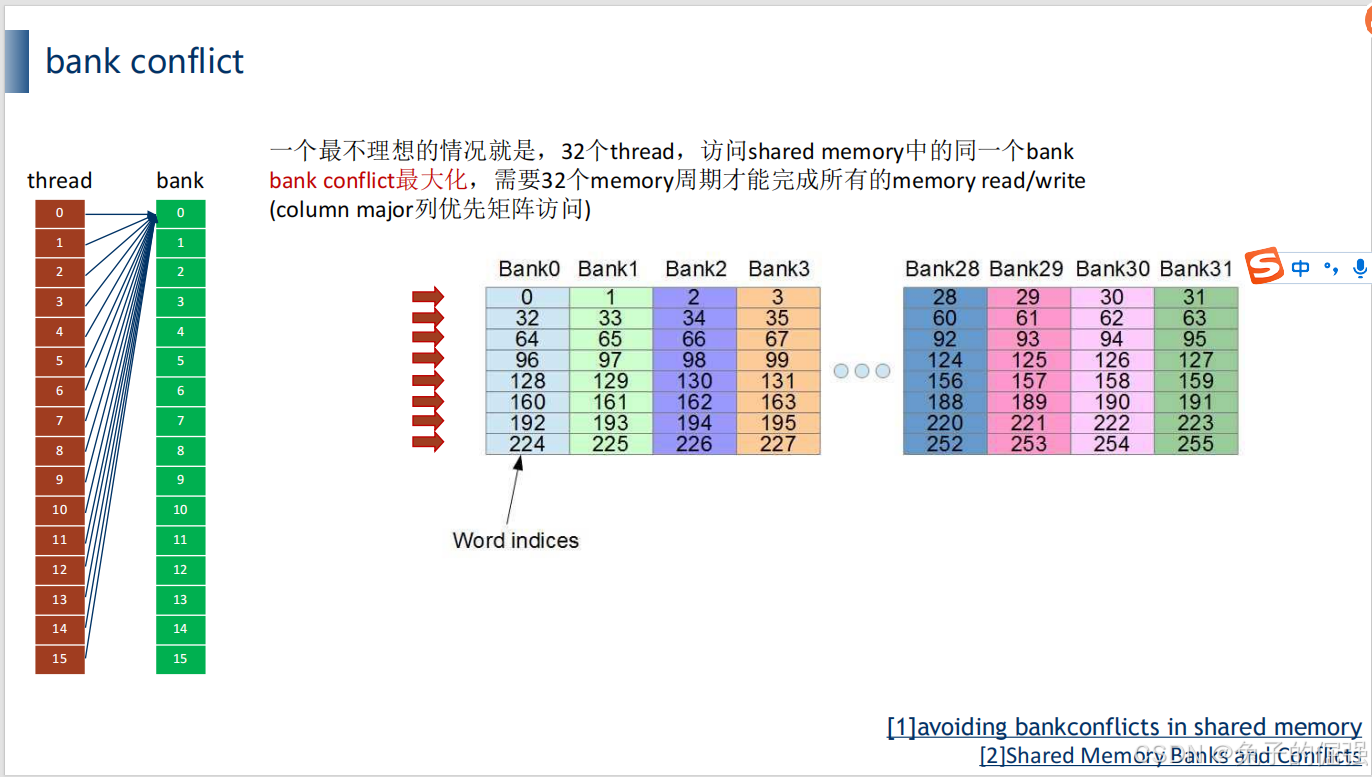
如何减缓bank conflict

代码实现
#include "cuda_runtime_api.h"
#include "utils.hpp"
#define BLOCKSIZE 16
/*
使用shared memory把计算一个tile所需要的数据分块存储到访问速度快的memory中
*/
__global__ void MatmulSharedStaticConflictPadKernel(float *M_device, float *N_device, float *P_device, int width){
/* 添加一个padding,可以防止bank conflict发生,结合图理解一下*/
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * BLOCKSIZE + threadIdx.x;
int y = blockIdx.y * BLOCKSIZE + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/
for (int m = 0; m < width / BLOCKSIZE; m ++) {
/* 这里为了实现bank conflict, 把tx与tx的顺序颠倒,同时索引也改变了*/
M_deviceShared[tx][ty] = M_device[x * width + (m * BLOCKSIZE + ty)];
N_deviceShared[tx][ty] = M_device[(m * BLOCKSIZE + tx)* width + y];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k ++) {
P_element += M_deviceShared[tx][k] * N_deviceShared[k][ty];
}
__syncthreads();
}
/* 列优先 */
P_device[x * width + y] = P_element;
}
__global__ void MatmulSharedDynamicConflictPadKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){
/*
声明动态共享变量的时候需要加extern,同时需要是一维的
注意这里有个坑, 不能够像这样定义:
__shared__ float M_deviceShared[];
__shared__ float N_deviceShared[];
因为在cuda中定义动态共享变量的话,无论定义多少个他们的地址都是一样的。
所以如果想要像上面这样使用的话,需要用两个指针分别指向shared memory的不同位置才行
*/
extern __shared__ float deviceShared[];
int stride = (blockSize + 1) * blockSize;
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * blockSize + threadIdx.x;
int y = blockIdx.y * blockSize + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了 */
for (int m = 0; m < width / blockSize; m ++) {
/* 这里为了实现bank conflict, 把tx与tx的顺序颠倒,同时索引也改变了*/
deviceShared[tx * (blockSize + 1) + ty] = M_device[x * width + (m * blockSize + ty)];
deviceShared[stride + (tx * (blockSize + 1) + ty)] = N_device[(m * blockSize + tx) * width + y];
__syncthreads();
for (int k = 0; k < blockSize; k ++) {
P_element += deviceShared[tx * (blockSize + 1) + k] * deviceShared[stride + (k * (blockSize + 1 ) + ty)];
}
__syncthreads();
}
/* 列优先 */
P_device[x * width + y] = P_element;
}
STREAM和EVENT
什么是stream

参考下述链接,理解cuda编程的一些基础概念:
理解CUDA中的thread,block,grid和warp
cuda stream的使用
多流编程实现
单流:
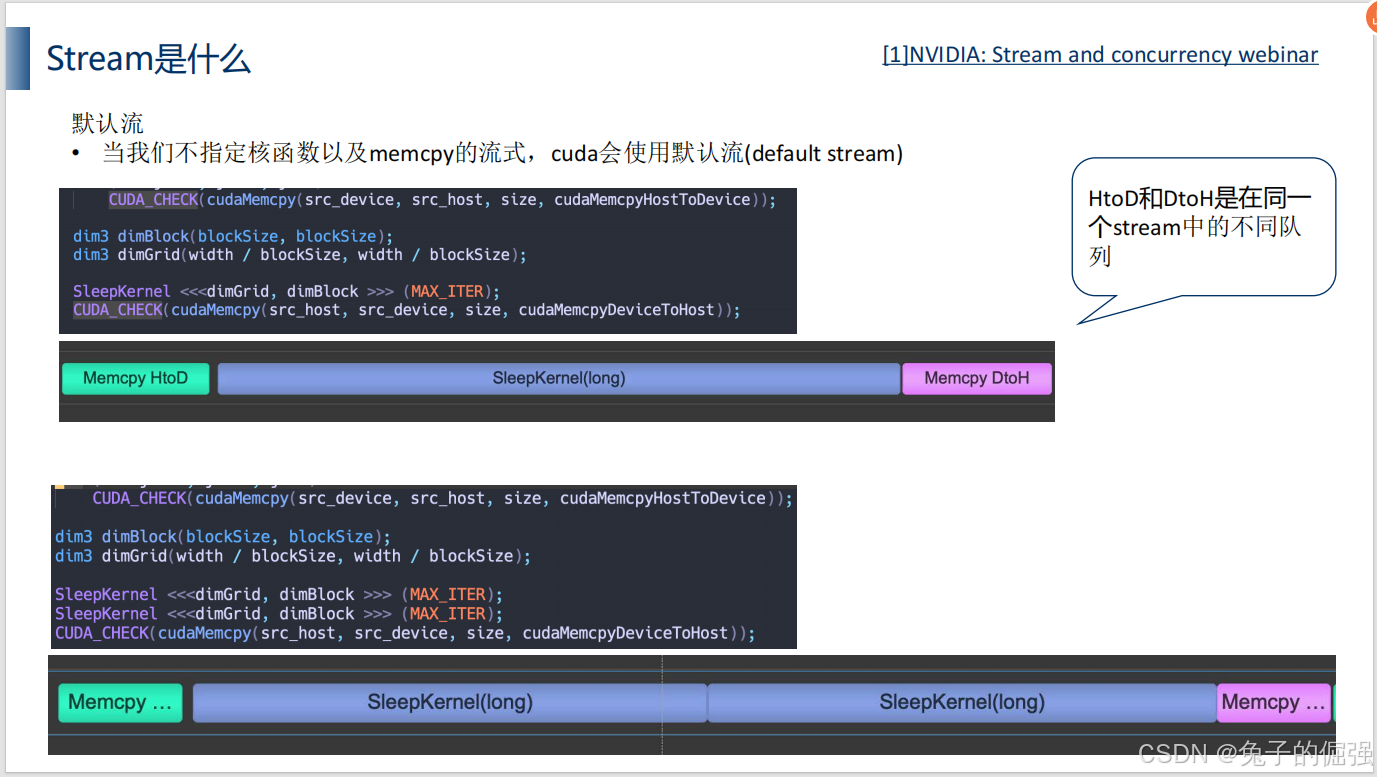
多流:
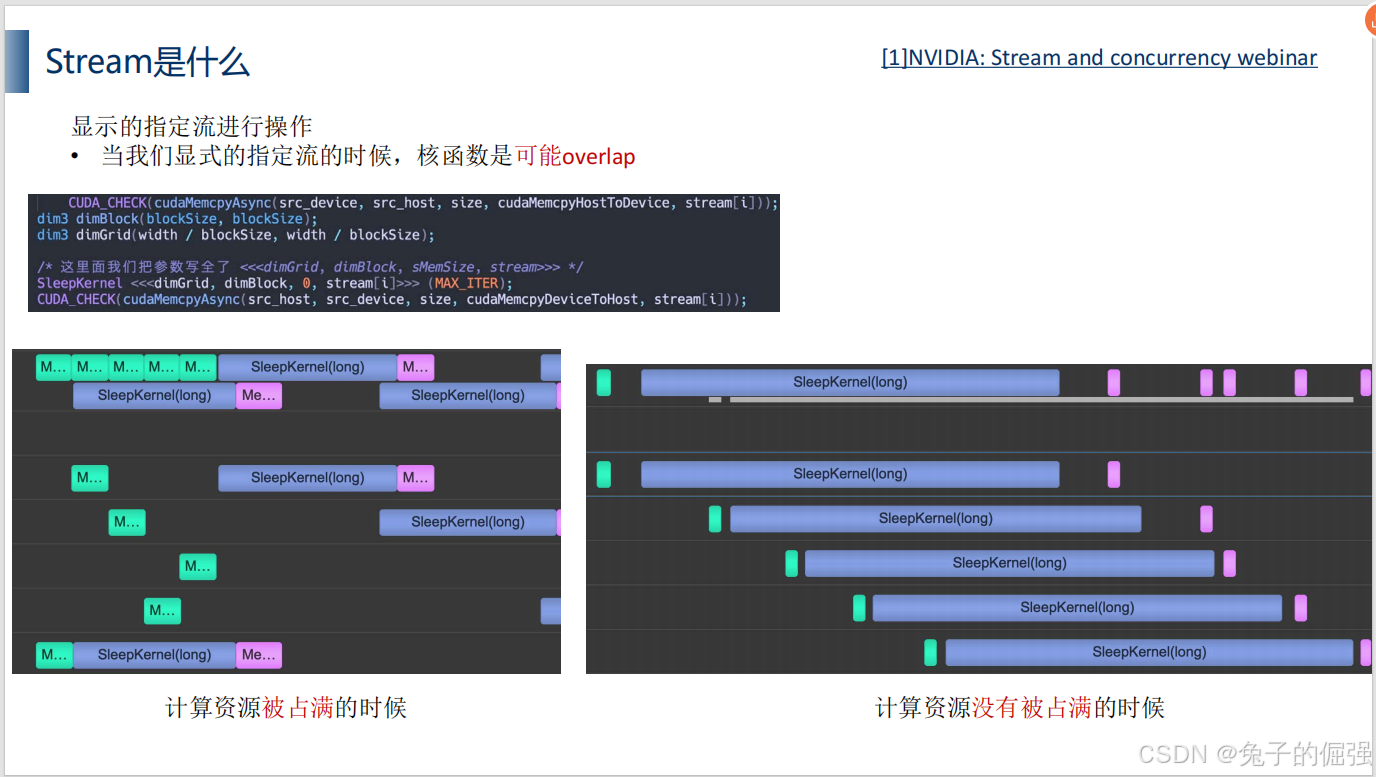
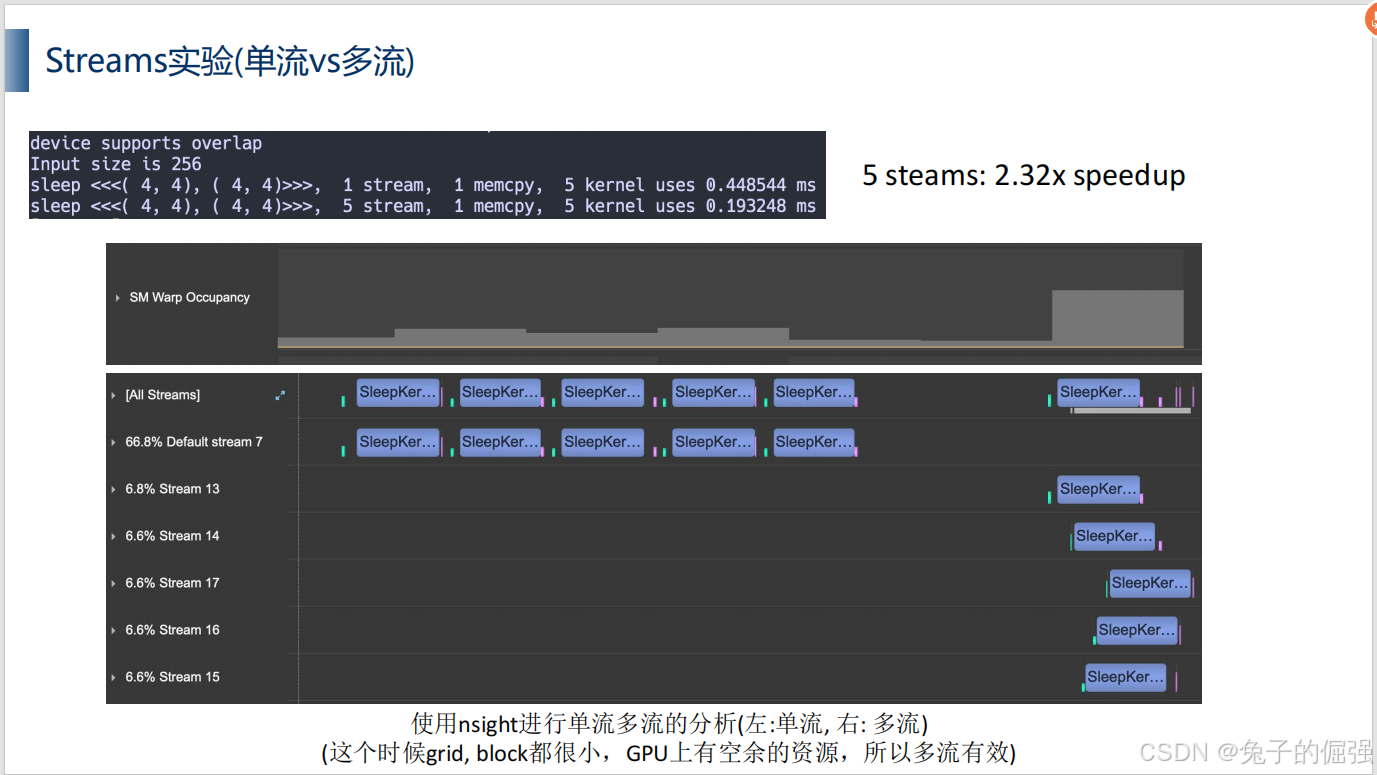
利用nsight systems进行分析:
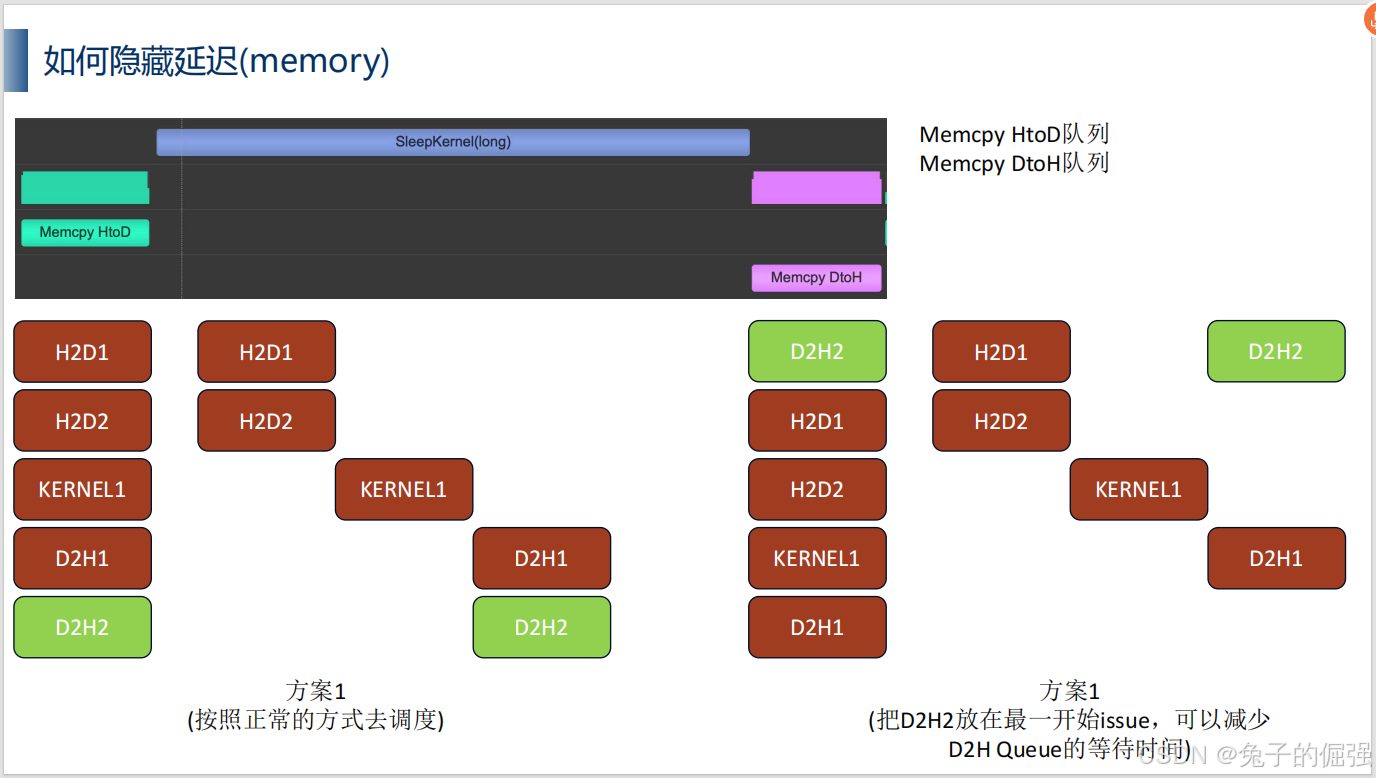
如何利用多流进行隐藏访存和核函数执行延迟的调度
举一个栗子:
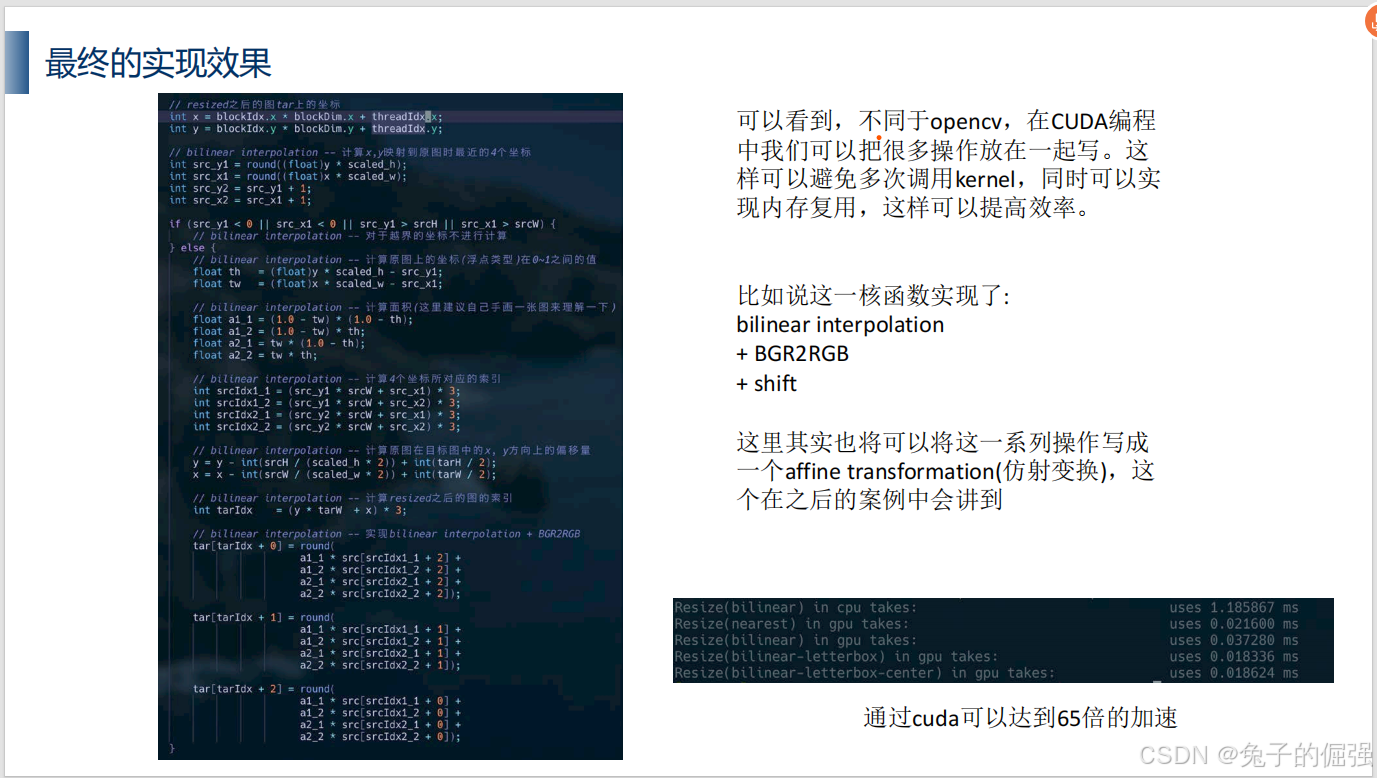
使用CUDA进行预处理/后处理
双线性插值
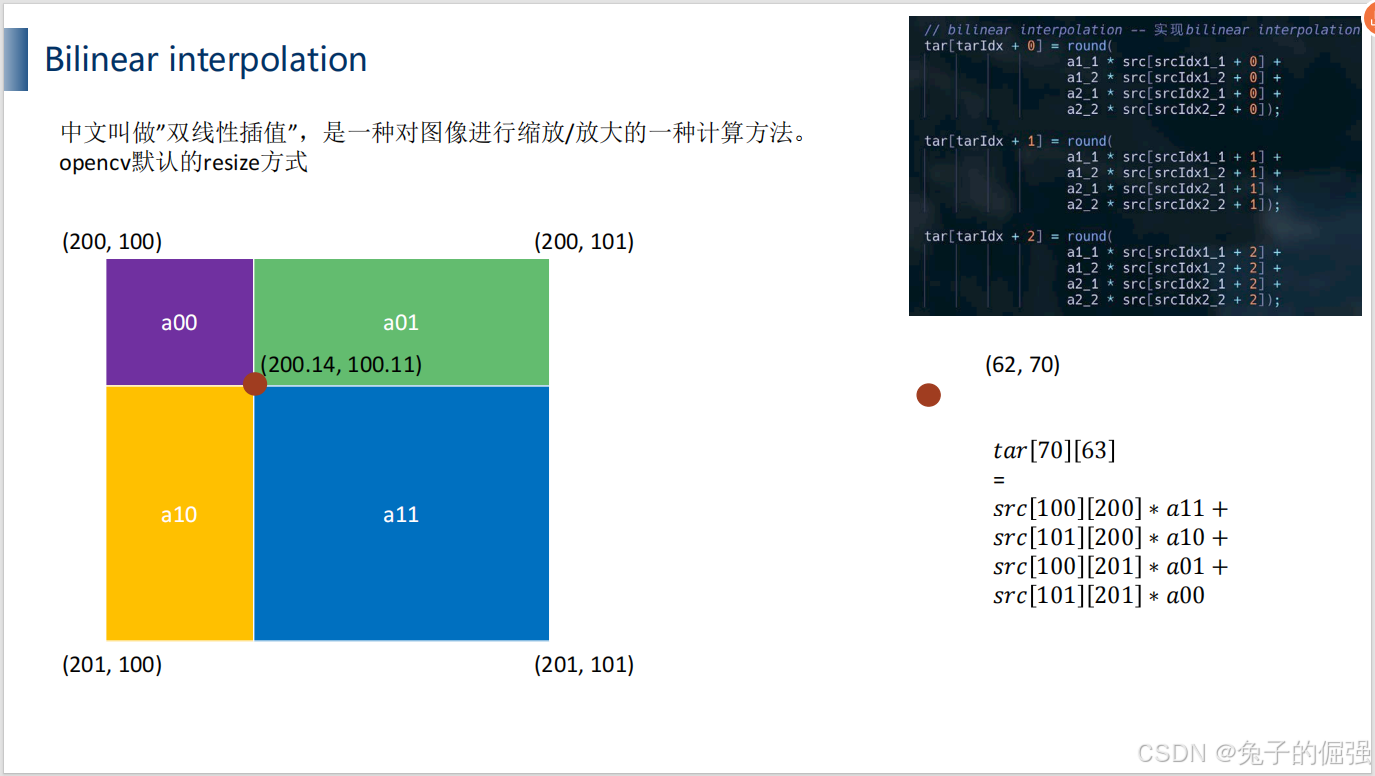
双线性插值的cuda实现
查看图片大小:
identity xx.png
可视化图片:
feh xx.png


















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











