







《阮郎归》
临流揽镜曳双魂 落红逐青裙 依稀往梦幻如真 泪湿千里云
风骤暖 草渐新 年年秋复春 温香软玉燕依人 再启生死门
公司项目,已申请专利。

深度学习作为新兴技术在显示屏外观缺陷检测领域蓬勃发展,因其自主学习显示屏外观缺陷特征避免了人工设计算法的繁琐,精准的检测性能、高效的检测效率以及对各种不同类型的显示屏外观缺陷都有比较好的泛化性能,使得深度学习技术在显示屏外观缺陷检测领域得到广泛应用。
由于深度学习自身的算法特性,需要大量的显示屏外观缺陷图片作为训练数据集供神经网络学习显示屏外观缺陷特征,而这些缺陷图像的获取则成了制约深度学习在显示屏外观缺陷检测领域发展应用的一大因素。每一张缺陷图片需要一个缺陷屏幕,而缺陷屏幕的数量本就不是很多,且这些缺陷屏幕都是各个厂家的保密资产,难以得到。
生成模式作为深度学习技术的一大分支在图像领域有较大发展,生成模式通过学习图像的数据统计分布特征,使用神经网络训练拟合这种统计分布特征,然后通过在分布特征中随机采样,解码重构生成与原图同分布不同采样的新数据,即生成和原图“同类但不一样”的新缺陷图片。可以大量生成各种不同的显示屏外观缺陷图像,扩充数据集。
本发明为一种基于深度学习条件变分自动编码器的神经网络模型,使用基于卷积操作的编码器提取显示屏外观缺陷图像的统计分布特征,和输入外观缺陷类别参数一起经过编码器编码成缺陷图像数据分布隐空间的均值和方差,通过训练使得隐空间的均值和方差和标准正态分布的均值和方差接近,然后从隐空间中随机采样隐向量,再加上输入外观缺陷类别参数,通过解码器生成出新的图像,该图像和原图像属于同一个统计分布空间的不同采样数据,即新图像和原图相似(都是真实的缺陷图片)但又不同(两者看起来不一样),且根据输入的不同外观缺陷类别参数,可以定向生成特定的某种外观缺陷图像,做到缺陷类型可控。
本专利属于计算机视觉、图像生成/重构领域,涉及一种基于多层卷积特征提取、注意力分配、图像重构的图像处理方法。包括采集存在外观缺陷的图像,进行图像预处理;本专利设计了一种基于多重注意力机制和条件变分自动编码器(CVAE)的神经网络模型称为KCE,提取外观缺陷图像和缺陷类别参数的条件概率分布,再根据输入外观缺陷类别参数从概率分布中随机采样,再通过神经网络解码重构生成新的缺陷图像。神经网络包括基于卷积核感受野注意力和通道注意力的特征注意力特征提取模块(KCA);平面区域注意力模块(RPA);基于3×3卷积的特征压缩模块(FS);基于注意力的DropOut模块(ADO);基于通道注意力的通道压缩模块(ACD);通道加和池化模块(CAP);增加了L2正则化用于防止神经网络过拟合;增加了Resnet技术增加前后特征层的数据交互,最大限度保留浅层的特征,消除梯度消失现象;加入数据并行(DP)模式用于减少显存消耗和提升训练速度;针对显示屏外观缺陷形状不规整的特性,本专利神经网络层中的卷积核大部分使用可变形卷积,用于匹配外观缺陷的形状,可以更好地提取特征。
使用神经网络对训练数据集进行深度学习,随机采样数据经过重参数化技术后和输入外观缺陷类别参数一起输入已完成训练的模型进行推理,生产能出新图片,并与传统的缺陷检测软件判定的类别进行综合判等。
目录
1.整体生成流程
2.缺陷图片获取及预处理
3.KCE神经网络模型设计
4.损失函数
5.神经网络模型参数
6. KCE训练和生成过程
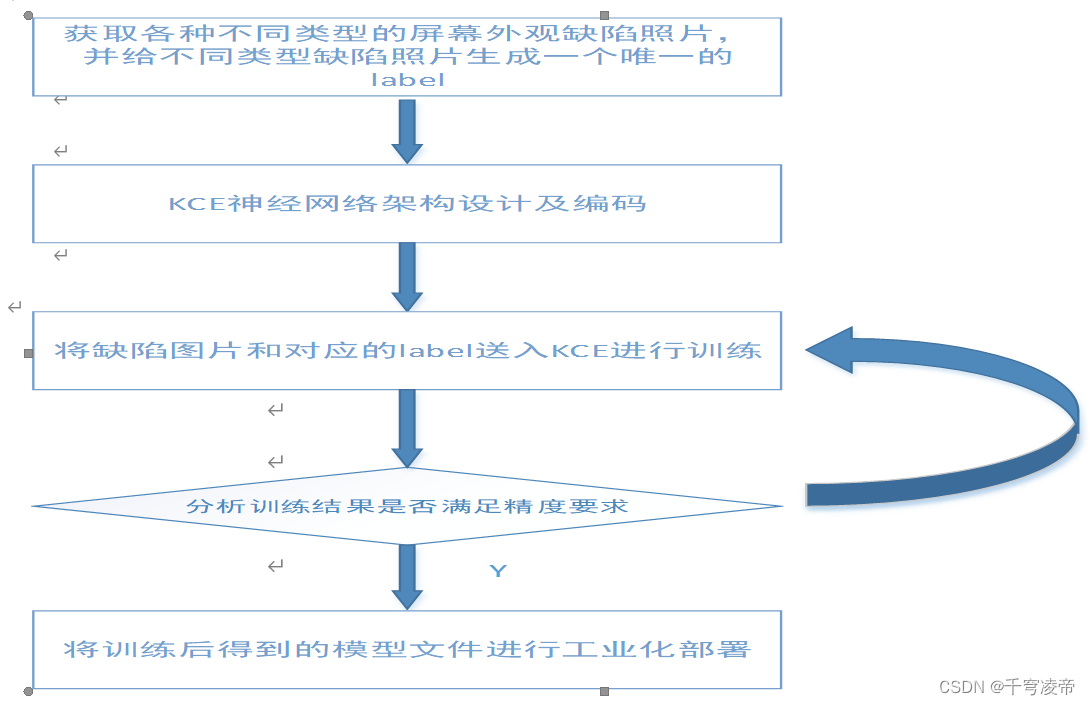
基于深度学习条件变分自编码器的显示屏外观缺陷图像数据集生成方案
本专利缺陷数据集生成方案分为缺陷图像训练集获取、AI神经网络模型设计编码、AI模型训练、AI模型测试部署五个步骤。
缺陷图片获取及预处理
本专利使用的是有监督的深度学习技术,AI模型处理的是图片数据,因此需要一些缺陷图片作为训练集。本专利通过非点屏拍照的方式获得划痕、贝壳、崩边这三种常见外观缺陷图片,对三种缺陷进行手动设置标签,比如划痕为1,贝壳为2,崩边为3。并通过抠图的方式将这三种缺陷的小图从整个显示屏图像上截取出来,避免大量无用像素的干扰以及节约内存减少训练时间。
KCE神经网络模型设计
本专利选择使用基于条件变分自动编码器的神经网络进行外观缺陷图像的生成,将缺陷照片和对应的类别标签一起输入编码器,编码得到缺陷数据的条件概率分布,从该概率分布空间随机采样,重参数化后再和标签一起输入解码器得到重构后的新缺陷图片。AI神经网络基于卷积、池化、非线性化、BN等操作,对输入图片样本进行特征提取(Encoder),每个阶段的特征提取都使用了多重注意力机制;平面区域注意力模块(RPA);基于3×3卷积的特征压缩模块(FS);基于注意力的DropOut模块(ADO);基于通道注意力的通道压缩模块(ACD);通道加和池化模块(CAP);增加了L2正则化用于防止神经网络过拟合;增加了Resnet技术增加前后特征层的数据交互,最大限度保留浅层的特征,消除梯度消失现象;针对显示屏外观缺陷形状不规整的特性,本专利神经网络层中的卷积核大部分使用可变形卷积,用于匹配外观缺陷的形状,可以更好地提取特征设计了新的基于注意力的通道池化方法,通道加和池化模块(CAP),增强每个特征通道的数据表证;使用基于注意力的Dropout技术,防止过拟合;
本专利自主设计一套AI神经网络体系结构名为KCE,如下图:
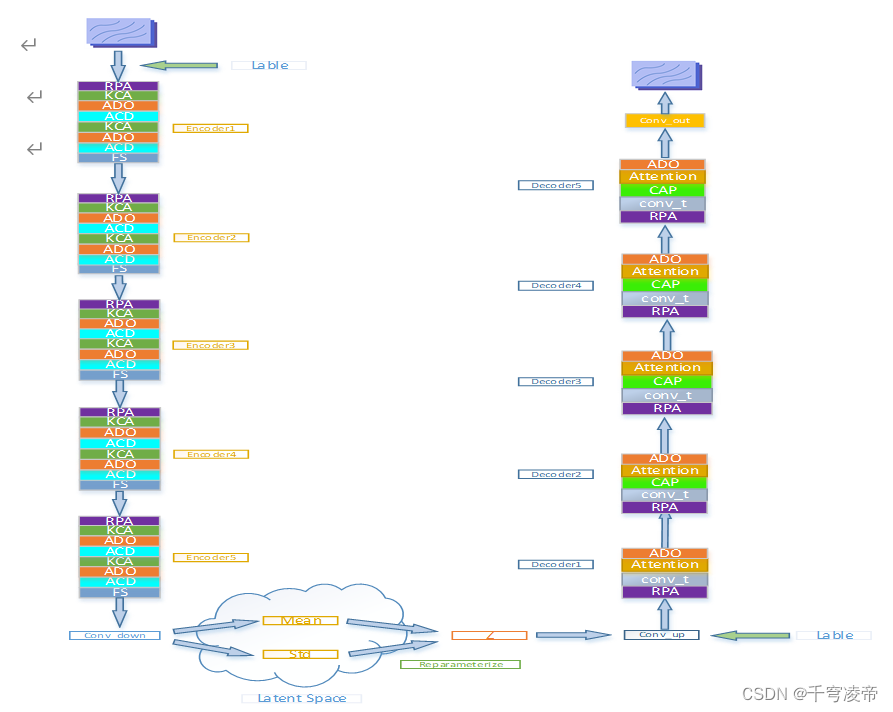
整个神经网络分为Encoder、条件概率隐空间和Decoder三部分,左边为图像特征提取分支(Encoder),包括5个Encoder模块,每个Encoder包含一个区域像素注意力模块(RPA)、2个多重注意力卷积模块(KCA)、2个注意力Dropout模块(ADO) 、2个注意力通道池化模块(ACD)和一个特征压缩(FS)模块。RPA和KCA构成三重注意力机制,分别是区域像素注意力、卷积核感受野注意力和特征通道注意力。RPA模块给输入特征的每一块区域的像素值分配注意力权重;KCA模块使用3个不同感受野的卷积核分别对输入特征进行卷积操作,再将3个不同感受野的卷积核生成的特征按通道叠加,经过压缩-解压后给每一个通道分配注意力权重,然后各个通道对应注意力和原通道相乘,再将3个特征通道按通道相加,再和输入特征按通道叠加;ADO模块给特征的每个神经元分配注意力,将注意力小于阈值的神经元置零;ACD模块给特征的每个通道分配注意力,舍弃注意力排序较后的通道;FS模块对输入特征长宽进行压缩;
下方为条件概率隐空间,第五个Encoder输出的特征分别通过两个Norm_conv_down模块生成平均值(mean)和方差(logvar)作为隐空间参数,均值(mean)和方差(logvar)经过重参数化技术(Reparameterize)采样为正态分布值Z,和标签按通道叠加后,再经过Norm_conv_up模块送入Decoder模块;
右边为图像重构生成分支(Decoder)分支包括5个Decoder模块和一个Conv_out。每个Decoder包括区域像素注意力模块(RPA) 、一个反卷积模块(Conv_t) 、一个注意力Dropout模块(ADO)和一个通道注意力(Attention)模块。后4个Decoder还包括一个通道加和池化模块(CAP)。Conv_t将输入特征进行重构,减少通道数;CAP将输入通道分组,每组特征按通道进行加和,每组输出一个通道,进行通道降维操作。通道注意力(Attention)模块给每个通道分配注意力权重。Conv_out将特征通道压缩至3通道恢复原图尺寸,完成图像的重构生成。
类别标签是独立一个张量,值为类别标签值比如划痕就是全为1的张量,长宽尺寸和输入图像/特征一致,将其作为输入图像/特征的一个独立通道。
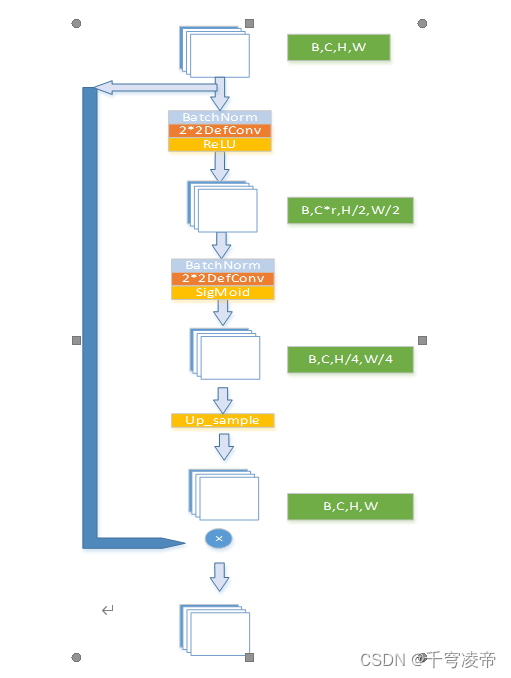
RPA
RPA作为第一重注意力机制,给输入特征的每块区域像素分配一个权重,使得神经网络对于图像特征明显的区域更加关注。输入特征(B,C,H,W)先经过一个BatchNorm-DefConv-ReLU进行通道压缩为(B,C*r,H/2,W/2),r<1;再经过一个BatchNorm-DefConv还原成(B,C,H/4,W/4),通过SigMoid函数生成每个像素值的权重,最后使用双线性插值还原成(B,C,H,W),和原输入特征一对一相乘相乘。
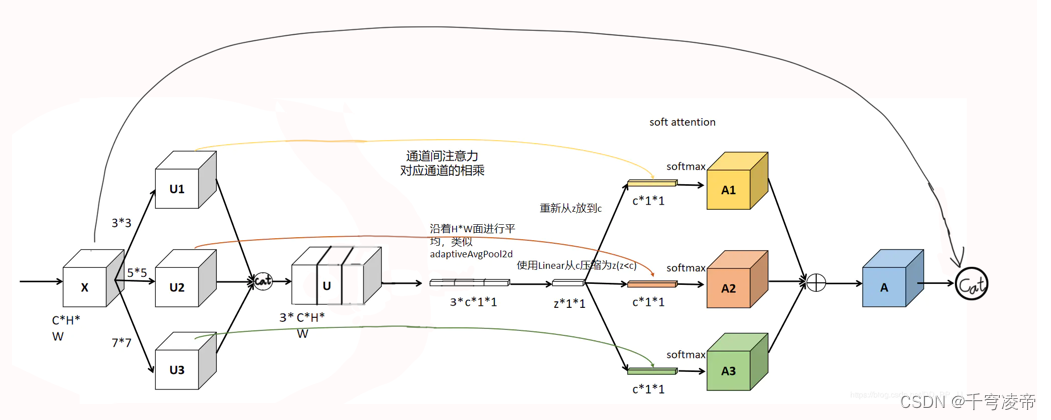
KCA
分别用于卷积核感受野注意力和特征通道注意力,通过不同感受野的卷积核对特征图的不同大小区域分配注意力,通过通道注意力对不同特征通道进行筛选,进一步提高神经网络对输入特征的编码效果,加入了Resnet结构,增强前后层特征的流通,防止梯度消失和梯度爆炸。
对输入特征使用3种不同大小感受野的可变形卷积核分别进行特征提取,将得到的3个特征按通道叠加(B,3*C,H,W),再把这个特征进行压缩和全局平均池化(B,3C’,1,1),再恢复成(B,3C,1,1),然后经过Sofamax给3个卷积输出的特征通道整体分配注意力,各个通道注意力和之前的3个卷积输出特征按通道对应相乘,再按通道对应元素相加,再和原输入按通道叠加。
ADO
基于注意力的Dropout方法,不同于一般Dropout使用的随机方式,利用注意力保留更重要的特征信息,使得神经网络的性能和泛化性更好。
对输入特征经过两个批次归一化+可变性卷积+ReLU/SigMiod,生成和原特征形同尺寸的注意力矩阵,根据注意力矩阵的值,将注意力小于阈值的原特征矩阵对应位置神经元置零。
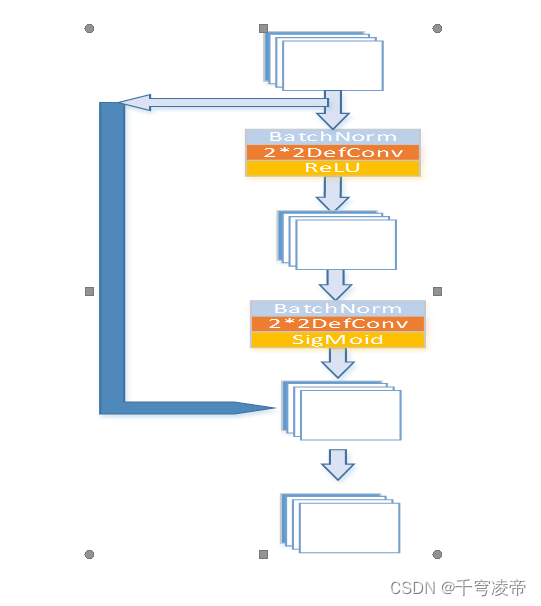
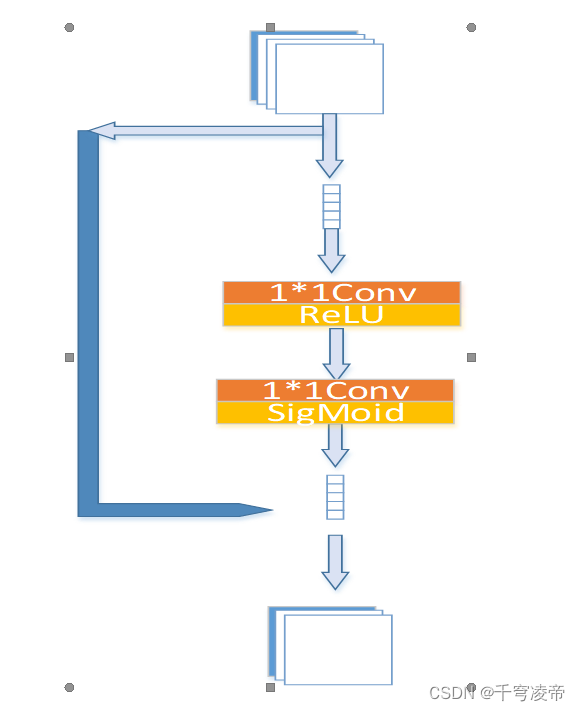
ACD
基于注意力的通道压缩方法,输入特征经过全局平均池化,1*1Conv+ReLU,1*1Conv+SigMoid生成各个通道的注意力,将特征通道按注意力排序,把注意力排名靠后的通道舍弃。
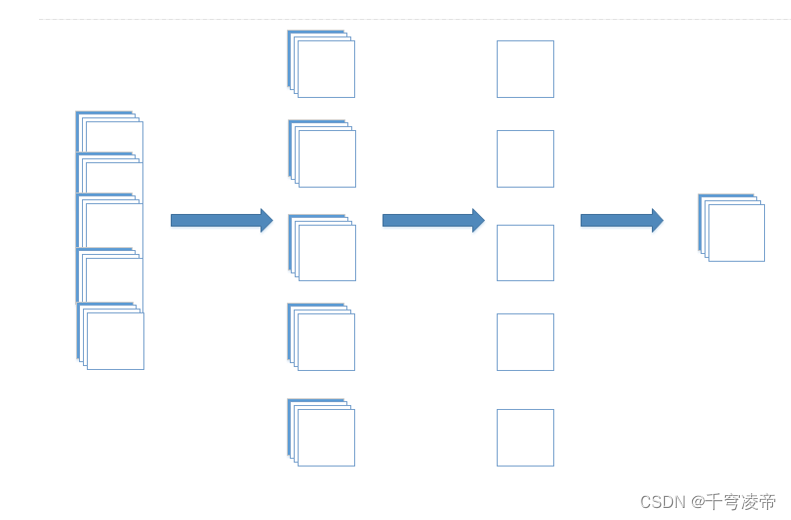
Feature Squeeze
使用卷积对上一层输出的特征提取特征信息,并压缩长宽。
Conv_down模块
通过两个卷积模块分别生成隐空间的均值和方差向量。
Conv_up
使用反卷积模块将隐向量Z重构,增加特征长宽。
Conv_t
使用反卷积模块将输入特征和类别标签重构,增加特征长宽。
CAP
将输入特征按通道分组,每组特征按通道相加,融合各个通道特征信息并减少特征通道数。
Attention
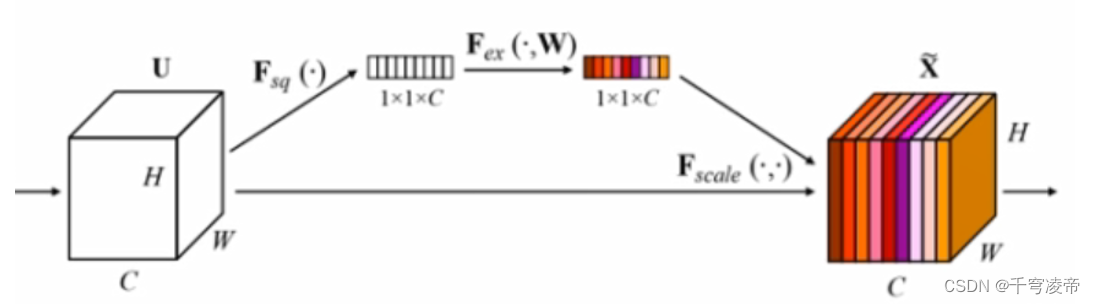
注意力机制通过对不同特征通道分配归一化的权重,增强某些特征通道而抑制其他的特征通道,达到选择特征信息的效果。
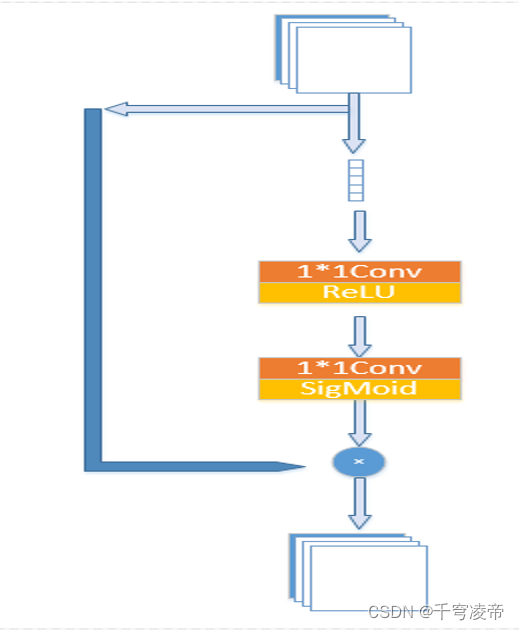
输入特征经过全局平均池化(Global Pooling) 生成通道向量;经过1×1卷积 、ReLU激活函数进行通道压缩;经过1×1卷积以及Sigmoid激活函数,输出一个维度等于输入特征通道数的归一化一维向量,这就是各个特征通道的注意力权重,将其输入特征各个通道相乘。
Conv_out
使用一个3×3卷积将特征还原成原图尺寸的3通道图片。
损失函数
生成图片的性能可以通过 evidence lower bound(ELBO) loss 来评估,该损失由Reconstruction loss 和 Kullback–Leibler loss(KL loss)组成。Reconstruction loss 用于计算生成的数据与原始数据的相似程度,而 KL loss 作为一个额外的 loss,用于测量一般正态分布与标准正态分布的差异,也就是均值 μ 和方差 之间的差异。
均方误差(MSE)是最常用的回归损失函数。MSE是目标变量与预测值之间距离平方之和,本专利使用经过LVAE神经网络模型恢复重构后的图片和标原图对应像素进行MSE,得到误差值,再进行反向梯度计算,更新神经网络的权重值。

在给定的隐变量空间维度为 n 的条件下,已知均值 和方差,KL loss 定义为:

最终,ELBO loss 由上述两个损失函数组成,系数为 α 和 β:
![]()
简单来说,这里的 Reconstruction loss 是用来让 decoder 的输出 Y 和输入 X 尽可能相似。而 KL loss 希望隐变量空间可以符合标准的正态分布,但实际 X 的分布其实并不是标准的正态分布,也就是说 KL loss 会让输出 Y具有多样性,与输入 X 产生一部分的差异。
神经网络模型参数
神经网络模型参数分为训练配置参数和模型结构参数,配置参数如下表:
KCE训练和生成过程
整个神经网络训练分为正向推理和反向传播:
1.正向推理:缺陷图片数据和标签输入KCE神经网络Encoder,标签和隐空间采样特征一起输入Decoder,按照4.2的数据流程通过神经网络,最终重构成结果图;
2.结果图和原图片使用4.2.14节的损失函数,计算损失值;
3.反向传播:优化器算法,将损失值反向传播到神经网络的各个阈值参数上,并更新阈值;
4.反复进行1-3,不停更新神经网络阈值参数,使得正向推理得到的结果图和原图片的损失值达到要求,停止训练;
训练完成后,生成时只使用Decoder,输入标签以及从正态分布中随机采样的数据,经过Decoder自动生成外观缺陷图像。
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











