






YOLO 结合CVPR年度最佳论文——Swin Transformer,把握视觉特征、不同尺度但同目标的语义特征、检测目标与周围复杂干扰的上下文特征等多尺度特征,实现层级式特征提取,有效抗干扰,强势提点!
其实目前网上现有的几篇Swin Transformer + YOLO系列的文章没办法做到傻瓜式的部署和跑通模型,这些文章中教的需要修改的代码也不完善,有的只写了需要修改的文件名但没说怎么改,有的需要改的文件根本没列出来.....
同时,目前YOLO的最新版的官方工程代码,结构相较于以往版本有一定程度上的调整,以往教程还未根据最新更新的结构进行调整,无法直接使用。
因此,对着那些教程,代码往往还是会报错,无法直接实现模型的傻瓜式、快速跑通,许多 代码实践经验较少 或者 看到代码就头疼的同学 遇到这种情况表示很是困扰。为解决这一问题,我们决定:做一个,从第一步到最后一步,都精细到“打开aaaa/bbbb/cccc地址下的dddd.py的文件,将代码的第n行:XXXXX改为xxxxx”的小白教程,帮助大家2小时快速跑通,解决论文的实验环节!废话不多说,我们直接开始!
一、Swin Transformer简介
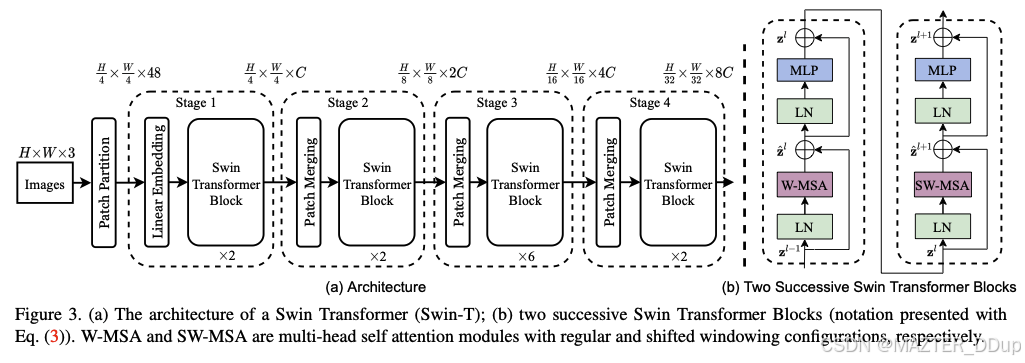
上图为Swin Transformer网络结构图
传统检测基于卷积思想(CNN)进行特征提取,CNN更为关注局部特征,忽略了局部与局部之间的联系,而Transformer很好地解决了这一问题。Swin Transformer更多地结合了计算机视觉的先验知识,实现了与卷积神经网络类似的层级化结构设计,通过Self Window、Shifted Window配对的灵活的自注意力机制,使得网络在较浅的层级就已经拥有了覆盖全局的感受野,拥有全局建模的能力,并且提高了模型的计算性能。详细内容,请见原文。
就走流程简单介绍一下,你不会真觉得要把它们全部理解全部看懂吧?你别管了!跟我上高速🛣️
接下来以YOLOv11为例进行介绍
二、Swin Transformer + YOLOv11
2.1 下载yolo工程代码
创建虚拟环境的小白教程文章很多,这一步我们就不过多赘述了,我们也不会讲的比其他大佬更好,我们也是参照别人文章创建的,哈哈哈。你别管了,对着大佬们的文章一步步搞!注意奥,如果要运行yolo11的话,pytorch版本好像是要1.8以上。创建虚拟环境文章在此!大家按口味喜好自选
接下来,有点超纲,但跟着我,你别管了好吧,少年郎,去成为出色的程序员!GitHub,扒代码去。怕你不会(我第一次扒就有点慌),我一步步说。先点开YOLO官方代码,然后看图,就是这里,对准点,别搞错了,下载,解压。
来到这一步,讲道理,你真不是一般人了,多少沾点天资聪颖。
2.2 核心代码展示
来到这一步,早已被论文、代码压弯的身躯已经慢慢直起来了一点,心中响起来一个熟悉的旋律:起来,不愿做奴隶.....
OK暂停一下,跟上我的节奏整齐划一~~~
下面这段代码,给我左键点击代码块右上角复制,右键搞里头(xxxxx/xxxx/xxxx/)
class WindowAttention(nn.Module):
""" 窗口注意力机制,包含相对位置偏置 """
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # 窗口高度(Wh)和宽度(Ww)
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# 定义相对位置偏置的参数表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 形状:(2*Wh-1 * 2*Ww-1, nH)
# 为窗口内的每个token生成成对的相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 形状:(2, Wh, Ww)
coords_flatten = torch.flatten(coords, 1) # 形状:(2, Wh*Ww)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 形状:(2, Wh*Ww, Wh*Ww)
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 形状:(Wh*Ww, Wh*Ww, 2)
relative_coords[:, :, 0] += self.window_size[0] - 1 # 调整坐标从0开始
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # 形状:(Wh*Ww, Wh*Ww)
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # 解包q,k,v(TorchScript兼容性处理)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# 添加相对位置偏置
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # (Wh*Ww, Wh*Ww, nH)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # (nH, Wh*Ww, Wh*Ww)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None: # 应用注意力掩码
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# 注意力加权后的值计算
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except: # 处理半精度兼容性问题
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformer(nn.Module):
""" CSP瓶颈结构(参考自CrossStagePartialNetworks) """
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # 输入通道, 输出通道, 重复次数, 是否捷径, 分组数, 扩展系数
super(SwinTransformer, self).__init__()
c_ = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32 # 根据通道数计算注意力头数
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
def forward(self, x):
y1 = self.m(self.cv1(x)) # 主路径处理
y2 = self.cv2(x) # 捷径路径处理
return self.cv3(torch.cat((y1, y2), dim=1))
class SwinTransformerB(nn.Module):
""" 变种B的CSP瓶颈结构 """
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super(Swin_Transformer_B, self).__init__()
c_ = int(c2) # 隐藏层通道数等于输出通道
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
def forward(self, x):
x1 = self.cv1(x)
y1 = self.m(x1) # 主路径处理
y2 = self.cv2(x1) # 内部捷径处理
return self.cv3(torch.cat((y1, y2), dim=1))
class SwinTransformerC(nn.Module):
""" 变种C的CSP瓶颈结构 """
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super(Swin_Transformer_C, self).__init__()
c_ = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 1, 1)
self.cv4 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x))) # 主路径处理后再次卷积
y2 = self.cv2(x) # 捷径路径处理
return self.cv4(torch.cat((y1, y2), dim=1))
class Mlp(nn.Module):
""" 多层感知机模块 """
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer() # 激活函数默认SiLU
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
""" 将特征图划分为不重叠的窗口
输入形状: (B, H, W, C)
输出形状: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
assert H % window_size == 0 and W % window_size == 0, '特征图尺寸必须能被窗口大小整除'
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
""" 将窗口还原回原始特征图
输入形状: (num_windows*B, window_size, window_size, C)
输出形状: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class SwinTransformerLayer(nn.Module):
""" Swin Transformer基础层,包含窗口注意力/滑动窗口注意力和MLP """
def __init__(self, dim, num_heads, window_size=8, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size必须位于0到window_size之间"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
""" 为滑动窗口注意力生成掩码 """
img_mask = torch.zeros((1, H, W, 1)) # 形状:(1, H, W, 1)
# 划分不同区域
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# 生成注意力掩码
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
_, _, H_, W_ = x.shape
# 特征图尺寸不足时进行填充
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size != 0 or W_ % self.window_size != 0:
Padding = True
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # 转换为序列格式
# 生成注意力掩码
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# 滑动窗口偏移
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# 窗口划分与注意力计算
x_windows = window_partition(shifted_x, self.window_size)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
attn_windows = self.attn(x_windows, mask=attn_mask)
# 窗口还原与偏移恢复
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W)
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
# 残差连接与MLP
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
# 恢复填充前的尺寸
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W)
if Padding:
x = x[:, :, :H_, :W_]
return x
class SwinTransformerBlock(nn.Module):
""" Swin Transformer模块,包含多个基础层 """
def __init__(self, c1, c2, num_heads, num_layers, window_size=8):
super().__init__()
self.conv = None
if c1 != c2: # 通道数不匹配时使用1x1卷积调整
self.conv = Conv(c1, c2)
# 构建多个Swin层(交替使用常规窗口和滑动窗口)
self.blocks = nn.Sequential(*[
SwinTransformerLayer(
dim=c2,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2 # 偶数层不偏移,奇数层偏移
) for i in range(num_layers)
])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x2.2 付费内容💰
哥们真的不是骗子,哥们只是除夕夜街头,即将放飞理想的有志青年,点击下方链接,助理每一个梦想!(环游世界,替你自由)
童叟无欺💰 :https://m.tb.cn/h.6m6wuQw?tk=41HJV4W2oiR
训练得到的模型测试轻松达到0.9+金指标!!!!有效提升复制干扰情况下的稳定性!提点就完了!
接下来我们的内容长达20+页的PDF,覆盖:修改其他文件、导包、注册,到最新的训练、测试、推理方法等等,同时可加🛰️用户社群,参与讨论,有效解决后续答疑、模型改进问题。
已经有多位同学陆续付费+入群,我们希望建立一个优质的交流渠道,帮助大家解决后续问题、交流,共同进步!👬👬👬
again:哥们真的不是骗子,哥们只是除夕夜街头,即将放飞理想的有志青年,点击下方链接,助理每一个梦想!(环游世界,替你自由)
💰 :https://m.tb.cn/h.6m6wuQw?tk=41HJV4W2oiR


















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









