








零部件成本下降、中低端车竞争加剧,推动ADAS渗透率在中国市场快速提升,自主品牌ADAS装配量大幅提升
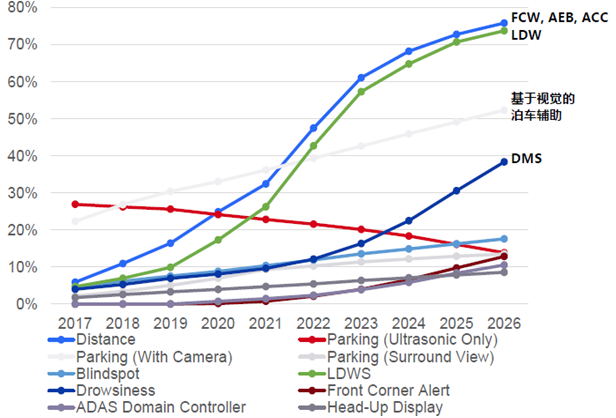
零部件成本下降、中低端车竞争加剧,推动ADAS渗透率在中国市场快速提升,自主品牌ADAS装配量大幅提升。5年前在一些高端车型上才有ADAS功能。2015 年以来,电子器件成本不断下降,消费者倾向于选择安全性能更高的、配备智能驾驶辅助功能的汽车。现在中低端车型,尤其是自主品牌,ADAS的装配率已经越来越高了,尤其是FCW前方碰撞预警系统、AEB自动紧急制动系统、ACC自适应巡航、LDW车道偏离预警系统、DMS疲劳驾驶预警系统等多项功能装配率不断提高。
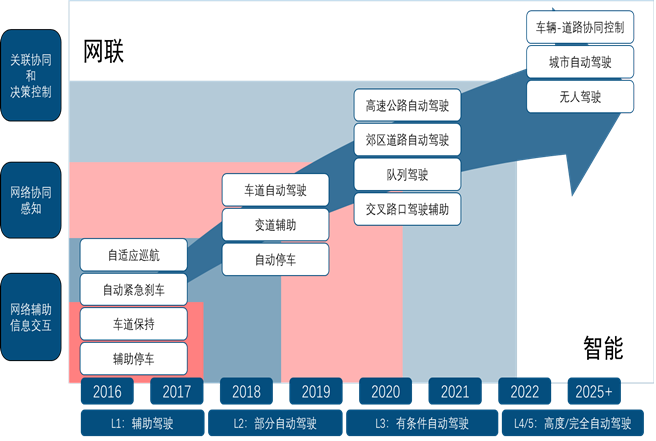
ADAS的渗透率快速提升来自于几方面动力:
1)ADAS相关的硬件成本近年来快速降低,例如毫米波雷达尤其是77GHz的毫米波雷达价格比五年前降低了超过50%;
2)CNCAP把一些基本的ADAS功能如AEB放入评价体系也在客观上有力推动了这些功能的普及;
3)中低端车竞争加剧,造成主流合资和自主品牌的重点车型上ADAS功能的搭载率甚至超过了一些在华销售的高端品牌车型。
预计未来中国市场智能驾驶辅助功能的渗透率将持续快速提升,中低端汽车配置的智能驾驶辅助功能项目将逐步增多。根据Strategy Analytics预测ADAS功能在我国乘用车中渗透率将从2019年的不到20%提高至70%以上;自动泊车目前车型渗透率较低,未来提升空间较大。根据汽车之家大数据统计,30万以下车型渗透率远不足20%,预计2025年可以达到50%左右的渗透率。
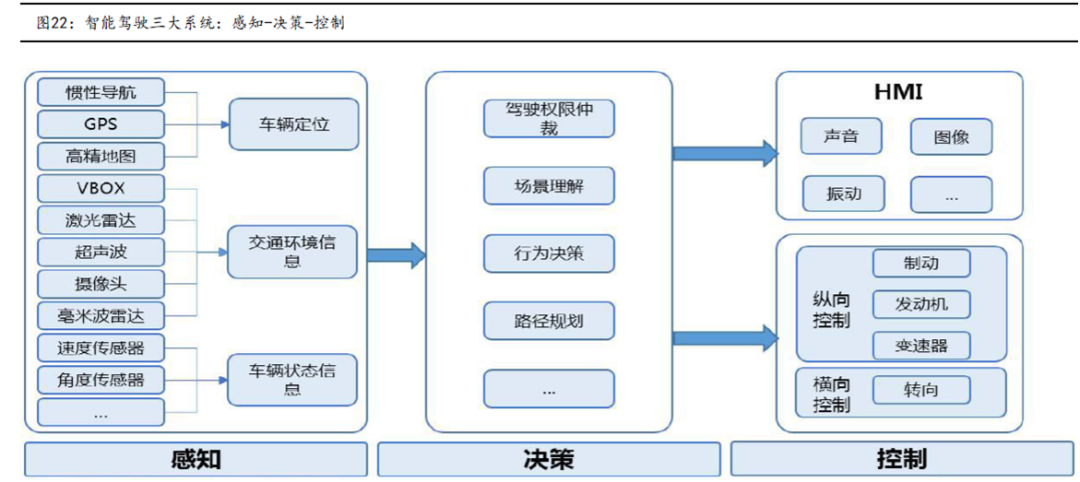
1、自动驾驶组成和主要技术简介
感知层:主要由激光雷达、 摄像头、高精度地图、IMU/GPS等部分构成,主要负责搜集车身周边信息;
决策层:以感知信息数据为基础,根高算力的计中心获取经过优化的驾驶决策;
执行层:基于决策层给出的驾驶决策,对制动系统、发机转向等控下达指令,负责驾驶执行;
自动驾驶产业链:
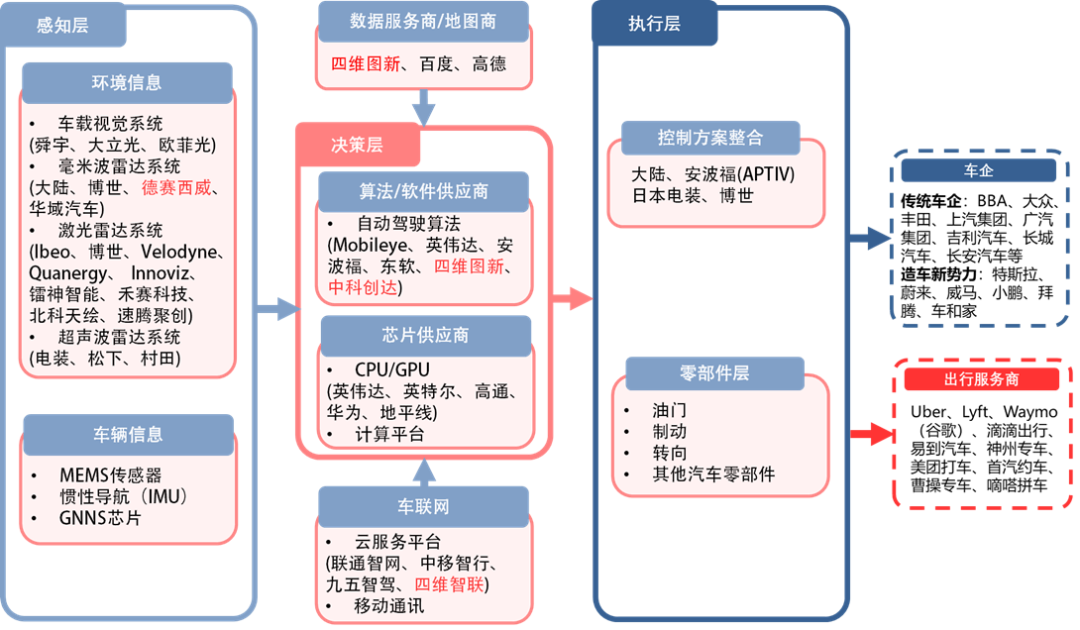
不用于智能座舱是按照Tier1 和tier2来分产业链,自动驾驶的技术层级来分的产业链,这样相对于比较清晰一些。
感知层的视觉系统:有舜宇、大立光、欧菲光;
毫米波雷达系统有大陆、博世、德赛西威、华域汽车;
激光雷达有 ibeo、博世、velodyne、Quanergy、innoviz、雷神智能、禾赛科技、北科天绘、速腾聚创;
超声波雷达系统 电装、松下、村田;
数据服务商/地图厂家 百度、四维图新、高德;
决策层有 mobileye、英伟达、安波福、东软、四维图新、中科创达;
芯片供应商有 英伟达、英特尔、高通、华为、地平线;
车联网服务平台 联通智网、中移智行、九五智驾、四维智联;
执行层 控制方案整合 安波福、日本电装、博世;
自动驾驶组成和主要技术简介
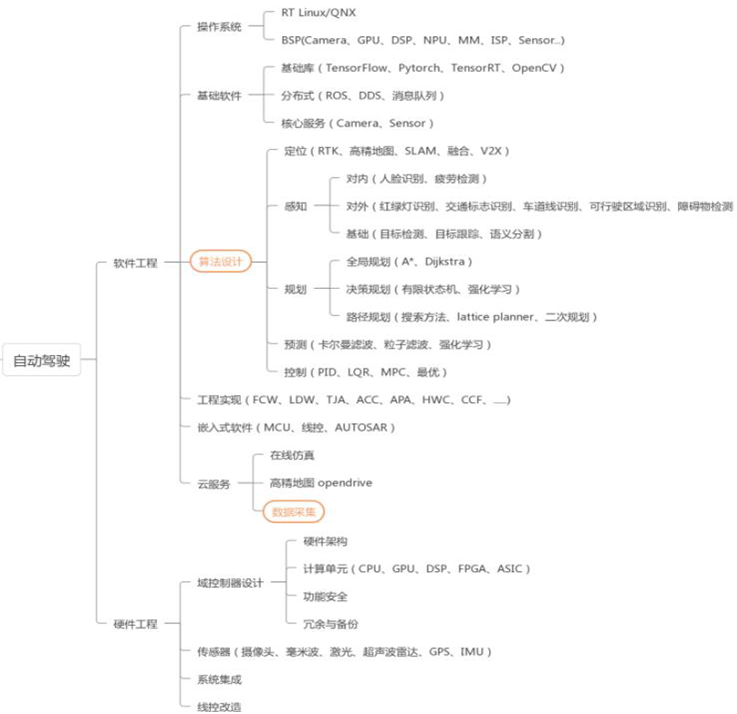
从自动驾驶各个研发环节来看,主要涉及到软件工程&硬件工程:
1)软件工程:
操作系统、
基础软件(基础库、分布式、核心服务)
算法设计(定为、感知、规划)
工程实现(FCW、LDW等)
云服务(仿真、高精度地图)
高精度地图
2)硬件工程:
域控制设计(硬件架构、计算单元、功能安全)
传感器(激光雷达、毫米波雷达、超声波雷达、摄像头、GPS、IMU等)
系统集成、线控改造。
供应链上游:CPU芯片
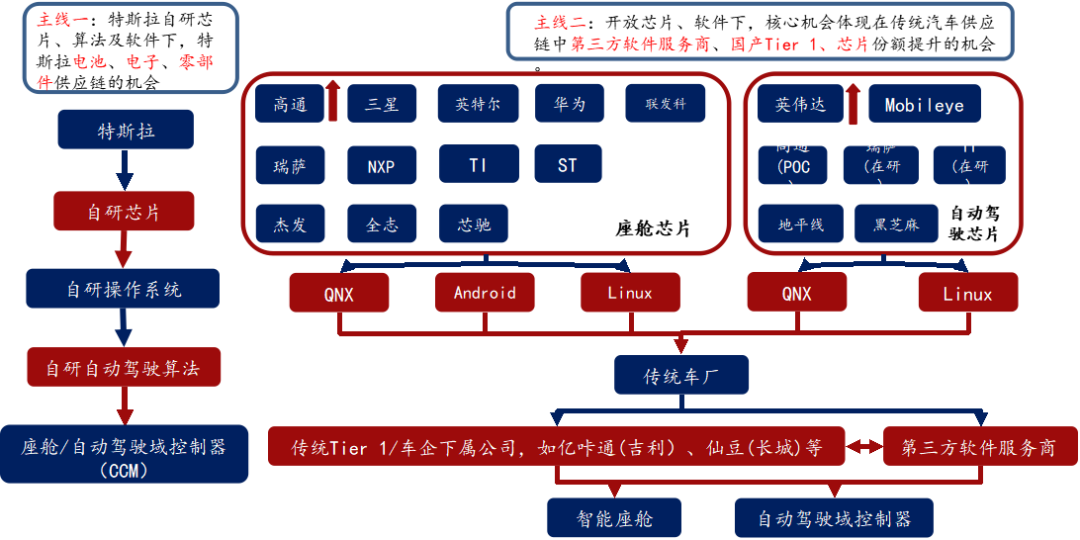
半导体、能源革命驱动的此轮汽车智能化、电动化浪潮,半导体格局反应产业链格局
座舱芯片:高通算力高、集成度高、性价比高,份额提升明显。
自动驾驶芯片
封闭生态战胜开放生态
L3+:英伟达>高通>华为
L3以下:Mobileye市占率最高,但黑盒子交付模式越来越不受车厂喜欢,未来开放模式将更受大家欢迎;地平线、黑芝麻等国产厂商有机会
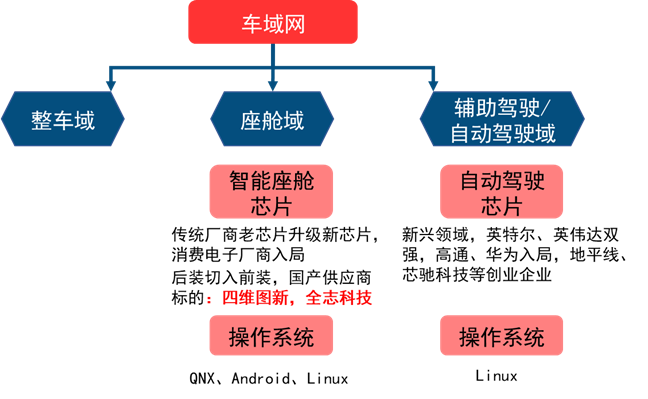
智能汽车芯片目前主要变化出现在座舱域、辅助驾驶/自动驾驶两大域控制器上。
智能座舱芯片是由中控屏芯片升级而来,目前主要参与者包括传统汽车芯片供应商以及新入局的消费电子厂商,国产厂商正从后装切入前装,包括:四维图新(杰发科技)和全志科技。
自动驾驶域控制器为电子电气架构变化下新产生的一块计算平台,目前占主导的是英特尔Mobileye和英伟达,高通、华为重点布局领域,同时也有地平线、芯驰科技等创业企业参与。
2、自动驾驶芯片相关性能介绍
运智能驾驶时代产业链分为三个层次:硬件公司为低层,上方是负责提供智能/连接/管理的软件层,顶层是与消费者体验相关的服务层;
大算力高性能芯片:相较于传统汽车,智能汽车数据量大增,高性能芯片成为刚需,比如流行的SA8155;
算法升级:目前硬件模块升级相对较慢,算法迭代升级则日新月异,持续优化的算法有助于降低成本,并提供更多的安全冗余
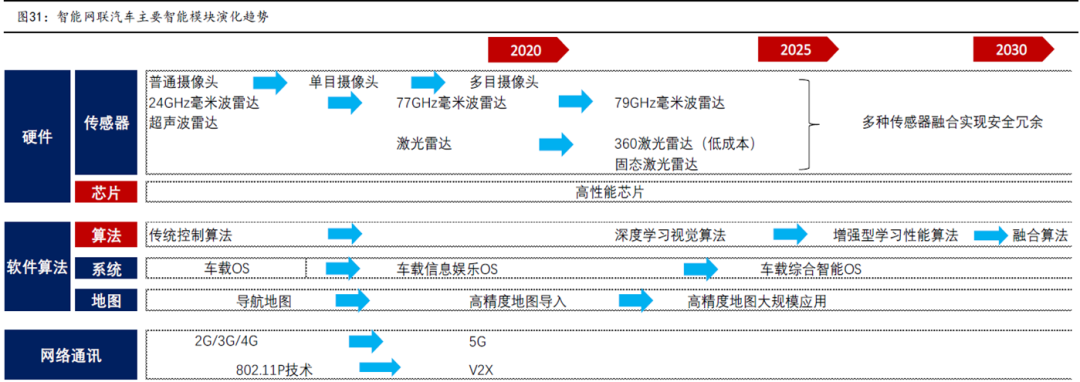
运从量产级别来看,近期量产的车型主要集中在L2+至L3级别车辆;
从硬件配置来看,相关车型主要配置有车载摄像头、毫米波雷达、超声波雷达、高算力芯片等,激光雷达则尚未配置,传感器芯片中以Mobileye相关产品居多,特斯拉采用自研的FSD;
自动驾驶适用场景中,如果是封闭路段,普遍需要高精度地图,开放路段中使用范围较小。
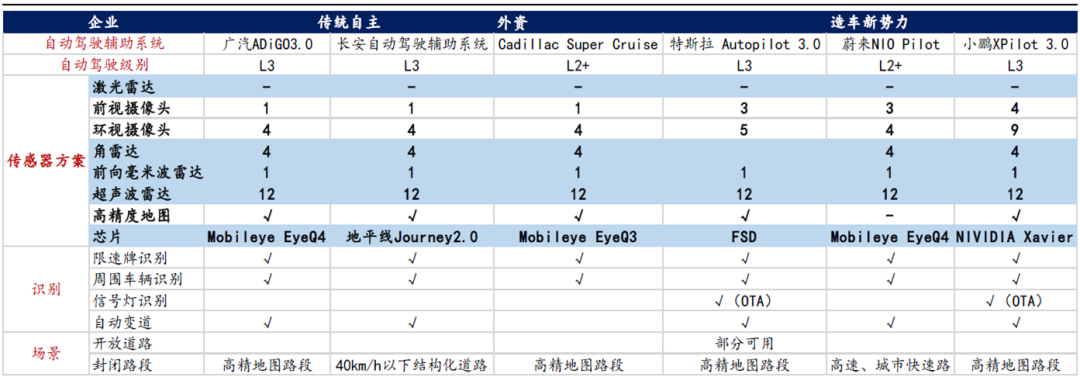
自动驾驶对于算力的要求
智能驾驶汽车涉及到传感器环境感知、高精地图/GPS精准定位、V2X信息通信、多种数据融合、决策与规划算法运算、运算结果的电子控制与执行等过程,此过程需要一个强劲的计算平台统一实时分析、处理海量的数据与进行复杂的逻辑运算,对计算能力的要求非常高。
根据地平线数据披露,自动驾驶等级每增加一级,所需要的芯片算力就会呈现十数倍的上升,L2级自动驾驶的算力需求仅要求2-2.5TOPS,但是L3级自动驾驶算力需求就需要20-30TOPS,到L4级需要200TOPS以上,L5级别算力需求则超过2000TOPS。
每增加一级自动驾驶等级算力需求增长一个数量级,根据Intel推算,全自动驾驶时代,每辆汽车每天产生的数据量高达4000GB。为了更好的智能驾驶表现,计算平台成为汽车设计重点,车载半导体价值量快速提升,汽车行业掀起算力军备竞赛。以行业龙头特斯拉为例,近日媒体报道,特斯拉正与博通合作研发新款 HW 4.0 自动驾驶芯片,预计明年第四季度就将大规模量产,新一代芯片采用7nm工艺。预计HW4.0算力有望达到432 TOPS以上,超过HW3.0的三倍以上,将可用于ADAS、电动车动力传动、车载娱乐系统和车身电子四大领域的计算,成为真正的“汽车大脑”。我们来看看主流的自动驾驶芯片的算力。

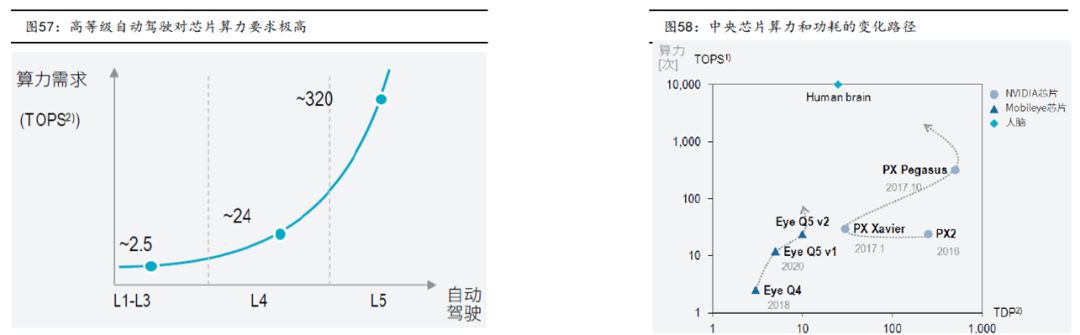
这里是量产的自动驾驶芯片的算力做的对比,英伟达最新的orin的算力秒杀全场,但是还没有量产,目前看到的特斯拉单芯片算力是量产里面最强算力的,达到72 TOPS。
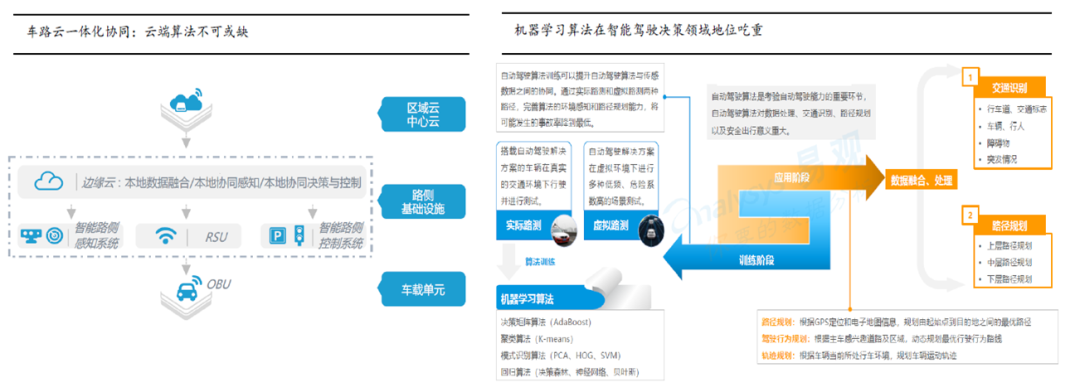
感知类算法,包括SLAM算法、自动驾驶感知算法;决策类算法包括自动驾驶规划算法、自动驾驶决策算法;执行类算法主要为自动驾驶控制算法;

涉及到的操作系统以Linux为主,编程语言包括C/C++/PYHTON/MATLAB等;

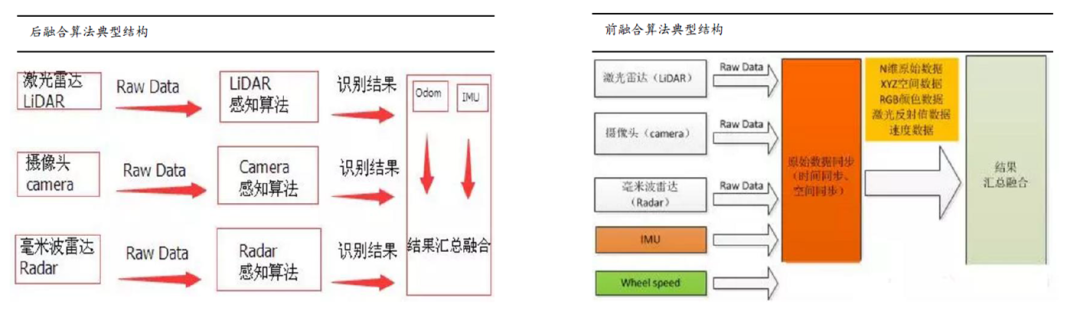
传感器融合技术:
单一类型传感器无法克服内生的缺点,我们需要将来自不同种类传感器的信息组合在一起,将多个传感器获取的数据、信息集中在一起综合分析以便更加准确可靠地描述外界环境,提高系统决策的正确性,比如典型的激光雷达+摄像头+IMU+高精度地图组合。
前融合算法:在原始层把数据都融合在一起,融合好的数据就好比是一个超级传感器,而且这个传感器不仅有能力可以看到红外线,还有能力可以看到摄像头或者RGB,也有能力看到liDAR的三维信息,就好比是一双超级眼睛,在这双超级眼睛上面,开发自己的感知算法,最后输出一个结果层的物体。
后融合算法:每个传感器各自独立处理生成的目标数据,当所有传感器完成目标数据生成后,再由主处理器进行数据融合
路端/云端:可以用于数据存储、模拟、高精地图绘制以及深度学习模型训练,作用是为无人车提供离线计算及存储功能,通过云平台,我们能够测试新的算法 、更新高精地图并训练更加有效的识别、追踪和决策模型。同时可支持全局信息存储和共享,互联互通业务流,对自动驾驶车实行路径优化。
智能驾驶时代,汽车数据处理量大幅增加,对芯片性要求更高,AI芯片为主
硬件架构升级驱动芯片算力需求呈现指数级提升趋势,汽车需要处理大量图片、视频等非结构化数据,同时处理器也需要整合雷达、视频等多路数据。这些都对车载处理器的并行计算效率提出更高要求,具备AI能力的主控芯片成为主流。
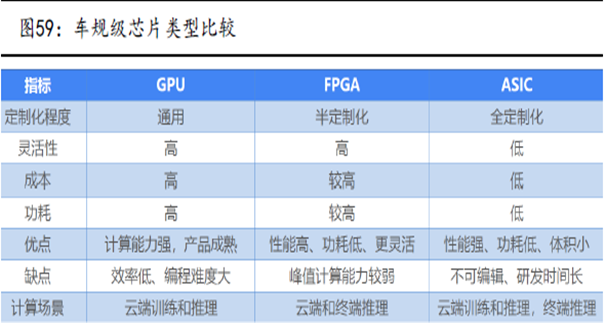
数据、算力和算法是AI三大要素,CPU配合加速芯片的模式成为典型的AI部署方案,CPU提供算力,加速芯片提升算力并助推算法的产生。常见的AI加速芯片包括GPU、FPGA、ASIC三类。
GPU是单指令、多数据处理,采用数量众多的计算单元和超长的流水线,主要处理图像领域的运算加速。但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
FPGA适用于多指令,单数据流的分析,与GPU相反,因此常用于预测阶段,如云端。FPGA是用硬件实现软件算法,因此在实现复杂算法方面有一定的难度,缺点是价格比较高。对比FPGA和GPU可以发现,一是缺少内存和控制所带来的存储和读取部分,速度更快。二是因为缺少读取的作用,所以功耗低,劣势是运算量并不是很大。结合CPU和GPU各自的优势,有一种解决方案就是异构。
ASIC是为实现特定要求而定制的专用AI芯片。除了不能扩展以外,在功耗、可靠性、体积方面都有优势,尤其在高性能、低功耗的移动端。
类脑芯片架构是一款模拟人脑的新型芯片编程架构,这一系统可以模拟人脑功能进行感知、行为和思考,简单来讲,就是复制人类大脑。
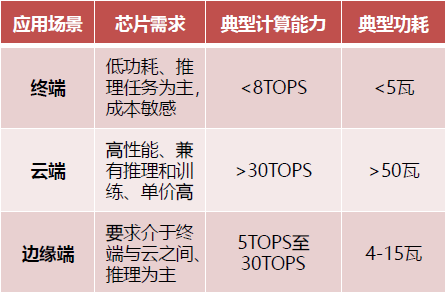
不同应用场景AI芯片性能需求和具体指标
AI芯片部署的位置有两种:云端和终端。云端AI应用主要用于数据中心,在深度学习的训练阶段需要极大的数据量和大运算量,因此训练环节在云端或者数据中心实现性价比最高,且终端单一芯片也无法独立完成大量的训练任务。
终端AI芯片,即用于即手机、安防摄像头、汽车、智能家居设备、各种IoT设备等执行边缘计算的智能设备。端AI芯片的特点是体积小、耗电少,而且性能不需要特别强大,通常只需要支持一两种AI能力。
从功能上来说,目前 AI 芯片主要有两个领域,一个是 AI 系统的 training 训练模型(主要是对深度神经网络的前期训练),另外一个是模型训练部署后,模型对新数据的 inference 推断。理论上来说 training 和 inference 有类似的特征,但是以目前的情况来说,在运算量差别大,精度差别大,能耗条件不同和算法也有差别的情况下,training 和 inference 还是分开的状态。
在 training 领域,需要将海量的参数进行迭代训练,所以芯片设计导向基本都是超高性能,高灵活性,高精度这几个方向。面向 training 的芯片一般都是在云端或者数据中心进行部署,成本大,能耗高。目前在 training 领域, Nvidia 的GPU在市场上独占鳌头,大部分的深度神经网络及项目实施都是采用 Nvidia 的GPU加速方案。同样深度学习加速市场的爆发也吸引了竞争者的入局。
Google在2015年发布了第一代TPU芯片,在2017年5月发布了基于ASIC的TPU芯片2.0版本,二代版本采用了systolic array脉动阵列技术,每秒峰值运算能力达到45TFlops。并且二代版本完善了初代TPU只能做 inference 无法 training 的问题。根据Google的披露,在自然语言处理深度学习网络中,八分之一的TPU Pod(Google自建的基于64个TPU2.0的处理单元)花费六个小时就能完成32块顶级GPU一整天的训练任务。
除了Google外,AMD也发布了基于Radeon Instinct的加速器方案,Intel则推出了 Xeon Phi+Nervana方案。在training领域,资金投入量大,研发成本高,目前竞争者主要是Nvidia GPU, Google TPU和新进入的AMD Radeon Instinct(基于GPU)和IntelXeon Phi+Nervana(基于ASIC)等。目前来看,不管是Google的TPU+tensorfow,还是其他巨头新的解决方案,想要在training端市场撼动Nvidia的地位非常困难。
相比 training 而言 inference 在计算量( 更小) , 精度要求( 更低) 和算法部署( 多种evaluation方法)上都有一定的差别,通常只需要用 training 阶段训练好的模型来对新输入的数据输出模型结果,或者在输出结果的基础上做一些调整。比如摄像头拍到的新的人像直接输出人脸识别模型的结果,就是利用 training 好的模型做一次 inference 操作。相对 training,inference比较适合在终端部署。
如iphoneX搭载的新的A11处理器内置了双核神经网络引擎,还有类似的在自动驾驶,监控摄像头,机器人等终端设备上的 inference 芯片。从CPU到GPU,再到FPGA和最后的ASIC,计算效率依次递增,但灵活性也是依次递减的。在inference方面,除了GPU之外,ASIC和FPGA都有比较大的潜力。
目前业界在 inference 方面也越来越多地开始使用专用性更强的FPGA和ASIC平台。FPGA全称“可编程门阵列”,通过在芯片内集成大量基本的门电路,允许用户后期烧写配置文件来更改芯片功能实现可更改半定制化。FPGA在延迟和功耗方面都有显著优势,在延迟需求较高比如语音识别和图像识别方面相比GPU而言是一个更好的选择。
ASIC是专用的定制化集成电路,能在开发阶段就针对特定的算法做优化,效率很高。ASIC虽然初期成本高,但是在大规模量产的情况下有规模经济效应,反而能在总体成本上占优。因为设计完成后无法更改,故ASIC的通用性比较差,市场风险高。FPGA因为可以半定制化并且内容可更改,在通用性/兼容性方面占有优势,但是在成本,性能,能效上比,ASIC更有优势
汽车主控芯片结构形式也由 MCU 向 SOC 异构芯片方向发展。
现阶段用于汽车决策控制芯片和汽车智能计算平台主要由三部分构成:
1)智能运算为主的 AI计算单元;
2)CPU单元;
3)控制单元。
主控SoC常由 CPU+GPU+DSP+NPU+各种外设接口、存储类型等电子元件组成,现阶段主要应用于座舱 IVI、域控制、ADAS等较复杂的领域。现有车载智能计算平台产品如奥迪 zFAS、特斯拉 FSD、英伟达Xavier 等硬件均主要由 AI(人工智能)单元、计算单元和控制单元三部分组成,每个单元完成各自所定位的功能。

3、车载AI芯片未来会非线性增长
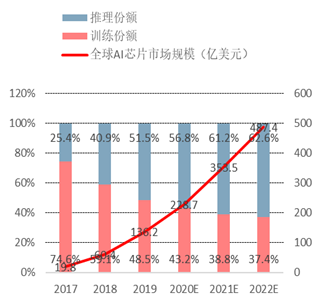
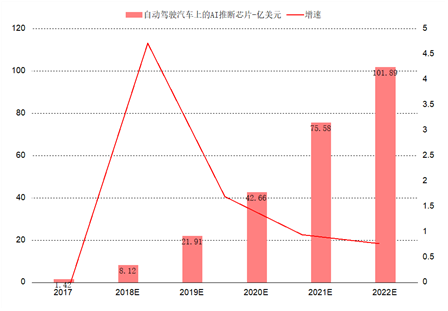
随着自动驾驶渗透率快速提升,预计车载AI芯片市场规模超过手机侧AI芯片规模。随着智能化对算力需求的指数级增长,ADAS功能逐步成为智能汽车标配,预计到2025年70%的中国汽车将搭载L2-L3级别的自动驾驶功能。观研天下预测全球自动驾驶汽车上的AI 推理芯片,其市场规模将从2017 年的1.42 亿美元,年均增长135%至2022 年的102 亿美元,相比之下手机侧AI芯片市场规模为34亿美金,汽车AI芯片市场规模远超手机侧。
部署于边缘的AI 芯片/内置单元的市场规模占比将从2017 年的21%,上升到2022年的47%。其年均增速123%,超过云端部署年均增速的75%。GPU 市场份额将从2017 年的70%下降到2022 年的39%,其主要增长动力将从数据中心算法训练,转移到自动驾驶汽车。
早期 对外采购mobileye EyeQ3 芯片+摄像头半集成方案,主要是为了满足快速量产需求,且受制于研发资金不足限制;
中期 采用高算力NVIDIA 芯片平台+其他摄像头供应商的特斯拉内部集成方案,mobileye开发节奏无法紧跟特斯拉需求;
当前:采用自研NPU(网络处理器)为核心的芯片+外采Aptina摄像头的特斯拉核心自研方案,主要原因在于市面方案无法满足定制需求,而后期时间和资金充足,公司自研实力和开发自由度更高。
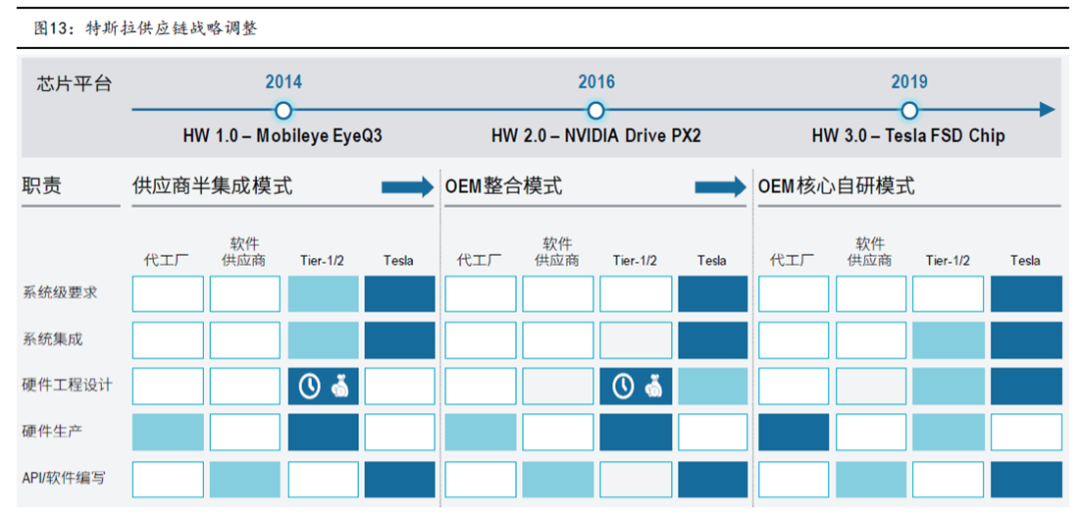
为了掌握自动驾驶话语权,同时并掌握核心数据和AI算法,过去5年特斯拉经历了外购主控芯片到自研的道路。2014年~2016年,特斯拉配备的是基于Mobileye EyeQ3芯片的AutoPilot HW1.0计算平台,车上包含1个前摄像头+1个毫米波雷达+12个超声波雷达。2016年~2019年,特斯拉采用基于英伟达的DRIVE PX 2 AI计算平台的AutoPilot HW2.0和后续的AutoPilot HW2.5,包含8个摄像头+1个毫米波雷达+12超声波雷达。
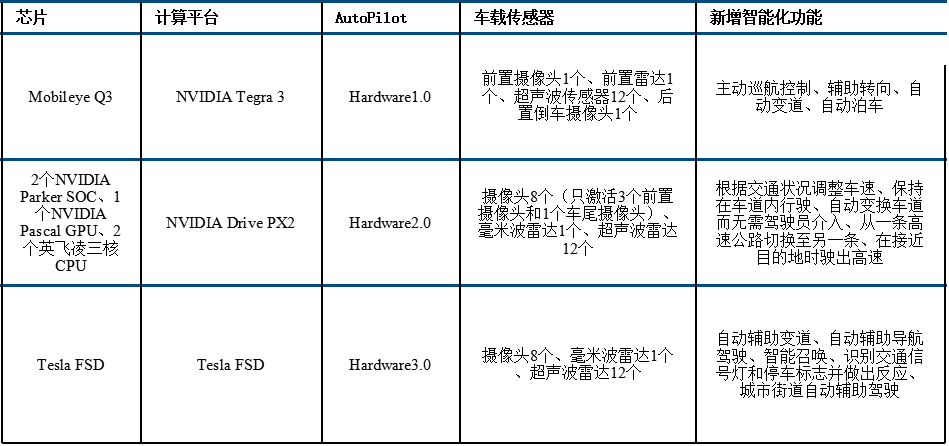
2017年开始特斯拉开始启动自研主控芯片,尤其是主控芯片中的神经网络算法和AI处理单元全部自己完成。2019年4月,AutoPilot HW3.0平台搭载了Tesla FSD自研版本的主控芯片,这款自动驾驶主控芯片拥有高达60亿的晶体管,每秒可完成144万亿次的计算,能同时处理每秒2300帧的图像。
4、特斯拉的FSD HW3.0基本介绍
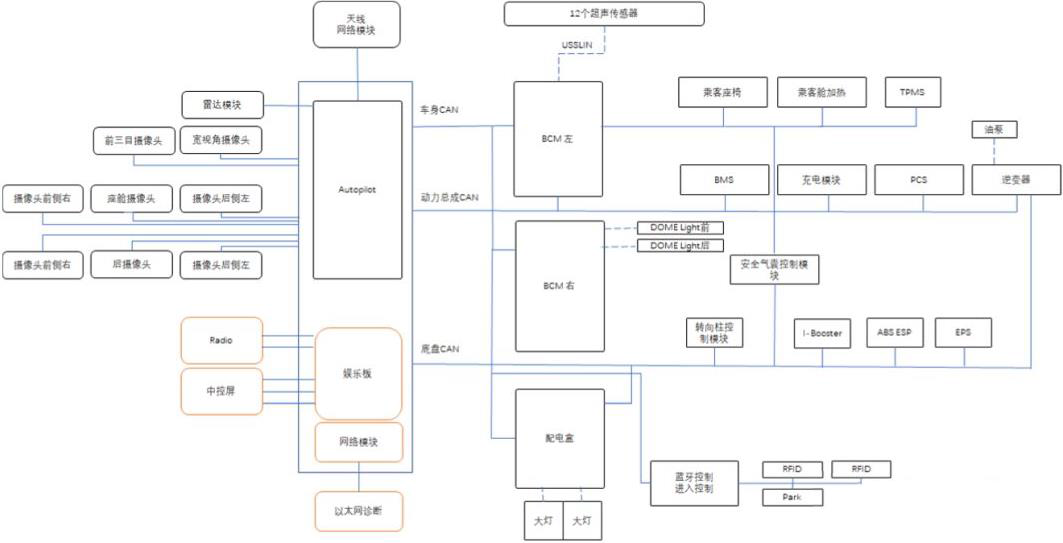
特斯拉Model 3自研“中央-区EEA”架构:中央计算机是自动驾驶及娱乐控制模块(Autopilot & Infotainment Control Module),由两块FSD芯片承担大量的数据计算,主要服务于自动驾驶功能。两个区控制器分别是右车身控制器(BCM RH)和左车身控制器(BCM LH),主要服务于热管理、扭矩控制、灯光等功能。
FSD 的 HW3.0 由两个相同的计算单元构成,每个计算单元上面有特斯拉自研的2 块FSD计算芯片,每块算力位 36 Tops,设备总算力位 4 x 36 Tops = 144 Tops。但是由于采用的是双机冗余热备的运行方式,实际可用的算力为72 Top。
特斯拉板子的右侧接口从上到下依次是FOV摄像头、环视摄像头、A柱左右摄像头、B柱左右摄像头、前视主摄像头、车内DMS摄像头、后摄像头、GPS同轴天线。左侧从上到下依次是第二供电和I/O接口(车身LIN网络等),以太网诊断进/出、调试USB、烧录、主供电和I/O(底盘CAN网络等)。
而通过特斯拉在售车型的介绍和实际配置来看,主张以摄像头视觉为核心的特斯拉安装了一个三目摄像头、4个环视、一个后置摄像头、车内DMS摄像头、前置毫米波雷达、以及12颗超声波雷达。
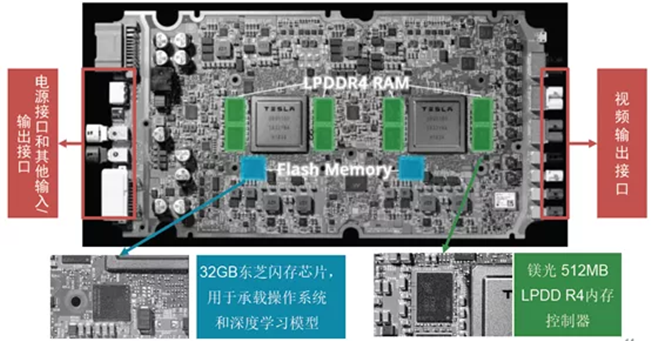
HW 3.0 PCB器件介绍
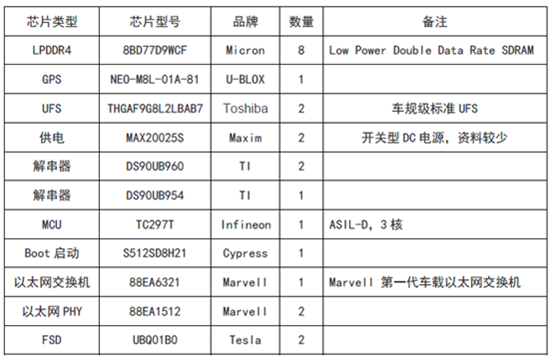
LPDDR 全称是Low Power Double Data Rate SDRAM,是DDR SDRAM的一种,又称为 mDDR(Mobile DDR SDRM),是目前全球范围内移动设备上使用最广泛的“工作记忆”内存。特斯拉的LPDDR4(8BD77D9WCF)是Micron美光供应。
FSD的GPS模块是NEO-M8L-01A-81,水平精度圆概率误差(英文简称CEP- CircularError Probable)为2.5米,有SBAS辅助下是1.5米,接收GPS/QZSS/GLONASS/北斗,CEP和RMS是GPS的定位准确度(俗称精度)单位,是误差概率单位。冷启动26秒,热启动1秒,辅助启动3秒。内置简易6轴IMU,刷新频率20Hz,量大的话价格会低于300元人民币。
UFS(Universal Flash Storage)采用THGAF9G8L2LBAB7,Toshiba 2018年中期量产的新产品,车规级标准UFS,AEC-Q100 2级标准,容量32GB,由于特斯拉的算法模型占地不大倒也够用。
MAX20025S是开关型电源稳压器,给内存供电的,来自Maxim Integrated,目前查不到更多的介绍资料。
S512SD8H21应该是Boot启动,由Cypress(已被Infineon收购)供货。
特斯拉用了3片TI的FPD-LINK,也就是解串器芯片,解串器芯片都是配对使用,加串行一般在摄像头内部,解串行在PCB上。两片DS90UB960,与其对应的可以是DS90UB953-Q1, DS90UB935-Q1,DS90UB933-Q1, DS90UB913A-Q1。DS90UB960拥有4条Lane,如果是MIPI CSI-2端口,每条Lane带宽可以从400Mbps到1.6Gbps之间设置。
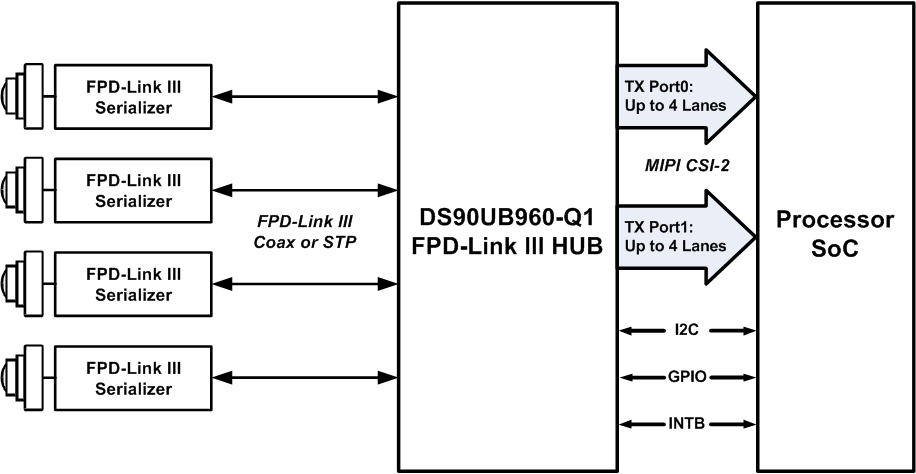
上图为TI推荐的DS90UB960的典型应用示意图,即接4个200万像素帧率30Hz的YUV444数据,或者4个200万像素帧率60Hz的YUV420数据。DS90UB954是DS90UB960简化版,从4Lane减少到2Lane,与之搭配使用的是DS90UB953。
由于大部分摄像头的LVDS格式只能用于近距离传输,因此摄像头都要配备一个解串行芯片,将并行数据转换为串行用同轴或STP传输,这样传输距离远且EMI电磁干扰更容易过车规。目前行业内做解串行芯片用的较多的就是德州仪器TI以及Maxim,特斯拉用的是德州仪器,而我们做开发接触的较多的是Maxim,可能是源于NVIDIA的AI芯片平台设计推荐,目前智能驾驶方面用的摄像头大部分都是Maxim方案。
(摄像头的数据格式通常有RAWRGB、YUV两种。YUV常见的有三种级YUV444,YUV422和YUV420。计算带宽的公式是像素*帧率*比特*X,对RAW RGB来说X=4,比如一款摄像头输出30Hz,200万像素,那么带宽是200万x30x8x4,即1.92Gbps。YUV444是像素X帧率X比特X3,即1.44Gbps,YUV422是像素X帧率X比特X2,即0.96Gbps,YUV420是像素X帧率X比特X1.5,即0.72Gbps。ADAS通常对色彩考虑不多,YUV420足够。除车载外一般多采用YUV422。)
5、特斯拉自动驾驶主芯片详细讲解
这款FSD芯片采用14nm工艺制造,包含一个中央处理器、1个图像处理单元、2个神经网络处理器,其中中央处理器和图像处理器都采用了第三方设计授权,以保证其性能和稳定性,并易于开发,关键的神经网络处理器设计是特斯拉自主研发, 是现阶段用于汽车自动驾驶领域最强大的芯片。

中央处理器是1个12核心ARM A72架构的64位处理器,运行频率为2.2GHz;图像处理器能够提供0.6TFLOPS计算能力,运行频率为1GHz;2个神经网络处理器运行在2.2GHz频率下能提供72TOPS的处理能力。为了提升神经网络处理器的内存存取速度以提升计算能力,每颗FSD芯片内部还集成了32MB高速缓存。
NPU的总功耗为7.5 W,约占FSD功耗预算的21%。这使得它们的性能功率效率约为4.9TOPs/W,特斯拉在芯片设计方面充分考虑了安全性,一块典型的自动驾驶电路板会集成两颗Tesla FSD芯片,执行双神经网络处理器冗余模式,两颗处理器相互独立,即便一个出现问题另一个也能照常执行,此外还设计了冗余的电源、重叠的摄像机视野部分、各种向后兼容的连接器和接口。
信号传输流程:
从摄像头的图像开始,根据数据流向,特斯拉解释了整个过程。首先,数据以每秒25亿像素的最大速度采集输入,这大致相当于以每秒60帧的速度输入21块全高清1080P屏幕的数据。这比目前安装的传感器产生的数据多得多。这些数据然后进入我们前面讨论的DRAM,这是SoC的第一个也是主要瓶颈之一,因为这是处理速度最慢的组件。然后数据返回到芯片,并通过图像信号处理器ISP,每秒可以处理10亿像素(大约8个全高清1080P屏幕,每秒60帧)。这一阶段芯片将来自摄像头传感器的原始RGB数据转换成除了增强色调和消除噪音之外
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1988
1988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









