






去噪自动编码器(DenoisingAutoencoder)
去噪自动编码器(Denoising Autoencoder,简称DAE)是一种无监督学习算法,用于对数据进行降噪和特征提取。它是自动编码器的一种变种,通过在输入数据中引入噪声,并尝试还原原始数据的过程,实现了对噪声的去除和恢复数据的功能。
一、去噪自动编码器的概念
去噪自动编码器是一种用于降噪和恢复数据的无监督学习算法。它通过在输入数据中引入噪声,并尝试从噪声数据中还原出原始数据,实现了对噪声的去除和还原数据的功能。与传统的自动编码器相比,去噪自动编码器具有更强的鲁棒性和泛化能力。
二、去噪自动编码器的结构
去噪自动编码器的结构和自动编码器类似,由编码器和解码器组成。
编码器:编码器将输入数据映射到潜在空间中的表示。与普通的自动编码器不同,在输入数据中引入噪声后,编码器仍然负责将噪声数据映射到潜在表示上。
解码器:解码器将编码器输出的潜在表示映射回原始输入空间,并尝试还原出原始数据。解码器的目标是尽量减少噪声的干扰,还原出与原始数据相似的结果。
三、去噪自动编码器的训练方法
去噪自动编码器的训练过程可以分为两个步骤:添加噪声和重构数据。
添加噪声:在训练阶段,去噪自动编码器需要在输入数据中引入噪声。常用的噪声类型包括高斯噪声、椒盐噪声等。通过添加噪声,可以模拟实际应用中的噪声环境,提高编码器的鲁棒性。
重构数据:在添加噪声后,编码器将噪声数据映射到潜在表示,在解码器的帮助下,重构出与原始数据相似的结果。因此,去噪自动编码器的目标是在尽量减少噪声干扰的情况下,还原出原始数据。
训练去噪自动编码器的关键是找到合适的权衡噪声和重构误差的方法。一种常用的方法是最小化重构误差和输入数据与还原数据之间的差异,通过优化这两个目标,可以得到在噪声环境下尽可能准确的数据恢复结果。
Likelihood-based models
Autoregressive models 自回归模型是一种可以用来预测序列数据的模型,它能够学习序列数据的联合分布,并且使用先前时间步的变量作为输入来预测每个变量在序列中的取值。这种模型假设序列数据的联合分布可以被分解成一系列条件分布的乘积,这也就是所说的“条件概率分解”。
上面我们简单跟大家聊到过RNN,本质上自回归模型和RNN都需要使用前面的时间步来预测当前时间步的值,但是它们的实现方式略有不同。在自回归模型中,前面的时间步直接作为输入提供给模型,而在 RNN 中,前面的时间步通过隐藏状态传递给模型。因此,可以将自回归模型看作是一个前馈神经网络,它接收前面所有时间步的变量作为输入。
在早期的工作中,自回归模型主要用于建模离散数据。其中,Fully Visible Sigmoid Belief Network, FVSBN使用逻辑回归函数来估计条件分布,而Neural Autoregressive Distribution Estimation, NADE则使用单隐藏层的神经网络。随着研究的发展,自回归模型的应用逐渐扩展到连续变量的建模。自回归模型已经在多个领域得到了广泛应用,包括计算机视觉如PixelCNN和PixelCNN++、音频生成WaveNet和自然语言处理Transformer等等。这些应用中,自回归模型被用来生成图像、音频、文本等序列数据。
VAE 自编码器是一类相似的模型,它们通过编码器Encoder将输入数据映射到低维的潜在表示空间,然后再通过解码器Decoder将这个低维表示还原回原始数据。整个编码-解码的过程旨在学习输入数据的潜在结构,以便于重建数据和生成新的样本。
变分自编码器VAE则是自编码器的一种变体,它使用了贝叶斯定理,通过学习潜在变量Latent variable的分布,从而学习原始数据的分布。为了训练 VAE,需要最大化一个较复杂的目标函数,它由一个最大化数据似然的项和一个正则化项组成。正则化项通常使用KL散度来度量潜在变量的分布和标准正态分布之间的差异。
Latent Space潜在空间
数据的潜在空间表示包含表示原始数据点所需的所有重要信息。然后,该表示必须表示原始数据的特征。换句话说,该模型学习数据特征并简化其表示,从而使其更易于分析。这是称为表示学习(Representation Learning)的概念的核心,该概念定义为允许系统从原始数据中发现特征检测或分类所需的表示的一组技术。在这种用例中,我们的潜在空间表示用于将更复杂的原始数据形式(即图像,视频)转换为更“易于处理”和分析的简单表示。
像素空间
像素空间是指图像中由像素组成的空间。像素是图像的基本构成单位,它们是由色彩值和位置确定的小方格。在图像中,每个像素都有一个明确的位置和色彩值,这些像素共同构成了图像的整体效果。 像素空间的概念在数字图像处理、计算机图形学和多媒体技术等领域中有广泛的应用。在数字图像处理中,图像的像素空间用于表示和处理图像的各种属性,如颜色、亮度等。在计算机图形学中,像素空间用于绘制和显示图像,以及实现各种图形效果。在多媒体技术中,像素空间则用于处理和分析图像数据,以实现图像的压缩、传输和识别等功能。 总之,像素空间是指图像中由像素组成的空间,这些像素共同决定了图像的视觉特征和表现效果。在各种计算机技术和多媒体应用中,对像素空间的理解和处理是至关重要的。
UNet 架构
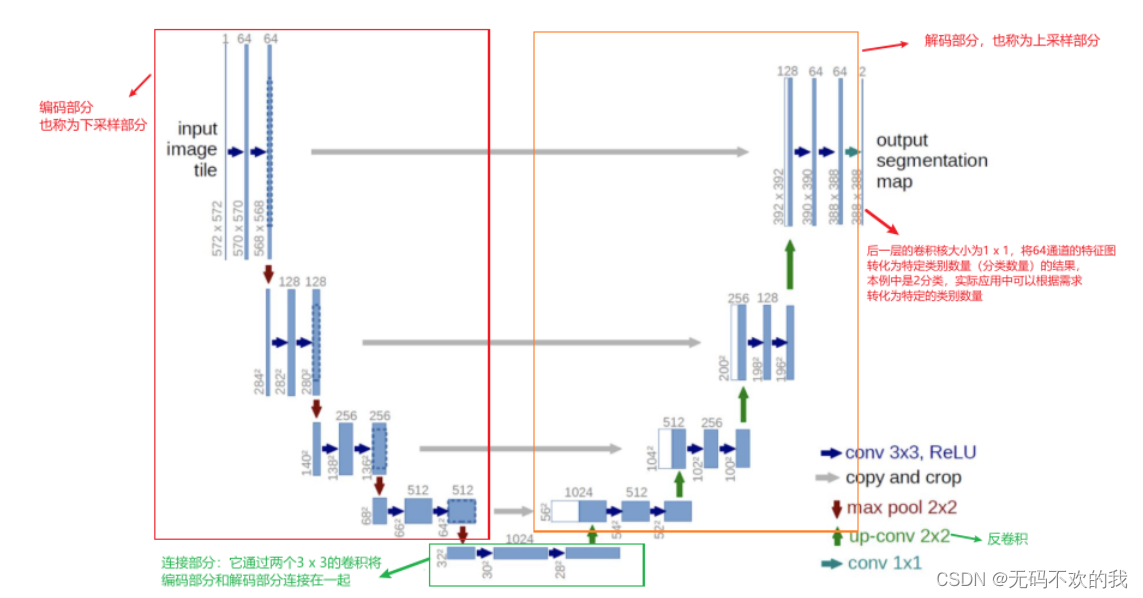
Encoder:左半部分,由两个3x3的卷积层(RELU激活函数)再加上一个2x2的maxpooling层(最大池化层)组成一个下采样的模块
Decoder:有半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成
整个网络由编码部分(左) 和 解码部分(右)组成,类似于一个大大的U字母,具体介绍如下:
1、编码部分是典型的卷积网络架构:
它主要的作用是进行特征提取 架构中含有着一种重复结构,每次重复中都有2个 3 x 3卷积层、非线性ReLU层和一个 2 x 2 max pooling层(stride为2)。(图中的蓝箭头、红箭头,没画ReLu) 每一次下采样后我们都把特征通道的数量加倍 2、解码部分也使用了类似的模式:
它主要的作用是进行上采样 (上采样可以让包含高级抽象特征的低分辨率图片在保留高级抽象特征的同时变为高分辨率) 架构中包含有一种重复结构,每次重复都有一个上采样的卷积层(反卷积层),特征拼接concat,两个3x3的卷积层,非线性ReLU层 每一步都首先使用反卷积(up-convolution),每次使用反卷积都将特征通道数量减半,特征图大小加倍。(图中绿箭头) 反卷积过后,将反卷积的结果与编码部分中对应步骤的特征图拼接起来(concat)(也就是将深层特征与浅层特征进行融合,使得信息变得更丰富)。(白/蓝块) 编码部分中的特征图尺寸稍大,将其修剪过后进行拼接(这里是将两个特征图的尺寸调整一致后按通道数进行拼接)。(左边深蓝虚线部分就是要裁剪的部分,它对应右边的白色长方块部分) 对拼接后的map再进行2次3 x 3的卷积。(右侧蓝箭头) 最后一层的卷积核大小为1 x 1,将64通道的特征图转化为特定类别数量(分类数量)的结果。(图中青色箭头)
Unconditional image synthesis
Unconditional image synthesis 是指一种人工智能技术,可以通过生成模型(generative models)来生成全新的图像,这些图像可以是现实世界中不存在的事物或者是修改过的现有事物。与传统的计算机生成图像方法不同,unconditional image synthesis 不需要依赖于训练样本中的特定条件或标签信息,而是直接从随机噪声中生成图像。 Unconditional image synthesis 的代表性技术有生成对抗网络(GANs)和变分自编码器(VAEs)。这些技术已经在各种领域取得了显著的成果,例如图像编辑、艺术创作、虚拟现实等。 unconditional image synthesis 的一个重要应用是图像生成,可以用于创建虚拟世界、设计游戏角色、渲染电影场景等。此外,它还可以用于图像编辑和增强,如将人像合成到风景中、调整图片亮度和对比度等。
Stochastic super-resolution(随机超分辨率)
Stochastic super-resolution(随机超分辨率)是一种图像处理方法,用于提高图像的分辨率。与传统的超分辨率方法不同,随机超分辨率通过引入随机性来生成高分辨率图像。这种方法可以提高图像的质量,使其看起来更加真实。 随机超分辨率通常基于以下两种主要策略: 基于生成的方法(Generative-based methods):这类方法利用生成模型,如生成对抗网络(GANs)或变分自编码器(VAEs),从低分辨率图像生成高分辨率图像。在训练过程中,模型学会捕捉图像中的潜在结构和高频信息,从而在提高分辨率的同时保留图像的细节。 基于插值的方法(Interpolation-based methods):这类方法通过在低分辨率图像上进行像素级别的插值来生成高分辨率图像。这类方法中最常用的是双线性插值(Bilinear interpolation)和双三次插值(Bicubic interpolation)。虽然这些方法在提高分辨率方面取得了一定的成果,但它们往往会导致图像失真和模糊。
Transformer-based approaches(基于变压器的方法)
Transformer-based approaches(基于变压器的方法)是一种人工智能技术,它利用深度学习模型中的自注意力机制(self-attention)来处理和生成数据。Transformer 是一种特殊的神经网络结构,于 2017 年由 Vaswani 等人在论文《Attention is All You Need》中提出。这种结构在自然语言处理(NLP)等领域取得了显著的成果,并逐渐应用于其他领域,如计算机视觉、音频处理等。 基于变压器的方法具有以下特点: 自注意力机制:Transformer 模型通过自注意力机制来捕捉输入数据中的全局依赖关系。这种机制使得模型能够理解数据中的长距离依赖,从而提高模型的性能。 并行计算:与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer 模型可以采用并行计算的方式处理数据。这使得基于变压器的模型在训练和推理阶段都能实现高效计算。 参数共享:Transformer 模型中的自注意力机制通过共享权重来减少参数数量,降低了模型的复杂度。这使得模型在训练和部署阶段具有较高的效率。 可扩展性:基于变压器的方法具有良好的可扩展性,可以轻松地扩展到不同领域和任务。目前,Transformer 已经成功应用于文本生成、机器翻译、图像分类、语音识别等多种任务。
Inductive biases(归纳偏见)
Inductive biases(归纳偏见)是指在机器学习和人工智能领域中,算法在训练过程中对数据分布的假设或先验知识。归纳偏见可以帮助算法在学习过程中更有效地捕捉到数据的潜在规律,从而提高模型的泛化能力。 归纳偏见通常分为以下几种类型: 参数偏见:指算法在训练过程中对参数空间的假设。例如,在神经网络中使用 ReLU 激活函数,假设数据分布具有非线性特征。 架构偏见:指算法在训练过程中对网络结构或层之间的连接方式的假设。例如,在卷积神经网络(CNN)中,假设图像特征具有局部相关性,因此采用卷积层和池化层来捕捉这些局部特征。 损失函数偏见:指算法在训练过程中对损失函数的假设。例如,在分类任务中使用交叉熵损失函数,假设类别分布为多项式分布。 数据偏见:指算法在训练过程中对数据分布的假设。例如,在监督学习中假设输入数据和标签之间存在一一对应的关系。 训练策略偏见:指算法在训练过程中对训练策略的假设。例如,在随机梯度下降(SGD)中假设数据之间相互独立。















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









